1. 从贝叶斯方法(思想)说起 - 我对世界的看法随世界变化而随时变化
用一句话概括贝叶斯方法创始人Thomas Bayes的观点就是:任何时候,我对世界总有一个主观的先验判断,但是这个判断会随着世界的真实变化而随机修正,我对世界永远保持开放的态度。

1763年,民间科学家Thomas Bayes发表了一篇名为《An essay towards solving a problem in the doctrine of chances》的论文,
这篇论文发表后,在当时并未产生多少影响,但是在20世纪后,这篇论文逐渐被人们所重视。人们逐渐发现,贝叶斯方法既符合人们日常生活的思考方式,也符合人们认识自然的规律,经过不断的发展,最终占据统计学领域的半壁江山,与经典统计学分庭抗礼。
让我们暂时回到Thomas Bayes所处的学术时代18世纪,来一起体会下贝叶斯的思想。
当时数理统计的主流思想是“频率学派”。所谓频率学派,举个例子来说:“有一个袋子,里面装着若干个白球和黑球(例如3黑2白),请问从袋子中取得白球的概率θ是多少?
频率派把需要推断的参数θ看做是固定的未知常数,即概率虽然是未知的,但最起码是确定的一个值。同时,样本X是随机的,所以频率派重点研究样本空间,大部分的概率计算都是针对样本X的分布。
这种观点看起来确实没有什么问题,也很合理。但是我们仔细深度思考一下就会发现一个重大问题。
频率学派之所以能够得到这种确定性,是因为研究的对象是“简单可数事件”,例如装有固定数量球的袋子、只有正反两面的硬币、只有6面的标准筛子。但是当研究的问题变得复杂之后,频率理论就无法处理了。
例如一个朋友创业,你现在需要估计他创业成功的几率有多大?
这个时候你就无法逐一枚举出导致他成功或者失败的所以子原因了(做法有方法?思路清晰?有毅力?能团结周围的人?和其他竞争对手相比,好多少?....),这是一个连续且不可数的事件空间。
“贝叶斯学派”的观点和频率学派则截然相反,贝叶斯学派认为参数是随机变量,是未知的。而样本X是固定的,由于样本是固定的,所以他们重点研究的是参数的分布。
用贝叶斯学派的理论来回答上面创业者评估问题,假如你对这个创业者为人比较了解,你会不由自主的估计他创业成功的几率可能在80%以上,这是一个先验的概率估计。随着公司的运营,你发现公司被运营的非常差,业绩也不行,随即,你对这个创业者的成功估计由80%下调到40%,这是一个后验概率估计。贝叶斯学派的这种动态的概率估计思维,就是贝叶斯方法。
为了能够动态地对真实世界进行概率估计,贝叶斯及贝叶斯派提出了一个思考问题的固定模式:
先验分布![]() + 样本信息(观测结果)
+ 样本信息(观测结果)![]()
![]() 后验分布
后验分布![]()
上述思考模式意味着,新观察到的样本信息将修正人们以前对事物的认知。换言之,在得到新的样本信息之前,人们对的认知是先验分布,在得到新的样本信息![]() 后,人们对的认知为后验估计
后,人们对的认知为后验估计![]() 。
。
笔者思考:
写到这里的时候,笔者联想到牛顿宏观第一定律和爱因斯坦的相对论之间的关系,在宏观世界,牛顿第一定律是有效的,但是进入高速微观世界,就只能用更抽象的相对论来概括了。牛顿第一定律只是相对论在宏观低速世界的一个特例。
同样,对简单问题来说,因为事件空间有限可数,所以频率理论是成立的,但是对于真实世界的复杂问题,事件空间是连续不可数的,就需要用到贝叶斯理论来概括描述了。
Relevant Link:
《概率图模型:原理与技术》DaphneKoller https://github.com/memect/hao/blob/master/awesome/bayesian-network-python.md
2. 一些背景知识
在本章中,我们回顾一些重要的背景材料,这些材料源自概率论、信息论和图论中的一些关键知识,它们都是贝叶斯网的重要概念组成部分。
0x1:条件概率公式
条件概率(又称后验概率)就是事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为P(A|B),读作“在B条件下A的概率”,
![]()
- 联合概率:表示两个事件共同发生的概率。A与B的联合概率表示为
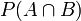 或者
或者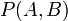
- 边缘概率(又称先验概率):是某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中那些不需要的事件通过合并成它们的全概率,而消去它们(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率),这称为边缘化(marginalization),比如A的边缘概率表示为P(A),B的边缘概率表示为P(B)。
0x2:全概率公式和贝叶斯概率公式
基于条件概率公式,我们可以继续推导出贝叶斯公式。关于这个话题,笔者在另一个文章中进行了详细的总结,这里不再赘述,为了保持文章自包含性,这里摘取部分笔者认为关键的部分。

全概率公式
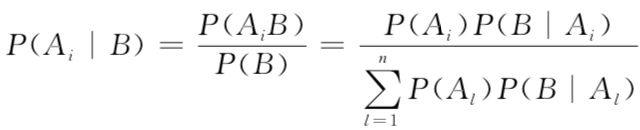
贝叶斯公式
将其和全概率公式进行对比。会发现以下几点:
- 贝叶斯公式的分子和全概率公式的分解子项是相同的
- 贝叶斯公式的分母等于全概率公式的累加和
笔者认为,贝叶斯公式可以这么理解:贝叶斯公式表达了一个思想,根据某个出现的结果B可以反推所有可能导致该结果的子原因Ai,而具体根据结果B逆推出每个子原因的条件概率比重,则取决于这个子原因和结果B的联合概率 ,这是从结果推原因的逆概率计算问题。
0x3:随机变量的链式法则(chain rule)
根据条件概率的定义,我们有:
![]()
更一般地,如果a1,....,ak是事件,那么有如下链式分解式,
![]()
这个等式称为条件概率的链式法则(chain rule)。 换句话说,我们可以将几个事件组合的概率表示为关于事件之间的递归式依赖关系的乘积。值得注意的是,我们可以用事件的任意顺序来扩展这个表达式而保持结果不变。
链式法则是一个非常有用的定理,它是贝叶斯网中的核心概念,因为贝叶斯网面对和描述的都是复杂事件。一个复杂事件往往是由大量子事件组成的,不同的子事件间既存在独立关系,也存在关联依赖关系。链式法则提供了一个理解复杂事件的世界观,即复杂事件是可以分解的。
0x4:随机变量的独立性
关于独立性,有一个很形象直观的例子。假设一个思想实验:如果一个社会中存在一种广泛的思潮,即重男轻女思潮,90%的家庭都认为生男孩比生女孩好,只要生的不是男孩就是继续生,直到生了一个女孩为止。 以上为背景,经过10年后,请问社会中男女比率会失衡吗?
这个问题答案可能有些反直觉,答案是:不管经过多少年,社会中男女比例都保持50%的平衡比例。出现这个现象的原因是,每一胎生男生女都是等概率的,不以父母的意志为转移。
下面我们定义随机变量的独立性概念,
假如![]() 或者
或者![]() ,则称事件α和事件β,则称事件α和事件β在P中独立,记为
,则称事件α和事件β,则称事件α和事件β在P中独立,记为![]() 。
。
- 从条件熵的角度解释独立性,事件α和事件β在P中独立,意味着事件事件β对事件α的不确定性不提供额外的信息。
- 从条件概率的角度,我们还可以给出独立性概念的另一种定义,即分布P满足
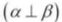 ,当且仅当
,当且仅当 。证明过程如下,
。证明过程如下,
- 使用链式法则,
 ,由于α和β独立,所以
,由于α和β独立,所以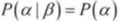 ,因此,
,因此, ,所以有,
,所以有,
- 使用链式法则,

