论文精读之PDE-Net: Learning PDEs from Data
论文精读之PDE-Net: Learning PDEs from Data
- 1.Introduction
- 1.1. Related Work
- 1.2. Our Approach
- 2. PDE-Net: A Flexible Deep Archtecture to Learn PDEs from Data
- 2.1. Convolutions and Differentiations
- 2.2. Architecture of PDE-Net
- 2.3. Initialization and training
- 2.4. Relations to some existing networks
- 3. Numerical Studies: Convection-Diffusion Equations
- 3.1. Simulated data, training and testing
- 3.2. Results and Discussions
- 3.2.1. PREDICTING LONG-TIME DYNAMICS
- 3.2.2. DISCOVERING THE HIDDEN EQUATION
- 3.2.3. FURTHER EXPERIMEN
- 4. Numerical Studies: Diffusion Equations with Nonlinear Source
- 4.1. Simulated data, training and testing
- 4.2. Results and Discussions
- 4.2.1. PREDICTING LONG-TIME DYNAMICS
- 4.2.2. DISCOVERING THE HIDDEN EQUATION
- 5.Conclusion and Discussion
整理人:陈振庭
qq:2621336811
第一次写博客,以后通过博客来记录自己的研究生学习过程。最近研究深度学习在PDE方面的应用,也要开始精读一些英文文章啦~
顺便附上文章的代码:文章中两个案例的代码
摘要
Partial differential equations (PDEs) play a prominent role in many disciplines of science and engineering. PDEs are commonly derived based on empirical observations. However, with the rapid development of sensors, computational power, and data storage in the past decade, huge quantities of data can be easily collected and efficiently stored. Such vast quantity of data offers new opportunities for data-driven discovery of physical laws. Inspired by the latest development of neural network designs in deep learning, we propose a new feed-forward deep network, called PDE-Net, to fulfill two objectives at the same time: to accurately predict dynamics of complex systems and to uncover the underlying hidden PDE models. Comparing with existing approaches, our approach has the most flexibility by learning both differential operators and the nonlinear response function of the underlying PDE model. A special feature of the proposed PDE-Net is that all filters are properly constrained, which enables us to easily identify the governing PDE models while still maintaining the expressive and predictive power of the network. These constrains are carefully designed by fully exploiting the relation between the orders of differential operators and the orders of sum rules of filters (an important concept originated from wavelet theory). Numerical experiments show that the PDE-Net has the potential to uncover the hidden PDE of the observed dynamics, and predict the dynamical behavior for a relatively long time, even in a noisy environment.
1.Introduction
1.1. Related Work
1.2. Our Approach
这篇文章,我们设计了一个深度前馈网络-----PDE-Net ,基于如下的非线性PDE:
u t = F ( x , u , ∇ u , ∇ 2 u , … ) , x ∈ Ω ⊂ R 2 t ∈ [ 0 , T ] u _ { t } = F \left( x , u , \nabla u , \nabla ^ { 2 } u , \ldots \right) , \quad x \in \Omega \subset R ^ { 2 } \quad t \in [ 0 , T ] ut=F(x,u,∇u,∇2u,…),x∈Ω⊂R2t∈[0,T]PDE-Net的目标是学习非线性函数F和做精确的预测。
2. PDE-Net: A Flexible Deep Archtecture to Learn PDEs from Data
给定一组测量值和一些物理量: { u ( t , ⋅ ) : t = t 0 , t 1 , … } \left\{ u ( t , \cdot ) : t = t _ { 0 } , t _ { 1 } , \ldots \right\} {u(t,⋅):t=t0,t1,…},在空间 Ω ⊂ R 2 \Omega \subset R ^ { 2 } Ω⊂R2,且 u ( t , ⋅ ) : Ω ↦ R u ( t , \cdot ) : \Omega \mapsto R u(t,⋅):Ω↦R , 我们假设观察数据与如下的PDE有关:
u t ( t , x , y ) = F ( x , y , u x , u y , u x x , u x y , u y y , … ) , ( 1 ) ∣ u _ { t } ( t , x , y ) = F \left( x , y , u _ { x } , u _ { y } , u _ { x x } , u _ { x y } , u _ { y y } , \ldots \right) , ( 1 ) | ut(t,x,y)=F(x,y,ux,uy,uxx,uxy,uyy,…),(1)∣其中 ( x , y ) ∈ Ω R 2 , t ∈ [ 0 , T ] ( x , y ) \in \Omega R ^ { 2 } , t \in [ 0 , T ] (x,y)∈ΩR2,t∈[0,T].
