Hierarchical Attention Networks for Document Classification翻译
摘要
我们提出了一种用于文档分类的分层注意力网络。我们的模型有两个显著特征:(i)它具有反映文档层次结构的层次结构; (ii)它在单词和句子级别应用了两个不同的注意力机制,使其能够在构建文档表示时区别地参与越来越重要的内容。在六个大规模文本分类任务上进行的实验表明,所提出的架构在很大程度上优于以前的方法。注意力层的可视化说明该模型能够选择有用的单词和句子信息。
1.介绍
文本分类是自然语言处理的基本任务之一。其目标是为文本指定标签。它具有广泛的应用,包括主题标签(Wang和Manning,2012),情感分类(Maas等,2011; Pang和Lee,2008),以及垃圾邮件检测(Sahami等,1998)。传统的文本分类方法使用稀疏词汇特征表示文档,例如n-gram,然后在此表示中使用线性模型或核方法(Wang和Manning,2012; Joachims,1998)。 最近的方法使用深度学习,例如卷积神经网络(Blunsom等,2014)和基于长短期记忆的循环神经网络(LSTM)(Hochreiter和Schmidhuber,1997)来学习文本表示。

虽然基于神经网络的文本分类方法十分有效(Kim,2014; Zhang等,2015; Johnson和Zhang,2014; Tang等,2015),但在本文中,我们检验了的如下假设,即可以通过将具有文档结构的知识结合到模型体系结构中来获得更好的表示。 我们模型的直觉是,并非文档的所有部分都同等重要,并且确定相关部分涉及对单词的交互进行建模,而不仅仅是单独存在。
我们的主要贡献是新的神经架构(§2),即分层注意力网络(HAN),其旨在捕获与文档结构有关的两个基本信息。首先,由于文档具有层次结构(单词形成句子,句子形成文档),我们同样通过首先构建句子的表示然后将它们聚合成文档表示来构造文档表示。其次,观察到文档中的不同单词和句子具有差异性信息。此外,单词和句子的重要性高度依赖于上下文,即相同的单词或句子在不同的上下文中可能具有不同的重要性(§3.5)。为了能够保证这种上下文相关性,我们的模型包括两个层次的注意力机制(Bahdanau等,2014; Xu等,2015) - 一个在单词级别,一个在句子级别 - 在构造文档表示时,让模型将注意力再多地集中在个别单词和句子的上。为了说明,请考虑图1中的示例,这是一个简短的Yelp评论,其任务是按1-5的等级预测评级。直观地说,第一句和第三句在帮助预测评级方面有更强的信息;在这些句子中,单词delicious,a-m-a-z-i-n-g在暗示本评论中包含的积极态度方面做出了更多贡献。注意力机制有两个好处:它不仅能够带来更好的表现,而且还提供了观察哪些词和句子对分类决策有贡献,这在应用和分析中是有价值的(Shen et al., 2014; Gao et al., 2014)。
与之前的工作的主要区别在于,我们的系统使用上下文来发现一系列字符是否相关,而不是简单地过滤上下文中的(序列)字符。为了评估我们的模型与其他常见分类体系结构的性能,我们查看了六个数据集(§3)。 我们的模型明显优于之前的方法。
2. 分层注意力网络
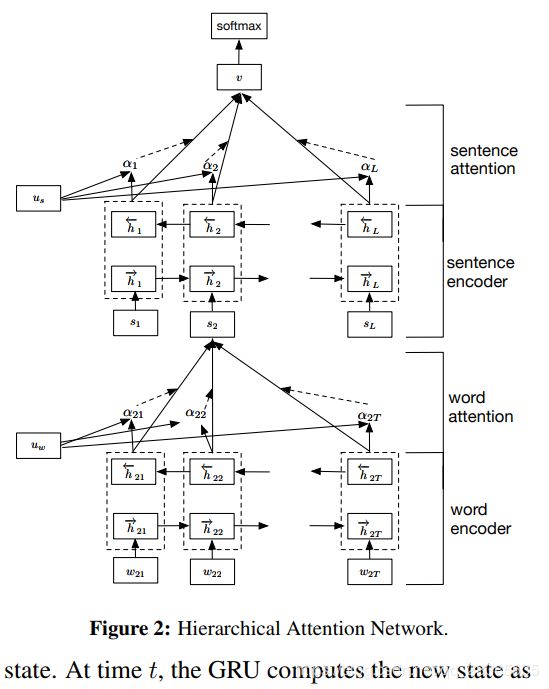
分层注意网络(HAN)的总体结构如图2所示。它由几个部分组成:
(1)一个词序列编码器;
(2)一个词级注意力层;
(3)一个句子编码器;
(4)一个句子级注意力层。
我们将在以下部分中描述不同组件的详细信息。
2.1 基于GRU的序列编码器
GRU(Bahdanau等,2014)使用门控机制来跟踪序列的状态,而不使用独立的记忆单元。有两种类型的门:重置门 r t r_t rt和更新门 z t z_t zt。 它们共同控制信息如何更新到当前状态。 在时刻 t t t,GRU新的状态的计算公式为:
h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ~ t . ( 1 ) h_t=(1−z_t)⊙h_{t−1}+z_t⊙\tilde{h}_t. \qquad(1) ht=(1−zt)⊙ht−1+zt⊙h~t.(1)
这是先前状态 h t − 1 h_{t-1} ht−1与用新序列信息计算的当前新状态 h ~ t \tilde{h}_t h~t之间的线性变换。更新门 z t z_t zt决定保留过去信息的数量以及添加了多少新信息。 z t z_t zt的计算公式如下:
z t = σ ( W z x t + U z h t − 1 + b z ) , ( 2 ) z_t = σ(W_zx_t + U_zh_{t−1} + b_z), \qquad(2) zt=σ(Wzxt+Uzht−1+bz),(2)
其中 x t x_t xt是时刻 t t t的输入序列向量。候选状态 h ~ t \tilde{h}_t h~t的计算方法类似于传统的循环神经网络(RNN):
h ~ t = t a n h ( W h x t + r t ⊙ ( U h h t − 1 ) + b h ) , ( 3 ) \tilde{h}_t = tanh(W_hx_t+r_t⊙(U_hh_{t−1}) + b_h),\qquad (3) h~t=tanh(Whxt+rt⊙(Uhht−1)+bh),(3)
这里 r t r_t rt是重置门,它控制过去状态对候选状态的贡献程度。如果 r t r_t rt为零,则会忘记先前的状态。重置门更新如下:
r t = σ ( W r x t + U r h t − 1 + b r ) ( 4 ) r_t= σ(W_rx_t + U_rh_t−1 + b_r) \qquad(4) rt=σ(Wrxt+Urht−1+br)(4)
2.2 分层注意力
这项工作中,我们关注文档级的分类。假设文档具有 L L L个句子 s i s_i si并且每个句子包含 T i T_i Ti个单词。 w i t , t ∈ [ 1 , T ] w_{it},t\in[1,T] wit,t∈[1,T],代表第 i i i个句子中的单词。所提出的模型将原始文档映射到向量表示中,然后紧接一个分类器以进行文档分类。在下文中,我们将介绍如何使用层次结构从单词向量逐步构建文档级向量。
(1)词编码(Word Encoder)
给定一个带有单词 w i t , t ∈ [ 0 , T ] w_{it},t∈[0,T] wit,t∈[0,T]的句子,我们首先通过词嵌入矩阵 W e , x i j = W e w i j W_e,x_{ij} = W_ew_{ij} We,xij=Wewij将这些单词嵌入到向量中。我们使用双向GRU(Bahdanau et al,2014)通过从单词的两个方向汇总信息来获取单词的表示,因此能够将上下文信息合并到单词的表示中。双向GRU包含前向GRU f → \overrightarrow f f,它读取从 w i 1 w_{i1} wi1到 w i T w_{iT} wiT的句子 s i s_i si,以及读取从 w i T w_{iT} wiT到 w i 1 w_{i1} wi1的后向GRU f ← \overleftarrow f f:
x i t = W e w i t , t ∈ [ 1 , T ] , h → i t = G R U → ( x i t ) , t ∈ [ 1 , T ] , h ← i t = G R U ← ( x i t ) , t ∈ [ T , 1 ] . x_{it} =W_ew_{it}, t ∈ [1, T],\\ \overrightarrow h_{it}=\overrightarrow {GRU}(x_{it}), t ∈ [1, T],\\ \overleftarrow h_{it}=\overleftarrow{GRU}(x_{it}), t ∈ [T, 1]. xit=Wewit,t∈[1,T],hit=GRU(xit),t∈[1,T],hit=GRU(xit),t∈[T,1].