-
- 从该公式可以看到,独立性是一个对称的概念,即意味着
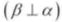 。
。
- 从该公式可以看到,独立性是一个对称的概念,即
我们需要明白的是,在大多数实际的应用中,随机变量并不是边缘独立的,尽管如此,这种方法的一般形式将是我们求解的基础。
0x5:随机变量条件独立性
关于条件独立性,笔者通过一个具体的例子来直观说明。我们假定学生的GPA成绩为随机变量G,被Stanford录入为随机变量S,被MIT录取为随机变量M。很显然,我们会得到下列几个分布判断:
- 零先验下条件依赖:”被MIT录取M“和”被Stanford录取S“之间并不相互独立,如果已知一个学生已经被Stanford录取,那么我们对她被MIT录取的概率的估计就会提高,因为”被Stanford录取S“潜在说明了她是一个智商高有前途的学生。换句话说,”被Stanford录取S“这个事实给”被MIT录取M“输入了额外的有效信息熵。
- 给定额外事件下条件独立:现在假定两所大学仅根据学生的GPA作决定,并且已知学生的GPA是A。在这种情况下,”被Stanford录取S“和”被Stanford录取S“之间就完全独立了。换句话说,在已知GPA的情况下,”被Stanford录取S“对”被Stanford录取S“的推断没有提供任何有效的信息熵,这个现象在贝叶斯网中被称作局部独立性。用条件概率公式表述上面这句话就是
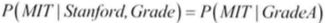 ,对于这种情况,我们说在给定Grade条件下,MIT与Stanford条件独立。
,对于这种情况,我们说在给定Grade条件下,MIT与Stanford条件独立。
下面我们形式化地定义事件之间条件独立性的概念,
假如![]() ,或者
,或者![]() ,则称事件α在给定事件Υ时,在分布P中条件独立于事件β,记作
,则称事件α在给定事件Υ时,在分布P中条件独立于事件β,记作![]() 。
。
进一步地有,P满足![]() 当且仅当
当且仅当![]() 。
。
现在我们将概念引申到随机变量的范畴内,关注随机变量间的条件独立性。
令X,Y,Z表示随机变量,如果P满足![]() ,则称集合X与Y在分布P中条件独立,集合Z中的变量称为观测(observed)变量。观测(observation)这个词很能引起我们的思考,我们看到,在不同的观测下,随机变量的条件独立性发生了改变,这正是体现了贝叶斯思想的精髓。
,则称集合X与Y在分布P中条件独立,集合Z中的变量称为观测(observed)变量。观测(observation)这个词很能引起我们的思考,我们看到,在不同的观测下,随机变量的条件独立性发生了改变,这正是体现了贝叶斯思想的精髓。
特别的,如果集合Z是空集,可以把![]() 记作
记作![]() ,并且称X与Y是边缘独立的(marginally independent)。
,并且称X与Y是边缘独立的(marginally independent)。
0x6:查询一个概率分布
我们基于贝叶斯网进行的一个常见应用是,利用多维随机变量的联合概率分布来完成推理查询。
1. 概率查询
概率查询是最常见的查询,查询由两部分组成,
- 证据(条件):模型中随机变量的子集E,以及这些变量的实例e
- 查询变量:网络中随机变量的子集Y
概率查询的任务是计算下式:
![]()
即,Y的值y上的后验概率分布取决于E=e,这个表达式也可以看作是以e为条件作用获得的分布中Y上的边缘。
2. 最大后验概率(MAP)查询
第二类重要任务是对变量的一些子集找到一个高概率的联合赋值。这类任务的最简单变形是MAP查询(最可能解释MPE),其目的是找到对所有(非证据)变量最可能的赋值。
如果令![]() ,那么在给定证据
,那么在给定证据![]() 的条件下,我们的任务是为W中的变量找到最可能的赋值:
的条件下,我们的任务是为W中的变量找到最可能的赋值:
![]()
其中的![]() 表示使得
表示使得![]() 最大的值。
最大的值。
0x7:图
把图作为一种数据结构来表示概率分布在贝叶斯网的一个重要概念,我们这节讨论一些图的基本概念。
1. 节点与边
图是一个包含节点(node)集与边(edge)的数据结构![]() 。
。
假定节点集为![]() ,节点对 Xi 与 Xj 由一条有向边(directed edge)Xi -> Xj 或者一条无向边(undirected edge)Xi - Xj 连接。因此,边集
,节点对 Xi 与 Xj 由一条有向边(directed edge)Xi -> Xj 或者一条无向边(undirected edge)Xi - Xj 连接。因此,边集![]() 是成对节点的集合,图通过二元关系来存所有边的连接关系。
是成对节点的集合,图通过二元关系来存所有边的连接关系。
因此,图按照边集的类型,可以分为:
- 有向图(directed graph):通常记作
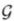 。
。 - 无向图(undirected graph):通常记作
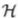 ,通过忽略边的方向,有向图可以转换为无向图。
,通过忽略边的方向,有向图可以转换为无向图。
我们用![]() 来表示 Xi 与 Xj 经由某种边连接的情形,这条边或者是有向的,或者是无向的。
来表示 Xi 与 Xj 经由某种边连接的情形,这条边或者是有向的,或者是无向的。
下图是部分有向图![]() 的一个例子,
的一个例子,

其中,
- A是C的唯一父节点
- F,I 是C的子节点
- C的唯一邻节点是D
- A,D,F,I 均与C相邻
2. 子图
很多时候,我们希望只考虑与节点的特定子集相关的部分图。
1)导出子图
令![]() ,且令
,且令![]() ,导出子图(induced subgraph)
,导出子图(induced subgraph)![]() 定义为图
定义为图![]() ,其中,
,其中,![]() 表示使得
表示使得![]() 的所有边
的所有边![]() 。例如下图表示的是导出子图
。例如下图表示的是导出子图![]() ,
,

