【CNN模型笔记(一)】Lenet-5模型+代码实现
LeNet神经网络由深度学习三巨头之一的Yan LeCun提出,他同时也是卷积神经网络 (CNN,Convolutional Neural Networks)之父。LeNet主要用来进行手写字符的识别与分类,并在美国的银行中投入了使用。LeNet的实现确立了CNN的结构,现在神经网络中的许多内容在LeNet的网络结构中都能看到,例如卷积层,Pooling层,ReLU层。虽然LeNet早在20世纪90年代就已经提出了,但由于当时缺乏大规模的训练数据,计算机硬件的性能也较低,因此LeNet神经网络在处理复杂问题时效果并不理想。虽然LeNet网络结构比较简单,但是刚好适合神经网络的入门学习。
Part1 相关理论
卷积的概念这个我想只要学过图像处理的人都懂的概念了,这个不解释。我们知道对于给定的一幅图像来说,给定一个卷积核,卷积就是根据卷积窗口,进行像素的加权求和。

卷积神经网络与我们之前所学到的图像的卷积的区别,我的理解是:我们之前学图像处理遇到卷积,一般来说,这个卷积核是已知的,比如各种边缘检测算子、高斯模糊等这些,都是已经知道卷积核,然后再与图像进行卷积运算。然而深度学习中的卷积神经网络卷积核是未知的,我们训练一个神经网络,就是要训练得出这些卷积核,而这些卷积核就相当于我们学单层感知器的时候的那些参数W,因此你可以把这些待学习的卷积核看成是神经网络的训练参数W。
2、池化
刚开始学习CNN的时候,看到这个词,好像高大上的样子,于是查了很多资料,理论一大堆,但是实践、算法实现却都没讲到,也不懂池化要怎么实现?其实所谓的池化,就是图片下采样。这个时候,你会发现CNN每一层的构建跟图像高斯金字塔的构建有点类似,因此你如果已经懂得了图像金字塔融合的相关算法,那么就变的容易理解了。在高斯金子塔构建中,每一层通过卷积,然后卷积后进行下采样,而CNN也是同样的过程。废话不多说,这里就讲一下,CNN的池化:
CNN的池化(图像下采样)方法很多:Mean pooling(均值采样)、Max pooling(最大值采样)、Overlapping (重叠采样)、L2 pooling(均方采样)、Local Contrast Normalization(归一化采样)、Stochasticpooling(随即采样)、Def-pooling(形变约束采样)。其中最经典的是最大池化,因此我就解释一下最大池化的实现:
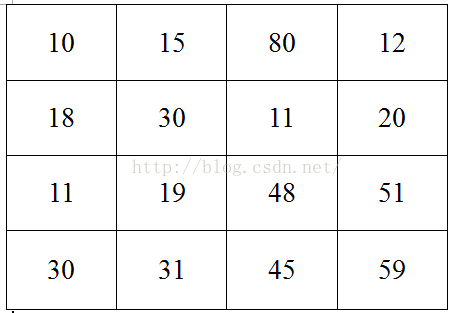
原图片
为了简单起见,我用上面的图片作为例子,假设上面的图片大小是4*4的,如上图所示,然后图片中每个像素点的值是上面各个格子中的数值。然后我要对这张4*4的图片进行池化,池化的大小为(2,2),跨步为2,那么采用最大池化也就是对上面4*4的图片进行分块,每个块的大小为2*2,然后统计每个块的最大值,作为下采样后图片的像素值,具体计算如下图所示:

也就是说我们最后得到下采样后的图片为:
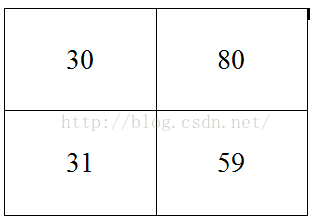
这就是所谓的最大池化。当然以后你还会遇到各种池化方法,比如均值池化,也就是对每个块求取平均值作为下采样的新像素值。还有重叠采样的池化,我上面这个例子是没有重叠的采样的,也就是每个块之间没有相互重叠的部分,上面我说的跨步为2,就是为了使得分块都非重叠,等等,这些以后再跟大家解释池化常用方法。这里就先记住最大池化就好了,因为这个目前是最常用的。
3、feature maps
这个单词国人把它翻译成特征图,挺起来很专业的名词。那么什么叫特征图呢?其实一张图片经过一个卷积核进行卷积运算,我们可以得到一张卷积后的结果图片,而这张图片就是特征图。在CNN中,我们要训练的卷积核并不是仅仅只有一个,这些卷积核用于提取特征,卷积核个数越多,提取的特征越多,理论上来说精度也会更高,然而卷积核一堆,意味着我们要训练的参数的个数越多。在LeNet-5经典结构中,第一层卷积核选择了6个,而在AlexNet中,第一层卷积核就选择了96个,具体多少个合适,还有待学习。
