利用movielens数据集实现基于物品的协同过滤推荐
文中的数据集来源于 movielens的ml-100k ,数据集包括,u.data、u.item、u.user 。
这里简要介绍下实现的思路,因为是基于物品的协同过滤,所以这里就是找两两物品之间的联系,然后根据物品来给用户进行相应的推荐,这里首先是要生成用户对物品的评分矩阵,然后就是生成物品同现矩阵,推荐结果 =物品同现矩阵* 用户物品评分矩阵。
首先是导入数据,将所给的数据导入进来,因为主要是做的一个实现的过程,所以数据的处理啥的就没怎么去做,主要是实现最终的推荐结果。数据集信息描述如下:
users数量:943 、items数量:1682 、ratings数量:100000
电影类目 ID对照表如下:1: Action、2: Adventure、3: Animation、4: Children's、5: Comedy
职业列表:artist 、doctor 、educator 、engineer 、entertainment
使用的工具为jupyter-notebook
import numpy as np
import pandas as pd
data_col = ['user_id','item_id','rating','timestamp']
item_col = ['movie_id','movie_title','release_date','video_release_date','IMDb_URL','unknown','Action',
'Adventure','Animation',"Children's",'Comedy','Crime','Documentary','Drama','Fantasy',
'Film-Noir','Horror','Musical','Mystery','Romance','Sci-Fi','Thriller','War','Western']
user_col = ['user_id','age','gender','occupation','zip_code']
#总数据包含了用户,物品,评分
data = pd.read_table('D:\\pycm\\movielens\\ml-100k\\u.data',
header=None,names=data_col,parse_dates=['timestamp'])
#物品详细数据
item = pd.read_table('D:\\pycm\\movielens\\ml-100k\\u.item',
header=None,names=item_col,parse_dates=['release_date','video_release_date'],encoding='ISO-8859-1',sep='|')
#用户信息
user = pd.read_table('D:\\pycm\\movielens\\ml-100k\\u.user',sep='|',
header=None,names=user_col)因为给出来的数据实际是不带列名的,所以我按照数据集中的解释文档的说明自己给它们加上了列名。
第一步先生成用户对物品的评分矩阵
def user_item_score(df,user_name,item_name,score_name):
"""
df:数据源
user_name: 用户列名
item_name: 物品列名
score_name: 评分列名
return: 返回用户对物品的评分矩阵,此处实际返回为DataFrame类型,行为用户,列为item,这里这样做主要是为了后面和物品同现矩阵做计算的时候,保持列名一致。
"""
user_names=df[user_name].unique()
item_names=df[item_name].unique()
user_n=len(user_names)
item_n=len(item_names)
zero_test=pd.DataFrame(np.zeros((user_n,item_n)),index=user_names,columns=item_names)
for i in df.itertuples():
zero_test.loc[getattr(i,user_name),getattr(i,item_name)]=getattr(i,score_name)
return zero_test
user_item_matrix=user_item_score(data,'user_id','item_id','rating')将用户评分矩阵导出到csv,自己查阅并验证生成是否有误
#查看某一个用户的对应评分是否有误 data.loc[data['user_id']==196]
#然后查看生成的shape是否有误
user_item_matrix.to_csv('D:\\pycm\\kaggle\\movielens\\user_item_matrix.csv')
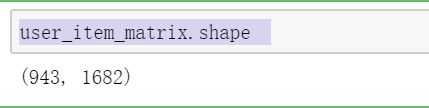
user_item_matrix.shape 可以看到这里生成的用户评分数据维度如下:
下面就是要生成物品同现矩阵了,这里我首先按照用户ID来进行物品的一个汇总,生成一个用户分组后的物品列表。
