深度学习--CNN
1 卷积
特点:将需要的特征放大,不需要的特征缩小,进而达到过滤的作用,所以卷积核经常被称为滤波器
应用:图像轮廓分析,图像平滑(高斯平滑核),特征提取
连续:
一维卷积: s(t)=(x∗w)(t)=∫x(a)w(t−a)dt
二维卷积: S(t)=(K∗I)(i,j)=∫∫I(i,j)K(i−m,j−n)dmdn
离散:
一维卷积: s(t)=(x∗w)(t)=∑ax(a)w(t−a)
二维卷积: S(i,j)=(K∗I)(i,j)=∑m∑nI(i,j)K(i−m,j−n)
卷积具有交换性,即
(K∗I)(i,j)=(I∗K)(i,j)
∑m∑nI(i,j)K(i−m,j−n)=∑m∑nI(i−m,j−n)K(i,j)
编程实现中:
二维卷积: S(t)=(K∗I)(i,j)=∑m∑nI(i+m,j+n)K(i,j)
这个定义就不具有交换性
上面的 w,K 称为核, s(t),S(i,j) 有时候称为特征映射。
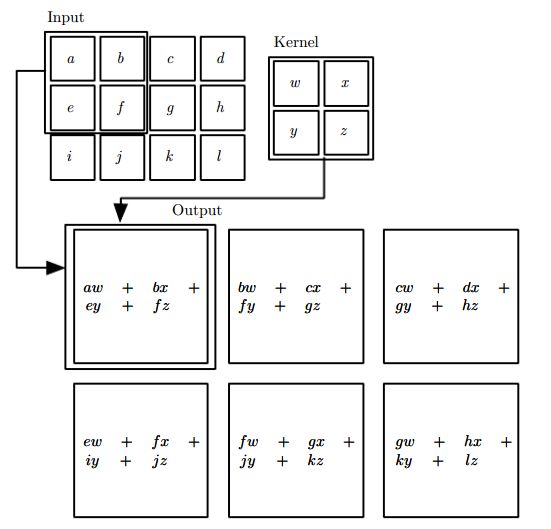
在卷积网络的术语中,卷积的第一个参数(函数 x)通常叫做输入(input),第二个参数(函数 w)叫做核函数(kernel function),输出被称作特征映射(feature map)。
2 卷积神经网络的三个思想
卷积神经网络主要利用3个思想:稀疏连接、参数共享、平移不变性。
- 稀疏连接

一个神经元的感知视野是指能够影响该神经元的其他神经元。如上图中 x3 的感知视野是 s2,s3,s4 。深度卷经网络中,深层单元的感知视野比浅层单元的大。
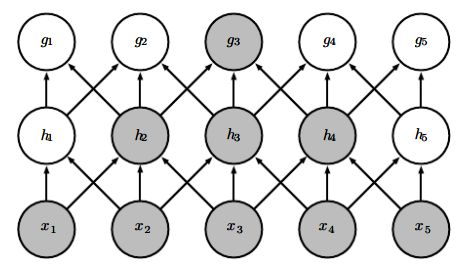
目的:减少参数
- 参数共享
