机器学习基础知识(一):梯度下降,L2,L1,L0范数
机器学习
机器学习,让机器学习某种知识或规律的过程。

机器学习按照情景来分,可以分为监督学习,半监督学习,无监督学习,transfer learning,强化学习等;按照任务,可以分为回归,分类,结构性学习等;按照方法分,可以分为线性模型,非线性模型(深度学习,SVM,决策树,KNN)等。
泰勒展开式
泰勒公式是将一个在x=x0处具有n阶导数的函数f(x)利用关于(x-x0)的n次多项式来逼近函数的方法。
若函数f(x)在包含x0的某个闭区间[a,b]上具有n阶导数,且在开区间(a,b)上具有(n+1)阶导数,则对闭区间[a,b]上任意一点x,成立下式:
![]()
其中,![]() 表示f(x)的n阶导数,等号后的多项式称为函数f(x)在x0处的泰勒展开式,剩余的Rn(x)是泰勒公式的余项,是(x-x0)n的高阶无穷小。
表示f(x)的n阶导数,等号后的多项式称为函数f(x)在x0处的泰勒展开式,剩余的Rn(x)是泰勒公式的余项,是(x-x0)n的高阶无穷小。
梯度下降
推导:

代码:
#!usr/bin/python3
# coding:utf-8
# BGD 批梯度下降代码实现
# SGD 随机梯度下降代码实现
import numpy as np
import random
def batchGradientDescent(x, y, theta, alpha, m, maxInteration):
x_train = x.transpose()
for i in range(0, maxInteration):
hypothesis = np.dot(x, theta)
# 损失函数
loss = hypothesis - y
# 下降梯度
gradient = np.dot(x_train, loss) / m
# 求导之后得到theta
theta = theta - alpha * gradient
return theta
def stochasticGradientDescent(x, y, theta, alpha, m, maxInteration):
data = []
for i in range(4):
data.append(i)
x_train = x.transpose()
for i in range(0, maxInteration):
hypothesis = np.dot(x, theta)
# 损失函数
loss = hypothesis - y
# 选取一个随机数
index = random.sample(data, 1)
index1 = index[0]
# 下降梯度
gradient = loss[index1] * x[index1]
# 求导之后得到theta
theta = theta - alpha * gradient
return theta
def main():
trainData = np.array([[1, 4, 2], [2, 5, 3], [5, 1, 6], [4, 2, 8]])
trainLabel = np.array([19, 26, 19, 20])
print(trainData)
print(trainLabel)
m, n = np.shape(trainData)
theta = np.ones(n)
print(theta.shape)
maxInteration = 500
alpha = 0.01
theta1 = batchGradientDescent(trainData, trainLabel, theta, alpha, m, maxInteration)
print(theta1)
theta2 = stochasticGradientDescent(trainData, trainLabel, theta, alpha, m, maxInteration)
print(theta2)
return
if __name__ == "__main__":
main()几个范数:L2-Norm,L1-Norm,L0-Norm
对于一个矩阵X,![]() 为它的第i行第j列元素,则它的以上范数表示为:
为它的第i行第j列元素,则它的以上范数表示为:
L2-Norm: ,即矩阵X中所有元素平方的和在开方。
,即矩阵X中所有元素平方的和在开方。
L1-Norm: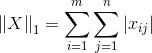 ,即矩阵X中所有元素的绝对值的和。
,即矩阵X中所有元素的绝对值的和。
L0-Norm: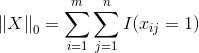 ,即矩阵X中不为0的元素的个数。
,即矩阵X中不为0的元素的个数。
1.正则化
大部分的正则化方法是在经验风险或者经验损失LempLemp(emprirical loss)上加上一个结构化风险,我们的结构化风险用参数范数惩罚Ω(θ)Ω(θ),用来限制模型的学习能力、通过防止过拟合来提高泛化能力。所以总的损失函数(也叫目标函数)为:
![]()
其中X是输入数据,y是标签,θ是参数,α∈[0,+∞]是用来调整参数范数惩罚与经验损失的相对贡献的超参数,当α=0时表示没有正则化,α越大对应该的正则化惩罚就越大。对于L1正则化,我们有:
![]()
对于L2正则化,有:
![]()
2.正则化推导
2.1 L1-Norm求导
有没有偏置的条件下,θ就是w,我们可以得到L1正则化的目标函数:
![]()
我们的目的是求得使目标函数取最小值的w∗,上式对w求导可得:
![]()
其中若w>0,则sign(w)=1;若w<0,则sign(w)=−1;若w=0,则sign(w)=0。当α=0,假设我们得到最优的目标解是w∗,用泰勒公式在w∗处展开可以得到(要注意的∇J(w∗)=0):
![]()
其中H是关于w的Hessian矩阵,为了得到更直观的解,我们简化H,假设H这对角矩阵,则有:
![]()
将上式代入到式(3.1)(3.1)中可以得到,我们简化后的目标函数可以写成这样:

从上式可以看出,w各个方向的导数是不相关的,所以可以分别独立求导并使之为0,可得:
![]()
上式的解:
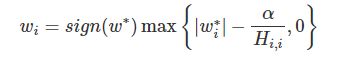
2.2 L2-Norm 求导
![]()
对其求导为:
![]()
令其为0,就可以得到w的解。
一个小小的问题:学习为什么只对参数W做正则化限制,而不对b做限制?
正则化的目的是使目标函数“平滑”,对参数W限制可以达到这个目的,而对b做限制,显而易见,只会在某个平面上上下移动目标函数而已,对目标函数的形状没有任何影响。
2. L2-Norm与L1-Norm的几何解释
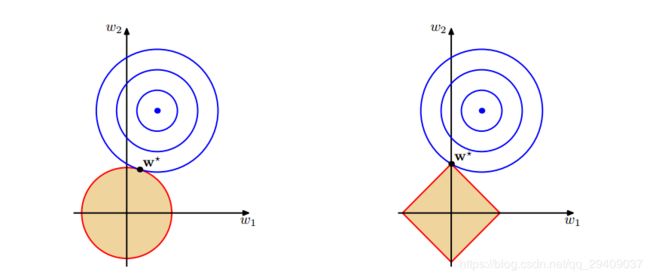
上图中的蓝色轮廓线是没有正则化损失函数的等高线,中心的蓝色点为最优解,左图、右图分别为L2、L1正则化给出的限制。可以看到在正则化的限制之下,L2正则化给出的最优解w∗是使解更加靠近原点,也就是说L2L2正则化能降低参数范数的总和。L1正则化给出的最优解w∗是使解更加靠近某些轴,而其它的轴则为0,所以L1正则化能使得到的参数稀疏化。
3.L1范数与L0范数
L0范数是指向量中非0的元素的个数。如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0。换句话说,让参数W是稀疏的。L1范数是指向量中各个元素绝对值之和,也称“稀疏规则算子”(Lasso regularization)。
为什么L1范数会使权值稀疏?有人可能会这样给你回答“它是L0范数的最优凸近似”。实际上,还存在一个更美的回答:任何的规则化算子,如果他在Wi=0的地方不可微,并且可以分解为一个“求和”的形式,那么这个规则化算子就可以实现稀疏。
既然L0可以实现稀疏,为什么不用L0,而要用L1呢?个人理解一是因为L0范数很难优化求解(NP难问题),二是L1范数是L0范数的最优凸近似,而且它比L0范数要容易优化求解。所以大家才把目光和万千宠爱转于L1范数。

系数稀疏的作用:
1)特征选择(Feature Selection):
大家对稀疏规则化趋之若鹜的一个关键原因在于它能实现特征的自动选择。一般来说,xi的大部分元素(也就是特征)都是和最终的输出yi没有关系或者不提供任何信息的,在最小化目标函数的时候考虑xi这些额外的特征,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的信息反而会被考虑,从而干扰了对正确yi的预测。稀疏规则化算子的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些没有信息的特征,也就是把这些特征对应的权重置为0。
2)可解释性(Interpretability):
另一个青睐于稀疏的理由是,模型更容易解释。例如患某种病的概率是y,然后我们收集到的数据x是1000维的,也就是我们需要寻找这1000种因素到底是怎么影响患上这种病的概率的。假设我们这个是个回归模型:y=w1*x1+w2*x2+…+w1000*x1000+b(当然了,为了让y限定在[0,1]的范围,一般还得加个Logistic函数)。通过学习,如果最后学习到的w*就只有很少的非零元素,例如只有5个非零的wi,那么我们就有理由相信,这些对应的特征在患病分析上面提供的信息是巨大的,决策性的。也就是说,患不患这种病只和这5个因素有关,那医生就好分析多了。但如果1000个wi都非0,医生面对这1000种因素,累觉不爱。
参考博客:
1.https://blog.csdn.net/qq_38906523/article/details/79851654
2.https://www.cnblogs.com/heguanyou/p/7582578.html
3.https://www.cnblogs.com/weizc/p/5778678.html