爬取微博评论并提取主要关键词(二)
在实现了微博评论爬取之后,可以对微博评论提取关键词了。
具体思路是找自然语言处理包,在网上查了半天,中文包目前就看到推荐的snownlp以及jieba。看了一下它们各自的案例介绍,感觉snownlp里面的功能还是没有jieba里面的丰富,特别是不知道snownlp如何自定义分词,而jieba可以比较简单的添加自定义分词以及词性,于是就选了jieba包。
首先我就针对其中一条微博的评论做了文本处理,代码如下:
import jieba
import jieba.analyse
import jieba.posseg as pseg
import re
import jieba.analyse
import jieba.posseg as pseg
import re
jieba.suggest_freq('月子',True)
jieba.add_word('月子',tag='n')
jieba.suggest_freq('无创',True)
jieba.add_word('无创',tag='n')
jieba.suggest_freq('子宫',True)
jieba.add_word('子宫',tag='n')
jieba.suggest_freq('月嫂',True)
jieba.add_word('月嫂',tag='n')
jieba.suggest_freq('例假',True)
jieba.add_word('例假',tag='n')
jieba.suggest_freq('二胎',True)
jieba.add_word('二胎',tag='n')
jieba.add_word('月子',tag='n')
jieba.suggest_freq('无创',True)
jieba.add_word('无创',tag='n')
jieba.suggest_freq('子宫',True)
jieba.add_word('子宫',tag='n')
jieba.suggest_freq('月嫂',True)
jieba.add_word('月嫂',tag='n')
jieba.suggest_freq('例假',True)
jieba.add_word('例假',tag='n')
jieba.suggest_freq('二胎',True)
jieba.add_word('二胎',tag='n')
jieba.suggest_freq('打掉',True)
jieba.add_word('打掉',tag='v')
jieba.suggest_freq('月子中心',True)
jieba.add_word('月子中心',tag='n')
jieba.suggest_freq('怀孕',True)
jieba.add_word('怀孕',tag='v')
jieba.suggest_freq('备孕',True)
jieba.add_word('备孕',tag='n')
jieba.suggest_freq('预产期',True)
jieba.add_word('预产期',tag='n')
jieba.suggest_freq('保胎',True)
jieba.add_word('保胎',tag='n')
jieba.add_word('打掉',tag='v')
jieba.suggest_freq('月子中心',True)
jieba.add_word('月子中心',tag='n')
jieba.suggest_freq('怀孕',True)
jieba.add_word('怀孕',tag='v')
jieba.suggest_freq('备孕',True)
jieba.add_word('备孕',tag='n')
jieba.suggest_freq('预产期',True)
jieba.add_word('预产期',tag='n')
jieba.suggest_freq('保胎',True)
jieba.add_word('保胎',tag='n')
jieba.suggest_freq('引产',True)
jieba.add_word('引产',tag='n')
jieba.suggest_freq('避孕',True)
jieba.add_word('避孕',tag='n')
jieba.suggest_freq('顺产',True)
jieba.add_word('顺产',tag='n')
jieba.suggest_freq('一胎',True)
jieba.add_word('一胎',tag='n')
jieba.suggest_freq('头胎',True)
jieba.add_word('头胎',tag='n')
jieba.suggest_freq('陪护',True)
jieba.add_word('陪护',tag='n')
jieba.add_word('引产',tag='n')
jieba.suggest_freq('避孕',True)
jieba.add_word('避孕',tag='n')
jieba.suggest_freq('顺产',True)
jieba.add_word('顺产',tag='n')
jieba.suggest_freq('一胎',True)
jieba.add_word('一胎',tag='n')
jieba.suggest_freq('头胎',True)
jieba.add_word('头胎',tag='n')
jieba.suggest_freq('陪护',True)
jieba.add_word('陪护',tag='n')
wordlist=[]
typelist=[]
for i in range(len(record_list)):
a=re.sub("[A-Za-z0-9\!\%\[\]\,\。\$\:\<\>\=\'\/\.\-\"\;\@\回复\_\#]", "", str(record_list[i]))
words=pseg.cut(a)
for w in words:
wordlist.append(w.word)
typelist.append(w.flag)
all_dic=pd.DataFrame(columns=['word','type','count'])
all_dic['word']=wordlist
all_dic['type']=typelist
all_dic['count']=1
all_dic=all_dic[all_dic['type']!='x']##剔除标点符号
df_word_count=all_dic[['word','type','count']].groupby(['word','type'],as_index=False).sum()
##上面的方式得到所有非标点符号的分词以及其词性type和总的计数值count,也许有更简单的方法...
all_dic['word']=wordlist
all_dic['type']=typelist
all_dic['count']=1
all_dic=all_dic[all_dic['type']!='x']##剔除标点符号
df_word_count=all_dic[['word','type','count']].groupby(['word','type'],as_index=False).sum()
##上面的方式得到所有非标点符号的分词以及其词性type和总的计数值count,也许有更简单的方法...
df_word_count_n=df_word_count[df_word_count['type']=='n']##得到所有名词
df_word_count_n.sort_values(by=['count'],ascending=False,inplace=True)##对所有名词按照count由高到低排序
#df_word_count_n.head()##得到高频的名词
df_word_count_a=df_word_count[df_word_count['type']=='a']##得到所有形容词
df_word_count_a.sort_values(by=['count'],ascending=False,inplace=True)##对所有名词按照count由高到低排序
df_word_count_d=df_word_count[df_word_count['type']=='d']##得到所有副词
df_word_count_d.sort_values(by=['count'],ascending=False,inplace=True)
df_word_count_n.sort_values(by=['count'],ascending=False,inplace=True)##对所有名词按照count由高到低排序
#df_word_count_n.head()##得到高频的名词
df_word_count_a=df_word_count[df_word_count['type']=='a']##得到所有形容词
df_word_count_a.sort_values(by=['count'],ascending=False,inplace=True)##对所有名词按照count由高到低排序
df_word_count_d=df_word_count[df_word_count['type']=='d']##得到所有副词
df_word_count_d.sort_values(by=['count'],ascending=False,inplace=True)
df_word_count_v=df_word_count[df_word_count['type']=='v']##得到所有动词
df_word_count_v.sort_values(by=['count'],ascending=False,inplace=True)
df_word_count_v.sort_values(by=['count'],ascending=False,inplace=True)
做文本处理,实际上很多时候还是得人工多看,然后把一些关键词放入词库(特别是医疗方向的词库,暂时没有看到合适的词库),然后分词进行词频统计。如果不进行自定义分词(特别是医疗行业分词,专业性极强,在大部分公开中文自然语言处理包里面都不会有相关词组),那么分词得出的结论一般是‘医生’,‘不’,‘是’,‘月’,‘中心’等等毫无意义的词。
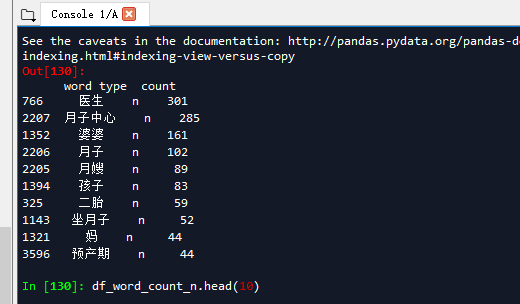
自定义词组后,得到结果如下:
参考:https://blog.csdn.net/qq_21238927/article/details/80172619
https://blog.csdn.net/flysky1991/article/details/73948971
https://blog.csdn.net/yibo492387/article/details/78783041
http://www.cnblogs.com/jiayongji/p/7119065.html