WGAN(wasserstein GAN)
论文:https://arxiv.org/pdf/1701.07875.pdf
介绍:
在非监督学习中学习概率分布的意义在哪儿?论文使用极大似然估计的理论来解释,使用一个分布来近似真实分布,并通过最小化连个分布之间的KL散度来求解。论文解释了生成模型GAN与VAE的特点:不用直接求解原分布![]() ,而通过生成一个随机变量z的分布P(z),并通过参数化方程(比如神经网络等)生成一个确定分布
,而通过生成一个随机变量z的分布P(z),并通过参数化方程(比如神经网络等)生成一个确定分布![]() ,并将
,并将![]() 不断的接近
不断的接近![]() 从而求解非监督问题。
从而求解非监督问题。
论文的主要工作:① 在理论上解释了Earth Mover(EM)距离,并比较了常用的其他距离和散度公式 ② 定义了一个新的GAN生成模型WGAN,通过最小化近似笔记EM距离 ③ WGAN解决了GAN在训练中不稳定等问题,WGAN训练鉴别器D过程中可以连续的评估EM距离。
不同的距离公式;


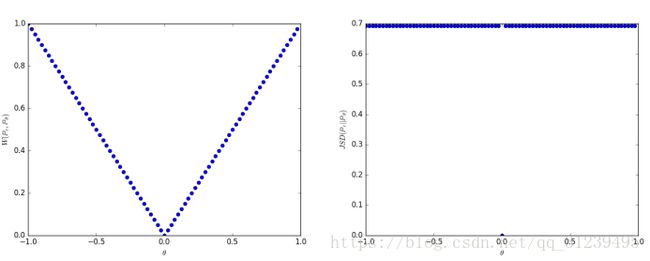
论文通过举例来证明EM在低维空间中仍然连续并可求导,如下图所示,EM连续并可梯度下降,JS不连续。
论文通过两个定理,和一个推论在证明EM在度量真实和重建分布的距离时,性能最优异,定理及推论如下(本文不作定理及推论的证明):

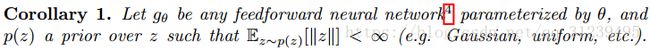
![]()

WGAN:
由W-Distance得:
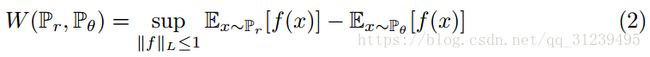
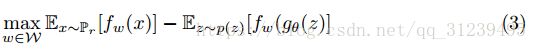
最大化公式(2)的期望,论文采用神经网络来训练权重w,使用反向传播算法更新。为了在一个小的空间中训练参数w,论文采在每次梯度更新时使用了一个clip。
该clip不能太大,太大会使得训练时间过长,也不能太小,太小会导致梯度弥散。
其中函数的Lipschitz常数为
![]()
论文提出,论文没有使用神经网络来代替这个clip项,这个方向也可能成为未来研究方向。

实验:
损失函数标准:论文提出了基于WGAN的损失函数标准

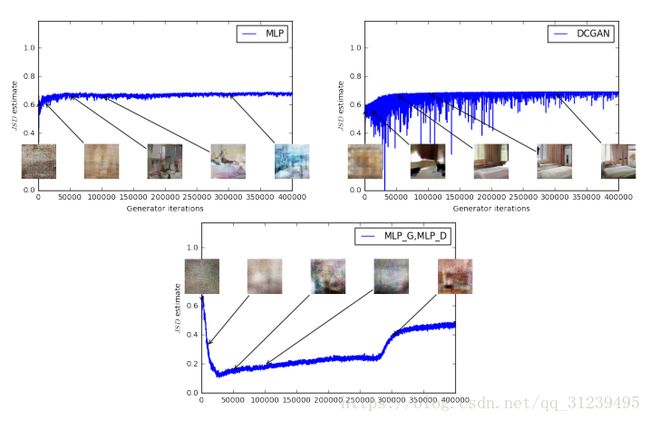
左图是使用W-Estimator,右图是使用JS-Estimator,左图显示,GAN的损失趋向于收敛(论文提出这是一个重要的进展)
同时,论文使用用了RMSProp而不是使用常用的Adam优化算法,这一点在伪代码里也有展示。
论文使用DCGAN的生成器,实验效果图如下:

思考:
① 连续评估EM距离的意义在哪儿?离散评估有什么不可以?
连续评估EM距离,在论文中经过证明,也就是上面的第一张图片,EM距离可以收敛到0,而想JS距离和KL散度等,都不能收敛到0。EM将会使得GAN在优化时,在如论文中 exmple1 中的均匀分布中,仍然可以收敛。
由于状态分布是连续的,所以不可以使用离散评估。
② WGAN与其他GAN相比优势在哪里?原来的GAN有什么问题?
首先回答原来的GAN有什么问题:① 判别器越好,生成器梯度消失越严重 ② 判别器越好的情况下,生成的模型多样性不够 ③ 训练困难,生成器和判别器的loss无法指示训练进程。
为什么会有这些问题?文章链接:https://zhuanlan.zhihu.com/p/25071913
WGAN的改进之处:①判别器最后一层去掉sigmoid ②生成器和判别器的loss不取log ③ 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c ④ 不要用基于动量的优化算法Adam,使用RMSProp
论文中WGAN相比于原始的GAN优势在于:① 将GAN的训练过程,也就是loss指示了训练进程 ② 解决了生成样本的多样性的问题 ③ 使用DCGAN的网络结构,不需要重新设计新的网络结构
③ 论文中提到的clip项在公式的什么地方显示出来?
clip指的是算法伪代码中的c,也就是论文中提到的k,其中![]() ,该clip是一个范围,论文中采用(-0.01, 0.01)。
,该clip是一个范围,论文中采用(-0.01, 0.01)。
④ WGAN的评估标准是什么?该标准是怎么来的?意义又在何处?
待思考
⑤ 为什么不使用常用的Adam算法,而使用RMSProp进行优化?
待思考
⑥ 为什么判别器最后一层去掉sigmoid函数?
GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在WGAN中的判别器做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。