OpenCv学习笔记15--传统目标检测(HOG+SVM)
此opencv系列博客只是为了记录本人对<>的学习笔记,所有代码在我的github主页https://github.com/RenDong3/OpenCV_Notes.
欢迎star,不定时更新...
推荐前辈链接:https://www.cnblogs.com/zyly/p/9651261.html,解释的非常清晰
目标检测是用来确定图像上某个区域是否有我们要识别的对象,目标识别是用来判断图片上这个对象是什么。识别通常只处理已经检测到对象的区域,例如,人们总是会使在已有的人脸图像的区域去识别人脸。
传统的目标检测方法与识别不同于深度学习方法,后者主要利用神经网络来实现分类和回归问题。在这里我们主要介绍如何利用OpecnCV来实现传统目标检测和识别,在计算机视觉中有很多目标检测和识别的技术,基于深度学习的目标检测算法可以观看下图,这是github里copy的.后面可能会对算法进行更全面的综述(完全阅读理解全部论文之后,[嘿嘿])

这里是介绍利用HOG+SVM进行行人检测,作为传统目标检测算法的学习...
一 HOG
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子,是与SIFT、SURF、ORB属于同一类型的描述符。HOG不是基于颜色值而是基于梯度来计算直方图的,它通过计算和统计图像局部区域的梯度方向直方图来构建特征。HOG特征结合SVM分类器已经被广泛应用到图像识别中,尤其在行人检测中获得了极大的成功。需要提醒的是,HOG+SVM进行行人检测的方法是法国研究人员Dalal 在2005的CVPR上提出的,而如今虽然有很多J基于深度学习的行人检测算法不断提出,效果也很不错,但是传统的目标检测算法(HOG+SVM)还是有必要了解的.
1、主要思想
此方法的基本观点是:局部目标的外表和形状可以被局部梯度或边缘方向的分布很好的描述,即使我们不知道对应的梯度和边缘的位置。(本质:梯度的统计信息,梯度主要存在于边缘的地方)
2、具体实施方法
首先将图像分成小的连通区域,我们把它叫细胞单元。然后采集细胞单元中各像素点的梯度的或边缘的方向直方图。最后把这些直方图组合起来就可以构成特征描述器(HOG descriptor)。
为了对光照和阴影有更好的不变性,需要对直方图进行对比度归一化,这可以通过把这些直方图在图像的更大的范围内(我们把它叫做区间或者block)进行对比度归一化。首先我们计算出各直方图在这个区间中的密度,然后根据这个密度对区间中的各个细胞单元做归一化。通过这个归一化后,能对光照变化和阴影获得更 好的效果。
我们把归一化的块描述符叫作HOG描述子。
3、优点
与其他的特征描述方法相比,HOG有很多优点。
首先,由于HOG是在图像的局部方格单元上操作,所以它对图像几何的和光学的形变都能保持很好的不 变性,这两种形变只会出现在更大的空间领域上。
其次,在粗的空域抽样、精细的方向抽样以及较强的局部光学归一化等条件下,只要行人大体上能够保持直立的姿 势,可以容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效果。因此HOG特征是特别适合于做图像中的人体检测。
HOG是在密集采样的图像块中求取的,在计算得到的HOG特征向量中隐含了该块与检测窗口之间的空间位置关系。
4、HOG的缺陷:
很难处理遮挡问题,人体姿势动作幅度过大或物体方向改变也不易检测(这个问题后来在DPM中采用可变形部件模型的方法得到了改善);
跟SIFT相比,HOG没有选取主方向,也没有旋转梯度方向直方图,因而本身不具有旋转不变性(较大的方向变化),其旋转不变性是通过采用不同旋转方向的训练样本来实现的;
跟SIFT相比,HOG本身不具有尺度不变性,其尺度不变性是通过缩放检测窗口图像的大小来实现的;
此外,由于梯度的性质,HOG对噪点相当敏感,在实际应用中,在block和cell划分之后,对于得到各个区域,有时候还会做一次高斯平滑去除噪点。(有时候去噪后会大大降低准确度哦!!)
HOG特征提取算法的实现过程:
大概过程:
HOG特征提取方法就是将一个image(你要检测的目标或者扫描窗口):
1)灰度化(将图像看做一个x,y,z(灰度)的三维图像);
2)采用Gamma校正法对输入图像进行颜色空间的标准化(归一化);目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰;
3)计算图像每个像素的梯度(包括大小和方向);主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
4)将图像划分成小cells(例如8*8像素 / cell);
5)统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的descriptor;
6)将每几个cell组成一个block(例如2*2个cell / block),块内归一化梯度直方图,去除光照、阴影等变化,增加鲁棒性, 一个block内所有cell的特征descriptor串联起来便得到该block的HOG特征descriptor。
7)将图像image内的所有block的HOG特征descriptor串联起来就可以得到该image(你要检测的目标)的HOG特征descriptor了。这个就是最终的可供分类使用的特征向量了。
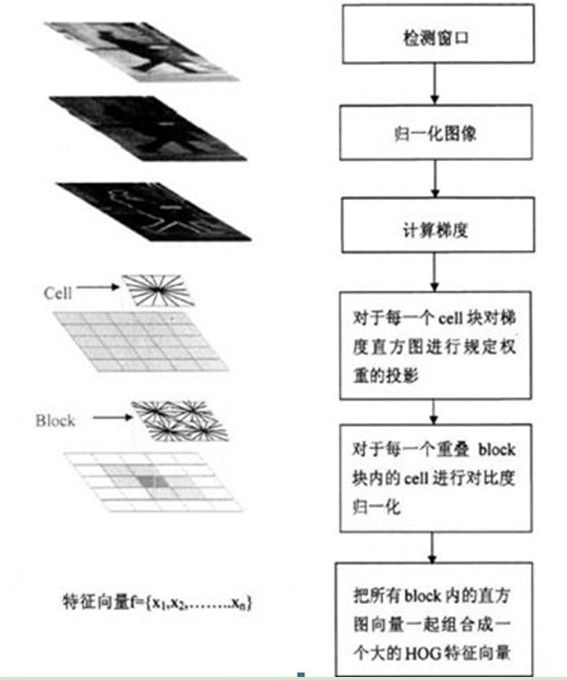
目标检测
将检测窗口中的所有块的HOG描述子组合起来就形成了最终的特征向量,然后使用SVM分类器进行行人检测。下图描述了特征提取和目标检测流程。检测窗口划分为重叠的块,对这些块计算HOG描述子,形成的特征向量放到线性SVM中进行目标/非目标的二分类。检测窗口在整个图像的所有位置和尺度上进行扫描,并对输出的金字塔进行非极大值抑制来检测目标。(检测窗口的大小一般为128×64)