回到特征图概念,CNN的每一个卷积层我们都要人为的选取合适的卷积核个数,及卷积核大小。每个卷积核与图片进行卷积,就可以得到一张特征图了,比如LeNet-5经典结构中,第一层卷积核选择了6个,我们可以得到6个特征图,这些特征图也就是下一层网络的输入了。我们也可以把输入图片看成一张特征图,作为第一层网络的输入。
Part2 Lenet模型
首先,我们给出LeNet-5卷积神经网络的整体框架:
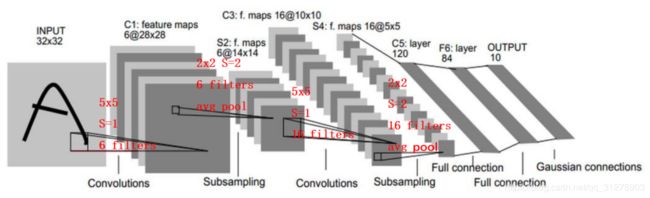
特征映射:一幅图在经过卷积操作后得到结果称为feature map。
LeNet-5共有8层,包含输入层,每层都包含可训练参数;每个层有多个特征映射(Feature Map),每个特征映射通过一种卷积核(或者叫滤波器)提取输入的一种特征,然后每个特征映射有多个神经元。C层代表的是卷积层,通过卷积操作,可以使原信号特征增强,并且降低噪音。 S层是一个降采样层,利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息。
计算公式:输入图像的大小为nxn,卷积核的大小为mxm,步长为s, 为输入图像两端填补p个零(zero padding),那么卷积操作之后输出的大小为(n-m+2p)/s + 1。
1、INPUT层-输入层
首先是数据 INPUT 层,输入图像的尺寸统一归一化为32*32。
2、C1层-卷积层
输入图片:32*32
卷积核大小:5*5
卷积核种类:6
步长为:1
输出特征映射大小:28*28 (32-5+1)=28
神经元数量:28*28*6
可训练参数:(5*5+1) * 6(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器)
连接数:(5*5+1)*6*28*28=122304
详细说明:对输入图像进行第一次卷积运算(使用 6个大小为 5*5 的卷积核),得到6个28x28 的特征映射。我们再来看看需要多少个参数,卷积核的大小为5*5,总共就有6*(5*5+1)=156个参数,其中+1是表示一个卷积核有一个bias参数。对于卷积层C1,C1内的每个像素都与输入图像中的5*5个像素和1个bias有连接,所以总共有156*28*28=122304个连接(connection)。有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。
3、S2层-池化层(降采样层-平均采样)
输入:28*28
采样区域:2*2
采样方式:平均池化,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid函数激活。
采样种类:6
步长为:2
输出特征映射的大小:14*14(28/2)
神经元数量:14*14*6
可训练参数:2*6(和的权+偏置)
连接数:(2*2+1)*6*14*14
S2中每个特征图的大小是C1中特征图大小的1/4。
详细说明:卷积之后紧接着就是池化运算,使用 2*2核进行池化,于是得到了S2,6个14*14的特征图(28/2=14)。S2汇聚层是对C1中的2*2区域内的像素求平均,乘以一个权值系数再加上一个偏置,然后将这个结果再做一次激活映射,于是每个池化之后的特征映射有两个训练参数,所以共有2x6=12个训练参数,但是有(2*2+1)x 14 x 14 x 6=5880个连接。
4、C3层-卷积层--(使用了复杂的局部连接)
输入:S2中所有6个或者几个特征映射的组合
卷积核大小:5*5
卷积核种类:16
步长为:1
输出特征映射的大小:10*10 (14-5+1) =10
C3中的每个特征映射是连接到S2中6个或者几个特征映射的组合,表示本层的特征映射是提取上一层特征映射的不同组合。
其中一个方式是:C3的前6个特征映射(feature map),把S2中3个相邻的特征映射子集为输入。接下来C3的6个特征映射以S2中4个相邻特征映射子集为输入。然后C3的3个特征映射以不相邻的4个特征映射子集为输入。最后一个将S2中所有特征图为输入。
