法研杯比赛总结
比赛已经结束好久了,准备来总结一下。

比赛结果:
队名shelley,做了任务一和任务二,排名如下:


任务一和任务二差不多,任务三有离散标签和连续标签,效果不太好,期待大牛的分享。
自己的模型使用attention和Textcnn。
整个处理流程如下:
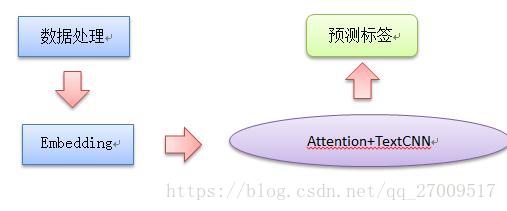
1. 文本预处理
去除地名,人名,一般停用词。
人名

地名,分词好后,根据特定的字过滤。
fact_str = re.sub(r'\r', '', fact_str)
fact_str = re.sub(r'\t', '', fact_str)
fact_str = re.sub(r'\n', '', fact_str)
fact_str = re.sub(r'([0-9]{4}年)?[0-9]{1,2}月([0-9]{1,2}日)?', '', fact_str)
fact_str = re.sub(r'[0-9]{1,2}时([0-9]{1,2}分)?许?', '', fact_str)
cut_list = jieba.cut(fact_str)
for w in cut_list:
if w in stopwords:
continue
elif '省' in w:
continue
elif '市' in w:
continue
elif '镇' in w:
continue
elif '村' in w:
continue
elif '路' in w:
continue
elif '县' in w:
continue
elif '区' in w:
continue
elif '城' in w:
continue
elif '府' in w:
continue
elif '庄' in w:
continue
elif '道' in w:
continue
elif '车' in w:
continue
elif '店' in w:
continue
elif '某' in w:
continue
elif '辆' in w:
continue
elif '房' in w:
continue
elif '馆' in w:
continue
elif '场' in w:
continue
elif '街' in w:
continue
elif '墙' in w:
continue
elif '牌' in w:
continue
else:
fact_list.append(w)2. 模型
2.1 attention
等有空再写
2.2 TextCNN
等有空再写
3. 模型评价函数
# -*- coding:utf-8 -*-
from __future__ import division
import numpy as np
def sigmoid(X):
sig = [1.0 / float(1.0 + np.exp(-x)) for x in X]
return sig
def to_categorical_single_class(cl):
y = np.zeros(183)
for i in range(len(cl)):
y[cl[i]] = 1
return y
def cail_evaluator(predict_labels_list, marked_labels_list):
# predict labels category
predict_labels_category = []
samples = len(predict_labels_list)
print('num of samples: ', samples)
for i in range(samples): # number of samples
predict_norm = sigmoid(predict_labels_list[i])
predict_category = [1 if i > 0.5 else 0 for i in predict_norm]
predict_labels_category.append(predict_category)
# marked labels category
marked_labels_category = []
num_class = len(predict_labels_category[0])
print('num of classes: ', num_class)
for i in range(samples):
marked_category = to_categorical_single_class(marked_labels_list[i])
marked_labels_category.append(marked_category)
tp_list = []
fp_list = []
fn_list = []
f1_list = []
for i in range(num_class): # 类别个数
tp = 0.0 # predict=1, truth=1
fp = 0.0 # predict=1, truth=0
fn = 0.0 # predict=0, truth=1
# 样本个数
pre = [p[i] for p in predict_labels_category]
mar = [p[i] for p in marked_labels_category]
pre = np.asarray(pre)
mar = np.asarray(mar)
for i in range(len(pre)):
if pre[i] == 1 and mar[i] == 1:
tp += 1
elif pre[i] == 1 and mar[i] == 0:
fp += 1
elif pre[i] == 0 and mar[i] == 1:
fn += 1
# print('tp: %s, fp: %s, fn:%s ' %(tp, fp, fn))
precision = 0.0
if tp + fp > 0:
precision = tp / (tp + fp)
recall = 0.0
if tp + fn > 0:
recall = tp / (tp + fn)
f1 = 0.0
if precision + recall > 0:
f1 = 2.0 * precision * recall / (precision + recall)
tp_list.append(tp)
fp_list.append(fp)
fn_list.append(fn)
f1_list.append(f1)
# micro level
f1_micro = 0.0
if sum(tp_list) + sum(fp_list) > 0:
f1_micro = sum(tp_list) / (sum(tp_list) + sum(fp_list))
# macro level
f1_macro = sum(f1_list) / len(f1_list)
score12 = (f1_macro + f1_micro) / 2.0
return f1_micro, f1_macro, score12
部分代码可以参考我的github:https://github.com/shelleyHLX/cail
参考文献
(1)TextCNN:
Kim Y. Convolutional Neural Networks for Sentence Classification[J]. Eprint Arxiv, 2014.
Conneau A, Schwenk H, Barrault L, et al. Very Deep Convolutional Networks for Text Classification[J]. 2017:1107-1116.
Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[J]. 2014:1-9.
(2)Attention:
Yang Z, Yang D, Dyer C, et al. Hierarchical Attention Networks for Document Classification[C]// Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2017:1480-1489.