TensorFlow 模型保存/加载方法: Saver与Restore
目录
0 .保存模型 tf.train.Saver()类
tf.train.Saver.restore() 加载模型
1. 加载 图结构+模型参数 tf.train.import_meta_graph
2.只加载数据,不加载图结构 tf.train.get_checkpoint_state
3. tf.train.get_checkpoint_state() 函数说明: 找出训练时保存的模型
4. 二进制模型加载: 修改已经训练好的网络模型
5. 二进制模型制作:tensorflow的Freezing
tensorflow在训练过程中,通常不会将权重数据保存在格式文件里(这里我理解是模型文件),反而是分开保存在一个叫checkpoint的检查点文件里,当初始化时,再通过模型文件里的变量Op节点来从checkoupoint文件读取数据并初始化变量。
0 .保存模型 tf.train.Saver()类
.save(sess, ckpt文件目录)方法 : saver()与restore()只是保存了session中的相关变量对应的值,并不涉及模型的结构
Saver的作用是将我们训练好的模型的参数保存下来,以便下一次继续用于训练或测试;Restore则是将训练好的参数提取出来。Saver类训练完后,是以checkpoints文件形式保存。提取的时候也是从checkpoints文件中恢复变量。Checkpoints文件是一个二进制文件,它把变量名映射到对应的tensor值 。
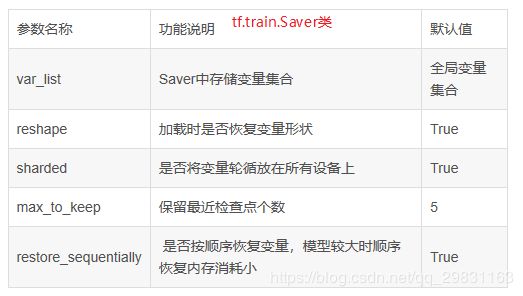
一般地,Saver会自动的管理Checkpoints文件。以max_to_keep指定保存最近的N个Checkpoints文件。
saver()可以选择global_step参数来为ckpt文件名添加数字标记:
saver.save(sess, 'my-model', global_step=0) ==> filename: 'my-model-0'
...
saver.save(sess, 'my-model', global_step=1000) ==> filename: 'my-model-1000'max_to_keep参数定义saver()将自动保存的最近n个ckpt文件,默认n=5,即保存最近的5个检查点ckpt文件。若n=0或者None,则保存所有的ckpt文件。keep_checkpoint_every_n_hours与max_to_keep类似,定义每n小时保存一个ckpt文件。
# Create a saver.
saver = tf.train.Saver(...variables...)
# Launch the graph and train, saving the model every 1,000 steps.
sess = tf.Session()
for step in xrange(1000000):
sess.run(..training_op..)
if step % 1000 == 0:
# Append the step number to the checkpoint name:
saver.save(sess, 'my-model', global_step=step)- 当var_list是字典形式{变量名字符串: 变量符号}时,相对应的restore也根据同样形式的字典将ckpt中的字符串对应的变量加载给程序中的符号, 如:saver = tf.train.Saver({"v/ExponentialMovingAverage":v})
- 如果Saver给定了字典作为加载方式,则按照字典来,如:saver = tf.train.Saver({"v/ExponentialMovingAverage":v}),否则每个变量寻找自己的name属性在ckpt中的对应值进行加载。eg:
#保存代码
saver = tf.train.Saver(max_to_keep=2)
with tf.Session() as sess:
...