则:可训练参数:6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516
连接数:10*10*1516=151600
详细说明:第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个10x10的特征映射,卷积核大小是 5*5. 我们知道S2 有6个 14*14 的特征映射,怎么从S2的6 个特征映射得到 C3的16个特征映射了? 这里是通过对S2 特征映射的特殊组合计算得到的16个特征图。具体如下:
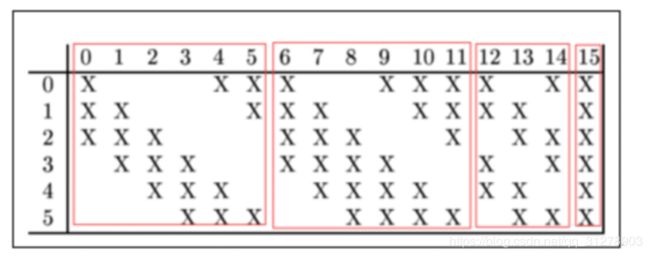
C3的前6个特征映射(feature map)(对应上图第一个红框的6列)与S2层相连的3个特征映射相连接(上图第一个红框),后面6个特征映射与S2层相连的4个特征映射相连接(上图第二个红框),后面3个特征映射与S2层部分不相连的4个特征映射相连接,最后一个与S2层的所有特征映射相连。卷积核大小依然为5*5,所以总共有6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516个参数。而图像大小为10*10,所以共有151600个连接。
C3与S2中前3个图相连的卷积结构如下图所示:
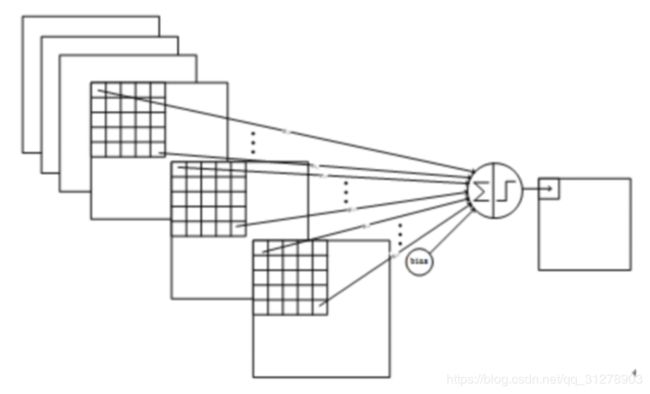
上图对应的参数为 3*5*5+1,一共进行6次卷积得到6个特征图,所以有6*(3*5*5+1)参数。 为什么采用上述这样的组合了?论文中说有两个原因:1)减少参数,2)这种不对称的组合连接的方式有利于提取多种组合特征。
5、S4层-池化层(降采样层)
输入:10*10
采样区域:2*2
采样方式:平均池化,一个参数,再加上一个偏置。结果通过sigmoid函数激活。
采样种类:16
步长为:2
输出特征映射大小:5*5(10/2)
神经元数量:5*5*16=400
可训练参数:2*16=32(和的权+偏置)
连接数:16*(2*2+1)*5*5=2000
S4中每个特征图的大小是C3中特征图大小的1/4
详细说明:S4是池化层,窗口大小仍然是2*2,共计16个特征映射,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征映射。这一层有2x16共32个训练参数,5x5x5x16=2000个连接。连接的方式与S2层类似。
6、C5层-卷积层
输入:S4层的全部16个单元特征映射(与 S4全相连)
卷积核大小:5*5
卷积核种类:120*16
输出特征映射的大小:1*1(5-5+1)
步长为:1
可训练参数/连接:120*(16*5*5+1)=48120
详细说明:C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。C5层的网络结构如下:
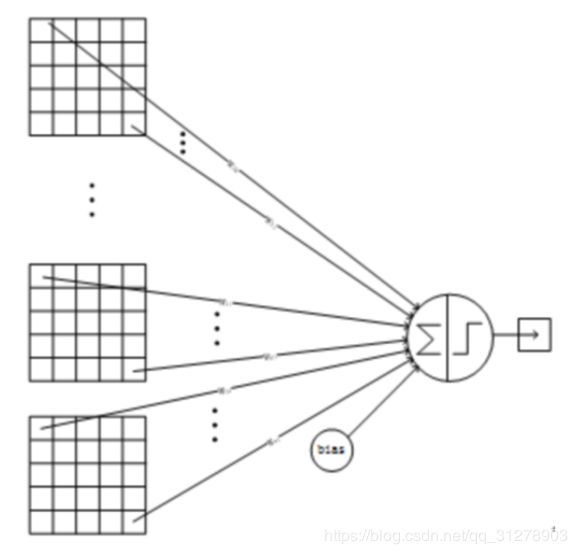
7、F6层-全连接层
输入:C5的120维向量
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。
可训练参数:84*(120+1)=10164
详细说明:6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。ASCII编码图如下:

F6层的连接方式如下:
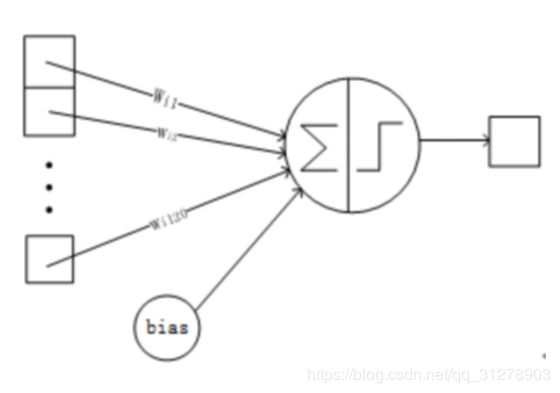
8、Output层-全连接层
Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
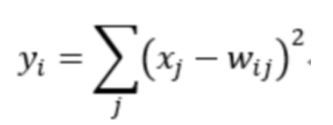
上式的值由的比特图编码确定,从0到9,取值从0到7*12-1。RBF输出的值越接近于0,则越接近于的ASCII编码图,表示当前网络输入的识别结果是字符。该层有84x10=840个参数和连接。