我们的目标是设计一个前馈网络PDE-Net,能够逼近PDE(1),且
1)我们能够尽可能长时间的预测方程的动态行为;
2)我们能够揭示相应函数F的形式和所涉及的微分算子。
PDE-Net主要由两部分组成:
1)自动确定PDE中所涉及的微分算子;
2)非线性响应函数F的逼近。
2.1. Convolutions and Differentiations
定义2.1 (Order of Sum Rules)
对于一个滤波器 q q q,当
∑ k ∈ Z 2 k β q [ k ] = 0 ( 2 ) \sum _ { k \in Z ^ { 2 } } k ^ { \beta } q [ k ] = 0 \quad ( 2 ) k∈Z2∑kβq[k]=0(2)我们说 q q q有求和规则的阶 α = ( α 1 , α 2 ) \alpha = \left( \alpha _ { 1 } , \alpha _ { 2 } \right) α=(α1,α2)且 α ∈ Z + 2 \alpha \in Z _ { + } ^ { 2 } α∈Z+2对于所有 β = ( β 1 , β 2 ) ∈ Z + 2 \beta = \left( \beta _ { 1 } , \beta _ { 2 } \right) \in Z _ { + } ^ { 2 } β=(β1,β2)∈Z+2且 ∣ β ∣ : = β 1 + β 2 < ∣ α ∣ | \beta | : = \beta _ { 1 } + \beta _ { 2 } < | \alpha | ∣β∣:=β1+β2<∣α∣和所有 β ∈ Z + 2 \beta \in Z _ { + } ^ { 2 } β∈Z+2且 ∣ β ∣ = ∣ α ∣ | \beta | = | \alpha | ∣β∣=∣α∣但是 β ≠ α \beta \neq \alpha β̸=α。如果对于(2)有 β ∈ Z + 2 \beta \in Z _ { + } ^ { 2 } β∈Z+2且 ∣ β ∣ < K | \beta | < \mathrm { K } ∣β∣<K但 β ≠ β ‾ \beta \neq \overline { \beta } β̸=β,且对某个 β ‾ ∈ Z + 2 \overline { \beta } \in Z _ { + } ^ { 2 } β∈Z+2且 ∣ β ‾ ∣ = J < K | \overline { \beta } | = \mathrm { J } < \mathrm { K } ∣β∣=J<K。那么我们说q有总的求和规则的阶 K \ { J + 1 } K \backslash \{ J + 1 \} K\{J+1}.
在实际应用中,滤波器通常是有限的且可以看做是一个矩阵。对于一个 N ∗ N N*N N∗N滤波器 q , N q,N q,N是奇数,假设 q q q的索引从 − N − 1 2 - \frac { N - 1 } { 2 } −2N−1开始,那么(2)可以写成如下形式 ∑ l = − N − 1 2 N − 1 2 ∑ m = − N − 1 2 N − 1 2 l β 1 m β 2 q [ l , m ] = 0 \sum _ { l = - \frac { N - 1 } { 2 } } ^ { \frac { N - 1 } { 2 } } \sum _ { m = - \frac { N - 1 } { 2 } } ^ { \frac { N - 1 } { 2 } } l ^ { \beta _ { 1 } } m ^ { \beta _ { 2 } } q [ l , m ] = 0 l=−2N−1∑2N−1m=−2N−1∑2N−1lβ1mβ2q[l,m]=0
命题2.1 令 q q q是一个有求和规则的阶为 α ∈ Z + 2 \alpha \in Z _ { + } ^ { 2 } α∈Z+2的滤波器,那么对于一个光滑函数 F ( x ) on R 2 F ( x ) \text { on } R ^ { 2 } F(x) on R2,我们有: 1 ε ∣ α ∣ ∑ k ∈ Z 2 q [ k ] F ( x + ε k ) = C α ∂ α ∂ x α F ( x ) + O ( ε ) , a s ε → 0 ( 3 ) \frac { 1 } { \varepsilon ^ { | \alpha | } } \sum _ { k \in \mathbb { Z } ^ { 2 } } q [ k ] F ( x + \varepsilon k ) = C _ { \alpha } \frac { \partial ^ { \alpha } } { \partial x ^ { \alpha } } F ( x ) + O ( \varepsilon ) , a s \varepsilon \rightarrow 0(3) ε∣α∣1k∈Z2∑q[k]F(x+εk)=Cα∂xα∂αF(x)+O(ε),asε→0(3)如果,另外, q q q有总的求和规则的阶为 K \ { ∣ α ∣ + 1 } K \backslash \{ | \alpha | + 1 \} K\{∣α∣+1}且对于有些 K > ∣ α ‾ ∣ K > |\overline { \alpha } | K>∣α∣,那么有 1 ε ∣ α ∣ ∑ k ∈ Z 2 q [ k ] F ( x + ε k ) = C α ∂ α ∂ x α F ( x ) + O ( ε K − ∣ α ∣ ) , a s ε → 0 ( 4 ) \frac { 1 } { \varepsilon ^ { | \alpha | } } \sum _ { k \in Z ^ { 2 } } q [ k ] F ( x + \varepsilon k ) = C _ { \alpha } \frac { \partial ^ { \alpha } } { \partial x ^ { \alpha } } F ( x ) + O \left( \varepsilon ^ { K - | \alpha | } \right) , a s \varepsilon \rightarrow 0(4) ε∣α∣1k∈Z2∑q[k]F(x+εk)=Cα∂xα∂αF(x)+O(εK−∣α∣),asε→0(4)
根据命题2.1,一个 α \alpha α阶的微分算子可以用一个有 α \alpha α阶求和规则的滤波器 q q q来近似。甚至,根据(4),我们可以得到,一个对于给定的高阶微分算子的对应的滤波器的高阶近似。滤波器的总的求和规则的阶为 K > ∣ α ∣ + k , k ≥ 1 K >| \alpha | + k , k \geq 1 K>∣α∣+k,k≥1比如,考虑这样一个滤波器 q = ( 1 0 − 1 2 0 − 2 1 0 − 1 ) q = \left( \begin{array} { c c c } { 1 } & { 0 } & { - 1 } \\ { 2 } & { 0 } & { - 2 } \\ { 1 } & { 0 } & { - 1 } \end{array} \right) q=⎝⎛121000−1−2−1⎠⎞他的一个求和规则的阶为(1,0),总的求和规则的阶为3{2},那么Q对应于 ∂ ∂ x \frac { \partial } { \partial x } ∂x∂的一个二阶离散近似。
现在我们介绍一下矩矩阵的概念。在一个PDE-Net中,对于一个给定的带有约束条件的 N ∗ N N*N N∗N滤波器 q , Q q,Q q,Q的矩矩阵定义为: M ( q ) = ( m i , j ) N × N M ( q ) = \left( m _ { i , j } \right) _ { N \times N } M(q)=(mi,j)N×N其中 m i , j = 1 ( i − 1 ) ! ( j − 1 ) ! ∑ k ∈ Z 2 k 1 i − 1 k 2 j − 1 q [ k 1 , k 2 ] m _ { i , j } = \frac { 1 } { ( i - 1 ) ! ( j - 1 ) ! } \sum _ { k \in \mathbb { Z } ^ { 2 } } k _ { 1 } ^ { i - 1 } k _ { 2 } ^ { j - 1 } q \left[ k _ { 1 } , k _ { 2 } \right] mi,j=(i−1)!(j−1)!1∑k∈Z2k1i−1k2j−1q[k1,k2], i , j = 1 , 2 , … , N i , j = 1,2 , \ldots , N i,j=1,2,…,N.
