Pytorch学习笔记1--自定义数据读取
最近在学习deep learning, 另外呢对pytorch框架感觉还不错,所以作为自己的入门框架进行学习,今天总结一下如何使用pytorch进行自定义数据读取.
在解决深度学习问题中,往往需要花费大量的时间和精力去处理数据,包括图像,文本,语音数据等.数据的处理对于训练神经网络来说十分重要,良好的数据不仅会加速模型训练,也会提高模型效果.考虑到这一点,pytorch提供了几个高效便捷的工具,以便使用者进行数据处理或者增强操作,同时可以并行化加速数据加载.
这里我们以Kaggle经典挑战赛"Dog vs. Cat"的数据为例,讲解如何处理数据..."Dog vs.Cat"是一个传统的二分类问题,判断一张图片是猫还是狗,其训练集包含25000张图片,这些图片均放置在同一文件夹下,命名格式为
我们只是做一些基础操作,主要是对代码进行熟悉和了解掌握,所以只是选择了几张图片作为示例,将几张图片放到一个文件夹下,根据文件名的前缀判断是狗还是猫 .
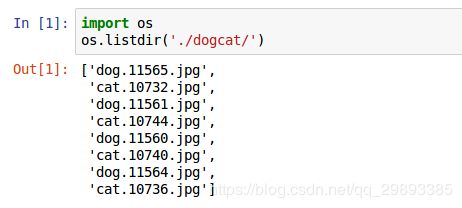
OK ,第一步我们先使用os.listdir()打印出dogcat文件夹下的所有文件名,可以很明显看出我们选用了kaggle数据训练集的8张图片
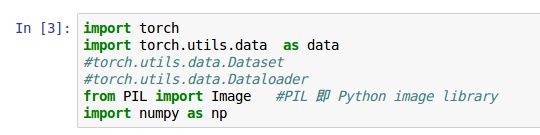
第二步 导入必要模块
torch.utils.data是我们进行数据处理要用到的,如果使用torchvision里面的数据集的话,会牵涉到 torch.utils.data.Dataset
和torch.utils.data.DataLoader两个类
PIL 即 python image libray 是python图像处理的标准库
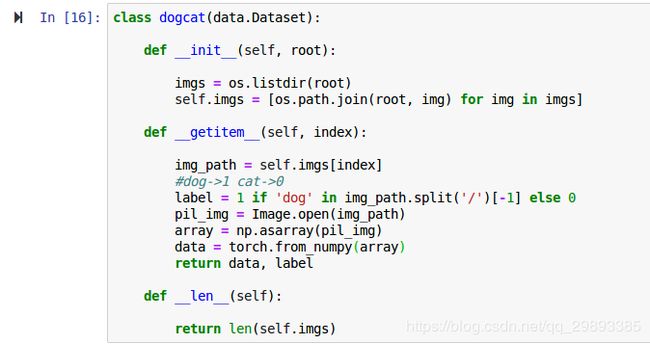
第三步 定义数据读取的类
在pytorch中,数据加载可通过自定义的数据集对象实现.数据集对象被抽象为Dataset类,实现自定义的数据集需要继承Dataset,并实现两个python魔法方法.
__getitem__(): 返回一条数据或一个样本
__len__(): 返回样本的数量
下面进行详细解释一下代码:
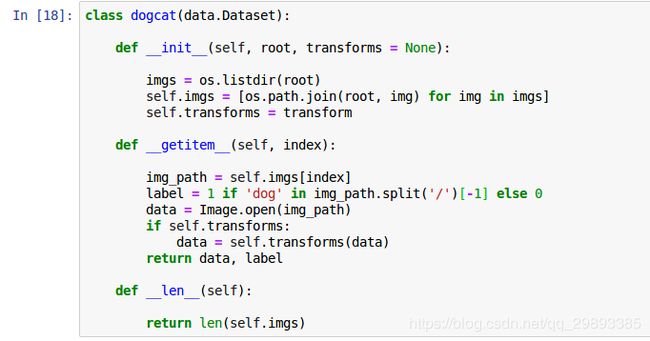
class dogcat(data.Dataset): ###继承Dataset类,调用自定义数据集
def __init__(self, root):
'''
所有图片的绝对路径
这里不加载图片,只是指定路径
当调用__getitem()时才会真正读图片
'''
imgs = os.listdir(root)
self.imgs = [os.path.join(root, img) for img in imgs]
#os.path.join()实现路径拼接, 遍历得到self.imgs
#self.imgs是包含所有图片的list即[]
def __getitem__(self, index):
#返回一张图片的数据 img label
img_path = self.imgs[index]
#通过index得到路径
label = 1 if 'dog' in img_path.split('/')[-1] else 0
#dog->1 cat->0
#string.split()用来分割字符串,这里以'/'作为分割标识
pil_img = Image.open(img_path)
#读取图片
array = np.asarray(pil_img)
#转换为数组array
data = torch.from_numpy(array)
#从numpy数组变为tensor (适合torch调用)
return data, label
def __len__(self):
#返回数据集所有图片的个数
return len(self.imgs) 下面显示的是最后一步
调用dogcat类,给定root,打印出所有img的尺寸,均值,以及根据前缀所赋予的标签..
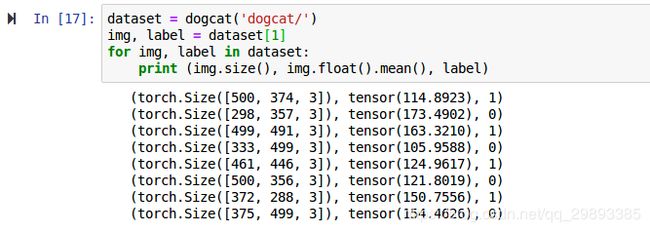
通过上面的代码,我们了解了如何自定义自己的数据集,并可以依次获取..但是这里返回的数据并不适合作为实际训练使用,主要具有以下问题:
~ 返回样本的形状不一即每张图片大小不一样 , 这对于需要取batch训练的神经网络很不友好
~ 返回的样本的数值很大,未归一化到[-1,1], 训练LOSS会很大,并且很慢
针对以上问题,pytorch提供了torchvision. 它是一个视觉工具包,提供了很多视觉图像处理的工具,其中transforms模块提供了对PIL Image 和tensor 对象的常用操作.