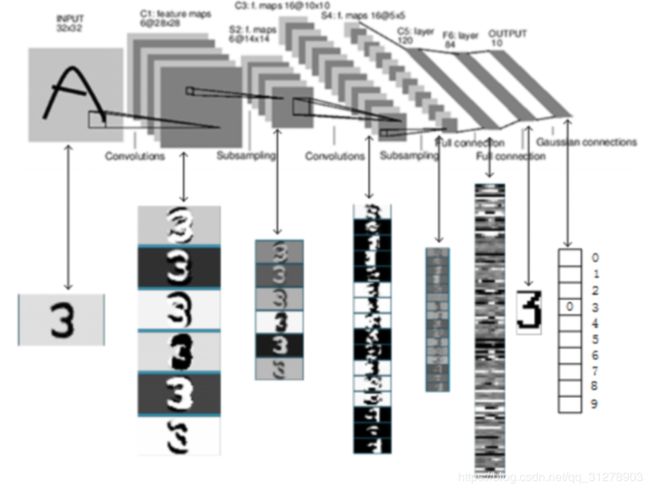
上图是LeNet-5识别数字3的过程。
四、总结
LeNet-5是一种用于手写体字符识别的卷积神经网络。
卷积神经网络能够很好的利用图像的结构信息。
卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
五、代码实现
首先你要知道mnist.pkl.gz这个库给我们的图片的大小是28*28的,因此我们可以第一步选择5*5的卷积核进行卷积得到24*24,同时我们希望C1层得到20张特征图,等等,具体的代码实现如下;
import os
import sys
import timeit
import numpy
import theano
import theano.tensor as T
from theano.tensor.signal import downsample
from theano.tensor.nnet import conv
from logistic_sgd import LogisticRegression, load_data
from mlp import HiddenLayer
#卷积神经网络的一层,包含:卷积+下采样两个步骤
#算法的过程是:卷积-》下采样-》激活函数
class LeNetConvPoolLayer(object):
#image_shape是输入数据的相关参数设置 filter_shape本层的相关参数设置
def __init__(self, rng, input, filter_shape, image_shape, poolsize=(2, 2)):
"""
:type rng: numpy.random.RandomState
:param rng: a random number generator used to initialize weights
3、input: 输入特征图数据,也就是n幅特征图片
4、参数 filter_shape: (number of filters, num input feature maps,
filter height, filter width)
num of filters:是卷积核的个数,有多少个卷积核,那么本层的out feature maps的个数
也将生成多少个。num input feature maps:输入特征图的个数。
然后接着filter height, filter width是卷积核的宽高,比如5*5,9*9……
filter_shape是列表,因此我们可以用filter_shape[0]获取卷积核个数
5、参数 image_shape: (batch size, num input feature maps,
image height, image width),
batch size:批量训练样本个数 ,num input feature maps:输入特征图的个数
image height, image width分别是输入的feature map图片的大小。
image_shape是一个列表类型,所以可以直接用索引,访问上面的4个参数,索引下标从
0~3。比如image_shape[2]=image_heigth image_shape[3]=num input feature maps
6、参数 poolsize: 池化下采样的的块大小,一般为(2,2)
"""
assert image_shape[1] == filter_shape[1]#判断输入特征图的个数是否一致,如果不一致是错误的
self.input = input
# fan_in=num input feature maps *filter height*filter width
#numpy.prod(x)函数为计算x各个元素的乘积
#也就是说fan_in就相当于每个即将输出的feature map所需要链接参数权值的个数