结合(5)和命题2.1,我们可以轻松得出,滤波器q能够设计成任意给定任意阶微分算子的近似,通过使用带约束条件的 M ( q ) M(q) M(q)。比如,如果我们想要近似 ∂ u ∂ x \frac { \partial u } { \partial x } ∂x∂u,可以用卷积 q ⊗ u q \otimes u q⊗u,其中 q q q是3*3的滤波器,我们可以考虑用如下的带约束的 M ( q ) M(q) M(q) ( 0 0 ⋆ 1 ⋆ ⋆ ⋆ ⋆ ⋆ ) or ( 0 0 0 1 0 ⋆ 0 ⋆ ⋆ ) ( 6 ) \left( \begin{array} { c c c } { 0 } & { 0 } & { \star } \\ { 1 } & { \star } & { \star } \\ { \star } & { \star } & { \star } \end{array} \right) \quad \text { or } \quad \left( \begin{array} { c c c } { 0 } & { 0 } & { 0 } \\ { 1 } & { 0 } & { \star } \\ { 0 } & { \star } & { \star } \end{array} \right)(6) ⎝⎛01⋆0⋆⋆⋆⋆⋆⎠⎞ or ⎝⎛01000⋆0⋆⋆⎠⎞(6)其中,左边的矩矩阵保证了近似的准确度至少是一阶的,另一个至少是二阶的.特别的,对于一个所有元素都是带约束的 M ( q ) M(q) M(q),比如 M ( q ) = ( 0 0 0 1 0 0 0 0 0 ) M(q) = \left( \begin{array} { c c c } {0 } & { 0 } & { 0} \\ { 1 } & { 0 } & { 0} \\ { 0 } & { 0 } & { 0 } \end{array} \right) M(q)=⎝⎛010000000⎠⎞其对应的滤波器是被唯一确定的,我们称为冻结滤波器。所有过滤器学习在相关力矩上受到部分约束矩阵。值得注意的是,用于近似的过滤器的近似性质是被他的大小所限制的。大的滤波器可以近似高阶微分算子或具有更高近似阶的低阶微分算子。但是,较大的过滤器会导致更多的内存管理费用和更高的计算成本。这是一种智慧在实践中平衡权衡。
2.2. Architecture of PDE-Net
对于给定的PDE(1),我们使用向前欧拉做时间的离散。
ONE δ t − b l o c k \delta t - b l o c k δt−block:
令 u ~ ( t i + 1 , ⋅ ) \widetilde { u } \left( t _ { i } + 1 , \cdot \right) u (ti+1,⋅)是 u u u在时间 t i + 1 t _ { i + 1 } ti+1上基于 u u u在 t i t _ { i } ti上的预测值,那么我们有: u ~ ( t i + 1 , ⋅ ) = D 0 u ( t i , ⋅ ) + Δ t ⋅ F ( x , y , D 00 u , D 10 u , D 01 u , D 20 u , … ) . ( 7 ) \tilde { u } \left( t _ { i + 1 } , \cdot \right) = D _ { 0 } u \left( t _ { i } , \cdot \right) +\Delta t \cdot F \left( x , y , D _ { 00 } u , D _ { 10 } u , D _ { 01 } u , D _ { 20 } u , \dots \right).(7) u~(ti+1,⋅)=D0u(ti,⋅)+Δt⋅F(x,y,D00u,D10u,D01u,D20u,…).(7)其中, D 0 , D i j D _ { 0 } , D _ { i j } D0,Dij是卷积算子,可以看做 D 0 u = q 0 ⊗ u and D i j u = q i j ⊗ u D _ { 0 } u = q _ { 0 } \otimes u \text { and } D _ { i j } u = q _ { i j } \otimes u D0u=q0⊗u and Diju=qij⊗u, 微分算子的近似 D i j u ≈ ∂ i + j u ∂ i x ∂ j y D _ { i j } u \approx \frac { \partial ^ { i + j } u } { \partial ^ { i } x \partial ^ { j } y } Diju≈∂ix∂jy∂i+ju.
