Kaggle比赛入门题目:Titanic
首先介绍下Kaggle比赛,这个比赛是专门为机器学习和数据挖掘相关从业人员和学习者准备的比赛,目前由谷歌提供支持运行,每场比赛设有几万到几百万的奖金池,但小编只是奔着学习的目的去体验的。有志同道合者可在后台联系小编。
好了,下面正是进入今天的主题:Kaggle入门题:预测泰坦尼克号上乘客是否幸存。
发生在1912年的泰坦尼克事件,导致船上2224名游客死亡1502(我们的男主角也牺牲了),作为事后诸葛亮,我们掌握了船上乘客的一些个人信息和一部分乘客是否获救的信息。我们希望能通过探索这些数据,发现一些不为人知的秘密。。。,随便预测下另外一部分乘客是否能够获救。
第一步:加载数据和数据概览
#加载数据
trainData = pd.read_csv('train.csv')
testData = pd.read_csv('test.csv')
#数据概览
print(trainData.info())数据大致信息如下:

训练数据样本一共有891条,信息包括:
PassengerId : 乘客ID
Survived : 0=死亡,1=幸存
Pclass : 经济等级 1=high 2=middle 3=low
Name :乘客姓名
Sex : 性别
Age : 年龄
Sibsp : 在船上的兄弟姐妹个数
Parch :在船上的父母孩子个数
Ticket : 船票号码
Fare : 票价
Cabin : 客舱号码
Embarked : 登船港口
真实数据如下:

第二步:数据探索
#数据探索
print(trainData.describe())结果如下:
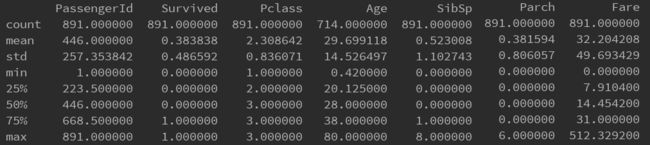
从中我们可以得出 Survived的平均值为0.383838,表明大部分乘客没有幸存;Pclass的平均值为2.308642,故乘客的平均经济水平中下;乘客年龄的平均值为29.7。
好了,让我们深入了解一下,看看上述的特征到底和是否幸存有无相关性。
2.1 Pclass与Survived的关系
为了了解经济阶层与是否幸存的关系,绘制了一张各阶层死亡和幸存人数的统计图,绘图Python如下:
#探索Pclass和是否幸存的关系
dead = [0,0,0]
alive = [0,0,0]
trainData = np.array(trainData)
for data in trainData:
if data[1] == 0:
dead[data[2]-1] += 1
else:
alive[data[2]-1] += 1
pos = [1,2,3]
ax = plt.figure(figsize=(8,6)).add_subplot(111)
ax.bar(pos, dead, color='r', alpha=0.6, label='死亡')
ax.bar(pos, alive, color='g', bottom=dead, alpha=0.6, label='幸存')
ax.legend(fontsize=16, loc='best')
ax.set_xticks(pos)
ax.set_xticklabels(['Pclass%d'%(i) for i in range(1,4)], size=15)
ax.set_title('经济阶层与是否幸存统计', size=20)
plt.show()
从图中能得到如下信息:
人数最多的阶层是Pclass3,即低水平收入者;
死亡比例最高的阶层是低水平收入阶层,幸存比例最高的阶层是高水平收入者,这也符合现实,经济阶层高的人群获救的概率较大。
2.2 Age与Survived的关系
首先看下乘客中的年龄分布,由于有些乘客的年龄信息为空,暂时不考虑这部分乘客。绘图Python代码如下:
ageDis = {}
trainData = np.array(trainData)
for data in trainData:
if np.isnan(data[5]):
pass
else:
if data[5] not in ageDis.keys():
ageDis[data[5]] = 0
ageDis[data[5]] += 1
ageDis = sorted(ageDis.items(),key=lambda item:item[0])
age = []
ageCount = []
for d in ageDis:
age.append(d[0])
ageCount.append(d[1])
plt.bar(age,ageCount)
plt.title('年龄分布图')
plt.xlabel('年龄')
plt.ylabel('人数',verticalalignment='baseline',horizontalalignment='left')
plt.show()