saver.save(sess,'../model/model.ckpt')

checkpoint文件:二进制文件保存最新的模型
.meta文件保存了 图结构
.index文件保存了 参数名
.data文件保存了 参数值
tf.train.Saver.restore() 加载模型
saver.restore()回根据 'model.ckpt-n' 自动寻找参数名--值文件进行加载
基于checkpoint文件(ckpt)加载参数时,实际上就是用Saver.restore取代了initializer的初始化
ckpt = tf.train.get_checkpoint_state('./model/')
saver.restore(sess,ckpt.model_checkpoint_path)
#等价
saver.restore(sess,'./model/model.ckpt-0') # restore(sess, save_path)
new_saver.restore(sess, tf.train.latest_checkpoint('./model/'))sess: 保存参数的会话。save_path: 保存参数的路径。- 当从文件中恢复变量时,不需要事先对他们进行初始化,因为“恢复”自身就是一种初始化变量的方法。
- 可以使用
tf.train.latest_checkpoint()来自动获取最后一次保存的模型。如:
model_file=tf.train.latest_checkpoint('ckpt/')
saver.restore(sess,model_file)1. 加载 图结构+模型参数 tf.train.import_meta_graph
tf.train.import_meta_graph() 根据 'model.ckpt-n.meta'加载图结构,并返回saver对象
ckpt = tf.train.get_checkpoint_state('./model/') #./model为数据加载路径
saver = tf.train.import_meta_graph(ckpt.model_checkpoint_path +'.meta')
with tf.Session() as sess:
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
saver.restore(sess,ckpt.model_checkpoint_path)
2.只加载数据,不加载图结构 tf.train.get_checkpoint_state
# 只加载数据,不加载图结构,可以在新图中改变batch_size等的值
# 不过需要注意,Saver对象实例化之前需要定义好新的图结构,否则会报错
saver = tf.train.Saver()
ckpt = tf.train.get_checkpoint_state('./model/')
with tf.Session() as sess:
... #graph 定义
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
saver.restore(sess,ckpt.model_checkpoint_path)
3. tf.train.get_checkpoint_state() 函数说明: 找出训练时保存的模型
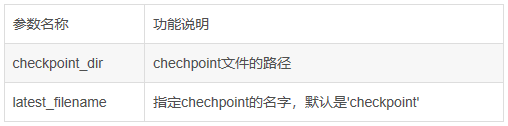
通过checkpoint文件找到模型文件名
tf.train.get_checkpoint_state(checkpoint_dir,latest_filename=None) # ckpt.model_checkpoint_path可以找出所有模型中最新的模型
ckpt = tf.train.get_checkpoint_state('/mnist/summary/train')
if ckpt and ckpt.model_checkpoint_path:
print(ckpt.model_checkpoint_path)
# ckpt.all_model_checkpoint_paths可以找出所有模型
ckpt = tf.train.get_checkpoint_state('mnist/summary/train')
if ckpt and ckpt.model_checkpoint_path:
print(ckpt.all_model_checkpoint_paths)
- model_checkpoint_path保存了最新的tensorflow模型文件的文件名,
- all_model_checkpoint_paths则有未被删除的所有tensorflow模型文件的文件名。
ckpt = tf.train.get_checkpoint_state('./model/') # 通过 'checkpoint文件' 找到模型文件名
ckpt 包含的属性:
- model_checkpoint_path: 保存了'./model'中最新的tensorflow模型文件的文件名
- all_model_checkpoint_paths: 保存了'./model'中所有tensorflow模型文件的文件名
ckpt = tf.train.get_checkpoint_state('./model/')
print(ckpt.model_checkpoint_path)

4. 二进制模型加载: 修改已经训练好的网络模型
# 新建空白图
self.graph = tf.Graph()
# 空白图列为默认图
with self.graph.as_default():
# 二进制读取模型文件
with tf.gfile.FastGFile(os.path.join(model_dir,model_name),'rb') as f:
# 新建GraphDef文件,用于临时载入模型中的图
graph_def = tf.GraphDef()
# GraphDef加载模型中的图
graph_def.ParseFromString(f.read())
# 在空白图中加载GraphDef中的图
tf.import_graph_def(graph_def,name='')
# 在图中获取张量需要使用graph.get_tensor_by_name加张量名
# 这里的张量可以直接用于session的run方法求值了
# 补充一个基础知识,形如'conv1'是节点名称,而'conv1:0'是张量名称,表示节点的第一个输出张量
self.input_tensor = self.graph.get_tensor_by_name(self.input_tensor_name)
self.layer_tensors = [self.graph.get_tensor_by_name(name + ':0') for name in self.layer_operation_names]
5. 二进制模型制作:tensorflow的Freezing
将模型文件和权重文件整合合并为一个文件,主要用途是便于发布 官方解释可参考
tensorflow将模型和权重数据分开保存,这使发布产品时不方便,而freeze_graph.py脚本文件可以将这两文件整合合并成一个文件。 【参考: TensorFlow 模型保存/加载方法】
参数:
- input_graph:(必选)模型文件,可以是二进制的pb文件,或文本的meta文件,用input_binary来指定区分
- input_checkpoint:(必选)检查点数据文件。训练时,给Saver用于保存权重、偏置等变量值。这时用于模型恢复变量值。
- output_node_names:(必选)输出节点的名字,有多个时用逗号分开。用于指定输出节点,将没有在输出线上的其它节点剔除。
- output_graph:(必选) 用来保存整合后的模型输出文件。
python tensorflow/python/tools/free_graph.py \
--input_graph=some_graph_def.pb \ 注意:这里的pb文件是用tf.train.write_graph方法保存的
--input_checkpoint=model.ckpt.1001 \ 注意:这里若是r12以上的版本,只需给.data-00000....前面的文件名,如:model.ckpt.1001.data-00000-of-00001,只需写model.ckpt.1001
--output_graph=/tmp/frozen_graph.pb
--output_node_names=softmax