我们假设PDE的最高阶数小于一些正整数。那么,近似f的任务相当于多元回归问题,就可以用点神经网络来近似了。我们实现了一个(7)的近似框架: δ t − b l o c k \delta t - b l o c k δt−block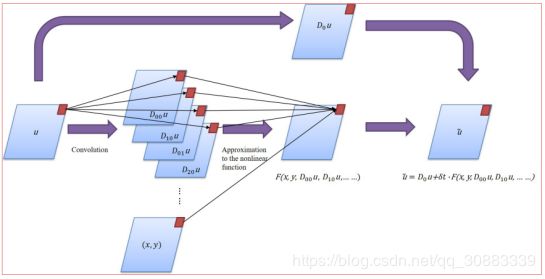
Figure 1. The schematic diagram of a δ t − b l o c k \delta t - b l o c k δt−block
PDE-NET (MULTIPLE δ t − b l o c k s \delta t - b l o c ks δt−blocks):
一个 δ t − b l o c k \delta t - b l o c k δt−block只能保证一步动态变化的准确度,为了能够实现长期的预测,我们搭建了多层 δ t − b l o c k s \delta t - b l o c ks δt−blocks,使之成为一个深层网络,我们叫做PDE-Net。
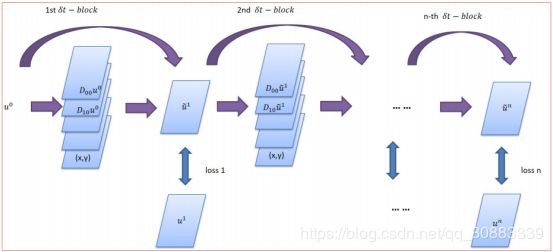
Figure 2. The schematic diagram of the PDE-Net.
PDE-Net可以简单描述为:
1)多个 δ t − b l o c k s \delta t - b l o c ks δt−blocks堆积而成;
2)所有的 δ t − b l o c k s \delta t - b l o c ks δt−blocks共享参数。
对于给定的输入数据 u ( t i , ⋅ ) u \left( t _ { i } , \cdot \right) u(ti,⋅),训练一个有多层 δ t − b l o c k s \delta t - b l o c ks δt−blocks的PDE-Net需要最小化累计误差 ∥ u ( t i + n , ⋅ ) − u ~ ( t i + n , ⋅ ) ∥ 2 2 \left\| u \left( t _ { i + n } , \cdot \right) - \widetilde { u } \left( t _ { i + n } , \cdot \right) \right\| _ { 2 } ^ { 2 } ∥u(ti+n,⋅)−u (ti+n,⋅)∥22,这里 u ~ ( t i + n , ) \widetilde { \mathcal { u } } \left( t _ { i + n } , \right) u (ti+n,)是基于输入 u ( t i , ⋅ ) u \left( t _ { i } , \cdot \right) u(ti,⋅)的PDE-Net的输出。
LOSS FUNCTION AND CONSTRAINTS:
考虑数据集 { u j ( t , ⋅ ) : i , j = 0 , 1 , … } \left\{ u _ { j } ( t , \cdot ) : i , j = 0,1 , \ldots \right\} {uj(t,⋅):i,j=0,1,…},这里 j j j代表对于某个未知动态初始化条件的第 j j j个的结果。我们想要用 n δ t − b l o c k s n\delta t - b l o c ks nδt−blocks来训练PDE-Net。对于一个给定的 n ≥ 1 n \geq 1 n≥1,每一个数据对 { u i ( t , ⋅ ) , u i ( t i + n , ⋅ ) } \left\{ u _ { i } ( t , \cdot ) , u _ { i } \left( t _ { i + n } , \cdot \right) \right\} {ui(t,⋅),ui(ti+n,⋅)},是一个训练样本。这里 u i ( t i , ⋅ ) u _ { i } \left( t _ { i , } \cdot \right) ui(ti,⋅)是输入, u i + n ( t i , ⋅ ) u _ { i+n } \left( t _ { i , } \cdot \right) ui+n(ti,⋅)是输出/标签。
我们选择 L 2 L _ { 2 } L2损失函数来训练: L = ∑ i , j l i j , where l i j = ∥ u j ( t i + n , ⋅ ) − u ~ j ( t i + n , ⋅ ) ∥ 2 2 L = \sum _ { i , j } l _ { i j } , \text { where } l _ { i j } = \left\| u _ { j } \left( t _ { i + n } , \cdot \right) - \tilde { u } _ { j } \left( t _ { i + n } , \cdot \right) \right\| _ { 2 } ^ { 2 } L=i,j∑lij, where lij=∥uj(ti+n,⋅)−u~j(ti+n,⋅)∥22这里 u ~ i ( t i + n , ⋅ ) \widetilde { u } _ { i } \left( t _ { i + n } , \cdot \right) u i(ti+n,⋅)是PDE-Net对于输入 u i ( t i , ⋅ ) { u } _ { i } \left( t _ { i } , \cdot \right) ui(ti,⋅)所对应的输出。所有的PDE-Net中所涉及的滤波器都是有适当的约束通过使用与他们相关的矩矩阵。