从图中可以看出,年龄大致呈现正态分布,为了处理上述说的有些乘客的年龄缺失问题,我们可以在【mean-std,mean+std】区间的一个随机数作为年龄的缺省值。Python代码如下:
'''处理年龄缺失'''
for i in range(len(trainData)):
if np.isnan(trainData.iloc[i,5]):
trainData.iloc[i, 5] = random.randint(29-14,29+14)下面我们定义一下年龄段的划分,0-6岁为孩童,7-17岁为少年,18-40岁为青年,41-65岁为中年,66以后为老年。Python代码如下:
'''年龄段划分'''
def life(age):
if age >= 66:
return 4 #老年
else:
if age >= 41:
return 3 #中年
else:
if age >= 18:
return 2 #青年
else:
if age >= 7:
return 1 #少年
else:
return 0 #孩童下面利用上面的定义,探究各年龄段的死亡和幸存人数占比,Python代码如下:
'''各年龄段的死亡和幸存人数'''
trainData = np.array(trainData)
aliveCount = [0,0,0,0,0]
deadCount = [0,0,0,0,0]
pos = [1,2,3,4,5]
for data in trainData:
if data[1] == 1:
aliveCount[life(data[5])] += 1
else:
deadCount[life(data[5])] += 1
pos = [1,2,3,4,5]
ax = plt.figure(figsize=(8,6)).add_subplot(111)
ax.bar(pos, deadCount, color='r', alpha=0.6, label='死亡')
ax.bar(pos, aliveCount, color='g', bottom=deadCount, alpha=0.6, label='幸存')
ax.legend(fontsize=16, loc='best')
ax.set_xticks(pos)
ax.set_xticklabels(['孩童','少年','青年','中年','老年'], size=15)
ax.set_title('各年龄段的死亡和幸存人数', size=20)
plt.show()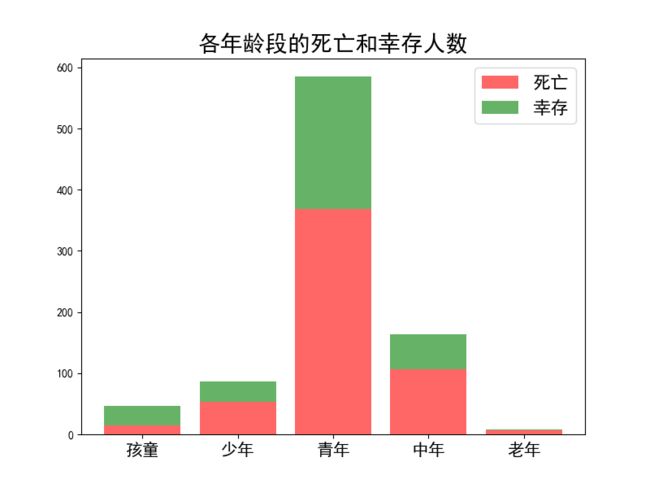
从上图可以看出除孩童的幸存人数高于死亡人数之外,其他年龄段的死亡人数较多,这可能充分表明了孩童优先施救的原则吧。
2.3 sex与Survived的关系
根据常识,女性较男性具有优先救援性,故可以推断女性的幸存率应该大于男性,通过绘图进行对比。Python代码如下。
'''sex与Survived的关系'''
trainData = np.array(trainData)
aliveCount = [0,0]
deadCount = [0,0]
pos = [1,2]
for data in trainData:
if data[4] == 'male':
if data[1] == 1:
aliveCount[1] += 1
else:
deadCount[1] += 1
else:
if data[1] == 1:
aliveCount[0] += 1
else:
deadCount[0] += 1
ax = plt.figure(figsize=(8,6)).add_subplot(111)
ax.bar(pos, deadCount, color='r', alpha=0.6, label='死亡')
ax.bar(pos, aliveCount, color='g', bottom=deadCount, alpha=0.6, label='幸存')
ax.legend(fontsize=16, loc='best')
ax.set_xticks(pos)
ax.set_xticklabels(['女性','男性'], size=15)
ax.set_title('性别和是否幸存的关系', size=20)
plt.show()
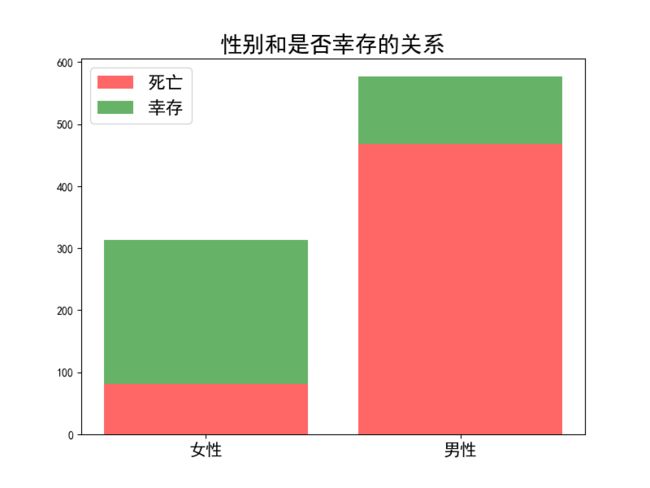
其中女性的幸存率为0.74,远大于男性的0.19。
2.4 Embacked和Survived的关系
乘客登船的港口和能否幸存有无关系,我们不好推测,直接绘图显示。Python代码如下。
'''Embacked和Survived的关系'''
trainData = np.array(trainData)
aliveCount = [0,0,0] # S,Q,C
deadCount = [0,0,0]
pos = [1,2,3]
for data in trainData:
if data[11] == 'S':
