TensorFlow学习之一:实现kaggle赛题Digit Recognizer
最近学习TensorFlow的时候,正好利用kaggle上的Minist数据集来入手。经历一段时间的折磨后,终于成功弄出了一个结果,至于优化类的后面再讲,今天就介绍下tensorflow入门minist。
一开始我是看着官网学习的,但是鉴于官网知识很有限,最后我都理解为我自己的东西了。
学习的部分我前半部分为训练模型加保存模型,后半部分为加载模型并预测。这里我们讲解也分为2部分来讲解。
先讲上部分,数据集来源于kaggle上的Minist项目
首先我们加载数据和观察数据,通过简单的观察,数据本身是没有缺失值的,
附上完整代码:
# !/usr/bin/env python3
import tensorflow as tf
import pandas as pd
import numpy as np
def read_data(filename):#读取数据
data=pd.read_csv(filename)
return data
def handle_data(data):
y_data=data['label'].values.ravel() #获取标签数据
data.drop(labels='label',axis=1,inplace=True) #Image 数据
return data,y_data
def train_val_split(x_data,y_data):
large=x_data.shape[0]
print(large)
x_train=x_data.iloc[:large-200,].div(255.0)#由于数据值范围在0-255,部分值差异太大,故进行0-1标准化
y_train=y_data[:large-200,].astype(np.float32) #需要保证数据类型一致性
x_val=x_data.iloc[large-200:,].div(255.0)#由于数据值范围在0-255,部分值差异太大,故进行0-1标准化,此为验证Images数据,用来验证后面的模型的准确率
y_val=y_data[large-200:,].astype(np.float32)#此为Label数据,用来验证后面模型的准确率
return x_train,y_train,x_val,y_val
#one_hot编码
def one_hot(data):
num_class=len(np.unique(data))#获取label的个数,这里我们的手写识别数字范围是0~9,所以num_class=10
print(num_class)
num_lables=data.shape[0]
index_offset=np.arange(num_lables)*num_class
lables_one_hot=np.zeros((num_lables,num_class)) #构造一个全零array
print(data.ravel()) # ravel()函数用来平摊数据
lables_one_hot.flat[index_offset+data.ravel()]=1 #flat函数很有效
return lables_one_hot
def train_model(x_train,y_train,x_val,y_val,n): #训练模型并保存模型 此处模型用的softmax回归模型训练y=w*x+b
x=tf.placeholder("float",[None,784])
w=tf.Variable(tf.zeros([784,10]),name='w')
b=tf.Variable(tf.zeros([1,10]),name='b') #在这里的时候需要保证矩阵的维度在进行 y=x*w+b后直接都是一致的,否则会报错 这里维度为[none,10]=[none,784]*[784,10]+[1,10]
y=tf.nn.softmax(tf.matmul(x,w)+b) #定义模softmax 函数 这里需要注意我们在模型训练的时候y值存储的是0,1值,比如如果label为5,则在实际中的标识为[0,0,0,0,1,0,0,0,0,0]
y_=tf.placeholder("float",[None,10])
cross_entropy=-tf.reduce_sum(y_*tf.log(y)) #设置交叉熵
train_step=tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init=tf.global_variables_initializer()
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) # argmax(y,1)这个函数是用来获取每一行y中最大值的下标,和One_hot原理上相同,tf.equal用来返回预测值和实际值一样则为True,反之为False
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) #计算正确率
sess=tf.Session() #创建Session对话的时候需要先初始化
sess.run(init) #初始化sess
n_batch=int(len(x_train)/100) #设置迭代参数,这里把迭代次数设置的比较小,后面是可以对应调整的
saver=tf.train.Saver() #用来保存模型
for i in range(n):#设置迭代次数
for count in range(n_batch):
batch_xs=x_train[count*100:(count+1)*100] #设置分批次获取数据
batch_ys=y_train[count*100:(count+1)*100] #设置分批次获取标签数据
sess.run(train_step,feed_dict={x:batch_xs,y_:batch_ys}) # 训练模型
saver.save(sess,'model/my_minist_model',global_step=i) #保存模型到本地设置没迭代一次就保存一次
accuracy_n=sess.run(accuracy, feed_dict={x: x_val, y_: y_val})
print("第"+str(i+1)+'轮,准确率为:'+str(accuracy_n)) #通过验证数据来的到模型的准确率
#print(sess.run(w)) #查看经过训练后的w
print(sess.run(b)) #查看经过训练后的b
def load_model():#加载整个模型的构造
with tf.Session() as sess:
saver=tf.train.import_meta_graph('model/my_minist_model-417.meta')
saver.restore(sess,tf.train.latest_checkpoint('model/'))
w=sess.run('w:0')
b=sess.run('b:0')
print(sess.run(fetches,feed_dict=None))
def load_data(data):#此处只加载模型的参数
try:
reader=tf.train.NewCheckpointReader('model/my_minist_model-417')
variables=reader.get_variable_to_shape_map()
x=tf.placeholder("float",[None,784])
w=reader.get_tensor('w')
b=reader.get_tensor('b')
y = tf.nn.softmax(tf.matmul(x, w) + b)
with tf.Session() as sess:
y_pre=sess.run(y,feed_dict={x:data})
y_=tf.argmax(y_pre,1) #获取最终结果,由于之前我们的y 存储的是0,1值,这里我们需要获取对应的0,1值对应的数字,如果如果为[0,0,0,0,1,0,0,0,0,0],这里我们通过argmax会直接转换为5
result=y_.eval() #tensor变量转换为array
pd.DataFrame(result).to_csv('../minist/result.csv') #输出到CSV文件
print(y_.eval())
except Exception as e:
print(str(e))
if __name__=='__main__':
train=read_data('F:\\kaggle\\minist\\train.csv')
data,y_data=handle_data(train)
y=one_hot(y_data)# 通过one_hot编码,把shape变为(?,10)
print(y.shape)
x_train,y_train,x_val,y_val=train_val_split(data,y)
print(x_train.shape,y_train.shape,x_val.shape,y_val.shape)
train_model(x_train,y_train,x_val,y_val,10)#训练模型
通过训练完后我们会发现保存的文件如下
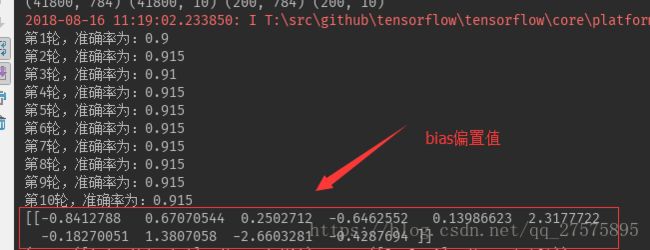
运行完后,我们的模型训练和保存工作也就做完啦,这里我们看到我们的模型准确度为90% 查看bias值如下:
接下来就需要加载模型并预测结果啦,这里由于上面的代码已经把所有的函数定义好了,我们只需要改下对应的main中的调用即可
if __name__=='__main__':
test=read_data('F:\\kaggle\\minist\\test.csv')
test = test.div(255.0)
load_data(test)最后将提交的结果上传到kaggle,我们会发现准确率为90.97%

后面我们边学习卷积神经网络,边提高模型的准确度。