令 q 0 q _ { 0 } q0和 q i j q _ { ij } qij为 D 0 D _ { 0 } D0和 D i j D_ { ij } Dij所对应的滤波器,我们使用一下的约束条件: ( M ( q 0 ) ) 1.1 = 1 , ( M ( q 00 ) ) 1.1 = 1 ∣ \left( M \left( q _ { 0 } \right) \right) _ { 1.1 } = 1 , \left( M \left( q _ { 00 } \right) \right) _ { 1.1 } = 1 | (M(q0))1.1=1,(M(q00))1.1=1∣这里 i + j > 0 \ i + j > 0 i+j>0。我们令 ( M ( q i , j ) ) k 1 , k 2 = 0 , k 1 + k 2 ≤ i + j + 2 , ( k 1 , k 2 ) ≠ ( i + 1 , j + 1 ) \left( M \left( q _ { i , j } \right) \right) _ { k _ { 1 } , k _ { 2 } } = 0 , k _ { 1 } + k _ { 2 } \leq i + j + 2 , \left( k _ { 1 } , k _ { 2 } \right) \neq ( i + 1 , j + 1 ) (M(qi,j))k1,k2=0,k1+k2≤i+j+2,(k1,k2)̸=(i+1,j+1); ( M ( q i , j ) ) i + 1 , j + 1 = 1 ∣ \left( M \left( q _ { i , j } \right) \right) _ { i + 1 , j + 1 } = 1 | (M(qi,j))i+1,j+1=1∣
为了展示可学习的滤波器的必要性,我们将会比较带约束的滤波器和冻结滤波器,我们把带有冻结滤波器的PDE-Net叫做“the Frozen-PDE-Net”。
NOVELTY OF THE PDE-NET:
使用可学习的过滤器使PDE网络更加灵活,能够对未知动态进行更稳健的近似,并能进行更长的时间预测。响应函数f的具体形式也是从数据中近似得出的,而不是假设的提前知道。通过对矩矩阵施加约束,我们可以确定微分运算符包含在基础PDE中,这有助于识别非线性响应函数f。这使得PDE网络和可能揭示隐藏的物理定律。
2.3. Initialization and training
在PDE-Net中,参数可以被分为三组:
1)用来近似微分算子的滤波器
2)用来近似F的神经网络的参数
3)超参数,如滤波器的个数、滤波器的大小、层数
其中,神经网络的参数在整个计算过程是共享的,由服从正态分布的数据做随机初始化。我们不直接训练n层PDE网络,而是采用分层训练,提高训练速度。所有参数在每个 δ t − b l o c k \delta t - b l o c k δt−block中是共享的。另外,我们第一个 δ t − b l o c k \delta t - b l o c k δt−block训练之前增加了一个热身的步骤。这个步骤是让近似F的神经网络获得一个好的参数初始化通过使用冻结滤波器。
2.4. Relations to some existing networks
- Network-In-Network(NIN)
- Deep Residual Neural Network(ResNet)
3. Numerical Studies: Convection-Diffusion Equations
3.1. Simulated data, training and testing
我们考虑一个2维的线性变参数对流扩散方程在 Ω = [ 0 , 2 π ] × [ 0 , 2 π ] \Omega = [ 0,2 \pi ] \times [ 0,2 \pi ] Ω=[0,2π]×[0,2π]上 { ∂ u ∂ t = a ( x , y ) u x + b ( x , y ) u y + 0.2 u x x + 0.3 u y y u ∣ t = 0 = u 0 ( x , y ) ( 8 ) \left\{ \begin{array} { l l } { \frac { \partial u } { \partial t } } & { = a ( x , y ) u _ { x } + b ( x , y ) u _ { y } + 0.2 u _ { x x } + 0.3 u _ { y y } } \\ { \left. u \right| _ { t = 0 } } & { = u _ { 0 } ( x , y ) } \end{array} \right.(8) {∂t∂uu∣t=0=a(x,y)ux+b(x,y)uy+0.2uxx+0.3uyy=u0(x,y)(8)其中 ( t , x , y ) ∈ [ 0 , 0.3 ] × Ω ( t , x , y ) \in [ 0,0.3 ] \times \Omega (t,x,y)∈[0,0.3]×Ω,且 a ( x , y ) = 0.5 ( cos ( y ) + x ( 2 π − x ) sin ( x ) ) + 0.6 b ( x , y ) = 2 ( cos ( y ) + sin ( x ) ) + 0.8 \begin{array} { l } { a ( x , y ) = 0.5 ( \cos ( y ) + x ( 2 \pi - x ) \sin ( x ) ) + 0.6 } \\ { b ( x , y ) = 2 ( \cos ( y ) + \sin ( x ) ) + 0.8 } \end{array} a(x,y)=0.5(cos(y)+x(2π−x)sin(x))+0.6b(x,y)=2(cos(y)+sin(x))+0.8