2)完全子图
如果X中的任意两个节点均由一条边连接,那么X上的子图是完全子图(complete subgraph)。集合X通常称为团(clique)。对于节点的任意超集![]() ,如果Y不是团,那么X称为最大团(maximal clique)。
,如果Y不是团,那么X称为最大团(maximal clique)。
尽管理论上说,节点子集X可以是任意的,但我们一般只对能够保持图结构的特定性质的节点集感兴趣。
3. 路径与迹
利用边的基本符号,可以在图中对不同类型的长范围连接进行定义。
1)路径(path)
对每一个 i=1,...,k-1,如果 Xi -> Xi+1,或者 Xi - Xi+1,那么 X1,....,Xi 在图![]() 中形成了一条路径(path)。如果一条路径中至少存在一个 i,使得 Xi -> Xi+1,则称该路径是有向的。
中形成了一条路径(path)。如果一条路径中至少存在一个 i,使得 Xi -> Xi+1,则称该路径是有向的。
2)迹(trail)
对于每个 i=1,...,k-1,如果![]() ,那么 X1,....,Xi 在图
,那么 X1,....,Xi 在图![]() 中形成一条迹(trail)。
中形成一条迹(trail)。
迹是比路径更弱的约束条件,迹必定是路径,但路径不一定成为迹。
例如下图中,
- A,C,D,E,I 是一条路径,因此也是一条迹
- A,C,F,G,D 是一条迹,但不是一条路径
3)连通图(connected graph)
对于图中的任意节点 Xi,Xj,如果 Xi 和 Xj 之间存在一条迹,那么该图是连通图。
4. 圈(cycle)
1)无圈图
图![]() 中的一个圈是一条有向路径 X1,....,Xk,其中 X1 = Xk。如果一个图不包含圈,那么这个图是无圈图(acyclic graph)。需要注意的是,在存在有向圈的图上定义一个一致的概率模型十分困难,因此机器学习中大部分的图算法都是假设图是无圈的。
中的一个圈是一条有向路径 X1,....,Xk,其中 X1 = Xk。如果一个图不包含圈,那么这个图是无圈图(acyclic graph)。需要注意的是,在存在有向圈的图上定义一个一致的概率模型十分困难,因此机器学习中大部分的图算法都是假设图是无圈的。
有向无圈图(directed acyclic graph,DAG)是构成贝叶斯网的基本图表示。
下图是一个无圈图,
但是只要为图中添加一条无向边 A-E,就可以获得一条从A到自身的路径A,C,D,E,A。
注意,圈是针对路径的概念而言的,无圈并不代表从节点到自身不会有迹,例如上图中,包含了 C,D,E,I,C 和 C,D,G,F,C 这两条迹。
2)部分有向无圈图(partially directed acyclic graph,PDAG)
一个包含有向边和无向边的无圈图称为部分有向无圈图,PDAG上无圈的要求意味着图可以被分解为一些链分支(chain component)的有向图,其中,每条链分支内的节点相互之间仅通过无向边链接。
PDAG的无圈性保证我们可以对分支进行排序,进而使得所有的边由数值低的分支指向数值高的分支。
3)链分支(chain component)
令![]() 是
是![]() 上的PDAG,K1,....,Ki 是
上的PDAG,K1,....,Ki 是![]() 的满足如下条件的不相交划分:
的满足如下条件的不相交划分:
- Ki 的导出子图不包含有向边。
- 对 i
 ,X与Y之间的边仅仅是有向边 X->Y。
,X与Y之间的边仅仅是有向边 X->Y。
满足以上条件时,每一个分支 Ki 称为一个链分支。同时由于其链结构,PDAG也称为链图(chain graph)。
还是对上面的图例子,我们来看一下链分支分解结果,
上图中共有六个链分支:
- {A}
- {B}
- {C,D,E}
- {F,G}
- {H}
- {I}
特别的,当PDAG是一个无向图时,整个图形成了一个单链分支。相反地,如果PDAG是一个有向图(无圈的),那么图中的每一个节点就是其本身的一个链分支。
笔者提醒:
链图这个概念非常重要,它和随机变量独立性原理一起,构成了贝叶斯网因子分解和局部独立性原理,也是贝叶斯网能够从原始的链式分解公式得到紧凑结构的理论基础。
5. 环(loop)
环是一个比圈更弱约束的结构,![]() 中的一个环是一条迹 X1,....,Xk,其中 X1 = Xk。如果一个图不包含任何环,那么这个图是单连通(singly connected)。如果一个节点在单连通图中只有一个相邻的节点,那么该节点是一个叶(leaf)节点。
中的一个环是一条迹 X1,....,Xk,其中 X1 = Xk。如果一个图不包含任何环,那么这个图是单连通(singly connected)。如果一个节点在单连通图中只有一个相邻的节点,那么该节点是一个叶(leaf)节点。
1)森林
如果有向图的每个节点至多只有一个父节点,那么这个有向图是森林。
2)树
如果有向图的每个节点至多只有一个父节点,且这个有向森林是连通的,那么它是一棵树。
3)多重树
一个单连通的有向图也称为一棵多重树(polytree)。注意,多重树与树非常不同,例如下图是多重树但不是树,因为有一些节点有不止一个父节点。
多重树例子
6. 弦(chord)
弦的定义在基于图结构的推理代价估计中扮演者非常重要的角色。
令 X1 - X2 - .... - Xk - X1 是图中的一个环。环中的一条弦(chord)是连接两个不连贯节点 Xi 与 Xj 的一条边。对 k>=4,如果任意环 X1 - X2 - .... - Xk - X1 有一条弦,那么无向图![]() 称为弦图(chordal graph)。
称为弦图(chordal graph)。
值得注意的是,在一个通弦的图中,最长的”最小环(一个没有捷径的环)“是一个三角形。因此,弦图通常也称为三角剖分图(triangulated graph)。
进一步的,如果图![]() 的基础无向图是通弦的,则称图
的基础无向图是通弦的,则称图![]() 是通弦的。
是通弦的。
Relevant Link:
《概率图模型:原理与技术》DaphneKoller
3. 贝叶斯网原理
0x1:什么是贝叶斯网络
- 贝叶斯网络(Bayesian network),又称信念网络(Belief Network),或有向无环图模型(directed acyclic graphical model),是一种概率图模型,于1985年由Judea Pearl首先提出。是一种帮助人们将概率统计应用于复杂领域、进行不确定性推理和数值分析的工具。
- 贝叶斯网是一种系统地描述随机变量之间关系的语言,它模拟了人类推理过程中因果关系的不确定性。
- 贝叶斯网是概率论与图论结合的产物,一方面用图论的语言直观揭示问题的结构,另一方面按概率论的原则对问题结构加以利用,本质上其网络拓朴结构是一个有向无环图(DAG)。
- 许多经典多元概率模型都是贝叶斯网的特例,例如朴素贝叶斯模型、马尔柯夫链、隐马尔科夫模型、卡尔曼滤波器、条件随机场等
0x2:为什么需要贝叶斯网络
在开始介绍贝叶斯网概念之前,我们先来一个讨论一下学者们提出贝叶斯网的学术动机,笔者将其总结为下面几句话:
- 不确定性推理
- 高维稀疏表征问题:利用条件独立降低复杂度
- 局部概率模型(local probability model):贝叶斯网的因子分解
- 有限状态转移的动态贝叶斯过程:因果推理与证据推理
1. 不确定性推理
所谓不确定性推理,是指基于概率论对真实世界进行抽象建模以及数值分析,使用概率分布而不是精确数值的方式进行有效预测。常规的不确定性推理过程如下,
- 把问题用一组随机变量 X = {X1, X2, . . . , Xn} 来刻画
- 把关于问题的知识表示为一个联合概率分布 P(X)
- 按概率论原则进行推理计算
2. 利用条件独立降低复杂度
根据全概率公式和链式法则我们知道,每个随机事件都可以分解为大量的子事件原因的累乘,且子事件原因之间还存在大量的递归依赖,
![]()
这样,假设我们的目标是在某个随机变量的集合![]() 上表示联合分布P,即使在变量为二值(binary-valued)这样最简单的情况下,n个变量的联合分布也需要
上表示联合分布P,即使在变量为二值(binary-valued)这样最简单的情况下,n个变量的联合分布也需要![]() 个不同赋值的概率。当n较大时,这种联合分布的显示表示和样本学习都会变得非常难处理。
个不同赋值的概率。当n较大时,这种联合分布的显示表示和样本学习都会变得非常难处理。
- 从计算的角度,操作的成本非常昂贵,并且也很难在内存中存储
- 从机器认知的角度,我们不可能从专家那里获得如此多的数值。而且,这些数值非常小并且不能与人们可以合理思考的事件一一对应
- 从统计的角度,如果希望从数据中学习出分布,需要有规模非常庞大的数据才能可靠地估计出这么多的自由参数,否则会遇到欠拟合问题
但是实际上,正如我们前面介绍举例的,对于一个好学生来说,考上Stanford和考上MIT这两件事之间是独立的,条件概率和边缘概率是相同的。因此,贝叶斯网络基于随机变量间独立性原理,对去全概率公式进行了有效的化简,得到了一个更紧凑的高维分布。这对我们建模复杂性事件提供了条件,例如下图,
学生示例的贝叶斯网图
可以以两种不同的方式来看待这个图:
- 它是提供了以因子分解的方式紧凑表示联合分布骨架的数据结构
- 它是关于一个分布的一系列条件独立性假设的紧凑表示
在严格意义上,这两种观点是等价的。
注意到,贝叶斯网用边表示直接依赖关系,如果在真实世界中A只依赖于B,则只应该存在一条从B通向A的有向边。节点只直接依赖其父节点,是贝叶斯网语义的核心。
3. 基于局部概率模型表示成对的因果推理
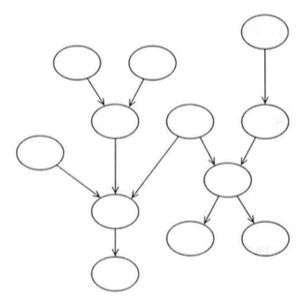
为了说明这个概念,我们继续引用学生示例,
这个问题包含五个随机变量:
- 学生的智商(I)
- 课程的难度(D)
- 考试的成绩(G)
- 学生的SAT成绩(S)
- 推荐信的质量(L)
我们知道,贝叶斯网可以用有向图来表示,其节点表示随机变量,而边则表示一个变量对另一个变量的直接影响(现实世界运行方法的直观假设)。我们可以将这个图看成是对一个由自然执行的生成式采样过程进行编码,其中,每个变量的值指取决于其父节点的分布自然选择。换句话说,每个变量是其父节点的一个随机函数(局部条件概率性质)。
换句话来说,局部条件概率性质来源于问题域本身的:
- 学生的成绩不仅取决于他的智商(I),同时也取决于课程的难度(D)
- 学生请求教授为其学推荐信,不过教授健忘并且从来记不住学生的名字,所以教授通过查看学生的成绩,并依据这仅有的信息来为其写推荐信,推荐信的好坏用L表示,随机地依赖于考试的成绩
- SAT成绩仅仅取决于学生的智商,在智商(I)已知的情况下,SAT成绩(S)和课程成绩(G)是独立的
我们将贝叶斯网中包含的这种局部的条件概率结构称之为局部概率模型(local probability model),用于表示每个变量对其父节点依赖的本质。
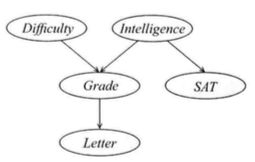
对于这个问题,条件概率分布的一个可能选择如下图所示,这个网络结构与条件概率分布一起组成了贝叶斯网![]() ,
,
带有条件概率分布的学生示例的贝叶斯网
具体的,考虑空间中的一些特定状态,比如![]() ,直观上,这个事件的概率可以通过计算构成它的基本事件的条件概率乘积获得,即:
,直观上,这个事件的概率可以通过计算构成它的基本事件的条件概率乘积获得,即:
![]()
一般地,对于联合概率空间中的任何状态,可以采用相同的过程,即:
![]()
上述本质上是一个概率查询(推理)过程。
4. 有限状态转移的动态贝叶斯过程
1)因果推理
所谓的“推理”,顾名思义是一个根据当前获得的证据动态变化条件概率的过程。现在考虑贝叶斯网![]() ,并且观察当证据获得时各种事情的概率如何动态地发生变化。
,并且观察当证据获得时各种事情的概率如何动态地发生变化。
以某个学生George为例,用获得的模型对George进行推理。我们可能想要询问George有多大可能从教授Econ101的教授那里获得一封好的推荐信(l1)。现在我们开始动态贝叶斯推理:
- 在对George和Econ101的其他情况一无所知的条件下,P(l1)=50.2%。更精确地,令
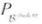 为根据前述贝叶斯网(BN)定义的联合分布,那么
为根据前述贝叶斯网(BN)定义的联合分布,那么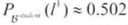 。
。 - 现在我们了解到George不太聪明(i0),现在George从教授Econ101课程的教授那里获得一封好的推荐信的概率降低到大约38.9%,即
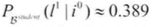 。
。 -
现在我们进一步得知Econ101是一门简单的课程(d0),此时,George从教授那里获得一封好的推荐信的概率是
 。
。 -
注意到上面两步的动态推理,都是基于我们不知道George的成绩Grade前提下,即head-to-head的关键节点未知,如果Grade已知,智商和课程难度就会独立,互不影响。
这类可以预测各种因素(如George的智商)“顺流而下”影响的概率查询,我们称之为因果推理(causal reasoning)或者预测(prediction)。
2)证据推理
现在考虑Acme咨询公司的一个招聘官,他试图贝叶斯网决定是否雇佣George,我们开始动态贝叶斯推理:
- 先验知识是,招聘官相信George有30%的可能有高智商。
- 之后,他拿到了George在Econ101上的成绩记录为C(g3),此时,招聘官对George有高智商的概率降至7.9%,即
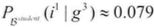 ,同时,课程困难度的概率也从40%上升到62.9%,因此我们有理由相信是因为课程太难导致George没有取得高分。
,同时,课程困难度的概率也从40%上升到62.9%,因此我们有理由相信是因为课程太难导致George没有取得高分。 -
现在,假定招聘官不小心丢失了George的成绩单,关于George的信息只剩下来自其Econ101课程教授的推荐信,不过这封信不是一个好的推荐信,此时,George有高智商的概率依然会降低,但只降至14%,即
 。我们看到,节点距离越近,信息传递的影响就越大,这也符合马尔科夫过程的熵传递原理。
。我们看到,节点距离越近,信息传递的影响就越大,这也符合马尔科夫过程的熵传递原理。 -
同时我们注意到,如果招聘官既有成绩单又有推荐信,George有高智商的概率与招聘官只有成绩单时的概率是一样的,
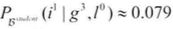 。原因是在head-to-tail结构下,如果关键节点已知,则head与tail之间是条件独立的。
。原因是在head-to-tail结构下,如果关键节点已知,则head与tail之间是条件独立的。 - 最后,George向招聘官提交了他的SAT成绩,他的SAT成绩很高,George有高智商的概率戏剧性地从7.9%又上升到了57.8%,,即
 。产生这个现象的原因是,与不好的考试成绩相比,SAT高分更有价值,因为低智商的学生在SAT考试中获得高分的可能性非常低,远远低于Econ101课程考试,也可以通俗地说“SAT考试成绩更硬”。同时,因为高智商的学生在困难的课程中更可能获得C,所有现在Econ101是一门困难的课程的概率已经从62.9%提高了76%左右。
。产生这个现象的原因是,与不好的考试成绩相比,SAT高分更有价值,因为低智商的学生在SAT考试中获得高分的可能性非常低,远远低于Econ101课程考试,也可以通俗地说“SAT考试成绩更硬”。同时,因为高智商的学生在困难的课程中更可能获得C,所有现在Econ101是一门困难的课程的概率已经从62.9%提高了76%左右。
这类从结果推理原因的“逆流而上”的概率查询,我们称之为证据推理(evidential reasoning)或解释(explanation)。
3)因果间推理一般模式
我们知道,课程难度D,课程成绩G,智商I,它们之间是head-to-head的拓朴结构。
如果George在Econ101中得到的成绩是B,那么![]() 。另一方面,如果Econ101比较难,那么
。另一方面,如果Econ101比较难,那么![]() 。
。
实际上我们已经通过课程的难度解释消除(explaining away)了成绩低这一事件带来的影响。解释消除是称为因果间推理(intercausal reasoning)的一般推理模式的一个示例。其中相同结果的不同原因之间可以相互影响。 在这里,因为Grade已知,所以D和I之间的信息影响流是通的,影响力可以沿着迹传递。
这类推理在人类日常的推理中是非常普遍的,例如,当发烧、咽喉痛,并且担心可能有单核细胞增多症时,如果告知只是得了流感,那么得单核细胞增多症的概率就会被消解下降。因为,患有流感为出现的针状提供了另一种解释,从而很大程度上降低了患有单核细胞增多症的概率。
笔者思考:
对上述这个理论可以有一个更加形象的理解方式,即河流类比,我们将新的证据带来的信息熵比作河流里的水,学生在某门课程上取得了不好的成绩就是一个有效信息熵,这个信息顺着G-I之间流动,使得高智商的后验概率下降。现在加入一个新的信息源是Econ101课程比较难,这个新的信息源就相当于一个新的水源,沿着D-G-I这个河道传播,和原来的G-I一起,共同综合决定了I的后验概率。
同样的,如果G是未知的,那就相当于这个河流中间是断开的,无论D如何都无法影响到I,I的后验概率只取决于G。
4)有限状态转移
另外一方面,贝叶斯网必须是有向无圈图。其中节点代表随机变量,节点间的边代表变量之间的直接依赖关系。
本质上因为贝叶斯网是对真实世界复杂性事件的抽象建模,所以不允许出现圈(即循环递归依赖)。简单来说就是不允许出现下列这种场景,
- A事件的发生依赖于B
- B事件的发生依赖于C
- C事件的发生依赖于D
- D事件的发生依赖于A
如果出现循环依赖,因果分解链式公式就会无限膨胀,也就无法用计算机处理。
0x3:贝叶斯网络的定义
贝叶斯网络的有向无环图中的节点表示随机变量,它们可以是可观察到的变量,或隐变量、未知参数等。
有因果关系(或非条件独立)的变量或命题,用箭头来连接。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(children)”,两节点就会产生一个条件概率值。
例如,假设节点E直接影响到节点H,即E->H,则用从E指向H的箭头建立结点E到结点H的有向弧(E,H),权值(即连接强度)用条件概率P(H|E)来表示,如下图所示:

一般地,贝叶斯网结构![]() 是其节点代表随机变量X1,....,Xn的一个有向无圈图(DAG)。令
是其节点代表随机变量X1,....,Xn的一个有向无圈图(DAG)。令![]() 表示Xi在
表示Xi在![]() 中的父节点,
中的父节点,![]() 表示Xi在图中的非后代节点变量。因此
表示Xi在图中的非后代节点变量。因此![]() 表示了如下称为局部独立性(local independencies)的条件独立性假设,并且记为
表示了如下称为局部独立性(local independencies)的条件独立性假设,并且记为![]() 。
。
对每个变量Xi,都有:
![]()
换句话说,局部独立性表明,在给定父节点条件下,每个节点Xi与其非后代节点条件独立。贝叶斯网图的形式化语义是一系列独立性断言。
如下图所示,便是一个简单的贝叶斯网络:
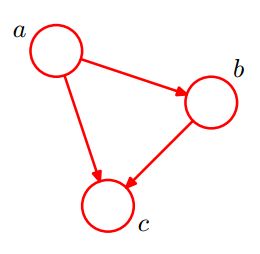
因为a导致b,a和b导致c,所以有下面累乘公式,
![]()
0x4:贝叶斯网络的典型结构形式
3节点对应的三角结构是贝叶斯网信息流动的最基本结构,这节我们来介绍几种经典的信息流动结构。
1. head-to-head(共同的作用)

