Python实现统计文本当中单词的数量,
这是阿里巴巴2016年的一道面试题:
统计英文文章中单词出现的次数,并且输出出现次数的前10个单词
文本如下:
Accessing Text from the Web and from Disk
Electronic Books
A small sample of texts from Project Gutenberg appears in the NLTK corpus collection. However, you may be interested in analyzing other texts from Project Gutenberg. You can browse the catalog of 25,000 free online books at http://www.gutenberg.org/catalog/, and obtain a URL to an ASCII text file. Although 90% of the texts in Project Gutenberg are in English, it includes material in over 50 other languages, including Catalan, Chinese, Dutch, Finnish, French, German, Italian,
先简单的看了下文章,基本单词间的分隔都是空格,或者是逗号加空格
方法一
1、先打开文档,进行初步分析
def read_file():
f=open('F:\\Python\\testfile\\test_3.txt')
readline=f.readlines()
word=[]#存储单词
#得到文章的单词并且存入列表中:
for line in readline:
#因为原文中每个单词都是用空格 或者逗号加空格分开的,
line=line.replace(',','')#除去逗号只要空格来分开单词
line=line.strip()#除去左右的空格
wo=line.split(' ')
word.extend(wo)
return word
def clear_account(lists):
#去除重复的值
wokey={}
wokey=wokey.fromkeys(lists)#此代码的意思为将lists的元素作为wokey的键值key#通过这个代码可以除去重复的列表元素
word_1=list(wokey.keys())
#然后统计单词出现的次数,并将它存入一个字典中
for i in word_1:
wokey[i]=lists.count(i)
return wokey
def sort_1(wokey):
#删除''字符
del[wokey['']]#因为我发现字典中存在空元素,所以删去
#排序,按values进行排序,如果是按key进行排序用sorted(wokey.items(),key=lambda d:d[0],reverse=True)
wokey_1={}
wokey_1=sorted(wokey.items(),key=lambda d:d[1],reverse=True)
#得到的是一个列表,里面的元素为元组,所以再把他转化为字典,不过不转化也可以
wokey_1=dict(wokey_1)
return wokey_1
def main(wokey_1):
#输出前10个
i=0
for x,y in wokey_1.items():
if i<10:
print('the word is "','{}'.format(x),'"',' and its amount is "','{}'.format(y),'"')
i+=1
continue
else:
break5、运行程序得出结果
main(sort_1(clear_account(read_file())))
运行截图:
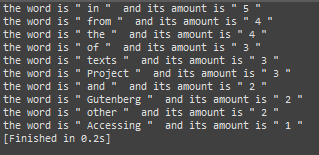
本程序到这里就结束了、下面是整个程序代码:
#读入一个文本,并且统计文本中单词的出现次数,输出出现次数前10个单词
def read_file():
f=open('F:\\Python\\testfile\\test_3.txt')
readline=f.readlines()
word=[]#存储单词
#得到文章的单词并且存入列表中:
for line in readline:
#因为原文中每个单词都是用空格 或者逗号加空格分开的,
line=line.replace(',','')#除去逗号只要空格来分开单词
line=line.strip()
wo=line.split(' ')
word.extend(wo)
return word
def clear_account(lists):
#去除重复的值
wokey={}
wokey=wokey.fromkeys(lists)
word_1=list(wokey.keys())
#然后统计单词出现的次数,并将它存入一个字典中
for i in word_1:
wokey[i]=lists.count(i)
return wokey
def sort_1(wokey):
#删除''字符
del[wokey['']]
#排序,按values进行排序,如果是按key进行排序用sorted(wokey.items(),key=lambda d:d[0],reverse=True)
wokey_1={}
wokey_1=sorted(wokey.items(),key=lambda d:d[1],reverse=True)
wokey_1=dict(wokey_1)
return wokey_1
def main(wokey_1):
#输出前10个
i=0
for x,y in wokey_1.items():
if i<10:
print('the word is "','{}'.format(x),'"',' and its amount is "','{}'.format(y),'"')
i+=1
continue
else:
break
main(sort_1(clear_account(read_file())))
不过值得注意的是,字典的排序很重要。
并且上面只给出了一种字典的排序,还有其他的排序比如:
a={'d':2,'f':4,'m':3}
b=a.keys()
c=a.values()
d=zip(b,c)#这里的b,c可以交换位置,
#key在前面就是按key值排序,values在前就是按values排序
print(sorted(d,reverse=False))方法二
下面的方法为Python Spark下的单词统计,这种方法不建议用在少量单词的计算上(spark为大数据集群计算平台,不做大数据的同学就别花时间去学了,还要下载spark,hadoop,和配环境)
#coding:utf-8
import sys
from pyspark import SparkConf, SparkContext
try:
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
print("connect success")
except Exception as e:
print("error",e)
sys.exit(1)
#计算每个键出现的次数与总值,可用于算均值
# try:
# lis=[("panda",0),("pink",3),("pirate",3),("panda",1),("pink",4),("panda",4)]
# rdd=sc.parallelize(lis)
# print(rdd.collect())
# key1=rdd.mapValues(lambda x: (x, 1))
# print(key1.collect())
# key2=key1.reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))
# print(key2.collect())
try:
lines=sc.textFile("F:/python/testfile/test_3_1.txt")
words=lines.flatMap(lambda x: x.split(" "))
print(words.collect())
result=words.map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y)
print(result.collect())
dict_1={}
for word in result.collect():
dict_1[word[0]]=word[1]
print(dict_1)
print("242343")
list_2=sorted(dict_1.items(),key=lambda d:d[1],reverse=True)
print(list_2)
i=0
for x in list_2:
if i<10:
print("word: ",x[0]," times: ",x[1])
i+=1
continue
else:
break
except Exception as e:
print(e)单词统计的话,应该还有其他的方法,比如NLTK,(想了解自然语言处理的可以学一下)。
学无止境嘛!