汽车之家字体反爬破解实践

汽车之家字体反爬破解实践
一、概览
爬虫与反爬虫一直是一对天生的对手,反爬手段多种多样,破解手段也应运而生。
本文主要介绍一种利用前端页面自定义字体的方式来实现反爬的技术手段,并实践如何技术上破解。(期间多次掉坑,拼接顽强的毅力,仍然坚强的走出来。)
自定义字体:@font-face是CSS3中的一个模块,主要是实现将自定义的Web字体嵌入到指定网页中去。具体详细定义见CSS @font-face。
二、查找字体源
汽车之家论坛是广大车友爱好者的集聚地,大家分享买车、选车、开车、自驾游等个人经历。我们尝试爬取一些用户热门精华帖子的内容,初始访问似乎并没有什么特别,直到我们发现下图所示。这里页面显示很正常的文字,但是在网页源码中某些字却是一段span包裹的不可见文本。
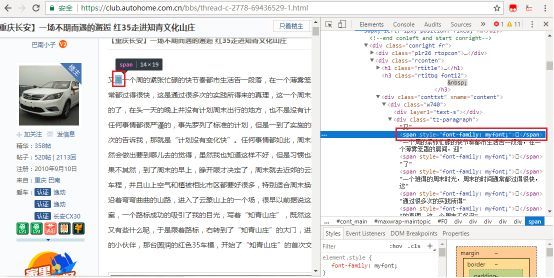
手动拷贝网页文本到Noetepad++,也发现了异常。
上面其实就是自定义字体搞的鬼。根据网页源码中,
<span style="font-family: myfont;">span>
使用了自定义的myfont字体,我们在网页中查找myfont,很快有了发现,这就是标准的@font-face定义方法。且每次访问,字体文件访问地址都会随机变化。
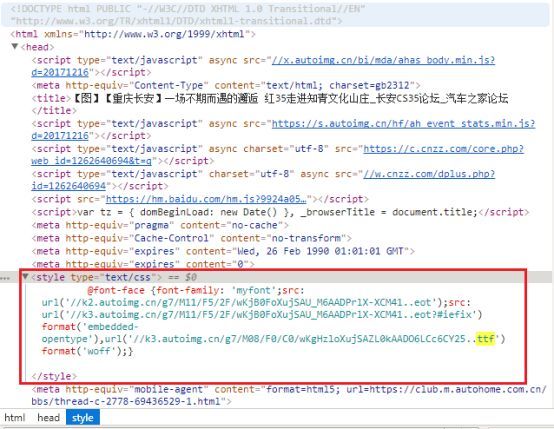
我们访问其中ttf文件的地址,可将ttf字体文件下载到本地。
字体文件博大精深,ttf文件是其中一种,为了解析该字体,在没有找到fonttools之前,找的很多代码都不能满足我这简单的解析需求,差点就准备看ttf规范定义自己编写解析代码了。此一坑。
三、字体解析
ttf就是我们常用的字体文件,可以使用系统自带的字体查看器查看,但是难以看到更多有效的信息,我们使用一个专用工具Font Creator查看。
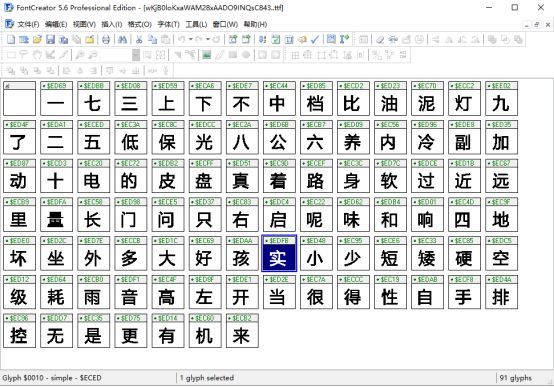
可以看到,这里不再是简单的数字混淆了,而是对一些中文文字进行了重新编码处理。这个字体里有91个字(含一个空白字),每个字显示其字形和其字形编码。比如上文中第一个显示的是,其编码是0xEC35,我们利用Notepad++查看复制的该不可见字符的十六进制编码是0xEEB0B5,