根据上图我们有:P(a,b,c) = P(a) * P(b) * P(c|a,b)成立,化简后可得:

这种结构代表的意思是:
- c未知时:a、b被阻断(blocked),是独立的,称之为head-to-head条件独立。
- c已知时(或已知c的后代):a和b不独立,a的信息可以沿着c流向b。
我们可以形象地理解为,将abc想象成河流,两条小河(a、b)流入一条大河(c),当c是未知时,a->c<-b之间的流动是阻断的,那么影响将无法沿着“a->c<-b”流动。形如“a->c<-b”的这种结构也称为一个v-结构(v-structure)。
2. tail-to-tail(共同的原因)
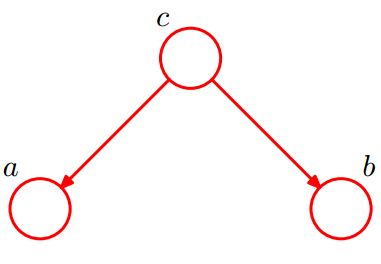
这种结构代表的意思是:
- c未知时:有:P(a,b,c)=P(c) * P(a|c) * P(b|c),此时,没法得出P(a,b) = P(a)P(b),即c未知时,a、b不独立,a可以通过c来影响b。
- c已知时:有:P(a,b|c)=P(a,b,c) / P(c),然后将P(a,b,c)=P(c) * P(a|c) * P(b|c)带入式子中,得到:P(a,b|c)=P(a,b,c)/P(c) = P(c)*P(a|c)*P(b|c) / P(c) = P(a|c)*P(b|c),即c已知时,a,b被阻断(blocked),a、b是独立的,称之为tail-to-tail条件独立。
我们可以形象地理解为,一条大河到某处分叉成两条支流,在c给定的条件下,a,b是两条独立的支流,彼此是独立的。
3. head-to-tail(因果迹)
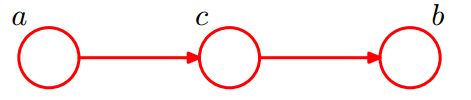
这种结构代表的意思是:
- c未知时:有:P(a,b,c)=P(a)*P(c|a)*P(b|c),但无法推出P(a,b) = P(a)P(b),即c未知时,a、b不独立。
- c已知时:有:P(a,b|c)=P(a,b,c)/P(c),且根据P(a,c) = P(a)*P(c|a) = P(c)*P(a|c),可化简得到:P(a,b|c) = P(a,b,c)/P(c) = P(a)*P(c|a)*P(b|c)/P(c) = P(a,c) * P(b|c) / P(c) = P(a|c) * P(b|c),即在c给定的条件下,a,b被阻断(blocked),是独立的,称之为head-to-tail条件独立。
4. tail-to-head(证据迹)

这种结构代表的意思是:
- c未知时:影响可以经过c从a流向b,a可以作为证据影响b的后验概率
- c已知时:在c给定的条件下,a,b被阻断,是独立的。
0x5:条件概率链式法则与局部独立性的统一
我们知道,贝叶斯网的形式化语义是一系列独立性断言,另一方面,贝叶斯网也是由一系列条件概率分布所组成的图,这个图通过链式法则为贝叶斯网定义了一个联合分布。
在本节中,我们将讨论它们二者的等价性。分布P满足于图![]() 相关的局部独立性,当且仅当P可以由与图
相关的局部独立性,当且仅当P可以由与图![]() 相关的一系列条件概率分布表示。
相关的一系列条件概率分布表示。
我们从形式化基本概念开始。
1. I-Map
首先我们定义与分布P相关的独立性的集合。
令P是![]() 上的分布,
上的分布,![]() 定义为在P中成立的形如
定义为在P中成立的形如![]() 的独立性断言的集合。
的独立性断言的集合。
现在可以将陈述“P满足与![]() 相关的局部独立性”简写为
相关的局部独立性”简写为![]() 。在这种情况下,可以称
。在这种情况下,可以称![]() 是P的一个I-map(独立图)。
是P的一个I-map(独立图)。
更一般的定义如下:
令![]() 是与独立性集合
是与独立性集合![]() 相关联的任意一个图对象,如果对独立性集合
相关联的任意一个图对象,如果对独立性集合![]() ,
,![]() ,则称
,则称![]() 是一个I-map。
是一个I-map。
2. I-map到因子分解
一个贝叶斯网![]() 蕴含了一系列条件独立性假设,这是我们能够用紧凑因子分解表示贝叶斯网的关键。一个特殊的例子就是朴素贝叶斯分解公式。
蕴含了一系列条件独立性假设,这是我们能够用紧凑因子分解表示贝叶斯网的关键。一个特殊的例子就是朴素贝叶斯分解公式。
考虑学生贝叶斯网![]() 的例子,
的例子,
先考虑任意分布P,我们将对联合分布进行分解并且将其分解成一些局部概率模型:
![]()
这种转换不依赖任何假设,它对任何联合分布P都适用。然而,因为等式右边的因子分解中的条件概率没有充分利用我们已知的独立依赖性信息,因此非常不紧凑。
现在,我们应用由贝叶斯网导出的条件独立性假设,假定![]() 关于分布P是一个I-map,我们得到下式:
关于分布P是一个I-map,我们得到下式:

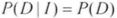
- 因为
 ,所以有
,所以有
综上,联合分布可化简为:
![]()
从上式可以看出,联合分布中的任何表值都可以通过每个变量所对应的因子的乘积来计算。每个因子表示表示一个变量在网络中给定父节点时的条件概率。在![]() 是I-map的条件下,这种因子分解可以应用于任何分布P。
是I-map的条件下,这种因子分解可以应用于任何分布P。
用形式化的语言来表达就是:
令![]() 未定义在变量X1,...,Xn上的一个贝叶斯网,假如P可以表示为如下乘积:
未定义在变量X1,...,Xn上的一个贝叶斯网,假如P可以表示为如下乘积:
![]()
则称分布P是关于图![]() 的在同一空间上的因子分解。这个等式称为贝叶斯网的链式法则。单个因子
的在同一空间上的因子分解。这个等式称为贝叶斯网的链式法则。单个因子![]() 称为条件概率分布(CPD)或局部概率模型。
称为条件概率分布(CPD)或局部概率模型。
贝叶斯网结构![]() 所蕴含的条件独立性假设允许我们将
所蕴含的条件独立性假设允许我们将![]() 是一个I-map的分布P分解成一系列较小的条件概率分布。
是一个I-map的分布P分解成一系列较小的条件概率分布。
0x6:d-分离概念
上一节我们讨论了联合分布的因子分解和局部独立性的统计概念。这个小节我们将其推广到整个贝叶斯网中,首先我们定义有效迹的概念。
1. 有效迹
考虑迹比较长的一般情况![]() 。直观上,对于从X1流动到Xn的影响,它需要流经这条迹上的单个节点。换句话说,如果每条双边迹
。直观上,对于从X1流动到Xn的影响,它需要流经这条迹上的单个节点。换句话说,如果每条双边迹![]() 都允许影响流过,那么X1可以影响到Xn。
都允许影响流过,那么X1可以影响到Xn。
对这一直观认识形式化定义如下:
令![]() 是一个贝叶斯网结构,且
是一个贝叶斯网结构,且![]() 是
是![]() 中的一条迹。令Z是观测变量的一个子集,在给定Z的条件下,如果满足下列条件:
中的一条迹。令Z是观测变量的一个子集,在给定Z的条件下,如果满足下列条件:
- 一旦有一个v-结构
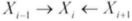 ,则Xi或其一个后代在Z中
,则Xi或其一个后代在Z中 - 迹上的其他节点都不在Z中
那么称迹![]() 是有效迹。
是有效迹。
2. d-分离(d-separation)
一般的,如果节点之间存在任何允许影响流过的迹,那么一个节点可以影响另一个节点。基于这个直观认识,可以定义d-分离的概念,这个概念为我们提供了在有向图的节点之间实现分离的能力。
形式化定义如下:
令X,Y,Z是图![]() 的三个节点集,在给定Z的的条件下,加入任意节点
的三个节点集,在给定Z的的条件下,加入任意节点![]() 与
与![]() 之间不存在有效迹,那么X与Y在给定Z时是d-分离的,记作
之间不存在有效迹,那么X与Y在给定Z时是d-分离的,记作![]() 。与d-分离相对应的独立性的集合用
。与d-分离相对应的独立性的集合用![]() 表示:
表示:
![]()
这个集合也称为全局马尔科夫独立性(global Markov independencies)集。![]() 中的独立性恰好是那些可以保证在
中的独立性恰好是那些可以保证在![]() 的每个分布中都成立的独立性。
的每个分布中都成立的独立性。
0x7:构建贝叶斯网结构的一般化方法
从上一章的条件概率链式公式化简过程我们可以看到,对于同一个独立性集合,与其相符的结构有很多。一个好的方法是选择能够反映真实世界的因果序列和依赖关系的结构,目的是使原因成为结果的父节点。
例如,在对汽车保险相关的贝叶斯网构建中,以前的事故(A)往往是好司机(G)的父节点,即“A->G”,这与保险公司对汽车保险这一问题的认知一致。同时,由于司机不好(B)才造成了以前(以及将来的)事故,即“B->A”。
一般来说,建模时我们可能会选择很多比较弱的影响,但如果将它们全部考虑进去,网络会变得非常复杂。这样的网络从表示的角度看是有问题的,它们难于理解、难于修正和学习。此外,由于贝叶斯网中的推理非常强地依赖于它们的连接功能,因此,增加这样的边无疑会使网络训练和预测的代价变得很高。
0x8:贝叶斯网学习(结构构件和参数估计)
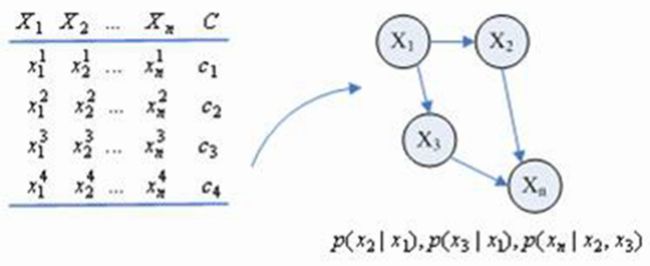
贝叶斯网的学习过程分为两部分:
- 结构学习:发现变量之间的图关系,构建贝叶斯网结构的一个一般方法是后向构建过程,该过程从我们感兴趣的一个变量开始,比如肺癌。然后尝试找到这个变量的先验因素,并将其添加为这个变量的父节点,这个过程称为对话扩展。例如,我们可以用这个过程来得出如下结论:
- 肺癌应该把吸烟作为其父节点
- 吸烟(可能,但不明显)应该把性别和年龄作为其父节点
- 参数学习:决定变量之间互相关联的量化关系,即估计贝叶斯网络的 CPD(条件概率分布) 表格中的数值。操作方法很简单,就是计算训练数据中事件发生的次数。例如要估计 p(SAT=s1|Intelligence=i1),我们只需要计算 SAT=s1 且 Intelligence = i1 的数据点在 Intelligence = i1 的数据点总量中所占的比例。
从数据中学习贝叶斯网络
0x9:贝叶斯网推理
所谓推理,就是要根据我们已知的信息做出预测。我们可以使用推理来解答一些问题:
1. 边际推理(marginal inference)
寻找一个特定变量的概率分布。比如,给定一个带有变量 A、B、C 和 D 的图,其中 A 取值 1、2 和 3,求 p(A=1)、p(A=2) 和 p(A=3)。
2. 后验推理(posterior inference)
给定某些显变量 v_E(E 表示证据(evidence)),其取值为 e,求某些隐藏变量 v_H 的后验分布 p(v_H|v_E=e)。
3. 最大后验(MAP)推理(maximum-a-posteriori inference)
给定某些显变量 v_E,其取值为 e,求使其它变量 v_H 有最高概率的配置。
Relevant Link:
《概率图模型:原理与技术》DaphneKoller http://staff.ustc.edu.cn/~jianmin/lecture/ai/bnet_slides.pdf https://zhuanlan.zhihu.com/p/30139208 https://www.zhihu.com/question/28006799 https://blog.csdn.net/v_JULY_v/article/details/40984699 http://staff.ustc.edu.cn/~jianmin/lecture/ai/bnet_slides.pdf
4. 贝叶斯网的一个特殊特例 - 马尔柯夫链
关于马尔柯夫链,笔者在另一篇文章有详细的讨论。简单来说,马尔柯夫链是一种基于“马尔科夫假设(marko assumption)”的动态贝叶斯网。
从网络结构的角度来说,马尔柯夫链是一个head-to-tail链式网络,如下图所示:

我们已经知道,在xi给定的条件下,xi+1的分布和x1,x2…xi-1条件独立。这意味着:xi+1的分布状态只和xi有关,和其他变量条件独立。
通俗地说,当前状态只跟上一状态有关,跟上上或上上之前的状态无关。这种顺次演变的随机过程,就叫做马尔科夫链(Markov chain)。且有:
![]()
可以看到,马尔柯夫链是一个特殊的贝叶斯网结构。
Relevant Link:
https://www.cnblogs.com/LittleHann/p/7609060.html#_lab2_2_1
5. 贝叶斯网的一个特殊特例 - 朴素贝叶斯模型
这章我们来描述一个最简单的例子,在这里例子中,条件参数化与条件独立性假设被结合在一起,目的是对高维概率分布产生非常紧凑的表示。
0x1:场景描述
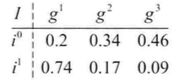
还是前面公司雇佣大学毕业生的例子,现在假定公司除了智商I和SAT成绩S之外,同时还知道学生某些课程的成绩G,在这种情况下,概率空间是定义在三个相关随机变量 I、S、G 上的联合分布。假定 I 与 S 如前所述,并且G可能取三个值g1,g2,g3,分别代表成绩A,B和C,那么联合分布有12个表值。
但是在这个例子中,我们发现了潜在的冗余结构,分布P满足条件独立性执行,即如果我们知道一个学生是高智商的,那么他在SAT考试中获得的高分并不能为我们带来任何有关他课程成绩的信息,形式化的表达为:
![]()
更一般的情况下,可以表达为:
![]()
注意到,这种独立性声明只有当假定学生的智商是其课程与SAT得分的唯一原因时才成立(tail-to-tail结构)。
基于条件独立性假设,我们可以得到一种更加紧凑的因果推理表达方式,
![]()
![]()
![]()
这样,联合分布P(I,S,G)可以分解为三个条件概率分布(CPD)的乘积。