if data[1] == 1:
aliveCount[0] += 1
else:
deadCount[0] += 1
else:
if data[11] == 'Q':
if data[1] == 1:
aliveCount[1] += 1
else:
deadCount[1] += 1
else:
if data[1] == 1:
aliveCount[2] += 1
else:
deadCount[2] += 1
ax = plt.figure(figsize=(8,6)).add_subplot(111)
ax.bar(pos, deadCount, color='r', alpha=0.6, label='死亡')
ax.bar(pos, aliveCount, color='g', bottom=deadCount, alpha=0.6, label='幸存')
ax.legend(fontsize=16, loc='best')
ax.set_xticks(pos)
ax.set_xticklabels(['S','Q','C'], size=15)
ax.set_title('登船港口和能否幸存的关系', size=20)
plt.show()
其中S港口的幸存率为0.33,Q港口的幸存率为0.39,C港口的幸存率为0.56,可以看出在C港口登船的乘客幸存几率较大。
2.5 Sibsp、Parch与Survived的关系
先给出两张图。
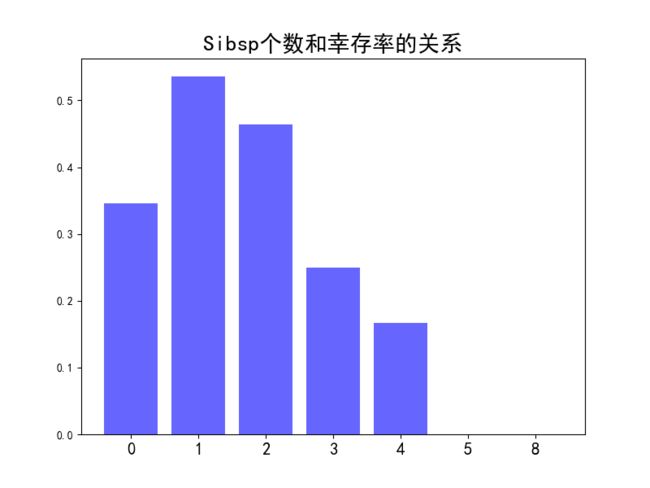
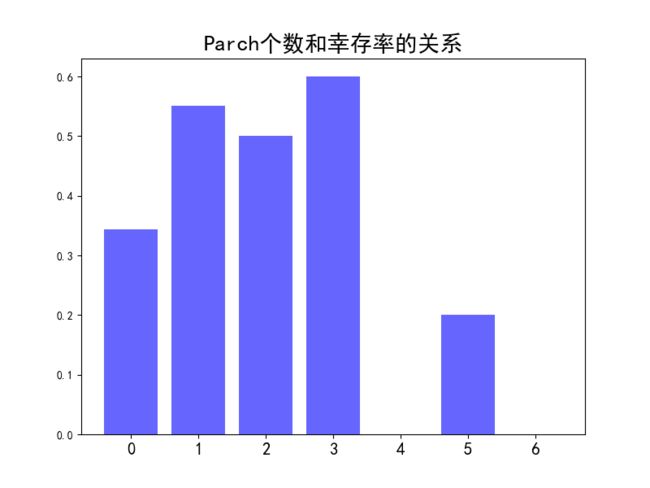
通过上面的两张图,可以看出幸存率和Sibsp、Parch的个数不是简单的线性关系,因为幸存率随着Sibsp、Parch个数的增加时高时低。
第三步 基于决策树的分类模型
通过上面的分析,我们先采用决策树来构建分类模型用于预测。此次的特征选择依次为经济等级、性别、年龄段、登船港口,目标为能否幸存。
对原始数据进行处理,得到适用于决策树的训练数据集。Python代码如下。
'''得到适用于决策树的训练集'''
trainData = np.array(trainData)
data = []
labels = ['Pclass','Sex','Age','Embacked']
for d in trainData:
temp = []
temp.append(str(d[2]))
temp.append(str(d[4]))
temp.append(str(life(d[5])))
temp.append(str(d[11]))
if d[1] == 1:
temp.append('yes')
else:
temp.append('no')
data.append(temp)
构建的决策树如下图所示.

从树中可以看出,性别是第一因素,接着是经济等级,然后是年龄段,最后是登船港口。利用构建好的决策树可以预测一个乘客是否幸存。Python代码如下。
'''决策树分类器
参数:inputTree:构建的决策树,
featureLabels,testVec:测试数据的特征标签和特征值
'''
def classify(inputTree,featureLabels,testVec):
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
featureIndex = featureLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featureIndex] == key:
if isinstance(secondDict[key],dict):
classLabel = classify(secondDict[key],featureLabels,testVec)
else:
classLabel = secondDict[key]
return classLabel对测试文件中所有乘客进行预测的Python代码如下。
'''预测'''
testData = np.array(testData)
featureLabels = labels[:]
for test in testData:
temp = []
temp.append(str(test[1]))
temp.append(str(test[3]))
temp.append(str(life(test[4])))
temp.append(str(test[10]))
print(classify(myTree,featureLabels,temp))利用以上代码,可以预测所有乘客是否幸存。将结果提交到Kaggle中,公共测试得分为0.66985,意味着将近70%的乘客预测正确。虽然得分不高,但整个过程收益颇多,只希望继续努力。

获取更多干货请关注微信公众号:追梦程序员。