两者不一样,这是怎么回事。此又一坑!一顿查找,这其实分别是unicode编码和utf-8编码,
这样两者的关系就对应了,我们也知道页面查看正确但读取网页却无法获取文本的原因了。我们发现,论坛页面每次访问,字体是不变的,但字符编码是变化的。因此,我们需要根据每次访问动态解析字体文件。
接着一顿查找,好不容易找到一款专门解析font的python包,fonttools,

使用下面语句可以获取顺序的字符编码值,
# 解析字体库font文件
font = TTFont('autohome.ttf')
uniList = font['cmap'].tables[0].ttFont.getGlyphOrder()
四、内容替换
关键点攻破了,整个工作就好做了。先访问需要爬取的页面,获取字体文件的动态访问地址并下载字体,读取用户帖子文本内容,替换其中的自定义字体编码为实际文本编码,就可复原网页为页面所见内容了。
完整代码如下:
# -*- coding:utf-8 -*-
import requests
from lxml import html
import re
from fontTools.ttLib import TTFont
#抓取autohome评论
class AutoSpider:
#页面初始化
def __init__(self):
self.headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.8",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36"
}
# 获取评论
def getNote(self):
url = "https://club.autohome.com.cn/bbs/thread-c-2778-69436529-1.html"
host = {'host':'club.autohome.com.cn',
'cookie':'your cookie'}
headers = dict(self.headers.items() + host.items())
# 获取页面内容
r = requests.get(url, headers=headers)
response = html.fromstring(r.text)
# 匹配ttf font
cmp = re.compile(",url\('(//.*.ttf)'\) format\('woff'\)")
rst = cmp.findall(r.text)
ttf = requests.get("http:" + rst[0], stream=True)
with open("autohome.ttf", "wb") as pdf:
for chunk in ttf.iter_content(chunk_size=1024):
if chunk:
pdf.write(chunk)
# 解析字体库font文件
font = TTFont('autohome.ttf')
uniList = font['cmap'].tables[0].ttFont.getGlyphOrder()
utf8List = [eval("u'\u" + uni[3:] + "'").encode("utf-8") for uni in uniList[1:]]
wordList = ['一', '七', '三', '上', '下', '不', '中', '档', '比', '油', '泥', '灯',
'九', '了', '二', '五', '低', '保', '光', '八', '公', '六', '养', '内', '冷',
'副', '加', '动', '十', '电', '的', '皮', '盘', '真', '着', '路', '身', '软',
'过', '近', '远', '里', '量', '长', '门', '问', '只', '右', '启', '呢', '味',
'和', '响', '四', '地', '坏', '坐', '外', '多', '大', '好', '孩', '实', '小',
'少', '短', '矮', '硬', '空', '级', '耗', '雨', '音', '高', '左', '开', '当',
'很', '得', '性', '自', '手', '排', '控', '无', '是', '更', '有', '机', '来']
# 获取发帖内容
note = response.cssselect(".tz-paragraph")[0].text_content().encode('utf-8')
print note
print '---------------after-----------------'
for i in range(len(utf8List)):
note = note.replace(utf8List[i], wordList[i])
print note
注意,wordList直接写'一',不需要写u'一',因为note和utf8List[i]均是str类型,wordList也应是str类型,而不应是unicode类型,否则会报错。此再一坑。
五、参考文章
1、爬虫与诡异的字体 (https://zhuanlan.zhihu.com/p/28183190)
2、fonttools源码 (https://github.com/fonttools/fonttools)
3、ttf文件结构解析
(https://www.cnblogs.com/sjhrun2001/archive/2010/01/19/1651274.html)
附录
字体反爬破解实践源代码:点这里,密码:gxf7