如果我们在稀疏连接方面需要100个参数,我们可以在100个参数(也就是卷积操作)看成是提取特征的方式,该方式与位置无关。这其中隐含的原理则是:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
- 平移不变性
参数共享会导致平移不变性。网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性 - 称 f(x) 对 g(x) 是不变的,如果 f(g(x))=g(f(x)) 。例如 I(x,y) 是一张图像, g(I)=I(x−1,y) ,则 (g(I)∗K)=g((I∗K))
池化(pooling)
3、池化
池化输出的是邻近区域的概括统计量,一般是矩形区域。池化有最大池化、平均池化、滑动平均池化、 L2 范数池化等。
池化使用函数核最小的sigmod函数使得特征获得平移不变性。如果我们只关心某些特征是否存在而不是在哪里时,平移不变性就很有用了。卷积也会产生平移不变性,注意区分,卷积对输入平移是不变的,池化对特征平移是不变的。
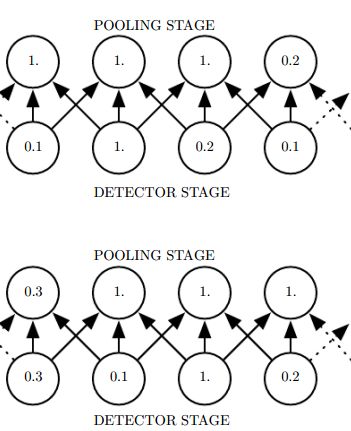
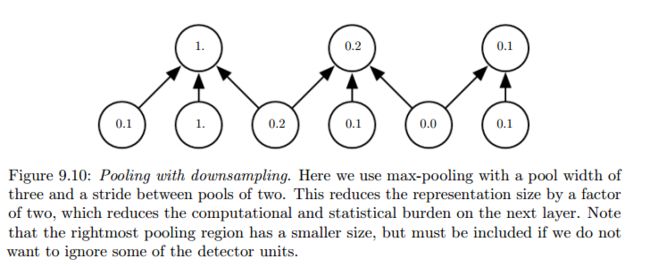
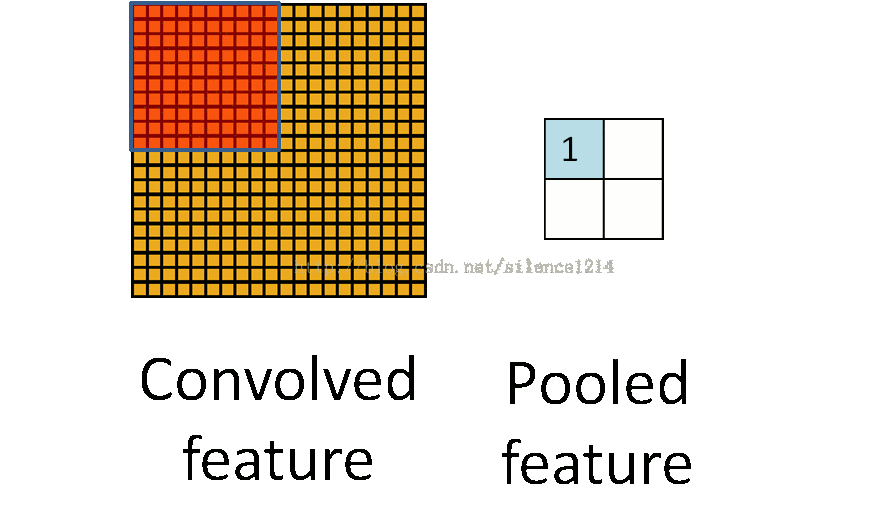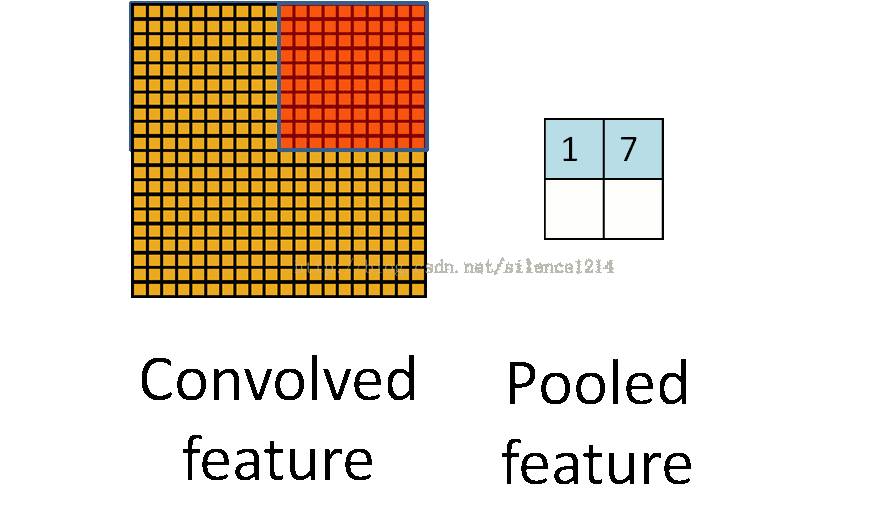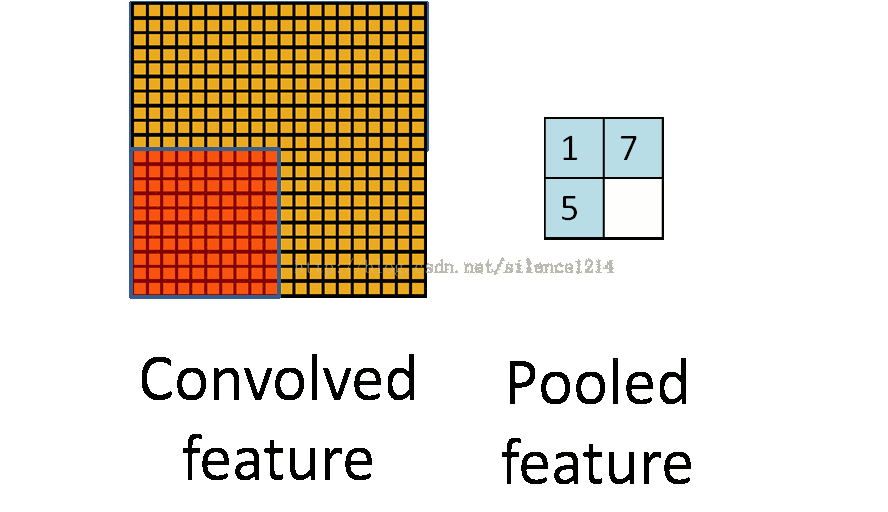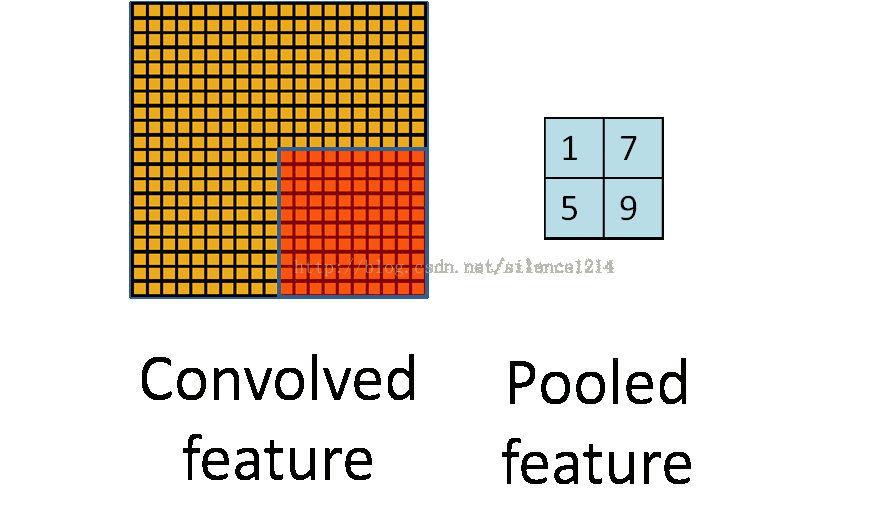
4、卷积网络工作流程
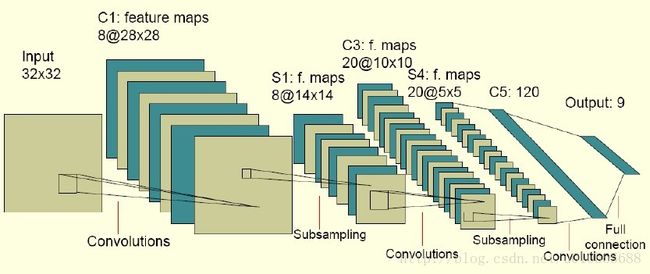
| C元 | 卷积层提取的局部特征 | S元 | 特征提取层的局部特征 |
| C面 | 卷积层提取的每个特征集合 | S面 | 特征提取层的每个特征集合 |
