行人重识别论文(三)--Semi-supervised person Re-Identification using multi-view clustering
论文获取地址:https://www.sciencedirect.com/science/article/pii/S0031320318304126
使用多视图聚类的半监督行人重识别
主要贡献
• 设计了一种用于人员重新识别的半监督特征表示框架,其有效地利用标记和未标记的训练数据来学习辨别表示,从而可以可靠地匹配不相交的摄像机视图上的人物图像。
• 提出了一种多视图聚类方法,将来自多个卷积神经网络的特征进行聚类,从而为未标记数据提供更准确的标签估计。
• 每个卷积神经网络都使用一个同时计算识别损失(identification loss)和验证损失(verification loss)的联合网络,同时学习有区别的卷积神经网络嵌入和相似性度量,从而提高行人检索的准确性。
目录
论文获取地址:https://www.sciencedirect.com/science/article/pii/S0031320318304126
使用多视图聚类的半监督行人重识别
主要贡献
目录
摘要
1. Introduction
1.1. Motivation
1.2. Our framework
2. Related work
多视图聚类
3. Methodology
3.1. Our model
机器学习中正则化项L1和L2的直观理解
稀疏模型与特征选择
softmax函数及对数似然函数
1. softmax函数及其求导
softmax配合log似然代价函数训练ANN
3.2. Optimization algorithm
4. Experimental results
5. Conclusion
摘要
本文提出了一种 Semi-supervised 的行人重识别方法,仅仅使用少量带标签的数据集以及额外的一部分不带标签的数据集。本文构建一组使用标记部分微调的异构卷积神经网络(CNN),然后将标签传播到未标记部分以进一步微调整个系统来解决大量标记训练数据耗时的问题。标签估计是传播过程中的关键组成部分。 此外,本文还提出了一种多视图聚类的方法,该方法将多个异构CNN的特征集成到聚类中,并为未标记的样本生成伪标签。然后通过使用具有真实标签和伪标签的训练数据最小化identification loss 和 a verification loss来微调多个异构卷积神经网络的每一个。迭代该过程直到伪标签的估计不再改变。
1. Introduction
针对人Re-Id的深度学习方法可以分为两类,即相似性学习和表征学习。对于第一类,训练输入可以是 image pairs, triplets , 和quadruplets 。这些方法旨在通过各种验证损失学习端到端深度神经网络系统中的特征。对于第二类,不同身份的图像被馈入深度神经网络,通过identification loss 来学习分类器,例如cross-entropy loss。
现有的方法大多数都是完全监督的方法,完全监督的弊端,然后作者提出了半监督方法。,有效地利用标记和未标记的训练数据来学习辨别特征表示。我们提出的半监督学习框架侧重于如何有效地利用小标记部分,然后通过估计其可能的标签传播到未标记的部分。我们尝试利用聚类为未标记的训练样本生成伪标签。
1.1. Motivation
Market-1501 的训练集包含12,936个751个身份的裁剪图像。我们选择250个身份作为标记部分,501个身份的剩余图像作为我们未标记的部分。首先,我们微调使用标记部分在ImageNet上预训练的Caffenet 和 VGG16,然后我们分别使用这些训练模型提取未标记部分的特征。

图一显示了30个随机选择的身份2D t-SNE的可视化表示。我们可以看到深层视觉特征的空间确实是一个丰富的空间,不同类别的实例通常形成自然集群。不同CNN特征的一些行人身份具有不同形式,具有互补信息,例如,Caffenet提取的人物身份1和2的特征比VGG16提取的特征具有更大的 inter-class distance ,也可以在person identity 6看到,而person identity 3或4的VGG16特征的 intra-class distance小于Caffenet提取的特征,我们可以观察到person identity 7和8也有类似的情况。基于这些观察,提取的特征是不同的CNN模型可以看作是对不同视图的描述,我们提出了一种多视图聚类方法旨在结合这些互补的多视图特征以生成未标记部分的伪标记。在我们的方法中,图像聚类和特征表示联合更新,良好的表示有益于图像聚类,聚类结果为表征学习提供监督信号。
1.2. Our framework
首先仅使用少量标记数据训练多个异构基本深度CNN,然后分别使用所获得的异构CNN来提取每个未标记训练数据的特征。然后,我们提出了一种多视图聚类方法,通过联合搜索每个视图的共识模式并执行聚类来估计未标记训练数据的伪标签。利用获得的伪标签,我们以完全监督的方式微调每个异构CNN。我们迭代上述步骤,直到估计的伪标签稳定。请注意,标准半监督学习与我们提出的方法之间的显着差异在于,在标准半监督学习中,标记实例对于所有类(人物身份)都存在,而我们对于unseen classes没有任何标记实例 ,这是典型的zero-shot learning problem。换句话说,我们的目标是跨相机挖掘标签以供未标记的类别。
2. Related work
略
多视图聚类
多视图聚类旨在通过组合可用的多视图特征信息将类似的主题分类为相同的组并且将不同的主题分类到不同的组中。
3. Methodology
Re-Id的半监督框架如图二所示。本文接下来:
1)首先介绍本框架的数学公式;
2)接着引入替代优化算法来求解我们的模型。