对 PIL Image的常见操作如下.
Resize(): 调整图像尺寸
CenterCrop(), RandomCrop(), RandomSizeCrop() : 裁剪图片

Pad: 填充

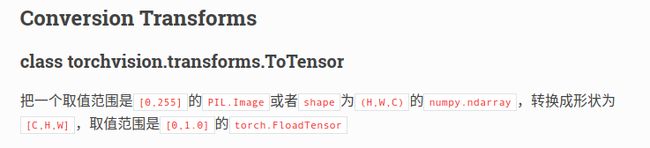
ToTensor: 将PIL Image对象转成Tensor, 会自动将[0, 255]归一化到[0,1],并且图片shape会由 [H, W, C] -- >[C, H, W]
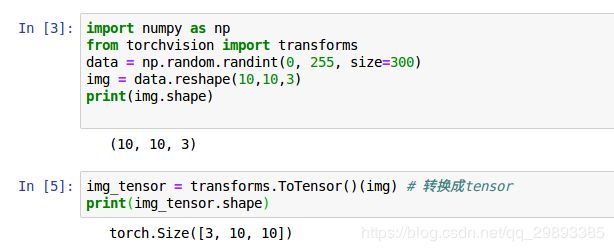
对Tensor的常见操作如下:
Normalize: 标准化,即 减均值 然后除以 标准差 (tensor - mean) / std

ToPILImage : 将Tensor转为PILImage对象

如果要对图像进行多个操作,可以用Compose将这些操作拼接起来,这是经常用到的!!
下面给出改进版的数据读取代码

可以看到前两步是没有变化的,只是为了调用trochvisin.transforms函数,前面导入模块中需要添加一句
import torchvision.transforms as transforms
下面对第三步进行讲解:
transform = transforms.Compose([
###使用Compose拼接操作
### class torchvision.transforms.Scale(size, interpolation=2)
将输入的`PIL.Image`重新改变大小成给定的`size`,`size`是最小边的边长。举个例子,如果原图的`height>width`,那么改变大小后的图片大小是`(size*height/width, size)`。
transforms.Resize(224),
#缩放图片, 保持长宽比不变, 最短边为224像素
transforms.CenterCrop(224),
#中心裁剪 即从图片中间切出224*224的图片
transforms.ToTensor(),
#转换为Tensor
transforms.Normalize(mean = [0.5, 0.5, 0.5], std = [0.5, 0.5, 0.5])
#标准化到[-1, 1]
0-0.5 = -0.5, 1-0.5 = 0.5 tensor1 = tensor - mean
[-0.5, 0.5]/0,5 --> [-1, 1] tensor2 = tensor1 / std
])下面两步基本没啥变化,只是添加了一句transforms操作作为预处理
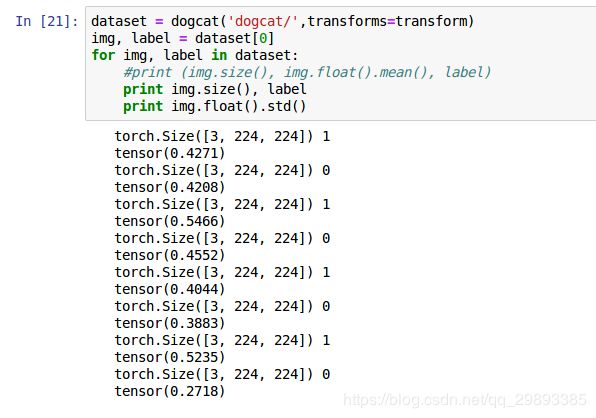
可以很明显看到std已经归一化到[-1,1]之间,并且基本在0.4-0.5附近波动
OK, 今天就到这里了,发现写博客第一次思路如此清晰,看来coding能力有那么一点点的提升,持续充电中,不定时跟新........