Neuraltalk2
文章目录
- Neuraltalk2 说明
- 准备工作
- 1. torch安装
- 2. 下载依赖
- 2.1 lua相关依赖包
- 2.2 安装CJson
- 2.3 使用GPU
- 2.4 安装loadcaffe
- 2.5 安装hdf5
- 执行检测
- 测试结果
- 在 MS COCO 上训练网络
- 其他问题
- 1. 没有 GPU
- 2. 在视频上进行 caption
- 遇到的错误
- cannot open eval.lua: No such file or directory
- hdf5:Unsupported HDF5 version: 1.10.1
- RuntimeError: cublas runtime error : library not initialized
- Permission denied
- error: read 0 blocks instead of 1
- localhost refused to connect
- CMake Error at CMakeLists.txt:30 (FIND_PACKAGE): Could not find a configuration file for package "OpenCV" that exactly matches requested version "3.1"
- Failed to open the default camera
Neuraltalk2 说明
Neuraltalk论文:Deep Visual-Semantic Alignments for Generating Image Descriptions
之前的版本是 Neuraltalk,采用 python 编写,但是由于效率较低而且有了更好的 Neuraltalk2,所以这个版本现在已经不再做维护,这里只提供代码,如果有需要的话。
Neuraltalk 代码地址:Neuraltalk
Neuraltalk2 与 Neuraltalk 相比,改进在于采用了 Torch,比 Neuraltalk 的训练速度快 100 倍以上(因为进行了 batch & 采用 GPU),而且支持 CNN finetuning,所以 Neuraltalk2 的性能更好。
注意:Neuraltalk2 网络结构采用了 VGGNet,通常自己训练模型的话需要 2-3 天。
Neuraltalk2 代码:github nerualtalk2
模型:model_id1-501-1448236541.t7
测试结果:demo
代码是用 Lua 写的,框架是 Torch
准备工作
1. torch安装
在 Ubuntu 系统下,下载 Torch 到自己的目录下:
$ curl -s https://raw.githubusercontent.com/torch/ezinstall/master/install-deps | bash
$ git clone https://github.com/torch/distro.git ~/torch --recursive
$ cd ~/torch;
$ ./install.sh # and enter "yes" at the end to modify your bashrc
$ source ~/.bashrc
2. 下载依赖
2.1 lua相关依赖包
Torch 安装好以后,还要用包管理工具 LuaRocks 安装一些额外的工具包:
$ luarocks install nn
$ luarocks install nngraph
$ luarocks install image
2.2 安装CJson
在 download link 下载 Lua CJSON,让我们可以下载或保存 json 文件,参见用户手册的 2.4 节进行简单的安装 Manual
这里搬运将安装手册的 2.4 搬运过来:
对 Lua CJSON 进行解压,然后用 LuaRocks 安装 Lua CJSON 就 OK 了:
$ tar -xzvf lua-cjson-2.1.0.tar.gz
$ cd lua-cjson-2.1.0
$ luarocks make
2.3 使用GPU
如果要用 NVIDIA GPU ,那还要安装 CUDA Toolkit,然后安装 cutorch 和 cunn 包:
$ luarocks install cutorch
$ luarocks install cunn
如果要用 cudnn,那么在 NVIDIA website 注册然后下载 cudnn library,修改环境变量 LD_LIBRARY_PATH 指向 lib64 文件夹(比如要包含 libcudnn.so.7.0.64)。然后 git clone cudnn.torch,cd 到该文件夹目录下,执行 luarocks make cudnn-scm-1.rockspec 建立 Torch binfings。
2.4 安装loadcaffe
如果要自己训练模型,需要使用 loadcaffe,因为 Neuraltalk 使用了 VGGNet。
首先,安装 protobuf 并执行一系列操作(比如 sudo apt-get install libprotobuf-dev protobuf-compiler)然后通过包管理工具 luarocks 安装 loadcaffe:
$ sudo apt-get install libprotobuf-dev protobuf-compiler
$ luarocks install loadcaffe
2.5 安装hdf5
安装 torch-hdf5 和 h5py,因为这里需要使用 hdf5 存储预处理的数据。
$ sudo pip install h5py
执行检测
论文有在 MS COCO dataset 上预训练好的模型 checkpoint(大约 600 M),可以直接对自己的图像进行 caption。
pretrained checkpoint:model_id1-501-1448236541.t7
将自己的图片放在一个文件夹里,比如 images,然后执行语句:
$ th eval.lua -model /data/monn/neuraltalk2/model_id1-501-1448236541.t7 -image_folder /data/monn/neuraltalk2/images -num_images 10
/data/monn/neuraltalk2/model_id1-501-1448236541.t7是你模型的路径/data/monn/neuraltalk2/images是你存放照片的路径- 最后的 10 是说最多检测
images中的 10 张照片,如果采用 GPU 进行测试,那么就可以增加这个 batch_size(默认为 1),使用-num_images -1来检测所有照片