fan_in = numpy.prod(filter_shape[1:])
# fan_out=num output feature maps * filter height * filter width
fan_out = (filter_shape[0] * numpy.prod(filter_shape[2:]) /
numpy.prod(poolsize))
# 把参数初始化到[-a,a]之间的数,其中a=sqrt(6./(fan_in + fan_out)),然后参数采用均匀采样
#权值需要多少个?卷积核个数*输入特征图个数*卷积核宽*卷积核高?这样没有包含采样层的链接权值个数
W_bound = numpy.sqrt(6. / (fan_in + fan_out))
self.W = theano.shared(
numpy.asarray(
rng.uniform(low=-W_bound, high=W_bound, size=filter_shape),
dtype=theano.config.floatX
),
borrow=True
)
# b为偏置,是一维的向量。每个输出特征图i对应一个偏置参数b[i]
#,因此下面初始化b的个数就是特征图的个数filter_shape[0]
b_values = numpy.zeros((filter_shape[0],), dtype=theano.config.floatX)
self.b = theano.shared(value=b_values, borrow=True)
# 卷积层操作,函数conv.conv2d的第一个参数为输入的特征图,第二个参数为随机出事化的卷积核参数
#第三个参数为卷积核的相关属性,输入特征图的相关属性
conv_out = conv.conv2d(
input=input,
filters=self.W,
filter_shape=filter_shape,
image_shape=image_shape
)
# 池化操作,最大池化
pooled_out = downsample.max_pool_2d(
input=conv_out,
ds=poolsize,
ignore_border=True
)
#激励函数,也就是说是先经过卷积核再池化后,然后在进行非线性映射
# add the bias term. Since the bias is a vector (1D array), we first
# reshape it to a tensor of shape (1, n_filters, 1, 1). Each bias will
# thus be broadcasted across mini-batches and feature map
# width & height
self.output = T.tanh(pooled_out + self.b.dimshuffle('x', 0, 'x', 'x'))
# 保存参数
self.params = [self.W, self.b]
self.input = input
#测试函数
def evaluate_lenet5(learning_rate=0.1, n_epochs=200,
dataset='mnist.pkl.gz',
nkerns=[20, 50], batch_size=500):
""" Demonstrates lenet on MNIST dataset
:learning_rate: 梯度下降法的学习率
:n_epochs: 最大迭代次数
:type dataset: string
:param dataset: path to the dataset used for training /testing (MNIST here)
:nkerns: 每个卷积层的卷积核个数,第一层卷积核个数为 nkerns[0]=20,第二层卷积核个数
为50个
"""
rng = numpy.random.RandomState(23455)
