R-CNN
一、文章概述
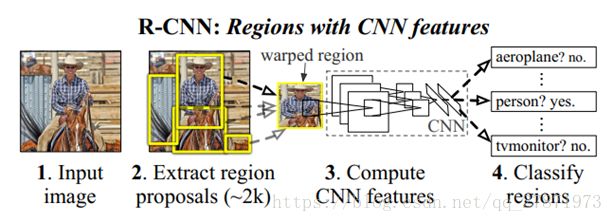
文章思路:对于输入的图片,首先使用Selective Search给出2000个物体建议候选框(Region Proposal),然后使用CNN提取每个Region Proposal中图片的特征向量,采用多个SVM分类器对各个候选框中的物体进行分类(compute score),得到的是一个region-bounding-box及对应的类别,再利用IOU得到具体的框,为了精确bounding-box,再根据pool5 feature做了个bounding-box 回归来提高定位精度。
二、 训练中涉及的主要技巧
- IOU的理解
在目标检测领域,我们使用检测算法对物体进行定位并识别,因为检测算法很难和人工标注的数据完全匹配,就需要一个评价定位精度的指标:IOU。IOU定义了两个bounding box的重叠程度,如下图所示:
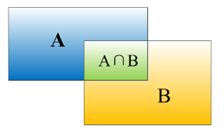
矩形框A、B的一个重合度IOU计算公式为:IOU=(A∩B)/(A∪B)

物体检测需要定位出物体的bounding box,对于上面的图像,我们不仅要给出狗的bounding box ,还要识别出bounding box 里面的物体是狗。假设红色框A是人工标注Ground Truth,绿色框B为建议框Region Proposal,那么就可以计算IOU了。
- 非极大值抑制
非极大值抑制(Non-Maximum Suppression,NMS),通俗说是抑制不是极大值的元素,也可以理解为局部最大搜索。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。NMS在计算机视觉领域有着非常多的使用。
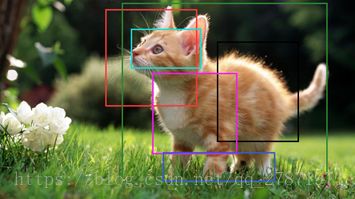
(1)

(2)
上面我们说过,在物体检测的时候,通过Selective Search会给出大量建议候选框,比如上图(2)左边第一个,我们需要判别哪些建议候选框是没用的。这里就用到了NMS。为了便于解释非极大值抑制,我们使用上图(1)猫的检测来说明,假设使用Selective Search给出了6个建议候选框,对每一个候选框使用CNN提取特征,并输入训练好的SVM中,根据SVM分类器类别分类概率做排序,从小到大分别属于猫的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设D与F的重叠度(IOU)超过阈值(一般设置0.3~0.5),那么扔掉D;并标记第一个矩形框F,保留下来。
(3)从剩下的矩形框A、B、C、E中,选择概率最大的E,然后判断E与A、B、C的IOU,IOU大于一定阈值的,就扔掉;并标记E是我们保留下来的第二个矩形框。
(4)一直重复,找到所有被保留下来的矩形框。
- SVM替换Softmax层
论文考虑到CNN训练可能会出现过拟合,所需的训练样本较多,对训练数据做了比较宽松的标注,IOU阈值只要大于0.5都被标注为正样本。这就导致一个Bounding box可能只包含物体的一部分,也被标注为正样本。然而SVM训练的时候,因为SVM区分类别的核心在于支撑向量(Support Vector),适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,只有当Bounding box把整个物体都包含进去了,才被标注为物体类别,训练SVM。
- 将建议框变形为227×227
当输入一张图像进网络时,使用Selective Search搜索出2000个候选框,算法给出的建议候选框是大小不相同的矩形。然而文章采用AlexNet网络对输入图像进行特征提取,我们知道AlexNet网络的输入图像大小:227×227,需要将所有建议候选框变形为227×227。论文给了几种方法进行缩放处理:

1. 各向异性缩放
不管图片的长宽比例,直接进行缩放就,全缩放到CNN输入的大小227*227,如上图(D)所示。
2. 各向同性缩放
考虑到图片扭曲后,可能会对CNN的训练精度有影响,论文测试了各向同性缩放方法。作者采用了两种技巧:
- 直接在原始图片中,把bounding box的边界进行扩展延伸成正方形,然后再进行裁剪;如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充;如图(B)所示。
- 先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值),如图(C)所示。
对于上面的各向异性、同性缩放,文种还测试了padding处理,上面处理结果图中第1、3行就是结合了padding=0;第2、4行采用padding=16的结果。经过试验,作者发现采用各向异性缩放、padding=16的效果较好。
- bounding-box回归
在SVM给出框的得分后,为了使得候选框定位的更加精确,作者在借鉴DPM的基础上给出如下操作:绿色框口P表示建议框Region Proposal,红色窗口G表示实际框Ground Truth,绿色窗口表示Region Proposal进行回归后的预测窗口,现在的目标是找到P到G的线性变换(P与G的IOU>0.6时可以认为是线性变换),使得与G越相近,这就相当于一个简单的可以用最小二乘法解决的线性回归问题。
定义窗口P的数学表达式:![]() 其中x,y表示第i窗口的中心点坐标,w,h分别为第i个窗口的宽和高;G窗口的数学表达式为:
其中x,y表示第i窗口的中心点坐标,w,h分别为第i个窗口的宽和高;G窗口的数学表达式为:![]() 。作者设计了四种坐标映射方法
。作者设计了四种坐标映射方法![]() ,其中前两个表示对proposal中心坐标的尺度不变的平移变换,后面两个则是对proposal的width和height的对数空间的变换,(通过平移对x和y进行变化和通过缩放对w和h进行变化,即下面四个式子所示)文章中的映射方式为:
,其中前两个表示对proposal中心坐标的尺度不变的平移变换,后面两个则是对proposal的width和height的对数空间的变换,(通过平移对x和y进行变化和通过缩放对w和h进行变化,即下面四个式子所示)文章中的映射方式为:

每一个![]() 【*表示x,y,w,h】都是一个AlexNet CNN网络Pool5层特征的线性函数,即:
【*表示x,y,w,h】都是一个AlexNet CNN网络Pool5层特征的线性函数,即:
![]()
最终的优化方法为:

其中:
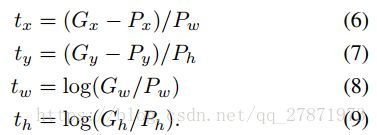
这是一个典型的最小二乘问题。在进行实验时,lambda = 1000,同时作者发现同一对中P和G相距过远时通过上面的变换是不能完成的,而相距过远实际上也基本不会是同一物体,因此作者在进行实时室,对于 PG对 的选择是选择离P较近的G进行配对,需要P和一个G的最大的IOU要大于0.6,否则则抛弃该P。
三、评价
作者在特征抽取方面借鉴CNN在图像分类中的使用,基于AlexNet网络对输入图像进行特征提取,但是ILSVRC样本集上用于图片分类的含标注类别的训练集有1millon之多,总共含有1000类;而PASCAL VOC 2007样本集上用于物体检测的含标注类别和位置信息的训练集只有10k,总共含有20类,直接用这部分数据训练容易造成过拟合,因此作者提出并利用ILSVRC2012的训练集先进行有监督预训练。有监督预训练也称为迁移学习。比如:当我们要对一个样本较少的数据集构建网络模型进行训练时,可能会出现过拟合,这个时候,我们可以在相似的样本充足的数据集对模型进行训练,保存前面卷积层的参数作为初始化参数,修改层的网络参数随机初始化,再在我们样本较少的数据集上微调训练。
论文算法流程相对来说比较复杂,涉及到的技巧比较多,并且算法的是一步一步进行,中间需要消耗大量的内存保存数据等等。后面开始学习更好的目标检测算法。
参考文献
[1]Uijlings J R R, Sande K E A V D, Gevers T, et al. Selective Search forObject Recognition[J]. International Journal of Computer Vision, 2013,104(2):154-171.
[2]Rich feature hierarchies for accurate object detection and semantic segmentation