数据通过高精度数值方法,通过将 Ω \Omega Ω使用 50 ∗ 50 50*50 50∗50的网格离散,时间步长为 δ t = 0.015 \delta t = 0.015 δt=0.015求解(8)获得。我们假设边界条件和初值 u 0 ( x , y ) u _ { 0 } ( x , y ) u0(x,y)来自 u 0 ( x , y ) = ∑ ∣ k ∣ , ∣ l ∣ ≤ N λ k , l cos ( k x + l y ) + γ k , l sin ( k x + l y ) , ( 9 ) u _ { 0 } ( x , y ) = \sum _ { | k | , | l | \leq N } \lambda _ { k , l } \cos ( k x + l y ) + \gamma _ { k , l } \sin ( k x + l y ) ,(9) u0(x,y)=∣k∣,∣l∣≤N∑λk,lcos(kx+ly)+γk,lsin(kx+ly),(9)其中 N = 9 N=9 N=9, λ k , l , γ k , l ∼ N ( 0 , 1 50 ) \lambda _ { k , l } , \gamma _ { k , l } \sim \mathrm { N } \left( 0 , \frac { 1 } { 50 } \right) λk,l,γk,l∼N(0,501), k k k和 L L L随机产生。同时我们也加入一些噪声数据: u ^ ( x , y , t ) = u ( x , y , t ) + 0.015 × M W ( 10 ) \widehat { u } ( x , y , t ) = u ( x , y , t ) + 0.015 \times M W(10) u (x,y,t)=u(x,y,t)+0.015×MW(10)这里 M = max x , y , t { u ( x , y , t ) } , W ∼ N ( 0 , 1 ) M = \max _ { x , y , t } \{ u ( x , y , t ) \} , W \sim \mathcal { N } ( 0,1 ) M=maxx,y,t{u(x,y,t)},W∼N(0,1)。假设我们知道了PDE是线性的且阶数不超过4,那么响应函数可以采用以下形式:
F = ∑ 0 ≤ i + j ≤ 4 f i j ( x , y ) ∂ i + j u ∂ x i ∂ y j F = \sum _ { 0 \leq i + j \leq 4 } f _ { i j } ( x , y ) \frac { \partial ^ { i + j } u } { \partial x ^ { i } \partial y ^ { j } } F=0≤i+j≤4∑fij(x,y)∂xi∂yj∂i+ju每一个PDE-Net中的 δ t − b l o c k \delta t - b l o c k δt−block可以写作: u ~ ( t n + 1 , ⋅ ) = D 0 u ( t n , ⋅ ) + δ t ⋅ ( c 00 D 00 u + c 10 D 10 u + … + c 04 D 04 u ) \tilde { u } \left( t _ { n + 1 } , \cdot \right) = D _ { 0 } u \left( t _ { n } , \cdot \right)+ \delta t \cdot \left( c _ { 00 } D _ { 00 } u + c _ { 10 } D _ { 10 } u + \ldots + c _ { 04 } D _ { 04 } u \right) u~(tn+1,⋅)=D0u(tn,⋅)+δt⋅(c00D00u+c10D10u+…+c04D04u)这里 { D 0 , D i j : i + j ≤ 4 } \left\{ D _ { 0 } , D _ { i j } : i + j \leq 4 \right\} {D0,Dij:i+j≤4}是卷积算子且 { c i j : i + j ≤ 4 } \left\{ c _ { i j } : i + j \leq 4 \right\} {cij:i+j≤4}是一个用来近似函数 f i j ( x , y ) f _ { i j } ( x , y ) fij(x,y)的二维矩阵。通过使用分段二次多项式插值,在每一块的边界处平滑过渡达到近似值。滤波器和卷积算子 { D 0 , D i j : i + j ≤ 4 } \left\{ D _ { 0 } , D _ { i j } : i + j \leq 4 \right\} {D0,Dij:i+j≤4},同时分段二次型多项式系数是可训练的参数。
在训练和测试期间,数据是动态产生的,滤波器的大小使用 5 ∗ 5 5*5 5∗5或者 7 ∗ 7 7*7 7∗7。所有的可训练参数大约有17k。训练时,我们使用LBFGS而不是SGD去训练参数。我们使用28个样本/批次去训练每一层,我们只搭建PDE-Net到20层,一共需要560个样本/批次。
3.2. Results and Discussions
3.2.1. PREDICTING LONG-TIME DYNAMICS