datasets = load_data(dataset)#加载训练数据,训练数据包含三个部分
train_set_x, train_set_y = datasets[0]#训练数据
valid_set_x, valid_set_y = datasets[1]#验证数据
test_set_x, test_set_y = datasets[2]#测试数据
# 计算批量训练可以分多少批数据进行训练,这个只要是知道批量训练的人都知道
n_train_batches = train_set_x.get_value(borrow=True).shape[0]#训练数据个数
n_valid_batches = valid_set_x.get_value(borrow=True).shape[0]
n_test_batches = test_set_x.get_value(borrow=True).shape[0]
n_train_batches /= batch_size#批数
n_valid_batches /= batch_size
n_test_batches /= batch_size
# allocate symbolic variables for the data
index = T.lscalar() # index to a [mini]batch
# start-snippet-1
x = T.matrix('x') # the data is presented as rasterized images
y = T.ivector('y') # the labels are presented as 1D vector of
# [int] labels
# Reshape matrix of rasterized images of shape (batch_size, 28 * 28)
# to a 4D tensor, compatible with our LeNetConvPoolLayer
# (28, 28) is the size of MNIST images.
layer0_input = x.reshape((batch_size, 1, 28, 28))
'''''构建第一层网络:
image_shape:输入大小为28*28的特征图,batch_size个训练数据,每个训练数据有1个特征图
filter_shape:卷积核个数为nkernes[0]=20,因此本层每个训练样本即将生成20个特征图
经过卷积操作,图片大小变为(28-5+1 , 28-5+1) = (24, 24)
经过池化操作,图片大小变为 (24/2, 24/2) = (12, 12)
最后生成的本层image_shape为(batch_size, nkerns[0], 12, 12)'''
layer0 = LeNetConvPoolLayer(
rng,
input=layer0_input,
image_shape=(batch_size, 1, 28, 28),
filter_shape=(nkerns[0], 1, 5, 5),
poolsize=(2, 2)
)
'''''构建第二层网络:输入batch_size个训练图片,经过第一层的卷积后,每个训练图片有nkernes[0]个特征图,每个特征图
大小为12*12
经过卷积后,图片大小变为(12-5+1, 12-5+1) = (8, 8)
经过池化后,图片大小变为(8/2, 8/2) = (4, 4)
最后生成的本层的image_shape为(batch_size, nkerns[1], 4, 4)'''
layer1 = LeNetConvPoolLayer(
rng,
input=layer0.output,
image_shape=(batch_size, nkerns[0], 12, 12),
filter_shape=(nkerns[1], nkerns[0], 5, 5),
poolsize=(2, 2)
)
