机器学习之深度迁移学习(二)
深度学习中使用迁移学习
1.深度网络的可迁移性 :finetune
虽然神经网络本身就行一个黑盒子,看不见,摸不着,解释性不是很强,但是神经网络具有很好的层级结构,我们可以通过这些层次结构很好的解释网络。有我们熟知的例子:假设一个网络要识别一只猫,那么一开始它只能检测到一些边边角角的东西,和猫 根本没有关系;然后可能会检测到一些线条和圆形;慢慢地,可以检测到有猫的区域;接着 是猫腿、猫脸等等。概括的来说:前面几层都学习到的是通用的特征(general feature);随着网络层次的加深,后面的网络更偏重于学习任务特定的特征(specificfeature)。
康奈尔大学的 Jason Yosinski 等人 [Yosinski et al., 2014] 率先进行了深度神经网 络可迁移性的研究:
作者论文的主要思想及实现方法:
在 ImageNet 的 1000 类上,作者把 1000 类分成两份(A 和 B),每份 500 个类别。然 后,分别对 A 和 B 基于 Caffe 训练了一个 AlexNet 网络。一个 AlexNet 网络一共有 8 层, 除去第 8 层是类别相关的网络无法迁移以外,作者在 1 到 7 这 7 层上逐层进行 finetune 实 验,探索网络的可迁移性。
为了更好地说明 finetune 的结果,作者提出了有趣的概念:AnB 和 BnB。 迁移 A 网络的前 n 层到 B(AnB)vs 固定 B 网络的前 n 层(BnB)。
简单说一下什么叫 AnB:(所有实验都是针对数据 B 来说的)将 A 网络的前 n 层拿来 并将它 frozen,剩下的 8−n 层随机初始化,然后对 B 进行分类。
相应地,有 BnB:把训练好的 B 网络的前 n 层拿来并将它 frozen,剩下的 8−n 层随 机初始化,然后对 B 进行分类。
实验结果 :
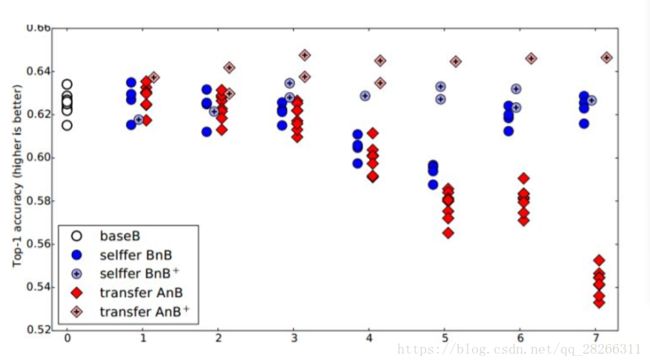
我们先看蓝色的 BnB 和 BnB+(就是 BnB 加上 finetune)。对 BnB 而言,原训练好的 B 模型的前 3 层直接拿来就可以用而不会对模型精度有什么损失。到了第 4 和第 5 层,精度略有下降,,是因为feature 变得越来越 specific,所以下降了。然而到了第 6 第第 7 层,精度开始回升。是因为,整个网络就 8 层,我们固定了第 6 第 7 层,这个网络还能学什么 呢?
BnB+ 来说,结果基本上都保持不变。说明 finetune 对模型结果有着很好的促进作用!
对 AnB 来说,直接将 A 网络的前 3 层迁移到 B,貌 似不会有什么影响。到 了第 4 第 5 层的时候,精度开始下降,,主要是由 于 A 和 B 两个数据集的差异比较大,所以会下降;到了第 6 第 7 层,由于网络几乎不迭代 了,学习能力太差,此时 feature 学不到,所以精度下降得更厉害。
再看 AnB+。加入了 finetune 以后,AnB+ 的表现对于所有的 n 几乎都非常好,甚至 比 baseB(最初的 B)还要好一些!这说明:finetune 对于深度迁移有着非常好的促进作用!