3.1. Our model
我们的半监督模型可以将深度特征学习和伪标签估计结合到一个统一的框架中。深度特征学习从多个基本卷积神经网络开始,例如Caffenet ,VGG16和Res50,它们在ImageNet上训练 。
1. 我们首先使用少量标记的训练样本对这些模型进行微调,并将它们存储为原始模型。
2.然后我们利用原始模型提取未标记训练样本的特征。本文采用一种多视图的聚类方法用于聚类特征以生成伪标签。
3.然后通过使用已标记训练样本的更新训练集和具有伪标签的未标记训练样本来微调原始模型。
最后,我们迭代第二步和第三步,直到更新的训练集变得稳定。
在CNN训练的每次迭代中,使用标记和未标记的训练数据,CNN模型在Imagenet上预训练的模型上进行微调。该聚类结果仅用于指示不同的群集ID。通过更好的聚类结果,可以获得更准确的伪标签。通过CNN训练过程可以学习更多的辨别特征。同时,更多的辨别特征导致更好的聚类结果。通过交替使用这两个步骤,可以学习更好和更好的CNN特征,直到估计的伪标签保持不变。
给定 M 种特征υ = 1 , 2 , . . . , M.算法可以描述为:
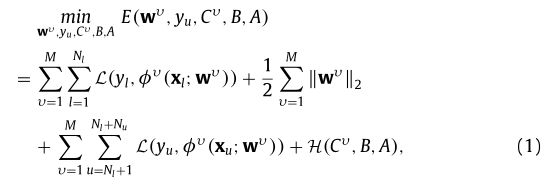
这里的![]() 表示有标签和无标签的训练样本。
表示有标签和无标签的训练样本。![]() 表示有标签和无表情样本的数量。
表示有标签和无表情样本的数量。![]() 表示CNN网络模型第
表示CNN网络模型第![]() 视图的参数。
视图的参数。![]() 表示标记和未标记训练样本的标签。
表示标记和未标记训练样本的标签。![]() 表示损失函数,
表示损失函数,![]() 表示多视图伪标签估计项。
表示多视图伪标签估计项。![]() 表示第
表示第![]() 视角下的重心矩阵(centroid matrix )。
视角下的重心矩阵(centroid matrix )。![]() 表示聚类结果。A 表示权重矩阵。
表示聚类结果。A 表示权重矩阵。
机器学习中正则化项L1和L2的直观理解
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1ℓ1-norm和ℓ2ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。下图是Lasso回归的损失函数,式中加号后面一项
即为L1正则化项。
下图是Ridge回归的损失函数,式中加号后面一项
即为L2正则化项。
一般回归分析中回归 w 表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。L1正则化和L2正则化的说明如下:
L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为
L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为
一般都会在正则化项之前添加一个系数,用α表示,一些文章也用λ表示。这个系数需要用户指定。那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到。
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合稀疏模型与特征选择
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. 通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。


The loss term 根据两个任务的不同重点,即识别任务和验证任务,损失项有两个损失。
![]()
对于基本的 discrimination learning,,我们将识别任务视为一个多类别的分类问题。
![]()
这里的![]() 是预测的概率。p 是目标概率。
是预测的概率。p 是目标概率。
对于验证部分,验证损失是二元逻辑回归损失。及那个图像对的特征定义为![]()