# the HiddenLayer being fully-connected, it operates on 2D matrices of
# shape (batch_size, num_pixels) (i.e matrix of rasterized images).
# This will generate a matrix of shape (batch_size, nkerns[1] * 4 * 4),
# or (500, 50 * 4 * 4) = (500, 800) with the default values.
layer2_input = layer1.output.flatten(2)
'''''全链接:输入layer2_input是一个二维的矩阵,第一维表示样本,第二维表示上面经过卷积下采样后
每个样本所得到的神经元,也就是每个样本的特征,HiddenLayer类是一个单层网络结构
下面的layer2把神经元个数由800个压缩映射为500个'''
layer2 = HiddenLayer(
rng,
input=layer2_input,
n_in=nkerns[1] * 4 * 4,
n_out=500,
activation=T.tanh
)
# 最后一层:逻辑回归层分类判别,把500个神经元,压缩映射成10个神经元,分别对应于手写字体的0~9
layer3 = LogisticRegression(input=layer2.output, n_in=500, n_out=10)
# the cost we minimize during training is the NLL of the model
cost = layer3.negative_log_likelihood(y)
# create a function to compute the mistakes that are made by the model
test_model = theano.function(
[index],
layer3.errors(y),
givens={
x: test_set_x[index * batch_size: (index + 1) * batch_size],
y: test_set_y[index * batch_size: (index + 1) * batch_size]
}
)
validate_model = theano.function(
[index],
layer3.errors(y),
givens={
x: valid_set_x[index * batch_size: (index + 1) * batch_size],
y: valid_set_y[index * batch_size: (index + 1) * batch_size]
}
)
#把所有的参数放在同一个列表里,可直接使用列表相加
params = layer3.params + layer2.params + layer1.params + layer0.params
#梯度求导
grads = T.grad(cost, params)
# train_model is a function that updates the model parameters by
# SGD Since this model has many parameters, it would be tedious to
# manually create an update rule for each model parameter. We thus
# create the updates list by automatically looping over all
# (params[i], grads[i]) pairs.
updates = [
(param_i, param_i - learning_rate * grad_i)
for param_i, grad_i in zip(params, grads)
]
train_model = theano.function(
[index],
cost,
updates=updates,
givens={
x: train_set_x[index * batch_size: (index + 1) * batch_size],
y: train_set_y[index * batch_size: (index + 1) * batch_size]
}
)
# end-snippet-1
###############
# TRAIN MODEL #
###############
print '... training'
# early-stopping parameters
patience = 10000 # look as this many examples regardless
patience_increase = 2 # wait this much longer when a new best is
# found
improvement_threshold = 0.995 # a relative improvement of this much is
# considered significant
validation_frequency = min(n_train_batches, patience / 2)
# go through this many
# minibatche before checking the network
# on the validation set; in this case we
# check every epoch
best_validation_loss = numpy.inf
best_iter = 0
test_score = 0.
start_time = timeit.default_timer()
epoch = 0
done_looping = False
while (epoch < n_epochs) and (not done_looping):
epoch = epoch + 1
for minibatch_index in xrange(n_train_batches):#每一批训练数据
cost_ij = train_model(minibatch_index)
iter = (epoch - 1) * n_train_batches + minibatch_index
if (iter + 1) % validation_frequency == 0:
# compute zero-one loss on validation set
validation_losses = [validate_model(i) for i
in xrange(n_valid_batches)]
this_validation_loss = numpy.mean(validation_losses)
print('epoch %i, minibatch %i/%i, validation error %f %%' %
(epoch, minibatch_index + 1, n_train_batches,
this_validation_loss * 100.))
# if we got the best validation score until now
if this_validation_loss < best_validation_loss:
#improve patience if loss improvement is good enough
if this_validation_loss < best_validation_loss * \
improvement_threshold:
patience = max(patience, iter * patience_increase)
# save best validation score and iteration number
best_validation_loss = this_validation_loss
best_iter = iter
# test it on the test set
test_losses = [
test_model(i)
for i in xrange(n_test_batches)
]
test_score = numpy.mean(test_losses)
print((' epoch %i, minibatch %i/%i, test error of '
'best model %f %%') %
(epoch, minibatch_index + 1, n_train_batches,
test_score * 100.))
if patience <= iter:
done_looping = True
break
end_time = timeit.default_timer()
print('Optimization complete.')
print('Best validation score of %f %% obtained at iteration %i, '
'with test performance %f %%' %
(best_validation_loss * 100., best_iter + 1, test_score * 100.))
print >> sys.stderr, ('The code for file ' +
os.path.split(__file__)[1] +
' ran for %.2fm' % ((end_time - start_time) / 60.))
if __name__ == '__main__':
evaluate_lenet5()
def experiment(state, channel):
evaluate_lenet5(state.learning_rate, dataset=state.dataset) 【参考】
http://www.deeplearning.net/tutorial/lenet.html#lenet(官方源码实现[英])
https://blog.csdn.net/yangyang688/article/details/82884336(讲解)
https://blog.csdn.net/yangyang688/article/details/82800022(实现)
https://www.cnblogs.com/muyangshaonian/p/9650486.html