import collections
def create_item_list_by_user(df,user_name,item_name):
"""
df: DataFrame数据源
user_name: 按照用户列名来划分
item_name: 对应的物品列名比如是物品ID
return: 返回结果为按照用户ID 和对应的物品ID列表的字典形式
"""
res={}
item_list =[]
#res=collections.defaultdict(list)
"""
for i in range(df.shape[0]):
k=test.loc[i,user_name]
temp=test.loc[i,item_name]
res.setdefault(k,[]).append(temp)
"""
for i in df.itertuples():
res.setdefault(getattr(i,user_name),[]).append(getattr(i,item_name))
for i in res.keys():
item_list.append(res[i])
return item_list
item_list =create_item_list_by_user(data,'user_id','item_id')def create_item_matrics(items,item_len,item_name_list):
"""
items 物品集合
item_len 总物品数
item_name_list 物品总集合(无重复)
return : 返回物品同现矩阵,此处实际返回为DataFrame类型
"""
item_matrix =pd.DataFrame(np.zeros((item_len,item_len)),index=item_name_list,columns=item_name_list)
for im in items:
for i in range(len(im)):
#print(i)
for j in range(len(im)-i):
item_matrix.loc[im[i],im[j+i]] +=1
item_matrix.loc[im[j+i],im[i]] = item_matrix.loc[im[i],im[j+i]]
return item_matrix
item_set=data['item_id'].unique()
item_matrix=create_item_matrics(item_list,len(item_set),item_set)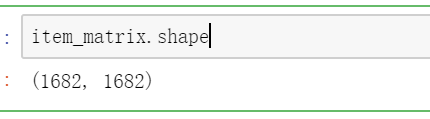
最后就是根据物品同现矩阵和用户评分矩阵来生成推荐结果。这里同时也要过滤掉用户曾经看过的电影。
##通过物品同现矩阵*用户评分矩阵=推荐结果,这里是指定一个用户来生成对应的用户的推荐结果。
def get_itemCF(item_matrix,user_score,col_name):
"""
item_matrix: 物品同现矩阵,DataFrame类型
user_score: 用户评分矩阵,DataFrame类型,某一个指定的用户的评分矩阵
return: 用户对对应的物品的兴趣值 得到的类型为DataFrame类型,
"""
columns=item_matrix.columns
#对列名进行重新排序,按照物品同现矩阵的列名进行排序
user_score = user_score[columns]
#过滤掉用户曾经看过的电影
user_movie=user_score[user_score.values==0].index
item_matrix=np.mat(item_matrix.as_matrix(columns=None))
user_score=np.mat(user_score.as_matrix(columns=None)).T
result_score=item_matrix * user_score
result = pd.DataFrame(result_score,index=columns,columns=['rating'])
result=result.sort_values(by='rating',ascending=False)
result[col_name]=columns
return result[result[col_name].isin(user_movie)]
user_result = get_itemCF(item_matrix,user_item_matrix.loc[196,:],'movie_id')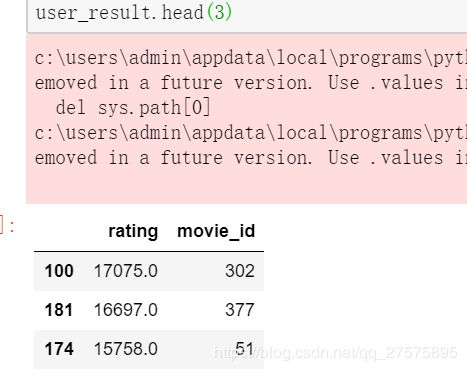
可以看到对应的结果出来了,然后要看详细的结果的详细信息则要和电影数据进行关联。
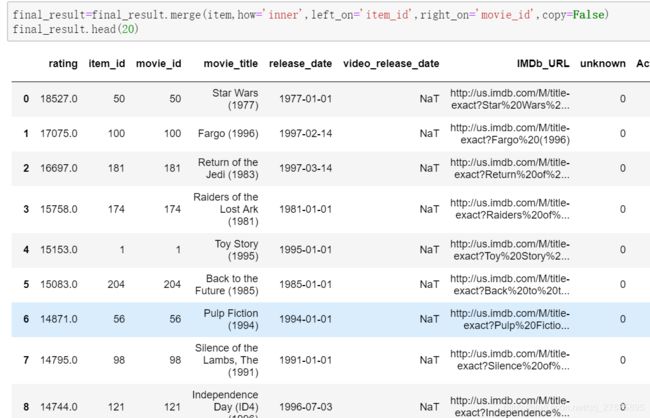
这样就实现了简单的基于物品的协同过滤,在这个过程中,理解如何生成物品同现矩阵是重点,那么在做这种思路求解的时候,问题点就在于求解物品同现矩阵很耗时,因为这里矩阵的维度相当于是1682*1682 ,所以这也是后期需要考虑进行升级的地方。然后深入分析这种思路,其实运用的原理主要还是物品的关联度原理和Apriori算法很相似。