这里的![]() 是预测的概率。如果图像对描绘了同一个人,q1=1,q2=0; 除此以外,q1=0,q2=1。
是预测的概率。如果图像对描绘了同一个人,q1=1,q2=0; 除此以外,q1=0,q2=1。
softmax函数及对数似然函数
1. softmax函数及其求导
softmax的函数公式如下:
其中,
表示第L层(通常是最后一层)第j个神经元的输入,
表示第L层第j个神经元的输出,
表示自然常数。注意看,
表示了第L层所有神经元的输入之和。
softmax函数最明显的特点在于:它把每个神经元的输入占当前层所有神经元输入之和的比值,当作该神经元的输出。这使得输出更容易被解释:神经元的输出值越大,则该神经元对应的类别是真实类别的可能性更高。
另外,softmax不仅把神经元输出构造成概率分布,而且还起到了归一化的作用,适用于很多需要进行归一化处理的分类问题。
由于softmax在人工神经网络算法中的求导结果比较特别,分为两种情况。希望能帮助到正在学习此类算法的朋友们。求导过程如下所示:
softmax配合log似然代价函数训练ANN
二次代价函数在训练ANN时可能会导致训练速度变慢的问题。那就是,初始的输出值离真实值越远,训练速度就越慢。这个问题可以通过采用交叉熵代价函数来解决。其实,这个问题也可以采用另外一种方法解决,那就是采用softmax激活函数,并采用log似然代价函数(log-likelihood cost function)来解决。
log似然代价函数的公式为:
其中,
表示第k个神经元的输出值,
表示第k个神经元对应的真实值,取值为0或1。
我们来简单理解一下这个代价函数的含义。在ANN中输入一个样本,那么只有一个神经元对应了该样本的正确类别;若这个神经元输出的概率值越高,则按照以上的代价函数公式,其产生的代价就越小;反之,则产生的代价就越高。
为了检验softmax和这个代价函数也可以解决上述所说的训练速度变慢问题,接下来的重点就是推导ANN的权重w和偏置b的梯度公式。以偏置b为例:
同理可得:
从上述梯度公式可知,softmax函数配合log似然代价函数可以很好地训练ANN,不存在学习速度变慢的问题。




The multi-view pseudo label estimated term. 通过利用CNN特征的多个视图来聚类来估计未标记的训练样本的伪标签。利用CNN特征的多个视图将所有特征连接在一起并执行聚类算法。然而,在这种方法中,多视图特征被同等对待,使得聚类结果不是最佳的。我们的目的是是的每个视角的每个数据的损失最小哪个视角小的特征较为重要就赋予较大的权重。此外,多视图聚类方法涉及从由不同CNN模型提取的多视图特征中找到统一部分。当逐个视图执行聚类算法时,不同视图的聚类结果应该是唯一的。在我们的方法中,我们强制集群分配矩阵( assignment matrices) 在不同的视图中是相同的,多视图伪标签估计项可以表示如下:

这里![]() 表示矩阵,其列是未标记的图像,其中d是图像特征的维度。
表示矩阵,其列是未标记的图像,其中d是图像特征的维度。![]() 代表第 υ 个视图下CNN 模型特征。
代表第 υ 个视图下CNN 模型特征。![]() 表示第 υ 个视图下的质心矩阵(centroid matrix)。
表示第 υ 个视图下的质心矩阵(centroid matrix)。![]() 是聚类结果,满足
是聚类结果,满足![]() 的编码规则。
的编码规则。![]() 是预期的聚类的数量。
是预期的聚类的数量。![]() 是由权重
是由权重 ![]() 在第 υ 个视图下的实例,
在第 υ 个视图下的实例,![]() 。
。![]() 表示在第 υ 个视图下第 i 个数据的权重。我们学习不同类型特征的权重,重要特征将在多视图聚类期间获得较大权重。
表示在第 υ 个视图下第 i 个数据的权重。我们学习不同类型特征的权重,重要特征将在多视图聚类期间获得较大权重。
3.2. Optimization algorithm
我们的方法主要由两部分组成:一部分是多视图聚类,另一部分是多个CNN的训练。可以采用alternative optimization strategy 替代优化策略(AOS)来解决我们的模型。优化过程如下:
Initialization: 我们初始化![]() 通过微调在Imagenet上训练的多个CNN模型,使用少量标记的训练数据。B由single-view - K-means和权重因子
通过微调在Imagenet上训练的多个CNN模型,使用少量标记的训练数据。B由single-view - K-means和权重因子![]() 对于每个视图初始化。
对于每个视图初始化。
update B : B是通过优化所提出的多视图聚类方法获得的。




4. Experimental results
5. Conclusion
在本文中,我们提出了行人Re-Id的半监督框架,它可以利用标记和未标记的训练样本和多个深度模型来提高Re-Id的性能。一种多视图聚类方法被引入用于伪标签估计,从而使其成为半受监督的行人Re-Id方法。首先,提出的多视图聚类方法组合多视图CNN特征以执行聚类,其为未标记的训练样本生成非常准确的伪标签估计。然后,使用该估计的标签微调多个异构CNN模型以改进其原始的相应版本。我们的每个CNN模型都使用一个联合网络,该网络联合优化识别损失和验证损失,同时学习有区别的CNN嵌入和相似性度量。在大规模的行人重识别数据集中证明了所提方法的有效性。在未来的研究中,我们将探索如何有效地训练多个CNN网络以具有更多的互补特征以及如何有效地利用未标记的数据来训练深度神经网络。
参考文献
https://blog.csdn.net/jinping_shi/article/details/52433975