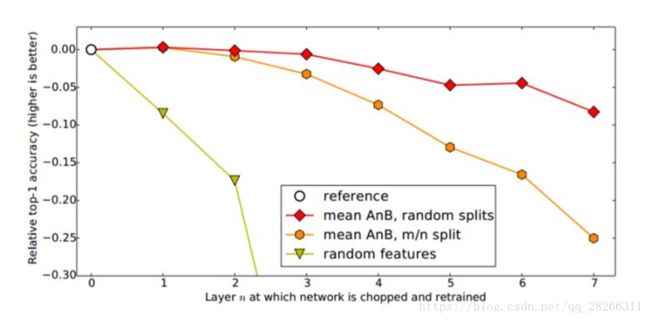
作者又想,是不是我分 A 和 B 数据的时候,里面存在 一些比较相似的类使结果好了?比如说 A 里有猫,B 里有狮子,所以结果会好?为了排除 这些影响,作者又分了一下数据集,这次使得 A 和 B 里几乎没有相似的类别。
2.深度网络自适应
基本思路:
许多深度学习方法都开发出了自适应层 (Adaptation Layer) 来完成源域和目标域数据的自 适应。自适应能够使得源域和目标域的数据分布更加接近,从而使得网络的效果更好。 从上述的分析我们可以得出,深度网络的自适应主要完成两部分的工作:
一是哪些层可以自适应,这决定了网络的学习程度;
二是采用什么样的自适应方法 (度量准则),这决定了网络的泛化能力。
深度网络中最重要的是网络损失的定义。绝大多数深度迁移学习方法都采用了以下的 损失定义方式:
ℓ = ℓc(Ds,ys) + λℓA(Ds,Dt)
(下标 s / t 指示源域 / 目标域 ,Ds / Dt :有标记的源域数据 / 无标记的目标域数据,ys表示源域中的实际类别 )
其中,ℓ 表示网络的最终损失,ℓc(Ds,ys) 表示网络在有标注的数据 (大部分是源域) 上 的常规分类损失 (这与普通的深度网络完全一致),ℓA(Ds,Dt) 表示网络的自适应损失。最后 一部分是传统的深度网络所不具有的、迁移学习所独有的。此部分的表达与我们先前讨论 过的源域和目标域的分布差异,在道理上是相同的。式中的 λ 是权衡两部分的权重参数。
因此,我们设计深度迁移网络的基本准则:
决定自适应层,
然后在这些层加入 自适应度量,
最后对网络进行 finetune。
Domain adaptation的目的是将源域(Source domain)中学到的知识可以应用到不同但相关的目标域(Target domain)。
核心方法:
(补充:度量准则:
最大均值差异 MMD
MMD(最大均值差异)是迁移学习,尤其是Domain adaptation (域适应)中使用最广泛(目前)的一种损失函数,主要用来度量两个不同但相关的分布的距离,是一种核学习方法。两个分布的距离定义为: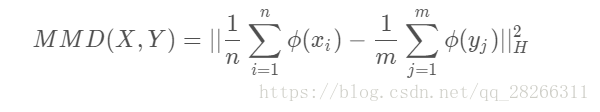
其中 ,ϕ(·) 是映射,用于把原变量映射到再生核希尔伯特空间 ,H表示这个距离是由 ϕ() 将数据映射到再生希尔伯特空间(RKHS)中进行度量的。
理解:就是求两堆数据在 RKHS 中的均值的距离。
1. DDC (Deep Domain Confusion) 解决深度网络的自适应问题
DDC 遵循了我们上述讨论过的基 本思路,采用了在 ImageNet 数据集上训练好的 AlexNet 网络 [Krizhevsky et al., 2012] 进 行自适应学习。
DDC 固定了 AlexNet 的前 7 层,在第 8 层 (分类器前一 层) 上加入了自适应的度量。自适应度量方法采用了被广泛使用的 MMD 准则。DDC 方法 的损失函数表示为:

在大多数论文中(比如DDC, DAN),都是用高斯核函数 ![]() 来作为核函数,至于为什么选用高斯核,最主要的应该是高斯核可以映射无穷维空间。
来作为核函数,至于为什么选用高斯核,最主要的应该是高斯核可以映射无穷维空间。