我们首先展示训练好的PDE-Net在预测方面的能力。在有的pde-net训练完后,我们随机产生了560个基于(9)(10)的初始数据,将他们喂给PDE-NET,然后测量动态预测和实际动态变化之间的误差,将误差定义为: ϵ = ∥ u ~ − u ∥ 2 2 ∥ u − u ‾ ∥ 2 2 \epsilon = \frac { \| \tilde { u } - u \| _ { 2 } ^ { 2 } } { \| u - \overline { u } \| _ { 2 } ^ { 2 } } ϵ=∥u−u∥22∥u~−u∥22其中, u u u是实际数据, u ~ \widetilde { u } u 是预测数据, u ‾ \overline { u } u是 u u u的平均值。
误差图如图3所示: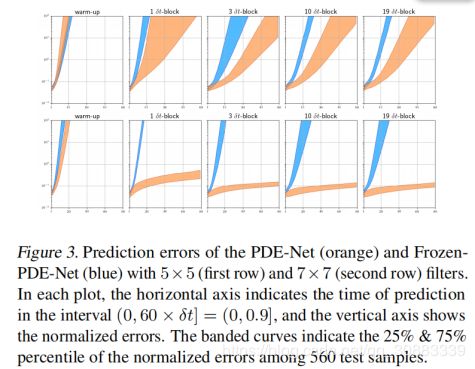
一些预测的动态变化的图片如图4所示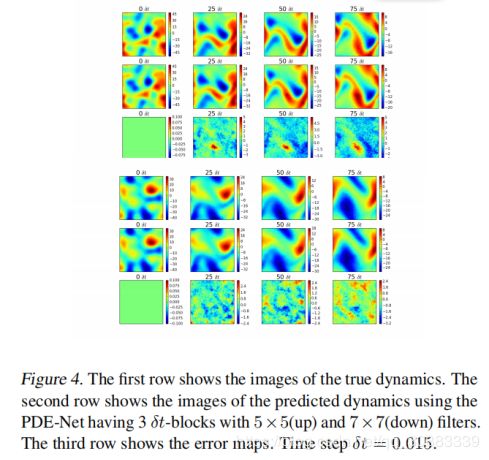
从这些结果中,我们可以看到:
1)即使在训练中加入了噪声数据,PDE-Net仍然可以实现长期的预测(见图4)
2)具有多个 δ t − b l o c k s \delta t - b l o c ks δt−blocks使得网络能够促进长期预测(见图3)
3)PDE网络的性能明显优于Frozen-PDE-Net,特别是对于7×7过滤器(见图3),7×7过滤器的PDE网络在性能上明显优于5×5过滤器的PDE网络就可靠预测的长度而言(见图3)。达到一个O(1)误差,7×7滤波器的预测长度约为5×5滤波器的预测长度的10倍。
3.2.2. DISCOVERING THE HIDDEN EQUATION
对于线性问题,求解PDE相当于寻找近似 { f i j : 1 ≤ i + j ≤ 4 } \left\{ f _ { i j } : 1 \leq i + j \leq 4 \right\} {fij:1≤i+j≤4}的系数 { c i j : 1 ≤ i + j ≤ 4 } \left\{ c _ { i j } : 1 \leq i + j \leq 4 \right\} {cij:1≤i+j≤4}.已经训练好的PDE-Net的系数 { c i j : 1 ≤ i + j ≤ 2 } \left\{ c _ { i j } : 1 \leq i + j \leq 2 \right\} {cij:1≤i+j≤2}如图5所示。注意 f 11 f i j : 1 ≤ i + j ≤ 2 f _ { 11 } f _ { i j } : 1 \leq i + j \leq 2 f11fij:1≤i+j≤2不在PDE(8)中,以及由PDE网络得出的相应系数确实接近于零。

比较图5的第一个前三列,通过PDE-Net学习的系数 { C i j } \left\{ C _ { i j } \right\} {Cij}与实际 { f i j } \left\{ f _ { i j } \right\} {fij}的系数非常接近。图5表明具有多个 δ t − b l o c k \delta t - b l o c k δt−block有助于系数的估计。然而使用较大的过滤器似乎不能提高系数的学习,尽管它对延长PDE网络的预测有很大帮助。
3.2.3. FURTHER EXPERIMEN
PDE(8)是二阶的,在我们前面的试验中,我们假设了PDE不超过4阶。如果我们知道PDE是二阶的,我们能够用更准确的方法估计对流和扩散项的变量系数。然而,预测的误差很高,因为我们只是用了较少的可训练参数。
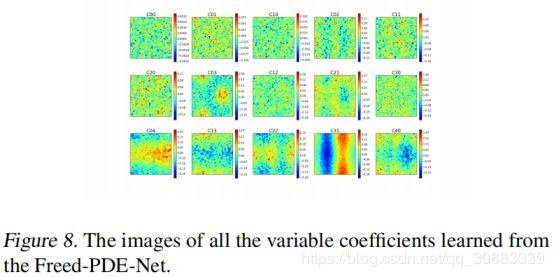
为了能够更好的展示PDE-Net中滤波器的矩矩阵的重要性,我们训练了一个没有任何约束矩矩阵的网络。我们称这样的网络为 Freed-PDE-Net。Freed-PDE-Net.的预测误差如图6中的红色部分所示。因为没有力矩限制,不知道滤波器与微分器的对应关系操作。因此,我们无法识别对应的学习的变量系数。我们在图8中画出了15个变量系数。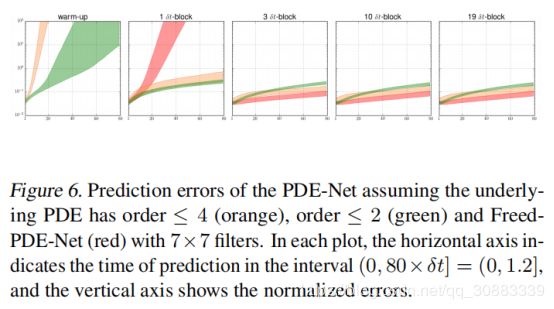
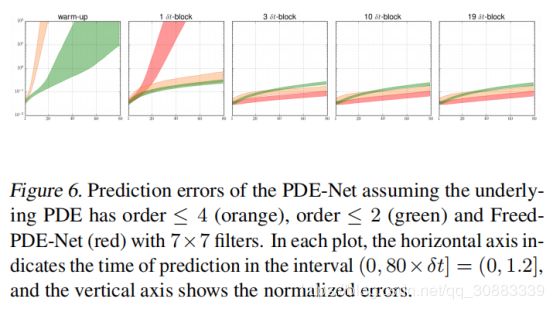
可以看出,Freed-PDE-Net的预测结果比PDE-Net要好,因为他有更多的可训练参数,然而,我们不能从Free-PDE-Net中识别出PDE。
4. Numerical Studies: Diffusion Equations with Nonlinear Source
4.1. Simulated data, training and testing
我们考虑这样一个2维带有非线性汇源项的线性对流方程: Ω = [ 0 , 2 π ] × [ 0 , 2 π ] \Omega = [ 0,2 \pi ] \times [ 0,2 \pi ] Ω=[0,2π]×[0,2π] { ∂ u ∂ t = c Δ u + f s ( u ) , u ∣ t = 0 = u 0 ( x , y ) , with ( t , x , y ) ∈ [ 0 , 0.2 ] × Ω ( 11 ) \left\{ \begin{array} { l l } { \frac { \partial u } { \partial t } } & { = c \Delta u + f _ { s } ( u ) , } \\ { \left. u \right| _ { t = 0 } } & { = u _ { 0 } ( x , y ) , } \end{array} \right. \quad \text { with } ( t , x , y ) \in [ 0,0.2 ] \times \Omega(11) {∂t∂uu∣t=0=cΔu+fs(u),=u0(x,y), with (t,x,y)∈[0,0.2]×Ω(11)其中, c = 0.3 c = 0.3 c=0.3, f s ( u ) = 15 sin ( u ) f _ { s } ( u ) = 15 \sin ( u ) fs(u)=15sin(u),数据的产生与上个例子类似,时间步长改为 δ t = 0.0009 \delta t = 0.0009 δt=0.0009,同时有0边界条件。