| C层(Uc) | 卷积层提取的全部特征集合 | S层 | 特征提取层的全部特征集合 |
图中的卷积网络工作流程如下,输入层由32×32个感知节点组成,接收原始图像。然后,计算流程在卷积和子抽样之间交替进行,如下所述:
第一隐藏层进行卷积,它由8个特征映射组成,每个特征映射由28×28个神经元组成,每个神经元指定一个 5×5 的接受域;
第二隐藏层进行池化,实现子 抽样和局部平均,它同样由 8 个特征映射组成,但其每个特征映射由14×14 个神经元组成。每个神经元具有一个 2×2 的接受域,一个可训练 系数,一个可训练偏置和一个 sigmoid 激活函数。可训练系数和偏置控制神经元的操作点。
第三隐藏层进行第二次卷积,它由 20 个特征映射组 成,每个特征映射由 10×10 个神经元组成。该隐藏层中的每个神经元可能具有和下一个隐藏层几个特征映射相连的突触连接,它以与第一个卷积 层相似的方式操作。
第四个隐藏层进行第二次子抽样和局部平均汁算。它由 20 个特征映射组成,但每个特征映射由 5×5 个神经元组成,它以 与第一次抽样相似的方式操作。
第五个隐藏层实现卷积的最后阶段,它由 120 个神经元组成,每个神经元指定一个 5×5 的接受域。
最后是个全 连接层,得到输出向量。
相继的计算层在卷积和抽样之间的连续交替,我们得到一个“双尖塔”的效果,也就是在每个卷积或抽样层,随着空 间分辨率下降,与相应的前一层相比特征映射的数量增加。
5、注
valid:也就是不补零。
same:在图像边缘补零,使得输入和输出大小相同。
| 原图 | 1000×1000 | 1000×1000 |
| 滤波器(卷积核) | 10×10+1(偏置) | 10×10×10+10 |
| 步长 | 10 | 10 |
| 神经元 | 100×100 | 10×100×100 |
6. 卷积层的前馈运算是通过如下算法实现的:
卷积层的输出= Sigmoid( Sum(卷积) +偏移量)
类似的子采样层的输出的计算式为:
输出= Sigmoid( 采样*权重 +偏移量)
6、应用
imageNet-2010网络结构
ImageNet LSVRC是一个图片分类的比赛,其训练集包括127W+张图片,验证集有5W张图片,测试集有15W张图片。本文截取2010年Alex Krizhevsky的CNN结构进行说明,该结构在2010年取得冠军,top-5错误率为15.3%。值得一提的是,在今年的ImageNet LSVRC比赛中,取得冠军的GoogNet已经达到了top-5错误率6.67%。可见,深度学习的提升空间还很巨大。
下图即为Alex的CNN结构图。需要注意的是,该模型采用了2-GPU并行结构,即第1、2、4、5卷积层都是将模型参数分为2部分进行训练的。在这里,更进一步,并行结构分为数据并行与模型并行。数据并行是指在不同的GPU上,模型结构相同,但将训练数据进行切分,分别训练得到不同的模型,然后再将模型进行融合。而模型并行则是,将若干层的模型参数进行切分,不同的GPU上使用相同的数据进行训练,得到的结果直接连接作为下一层的输入。
上图模型的基本参数为:
DeepID网络结构
DeepID网络结构是香港中文大学的Sun Yi开发出来用来学习人脸特征的卷积神经网络。每张输入的人脸被表示为160维的向量,学习到的向量经过其他模型进行分类,在人脸验证试验上得到了97.45%的正确率,更进一步的,原作者改进了CNN,又得到了99.15%的正确率。
如下图所示,该结构与ImageNet的具体参数类似,所以只解释一下不同的部分吧。
上图中的结构,在最后只有一层全连接层,然后就是softmax层了。论文中就是以该全连接层作为图像的表示。在全连接层,以第四层卷积和第三层max-pooling的输出作为全连接层的输入,这样可以学习到局部的和全局的特征。