我们通过连接给定单词 w i t w_{it} wit的前向隐藏态 h → i t \overrightarrow{h}_{it} hit和反向隐藏态 h ← i t \overleftarrow{h}_{it} hit来获得该单词的表示,例如 h i t = [ h → i t , h ← i t ] h_{it}=[\overrightarrow{h}_{it}, \overleftarrow{h}_{it}] hit=[hit,hit],其对以单词 w i t w_{it} wit为中心的句子信息进行了整合。
请注意,我们直接使用单词的词嵌入。对于更完整的模型,我们可以使用GRU直接从字符中获取单词向量,类似于(Ling et al,2015)。为简单起见,我们对其进行省略。
(2)词级注意力(Word Attention )
并非所有单词对句子语义的表示都有同等作用。因此,我们引入注意力机制来提取对句子语义表示重要的词,并汇总这些词的表示以形成句子向量。特别,
u i t = t a n h ( W w h i t + b w ) ( 5 ) α i t = e x p ( u i t ⊤ u w ) ∑ t e x p ( u i t ⊤ u w ) ( 6 ) s i = ∑ t α i t h i t . ( 7 ) u_{it}= tanh(W_wh_{it} + b_w)\qquad (5)\\ α_{it}=\frac{exp(u^⊤_{it}u_w)}{∑_texp(u^⊤_{it}u_w)}\qquad(6)\\ s_i =∑_tα_{it}h_{it}.\qquad(7) uit=tanh(Wwhit+bw)(5)αit=∑texp(uit⊤uw)exp(uit⊤uw)(6)si=t∑αithit.(7)
也就是说,我们首先将 h i t h_{it} hit通过单层MLP提供单词表示以获取作为 h i t h_{it} hit的隐藏表示 u i t u_{it} uit,然后我们通过计算与单词级别上下文向量 u w u_w uw的相似性来测量单词作为 u i t u_it uit的重要性,并进行softmax归一化来获得 α i t α_{it} αit。之后,我们计算基于权重的单词表示的加权来获得句子向量 s i s_i si。上下文向量 u w u_w uw可以被视为固定问题的“高级表示”,即“哪些是有用的单词”(Sukhbaatar等,2015; Kumar等,2015)。 在训练过程中随机初始化并联合学习单词上下文向量 u w u_w uw。
(3)句子编码(Sentence Encoder)
对于给定的句子向量 s i s_i si,我们可以以类似的方式获得文档向量。我们首先使用双向GRU来编码句子:
w i 1 w_{i1} wi1的后向GRU f ← \overleftarrow f f:
h → i = G R U → ( s i ) , i ∈ [ 1 , L ] , h ← i = G R U ← ( s i ) , s ∈ [ L , 1 ] . \overrightarrow h_{i}=\overrightarrow {GRU}(s_{i}), i ∈ [1, L],\\ \overleftarrow h_{i}=\overleftarrow{GRU}(s_{i}), s ∈ [L, 1]. hi=GRU(si),i∈[1,L],hi=GRU(si),s∈[L,1].
我们通过连接前向隐藏态 h → i \overrightarrow{h}_{i} hi和反向隐藏态 h ← i \overleftarrow{h}_{i} hi来获得句子 i i i的表示,例如 h i = [ h → i , h ← i ] h_{i}=[\overrightarrow{h}_{i}, \overleftarrow{h}_{i}] hi=[hi,hi],其对以句子 i i i为中心的文档信息进行了整合。
(2)句子级注意力(Sentence Attention)
为了奖励那些正确分类文档的句子,我们再次使用注意机制并引入句子级别的上下文向量 u s u_s us,并使用该向量来衡量句子的重要性。 这产生了:
u i = t a n h ( W s h i + b s ) ( 8 ) α i = e x p ( u i ⊤ u s ) ∑ t e x p ( u i ⊤ u s ) ( 9 ) v = ∑ t α i h i . ( 10 ) u_{i}= tanh(W_sh_{i} + b_s)\qquad (8)\\ α_{i}=\frac{exp(u^⊤_{i}u_s)}{∑_texp(u^⊤_{i}u_s)}\qquad(9)\\ v =∑_tα_{i}h_{i}.\qquad(10) ui=tanh(Wshi+bs)(8)αi=∑texp(ui⊤us)exp(ui⊤us)(9)v=t∑αihi.(10)
其中 v v v是文档向量,它总合了文档中句子的所有信息。类似地,句子级别上下文向量 u s u_s us可以在训练过程中随机初始化并联合学习。
2.3 文档分类
文档向量 v v v是文档的高级表示,可用作文档的分类:
p = s o f t m a x ( W c v + b c ) . ( 11 ) p = softmax(W_cv + b_c). (11) p=softmax(Wcv+bc).(11)
我们使用正确标签的负对数概率作为训练的损失:
L = − ∑ d l o g p d j , ( 12 ) L = −∑_dlog p_{dj} , (12) L=−d∑logpdj,(12)
其中, j j j是文档 d d d的标签。