我们假设响应函数 F F F有如下形式: F = ∑ 1 ≤ i + j ≤ 2 f i j ( x , y ) ∂ i + j u ∂ x i ∂ y j + f s ( u ) F = \sum _ { 1 \leq i + j \leq 2 } f _ { i j } ( x , y ) \frac { \partial ^ { i + j } u } { \partial x ^ { i } \partial y ^ { j } } + f _ { s } ( u ) F=1≤i+j≤2∑fij(x,y)∂xi∂yj∂i+ju+fs(u)PDE-Net中的每一个 δ t − b l o c k \delta t - b l o c k δt−block可以写作: u ~ ( t n + 1 , ⋅ ) = D 0 u ( t n , ⋅ ) + δ t ⋅ ( ∑ 1 ≤ i + j ≤ 2 c i j D i j u + f ~ s ( u ) ) \tilde { u } \left( t _ { n + 1 } , \cdot \right) = D _ { 0 } u \left( t _ { n } , \cdot \right) + \delta t \cdot \left( \sum _ { 1 \leq i + j \leq 2 } c _ { i j } D _ { i j } u + \tilde { f } _ { s } ( u ) \right) u~(tn+1,⋅)=D0u(tn,⋅)+δt⋅(1≤i+j≤2∑cijDiju+f~s(u))其中 { D 0 , D i j : 1 ≤ i + j ≤ 2 } \left\{ D _ { 0 } , D _ { i j } : 1 \leq i + j \leq 2 \right\} {D0,Dij:1≤i+j≤2}是卷积算子, { c i j : 1 ≤ i + j ≤ 2 } \left\{ c _ { i j } : 1 \leq i + j \leq 2 \right\} {cij:1≤i+j≤2}是 f i j ( x , y ) f _ { i j } ( x , y ) fij(x,y)的近似,是一个二维矩阵。在我们的试验中,滤波器的大小为7*7,参数量大约为1.2k。
4.2. Results and Discussions
4.2.1. PREDICTING LONG-TIME DYNAMICS
我们首先展示训练好的PDE-Net的预测能力。
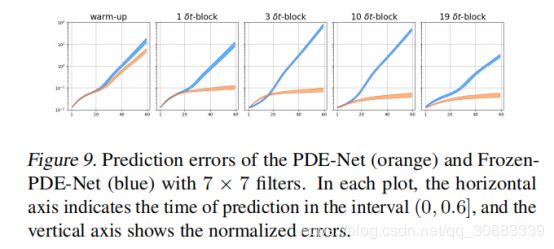
图9是PDE-Net和Frozen-PDE-Net的对比;
图10是动态预测的可视化结果;
所有的这些结果表示,PDE-Net在预测方面表现很好

4.2.2. DISCOVERING THE HIDDEN EQUATION
对于PDE(11),确定PDE相当于寻找近似 { f i j : 1 ≤ i + j ≤ 2 } } \left\{ f _ { i j} : 1 \leq i + j \leq 2 \right\} \} {fij:1≤i+j≤2}}的系数 { c i j : 1 ≤ i + j ≤ 2 } \left\{ c _ { i j } : 1 \leq i + j \leq 2 \right\} {cij:1≤i+j≤2}和 f s f _ { s } fs的近似 f ~ s \widetilde { f } _ { s } f s。
经过训练的PDE网的计算系数 { c i j : 1 ≤ i + j ≤ 2 } \left\{ c _ { i j } : 1 \leq i + j \leq 2 \right\} {cij:1≤i+j≤2}如图11所示,计算出的如图12(左)所示。注意到一阶项不在PDE(11)中以及PDE-Net学习到的相应系数实际上接近于零。 f s f _ { s } fs的近似值在区间中心附近比在边界附近更精确。这是因为数据集中的u值主要分布在中心附近(图12(右))。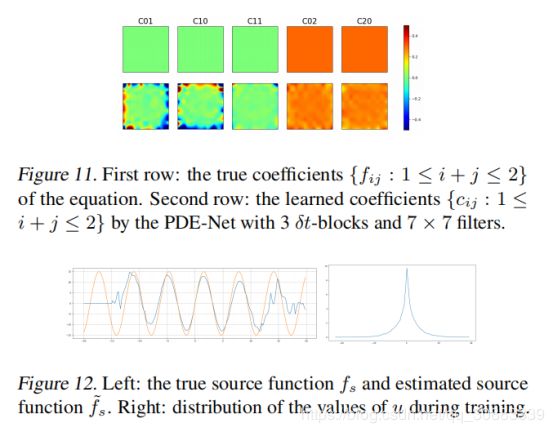
5.Conclusion and Discussion
在这篇文章中,我们设计了一个深层的前馈网络叫PDE-Net,为了从观测到的动态变化中发现隐藏的PDE模型并预测其动态行为。
PDE-Net参与训练的主要由两部分组成:
1)通过合适的带约束的滤波器做卷积来近似微分算子
2)通过深层神经网络来近似非线性响应函数
这个PDE-Net适用于学习PDE(1)类型。以线性变系数对流扩散方程为例。结果表明,PDE网络能够揭示观测动力学的隐式方程,并能在较长的时间内,甚至在噪声环境中预测动态行为。其中一个重要的方向是揭示传感器无法直接测量的隐藏变量,如数据同化。另一个值得探索的方向是学习基于PDE网络结构的给定PDE模型的稳定一致的数值格式。