在执行了 eval 脚本后,会在 vis 文件夹中生成一个文件 vis.json,我们可以将这个文件在 HTML 接口中进行可视化:
$ cd vis
$ python -m SimpleHTTPServer
python -m SimpleHTTPServer是 python2 的写法,如果使用 python3,需要修改为python -m http.server,或者python -m http.server 8000,8000可以不写,默认是 8000,如果需要别的端口可以修改数字
最后访问 localhost:8000,就可以看到对图片预测的 caption。
测试结果
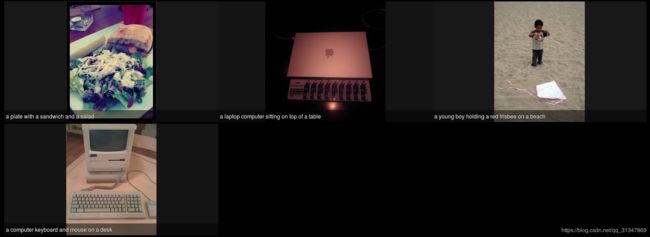
随便从 VOC2007 中选了 20 张图片的测试结果:前面是一些出错的 caption,后面有的倒是很靠谱。




















在 MS COCO 上训练网络
首先,进入 coco/ 文件夹路径下,启动 IPython notebook 下载 COCO 数据集并做一些简单的预处理。
其他问题
1. 没有 GPU
如果只有 CPU,那么就下载 cpu model: cpu model checkpoint,同时在运行 eval 脚本时,加上 -gpuid -1,告诉脚本在想要在 CPU 上运行(CPU 进行 caption 的话大概每张图片将近 1s)
2. 在视频上进行 caption
如果安装了 OpenCV3,你也可以在视频上实时进行 caption,按照 torch-opencv 的指导来安装,然后用 videocaptioning.lua 来进行测试(和 evak.lua 同理),注意只有中心物体会有 caption。
安装执行过程:
首先确保安装了 OpenCV 3.1 和 Torch 7,然后执行:
luarocks install cv
*如果 CMake 没有找到 OpenCV 3.1,可以辅助以指定其路径:
OpenCV_DIR="" luarocks install cv
*如果不希望与某些模块绑定,可以通过 DONT_WRAP 环境变量修改安装语句:
DONT_WRAP="xphoto;superres" luarocks install cv
*如果不希望与 CUDA 包绑定,可以修改安装语句:
OpenCV_DIR="/home/sir/opencv-3.1.0/install" WITH_CUDA=OFF luarocks install cv
安装完毕后。执行 demo 测试一下:
th demo/videocap.lua
th demo/flann.lua
th demo/SVM.lua
th demo/trackbar.lua
遇到的错误
cannot open eval.lua: No such file or directory
一个低级错误,在对图片进行测试时,要保证路径在 neuraltalk2 的代码路径下:
/data/monn/neuraltalk2$ th eval.lua -model /data/monn/neuraltalk2 -image_folder /data/monn/neuraltalk2/images -num_images 10
hdf5:Unsupported HDF5 version: 1.10.1
解决方法:
git clone https://github.com/anibali/torch-hdf5.git
cd torch-hdf5
git checkout hdf5-1.10
luarocks make hdf5-0-0.rockspec
RuntimeError: cublas runtime error : library not initialized
解决方法:
sudo rm -rf ~/.nv
Permission denied
解决方法:
第一种:创建一个虚拟环境来安装包
python3 -m venv env
source ./env/bin/activate
python -m pip install google-assistant-sdk[samples]
第二种:将包安装在用户目录下
python -m pip install --user google-assistant-sdk[samples]
error: read 0 blocks instead of 1
cd ~/torch
git pull
./update.sh
localhost refused to connect
做预测的最后一步,生成过程都没有问题,就是想要在网页上进行可视化时打不开 localhost:8000!
感觉自己有些傻,我是远程连接服务器测试的图片,在本地电脑上当然打不开啊!!
解决:
用 MovaXterm 在服务器上安装 firefox 浏览器(不用 Xshell 是因为懒得装 Xmanager),然后在 vis 文件夹下启动 HttpServer,即运行 python -m http.server,重新再打开一个服务器连接界面,输入 firefox,就可以打开浏览器了,这时再在地址栏输入 localhost:8000,成功。
安装 firefox 浏览器:
sudo apt-get install firefox
此时 firefox 在当前 Windows 终端打开,但是进行的一系列操作都是基于 Linux 的,而不是 Windows 本机的浏览器。
CMake Error at CMakeLists.txt:30 (FIND_PACKAGE): Could not find a configuration file for package “OpenCV” that exactly matches requested version “3.1”
在安装 torch_opencv 时,按照指导执行安装命令:luarocks install cv,结果报错 CMake Error at CMakeLists.txt:30 (FIND_PACKAGE): Could not find a configuration file for package "OpenCV" that exactly matches requested version "3.1"
解决:
- 安装 Anaconda
conda create 0n opencv3.1 python=3conda activate opencv3.1conda install -c conda-forge opencv==3.1.0- 安装 torch_opencv:
OpenCV_DIR=/data/monn/usr/local/anaconda3/pkgs/opencv-3.1.0 luarocks install cv
Failed to open the default camera
在解决上一个问题后,运行 demo 里的小视频结果又报错无法打开相机。