说明一下对于HOG特征提取算法的具体实现这里并不会做过多介绍,因为篇幅实在是太长了,所以这里给出两位前辈的讲解链接:
基于传统图像处理的目标检测与识别(HOG+SVM附代码)
图像三大特征
使用opencv检测行人
下面我们介绍使用OpenCV自带的HOGDescriptor()函数对人进行检测:
完整代码如下:
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 24 09:17:37 2018
@author: ren_dong
"""
'''
HOG检测人
'''
import cv2
import numpy as np
def is_inside(o, i):
'''
判断矩形o是不是在i矩形中
args:
o:矩形o (x,y,w,h)
i:矩形i (x,y,w,h)
'''
ox, oy, ow, oh = o
ix, iy, iw, ih = i
return ox > ix and oy > iy and ox + ow < ix + iw and oy + oh < iy + ih
def draw_person(img, person):
'''
在img图像上绘制矩形框person
args:
img:图像img
person:人所在的边框位置 (x,y,w,h)
'''
x, y, w, h = person
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2)
def detect_test():
'''
检测人
'''
img = cv2.imread('./images/person.jpg')
rows, cols = img.shape[:2]
sacle = 0.5
print('img',img.shape)
img = cv2.resize(img, dsize=(int(cols * sacle), int(rows * sacle)))
# print('img',img.shape)
# img = cv2.resize(img, (128,64))
# 创建HOG描述符对象
# 计算一个检测窗口特征向量维度:(64/8 - 1)*(128/8 - 1)*4*9 = 3780
'''
winSize = (64,128)
blockSize = (16,16)
blockStride = (8,8)
cellSize = (8,8)
nbins = 9
hog = cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nbins)
'''
hog = cv2.HOGDescriptor()
# hist = hog.compute(img[0:128,0:64]) 计算一个检测窗口的维度
# print(hist.shape)
detector = cv2.HOGDescriptor_getDefaultPeopleDetector()
print('detector', type(detector), detector.shape)
hog.setSVMDetector(detector)
# 多尺度检测,found是一个数组,每一个元素都是对应一个矩形,即检测到的目标框
found, w = hog.detectMultiScale(img)
print('found', type(found), found.shape)
# 过滤一些矩形,如果矩形o在矩形i中,则过滤掉o
found_filtered = []
for ri, r in enumerate(found):
for qi, q in enumerate(found):
# r在q内?
if ri != qi and is_inside(r, q):
break
else:
found_filtered.append(r)
for person in found_filtered:
draw_person(img, person)
cv2.imshow('img', img)
cv2.waitKey()
cv2.destroyAllWindows()
if __name__ == '__main__':
detect_test()实现结果:

在导入模块后,定义两个非常简单的函数;is_inside和draw_person,他们会完成两个简单的任务,即确定某矩形是否完全包含在另一个矩形中,并绘制矩形来框住检测到的人.
然后加载图像,并通过如下方法调用HOGDescriptor:
cv2.HOGDescriptor()在这之后,指定HOGDesricptor作为检测人的默认检测器.这可通过setSVMDetector()方法实现,如果想要参考SVM的话可以观看我之前转载的博客.
另外说明一点,这里与人脸检测算法不一样,不需要在使用目标检测算法之前将原始图像转换为灰度格式.
该检测方法将返回一个与矩形相关的数组,用户可用该数组在图像上绘制形状,但如果这样做,就会发现某些矩形完全包含在其他矩形中,这说明检测出现了错误.如果矩形被完全包含在另外一个矩形中,可确定该矩形应被丢弃.
这就是为什么要定义is_inside函数的原因,以及为什么要遍历检测结果来丢掉不含有检测目标的区域.
如果运行该脚本,就会看到在图像中有一个矩形框将人框住.
为了避免篇幅过长,这里只作为传统检测方法(HOG+SVM)的第一部分,未完待续...
参考博客:
https://www.cnblogs.com/zyly/p/9651261.html
https://blog.csdn.net/singdancer/article/details/52974839