作为一个整体,这3个条件概率分布详细说明了联合分布在条件独立性假设下的因果表示,例如:
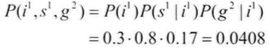
我们注意到,除了更紧凑的表达方式之外,基于条件独立性的因果表达方法的另一个好处是,模块性。当增加一个新的变量G时,联合分布在整体上会发生变化。而在因子表示中,我们可以重复使用变量I和S的局部概率模型,并且只需增加对新变量的条件概率P(G|I)即可。这个性质对于模拟真实系统非常有价值。
0x2:朴素贝叶斯模型(naive Bayes)
上个小节讨论的例子被称之为朴素贝叶斯模型。
朴素贝叶斯模型假设所有的实例属于若干两两互斥且包含所有事例情况的类(class)中的一个。因此,存在一个在某个集合{c1,...,ck}中取值的类变量C。在这个例子中,类变量是学生的智商I,并且存在且只存在事例的两个类(高智商和低智商)的学生。
模型还包括一定数量的、可以观测到其值的特征(feature)X1,....,Xk。朴素贝叶斯假设(naive Bayes assumption)是在给定事例的类的条件下,这些特征条件独立。换言之,在事例的每个类内,不同的性质可以独立地确定,形式化的表达为![]() 。
。
从网络结构上来说,朴素贝叶斯是一种典型的tail-to-tail的贝叶斯网结构,整个贝叶斯网都是由这种结构组成,
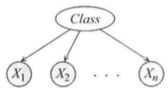
朴素贝叶斯模型的贝叶斯网
基于这些独立性假设,朴素贝叶斯模型的因子分解(factorization)可以表示如下,
![]()
0x3:朴素贝叶斯模型应用之困
尽管具有很强的假设,由于简单并且只需要少量参数,朴素贝叶斯模型经常在实践中作为“分类器”得以应用,例如基于朴素贝叶斯模型的垃圾邮件分类器。
这个模型最早被应用于医疗诊断,其中,类变量的不同值用于表示患者可能患的不同疾病。证据变量用于表示不同症状、化验结果等。在简单的疾病诊断上,朴素贝叶斯模型确实发挥了很好的作用,甚至比人类专家的诊断结果都要好。但是在更深度的应用中,医生发现,对于更复杂(由多种致病原因和症状共同表现)的疾病,模型表现的并不好。
数据科学家经过分析认为,出现这种现象的原因在于:模型做了集中通常并不真实的强假设,例如:
一个患者至多可能患一种疾病
在已知患者的疾病条件下,不同症状的出现与否,不同化验结果,之间是互相独立的
这种模型可用于医学诊断是因为少量可解释的参数易于由专家获得,早期的机器辅助医疗诊断系统正式建立在这一技术之上。
但是,之后更加深入的实践表明,构建这种模型的强假设降低了模型诊断的准确性,尤其是“过度计算”某些特定的证据,该模型很容易过高估计某些方面特征的影响。
例如,“高血压”和“肥胖症”是心脏病的两个硬指标,但是,这两个症状之间相关度很高,高血压一般就伴随着肥胖症。在使用朴素贝叶斯公式计算的时候,由于乘法项的缘故,关于这方面的证据因子就会被重复计算,如下式:
P(心脏病 | 高血压,肥胖症) = P(高血压 | 心脏病) * P(高血压 | 肥胖症) / P(高血压,肥胖症)
由于“高血压”和“肥胖症”之间存在较强相关性的缘故,我们可以很容易想象,分子乘积增加的比率是大于分母联合分布增加的比率的。因此,当分子项继续增加的时候,最终的后验概率就会不断增大。但是因为新增的特征项并没有提供新的信息,后验概率的这种增大变化反而降低了模型的预测性能。
实际上,在实践中人们发现,朴素贝叶斯模型的诊断性能会随着特征的增加而降低,这种降低常常归因于违背了强条件独立性假设。
Relevant Link:
https://www.cnblogs.com/LittleHann/p/7199242.html#_label6
6. 基于贝叶斯网解决三门问题(蒙提霍尔问题)
本章来自云栖社区一篇很棒的文章。

主持人会向挑战者展示三扇关着的门,其中一扇门之后有一辆车,其它门后则有一些无价值的东西。挑战者并不知道哪扇门背后是车。
现在挑战者可以先选择一扇门。然后,主持人会打开剩下的两扇门中没有车的一扇。现在,挑战者可以选择是否更换选择的门,但是问题来了,我们应该更换吗?
直觉上看,主持人似乎并没有透露任何信息。事实证明这种直觉并不完全正确。让我们使用我们的新工具"贝叶斯网"来分析这个问题。
我们首先先定义一些随机变量:
- D:背后有车的门:可取值为 1、2 或 3;D是未被观察到的随机变量。
- F:你的第一个选择:可取值为 1、2 或 3;D是已被观察到的随机变量。
- H:主持人打开的门:可取值为 1、2 或 3;主持人打开其中一扇门之前,H 都是未被观察到的。
- I:F 是否是 D?:可取值为 0、1;I是未被观察到的随机变量。
我们建立初始状态贝叶斯网结构(即挑战者做出的选择,但是主持人还未打开一扇门):

注意到:
- D 和 F 是相互独立的,因为此时I和H都是未知的(参考文章前面谈到的head-to-head独立结构)
- I 依赖于 D 和 F
- 主持人选择的门 H 也取决于 D 和 F
- 目前我们对 D 还一无所知,因为F是和D是独立的,因此知道F并不能对D有任何信息影响(这与学生网络的结构类似,即知道学生的智力水平不能让你获得有关课程难度的任何信息。)
现在,主持人选择了门 H 并打开了它。所以现在 H 已被观察到。
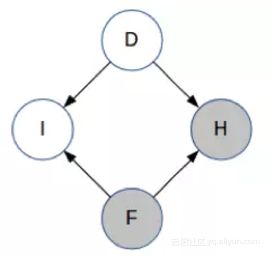
现在贝叶斯网的条件概率情况发生了变化:
- I<-D->H是一种tail-to-tail结构,D是未知的,所以 H 的信息影响力可以通过D传递到 I,因此已知 H 提供了对 I 的一些信息
也就是说,当支持人打开了剩下的两扇门中没有车的一扇后,挑战者理性的做法是改变自己最初的决策。
下面用CPD表格来形式化地分析这个游戏过程:

- D 和 F 都是先验概率,背后有车的门可能是这些门中的任何一扇且概率相等,我们选择其中一扇的概率是一样的。
- I 依赖于 D 和 F 的先验:
- 当 D,F 一样时,I=1
- 当 D,F 不一样时,I=0
- H 依赖于 D 和 F 的先验:
- D,F 一样时,那么主持人从另外两扇门选择一扇门的概率一样
- 如果 D 和 F 不一样,那么主持人就选择第三扇门
现在,让我们假设我们已经选择了一扇门。也就是说现在已经观察到 F,假设 F=1。那么给定 F 时,I 和 D 的条件概率是多少?
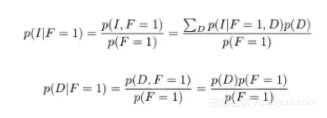
基于上面CPD表格计算边缘概率得:
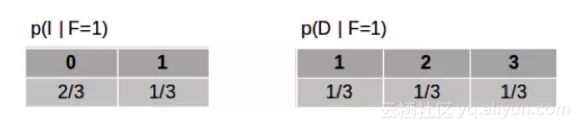
到目前为止,我们选对了门的概率都是三分之一,汽车仍然有可能在任何一扇门之后且概率相等。
现在,主持人打开了 F 之外的另一扇门,所以我们观察到了 H。假设 H=2。让我们再计算给定了 F 和 H 时 I 和 D 的条件概率。

概率计算结果如下:

可以看到,我们第一个选择正确的概率仍然是三分之一,我们的直觉也是如此。但是,现在车在第 3 扇门后的概率不再是三分之一,而是三分之二了。
所以如果我们更换选择,那么我们得到车的概率是三分之二;如果我们不换,我们得到车的概率是三分之一。
这里介绍一个pomegranate库,它抽象了概率图模型的底层细节,我们可以方便地基于API进行上层应用建模。
# -*- coding: utf-8 -*- from pomegranate import * if __name__ == '__main__': guest = DiscreteDistribution({'A': 1./3, 'B': 1./3, 'C': 1./3}) prize = DiscreteDistribution({'A': 1./3, 'B': 1./3, 'C': 1./3}) monty = ConditionalProbabilityTable( [['A', 'A', 'A', 0.0], ['A', 'A', 'B', 0.5], ['A', 'A', 'C', 0.5], ['A', 'B', 'A', 0.0], ['A', 'B', 'B', 0.0], ['A', 'B', 'C', 1.0], ['A', 'C', 'A', 0.0], ['A', 'C', 'B', 1.0], ['A', 'C', 'C', 0.0], ['B', 'A', 'A', 0.0], ['B', 'A', 'B', 0.0], ['B', 'A', 'C', 1.0], ['B', 'B', 'A', 0.5], ['B', 'B', 'B', 0.0], ['B', 'B', 'C', 0.5], ['B', 'C', 'A', 1.0], ['B', 'C', 'B', 0.0], ['B', 'C', 'C', 0.0], ['C', 'A', 'A', 0.0], ['C', 'A', 'B', 1.0], ['C', 'A', 'C', 0.0], ['C', 'B', 'A', 1.0], ['C', 'B', 'B', 0.0], ['C', 'B', 'C', 0.0], ['C', 'C', 'A', 0.5], ['C', 'C', 'B', 0.5], ['C', 'C', 'C', 0.0]], [guest, prize]) s1 = Node(guest, name="guest") s2 = Node(prize, name="prize") s3 = Node(monty, name="monty") model = BayesianNetwork("Monty Hall Problem") model.add_states(s1, s2, s3) model.add_edge(s1, s3) model.add_edge(s2, s3) model.bake() print model.probability([['A', 'A', 'A'], ['A', 'A', 'B'], ['C', 'C', 'B']]) print model.predict([['A', 'B', None], ['A', 'C', None], ['C', 'B', None]]) print model.predict([['A', 'B', None], ['A', None, 'C'], [None, 'B', 'A']])
![]()
Relevant Link:
https://yq.aliyun.com/articles/280788
7. 基于贝叶斯网进行图像降噪
假设我们有以下图像:

现在假设这张图像受到了随机噪声的污染,变成了有噪声的图像:

现在我们的目标是恢复原始图像。让我们看看如何使用概率图模型来实现。
0x1:问题分析
我们将有噪声图像中的每个像素都定义为一个观察到的随机变量,并将基准图像中的每个像素都定义为一个未被观察到的变量,由此,观察到的变量和未被观察到的变量都为 MxN 个。
我们将观察到的变量表示为 X_ij,未被观察到的变量定义为 Y_ij。每个变量都可取值 +1 或 -1(分别对应于黑色像素和白色像素)。
给定观察到的变量,我们希望找到未观察到的变量的最有可能的值。这对应于 MAP 推理。
0x2:图结构构建
现在让我们使用一些领域知识来构建图结构:
- 在有噪声图像中的 (i,j) 位置观察到的变量取决于在基准图像中的 (i,j) 位置未观察到的变量。原因是大多数时候它们是相等的,即 X_ij 和 Y_ij 的初始先验是相等的。
- 对于基准图像,
- 在每个单一颜色的区域内,邻近的像素通常有一样的值,因此,如果 Y_ij 和 Y_kl 是邻近像素,那么我们将它们连接起来。
- 在颜色变化的边界没有这个性质。
由此,我们得到图结构:
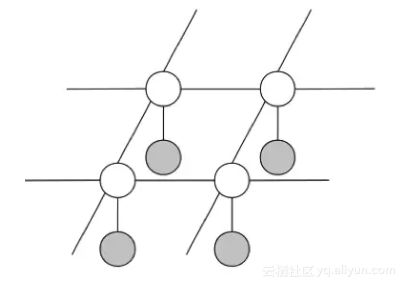
- 白色节点表示未被观察到的变量 Y_ij
- 灰色节点表示观察到的变量 X_ij
- 每个 X_ij 都连接到对应的 Y_ij
- 每个 Y_ij 都连接到它的相邻节点
这个图结构的先验知识非常重要,这是我们后面进行概率推理的一个重要条件。
0x3:图推理过程
我们的 MAP 推理问题可以用数学的方式写出,如下:
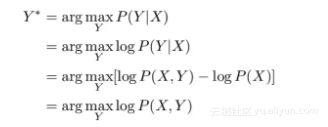
现在,我们需要根据我们的图结构来定义我们的联合分布 P(X,Y)。让我们假设 P(X,Y) 由两类因子组成,ϕ(X_ij, Y_ij) 和 ϕ(Y_ij,Y_kl),对应于图中的两类边。
接下来,我们按如下方式定义这些因子:
- ϕ(X_ij, Y_ij) = exp(w_e X_ij Y_ij),其中 w_e 是一个大于 0 的参数。当 X_ij 和 Y_ij 相等时,这个因子取较大的值,当 X_ij 和 Y_ij 不同时就取较小的值。
- ϕ(Y_ij, Y_kl) = exp(w_s Y_ij Y_kl),其中 w_s 也是一个大于 0 的参数。当 Y_ij 和 Y_kl 取值相等时,这个因子较大。
因此,我们的联合分布可由下式给出:
![]()
将其插入到我们的 MAP 推理式中,可得:
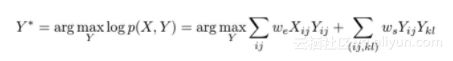
有了这些参数后,我们需要求解上述 MAP 推理问题。我们可以使用迭代条件模式(ICM/iterated conditional mode)。其基本思想是:在每个步骤选择一个节点 Y_ij,然后检查 Y_ij=-1 和 Y_ij=1 时 MAP 推理表达式的值,然后选择值更高的那个。重复这个过程一定的迭代次数或直到收敛,通常就能得到相当好的结果。
下面代码中展示了这个过程,需要特别体会的是,这是一个动态的概率调整过程,每次像素的猜测的同时都相当于向网络中输入了新的信息,网络中的条件概率也因此发生了改变。
# -*- coding: utf-8 -*- import numpy as np from PIL import Image import sys # look up the value of Y for the given indices # if the indices are out of bounds, return 0 def compute_log_prob_helper(Y, i, j): try: return Y[i][j] except IndexError: return 0 def compute_log_prob(X, Y, i, j, w_e, w_s, y_val): result = w_e * X[i][j] * y_val # 在每个单一颜色的区域内,邻近的像素通常有一样的值,因此,如果 Y_ij 和 Y_kl 是邻近像素,那么我们将它们连接起来 result += w_s * y_val * compute_log_prob_helper(Y, i-1, j) result += w_s * y_val * compute_log_prob_helper(Y, i+1, j) result += w_s * y_val * compute_log_prob_helper(Y, i, j-1) result += w_s * y_val * compute_log_prob_helper(Y, i, j+1) return result def denoise_image(X, w_e, w_s): m, n = np.shape(X) # initialize Y same as X # 在有噪声图像中的 (i,j) 位置观察到的变量取决于在基准图像中的 (i,j) 位置未观察到的变量。原因是大多数时候它们是相等的,即 X_ij 和 Y_ij 的初始先验是相等的 Y = np.copy(X) # optimization max_iter = 10 * m * n for iter in range(max_iter): # randomly pick a location i = np.random.randint(m) j = np.random.randint(n) # compute the log probabilities of both values of Y_ij log_p_neg = compute_log_prob(X, Y, i, j, w_e, w_s, -1) log_p_pos = compute_log_prob(X, Y, i, j, w_e, w_s, 1) # assign Y_ij to the value with higher log probability if log_p_neg > log_p_pos: Y[i][j] = -1 else: Y[i][j] = 1 if iter % 100000 == 0: print ('Completed', iter, 'iterations out of', max_iter) return Y # preprocessing step def read_image_and_binarize(image_file): im = Image.open(image_file).convert("L") A = np.asarray(im).astype(int) A.flags.writeable = True A[A<128] = -1 A[A>=128] = 1 return A def add_noise(orig): A = np.copy(orig) for i in range(np.size(A, 0)): for j in range(np.size(A, 1)): r = np.random.rand() if r < 0.1: A[i][j] = -A[i][j] return A def convert_from_matrix_and_save(M, filename, display=False): M[M==-1] = 0 M[M==1] = 255 im = Image.fromarray(np.uint8(M)) if display: im.show() im.save(filename) def get_mismatched_percentage(orig_image, denoised_image): diff = abs(orig_image - denoised_image) / 2 return (100.0 * np.sum(diff)) / np.size(orig_image) def main(): # read input and arguments orig_image = read_image_and_binarize("input.png") w_e = 8 w_s = 10 # add noise noisy_image = add_noise(orig_image) # use ICM for denoising denoised_image = denoise_image(noisy_image, w_e, w_s) # print the percentage of mismatched pixels print ('Percentage of mismatched pixels: ', get_mismatched_percentage(orig_image, denoised_image)) convert_from_matrix_and_save(orig_image, 'orig_image.png', display=False) convert_from_matrix_and_save(noisy_image, 'noisy_image.png', display=False) convert_from_matrix_and_save(denoised_image, 'denoised_image.png', display=False) if __name__ == '__main__': main()


降噪后的图像
可以看到,算法获得了70%的降噪效果。
Relevant Link:
https://www.coursera.org/learn/probabilistic-graphical-models?authMode=signup https://www.cnblogs.com/tornadomeet/p/3480694.html https://yq.aliyun.com/articles/280788 https://github.com/prasoongoyal/image-denoising-mrf/blob/master/denoise.py