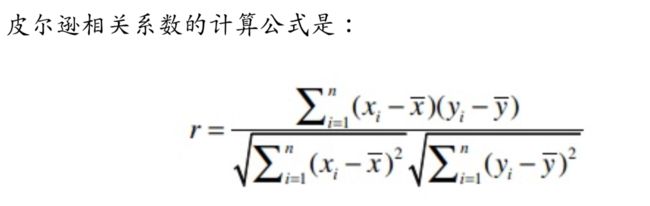
机器学习-推荐算法-皮尔逊相关系数
介绍
比如用户E看了4个影片,分别是‘无双’,‘逃学威龙1’,‘逃学威龙2’,‘他人笑我太疯癫’ 都打了不同的分。用户A看了‘唐伯虎点秋香’,'逃学威龙1',‘追龙’,‘他人笑我太疯癫’ 也打了不同的分。现求他们两人的相似度。利用皮尔逊相似度算法的优点是 只要他们的打分不是0并且观影相同的影片2个以上都会有相似的地方。用户相似可以相互推荐不同的影片。根据相似度排序获取高度相似的用户。
代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2019/1/16 17:14
# @Author : fuch
# @File : recommend.py
from math import sqrt
# 比如有5个用户分别给自己看的电影打分
users = {
'用户A': {'唐伯虎点秋香': 5, '逃学威龙1': 1, '追龙': 2, '他人笑我太疯癫': 0},
'用户B': {'唐伯虎点秋香': 4, '喜欢你': 2, '暗战': 3.5},
'用户C': {'复仇者联盟1': 4.5, '逃学威龙1': 2, '大黄蜂': 2.5, '蜘蛛侠:平行宇宙': 2, '巴霍巴利王:开端': 4},
'用户D': {'狗十三': 2, '无双': 5},
'用户E': {'无双': 4, '逃学威龙1': 4, '逃学威龙2': 4.5, '他人笑我太疯癫': 3}
}
# 现在要给用户E找相似用户
user = '用户E'
userInfo = users[user]
for u in users:
if u != user:
sum_x, sum_y, sum_x2, sum_y2, sum_xy, n = 0, 0, 0, 0, 0, 0
for key, value in users[u].items():
if key in userInfo.keys():
x = userInfo[key]
y = value
sum_x += x
sum_y += y
sum_x2 += pow(x, 2)
sum_y2 += pow(y, 2)
sum_xy += x * y
n += 1
if n > 0:
denominator = sqrt(sum_x2 - pow(sum_x, 2) / n) * sqrt(sum_y2 - pow(sum_y, 2) / n)
result = 0.
if denominator > 0:
result = (sum_xy - (sum_x * sum_y) / n) / denominator
print("{} to {} score => {}".format(user, u, result))