DDC 方法示意图
为什么选择了倒数第二层? DDC 方法的作者在文章中提到,他们经过了多次实验,在 不同的层进行了尝试,最终得出结论,在分类器前一层加入自适应可以达到最好的效果。 这也是与我们的认知相符合的。通常来说,分类器前一层即特征,在特征上加入自适 应,也正是迁移学习要完成的工作。
2. DAN
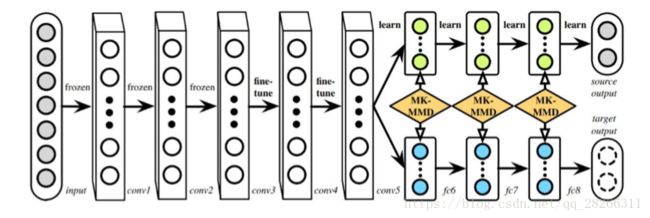
来自清华大学的龙明盛等人在 2015 年发表在机器学习顶级会议 ICML 上的 DAN 方法 (Deep Adaptation Networks) 对 DDC 方法进行了几个方面的扩展。首 先,有别于 DDC 方法只加入一个自适应层,DAN 方法同时加入了三个自适应层 (分类器前 三层)。其次,DAN方法采用了表征能力更好的多核MMD度量(MK-MMD)代替了 DDC 方法中的单一核 MMD。然后,DAN 方法将多核 MMD 的参数学习融入到深 度网络的训练中,不增加网络的额外训练时间。DAN 方法在多个任务上都取得了比 DDC 更好的分类效果。
为什么是适配 3 层?原来的 DDC 方法只是适配了一层,现在 DAN 也基于 AlexNet 网 络,适配最后三层(第6第7第8层)。为什么是这三层?因为在Jason的文章[Yosinski et al., 2014] 中已经说了,网络的迁移能力在这三层开始就会特别地 task-specific,所以要着重适配这三 层。至于别的网络(比如 GoogLeNet、VGG)等是不是这三层就需要通过自己的实验来推 测。DAN 只关注使用 AlexNet。
MK-MMD 的多核表示形式为
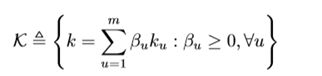
DAN 的优化目标也由两部分组成:损失函数和自适应损失。损失函数这个好理解,基 本上所有的机器学习方法都会定义一个损失函数,它来度量预测值和真实值的差异。分布 距离就是我们上面提到的 MK-MMD 距离。于是,DAN 的优化目标就是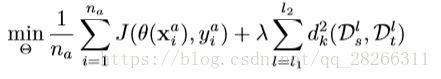
这个式子中,Θ 表示网络的所有权重和 bias 参数,是用来学习的目标。其中 l1,l2 分 别是 6 和 8, 表示网络适配是从第 6 层到第 8 层,前面的不进行适配。xa,na 表示源域和 目标域中所有有标注的数据的集合。J(·) 就定义了一个损失函数,在深度网络中一般都是 cross-entropy。DAN 的网络结构如下图所示。
3.深度对抗网络迁移
3.1基本思路
GAN 的目标很明确:生成训练样本。GAN有两部分组成:
一部分是生成网络,此部分负责尽可能多的生成以假乱真的样本。
另一部分是判别网络,此部分负责判别样本的真实性。
GAN与迁移学习:
迁移学习中存在源域与目标域,我们可以免去生成样本的步骤,直接将其中的一个领域的数据作为生成样本。(通常是目标域)。此时,生成网络的功能不再是生成新样本,而是进行特征提取,不断学习领域数据的特征,使得判别网络无法对两个网络进行判别。
与深度网络自适应迁移方法类似,深度对抗网络的损失也由两部分构成:网络训练的损 失 ℓc 和领域判别损失 ℓd:

3.2 核心方法
1. DANN
YaroslavGanin 等人首先在神经网络的训练中加入了对抗机制,作 者将他们的网络称之为 DANN(Domain-Adversarial Neural Network)。在此研究中,网络的 学习目标是:生成的特征尽可能帮助区分两个领域的特征,同时使得判别器无法对两个领域 的差异进行判别。该方法的领域对抗损失函数表示为:

其中的 Ld 表示为

2. DSN(Domain Separation Networks)
DSN 认为,源域和目标域都由两部 分构成:公共部分和私有部分。公共部分可以学习公共的特征,私有部分用来保持各个领域 独立的特性。DSN 进一步对损失函数进行了定义:

除去网络的常规训练损失 ℓtask 外,其他损失的含义如下:
• ℓrecon: 重构损失,确保私有部分仍然对学习目标有作用
• ℓdifference: 公共部分与私有部分的差异损失
• ℓsimilarity: 源域和目标域公共部分的相似性损失
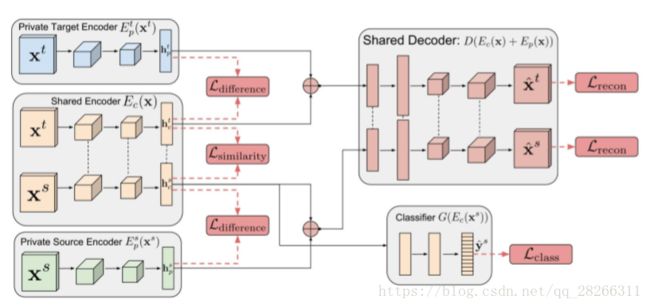
DSN 方法的示意图
算法描述
- Xs:source domain里的数据(被标记的)
- Xt:target domain里的数据(尚未被标记的)
- Ec( θc,X):函数,论文中似乎也把它称为一个encoder。将X(数据)里共有的特征(source domain和target domain里)提取出来(shared subspace里的)作为隐藏特征hc(hidden representation,common)。参数为 θc和X
- Ep( θp,X):函数,论文中似乎也把它称为一个encoder。与Ec类似。将X(数据)里私有的特征(分别是source domain和target domain里的)分别提取出来(private subspace里的)作为隐藏特征hp(hidden representation,private)。参数为 θp和X
-
D(h,θd)作为一个解码函数(decoder),将隐藏特征重建为图像。
-
G(h; θg): task-specific function。利用隐藏特征作出预测(task-specific predictions)
4.使用图像数据进行迁移学习
在将视频或者图像作为输入的预测模型问题中使用迁移学习是很常见的问题。对于这类问题,我们通常使用为大规模的挑战性图像数据集预训练模型。例如 ImageNet(1000 类图像分类挑战赛的数据集)。
基于该数据集的比较出色的模型有:
- 牛津 VGG 模型(http://www.robots.ox.ac.uk/~vgg/research/very_deep/)
- 谷歌 Inception 模型(https://github.com/tensorflow/models/tree/master/inception)
- 微软 ResNet 模型(https://github.com/KaimingHe/deep-residual-networks)
各种图像预处理的模型可以直接下载到,它们将图像作为输入。
在 Caffe Model Zoo(https://github.com/BVLC/caffe/wiki/Model-Zoo)中找到更多的预训练的模型。
(图片来源于水印出处)
使用图像数据进行迁移学习的方法是有效的,因为大量的图片在这个模型上进行训练,需要模型能够预测出相对比较多的图片类型,反过来,这需要模型能够有效地学习从图片中提取特征,以较好地解决这个问题。但是要注意仔细选择将预训练模型在多大程度上利用到新模型中。
近年来,以生成对抗网络 (GenerativeAdversarialNets,GAN)[Goodfellow et al., 2014] 为代表的对抗学习也吸引了很多研究者的目光。基于 GAN 的各种变体网络不断涌现。对抗学习网络对比传统的深度神经网络,极大地提升了学习效果。因此,基于对抗网络的迁移学习,也是一个热门的研究点。
使用迁移学习的时候可能带来的三种益处:
- 更高的起点。在微调之前,源模型的初始性能要比不使用迁移学习来的高。
- 更高的斜率。在训练的过程中源模型提升的速率要比不使用迁移学习来得快。
- 更高的渐进。训练得到的模型的收敛性能要比不使用迁移学习更好。
迁移学习能够改善学习的三种方式
如果你能够发现一个与你的任务有相关性的任务,它具备丰富的数据,并且你也有资源来为它开发模型,那么,在你的任务中重用这个模型确实是一个好方法,或者(更好的情况),有一个可用的预训练模型,你可以将它作为你自己模型的训练初始点。