elastic stack 组件之Elasticsearch , beats , logstash , kibana学习笔记
目录
一 、Elastic Search 篇
(1)常见术语:
(2)Document
(3)index
(4)rest api
(5)正排索引 与 倒排索引
(6) 倒排索引组成
(7) 分词 介绍
(8)Mapping 简介
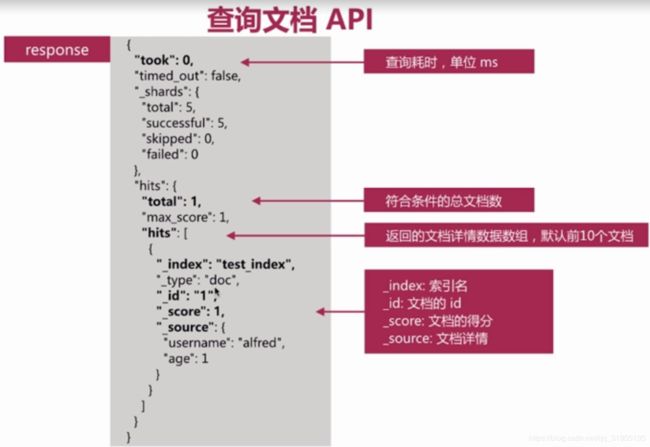
(9)es 数据搜索查询api
(10)分布式 特性
(11)search 的运行机制
(12)分页和遍历
(13)聚合分析
(14)数据建模
(15) ReIndex 重新索引
(16)生产环境部署建议
二 、 LogStash 篇
(1)logstash 介绍
(2) logstash 中的 queue
(3)logstash 的配置文件
(4) logstash 多实例5运行
(5) pipeline 配置
(6)logstash 插件
(7) logstash 实战
三 、 beats 篇
(1)filebeat
(2) metric beat
(3)packet beat
(4)Heart beat
(5)社区 beats
四 、kibana 篇
(1) 下载安装kibana ,修改 配置
(2) 启动 kibana
(3) 使用kibana 完成 elastic search 的增删改查 操作(更加全面的查询)
五 、es 搜索 实战项目
(1)创建索引
(2)在 logstash 的 config 文件夹 下编写 一个 ls.conf
(3) 执行命令
(4) 修改 url 、image 字段的format
(5)discovery
(6) 搭建搜索页面
六 、nginx 日志采集 实战
七、空气质量数据分析实战 filebeat + ingest node es
一 、Elastic Search 篇
单index,单type
未来发布的elasticsearch 6.0.0版本为保持兼容,仍然会支持单index,多type结构,但是作者已不推荐这么设置。在elasticsearch 7.0.0版本必须使用单index,单type,多type结构则会完全移除。
针对这一问题,elasticsearch 作者的讨论:
https://github.com/elastic/ela ... 24317
https://www.elastic.co/guide/e ... .html
单index,多type结构弊端
人们经常会谈到index类似传统sql数据库的“database”,而type类似于"table"。现在想想,这是一个非常糟糕的比喻,而这个比喻会造成很多错误的假设。
在传统的sql数据库中,各个"table"之间是互相独立的,在一个表中的列都与另一个表相同名称的列无关。
①,而在我们elasticsearch中同一 Index 下,同名 Field 类型必须相同,即使不同的 Type;
②, 同一 Index 下,TypeA 的 Field 会占用 TypeB 的资源(互相消耗资源),会形成一种稀疏存储的情况。尤其是 doc value ,为什么这么说呢?doc value为了性能考虑会保留一部分的磁盘空间,这意味着 TypeB 可能不需要这个字段的 doc_value 而 TypeA 需要,那么 TypeB 就被白白占用了一部分没有半点用处的资源;
③,Score 评分机制是 index-wide 的,不同的type之间评分也会造成干扰。
④,索引元数据本身是放在主节点中维护的,CP 设计。意味着涉及到大量字段变更及元数据变更的操作,都会导致该 Index 被堵塞或假死。我们应该对这样的 Index 做隔离,避免影响到其他 Index 正常的增删改查。甚至当涉及到字段变更十分频繁且无法预定义 schema 的场景时,是否要使用 ES 都应该慎思熟虑了!
(1)常见术语:
document : 用户存储在es中的数据文档 ,类比为数据库中的每一条数据记录
index :索引,由具有相同字段的文档列表组成,类比为数据库中的表
node:节点,一个es 的运行示例,是集群的构成单元
cluster : 由一个或者多个节点组成,对外提供服务
(2)Document

每个 文档都有一个唯一的id标识:自行指定或者 es 自动生成。

(3)index
索引中存储具有相同结构的文档(document)
每个索引都有自己的mapping 定义,用于定义字段名和类型
一个集群可以有多个索引,比如:
nginx 日志存储的时候可以按照日期每天生成一个索引来存储
nginx-log-2018-01-01
nginx-log-2018-01-02
nginx-log-2018-01-03
(4)rest api

常见两种交互方式
方式一:curl 命令行
curl -XPUT "http://localhost:9200/employee/doc/1" -i -H "Content-Type: application/json" -d
{
"username":"dzx",
"job":"software engineer"
}
方式二:kibana DevTools
创建索引:

删除索引:

创建文档:

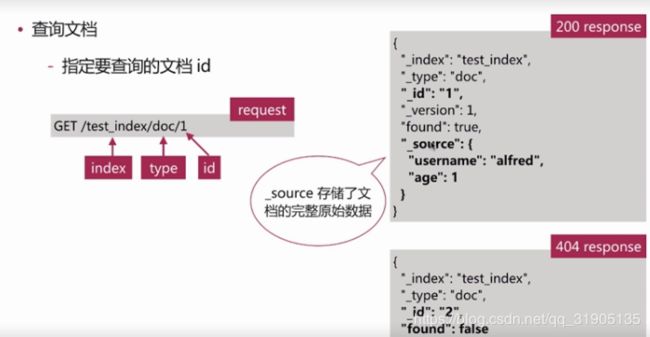


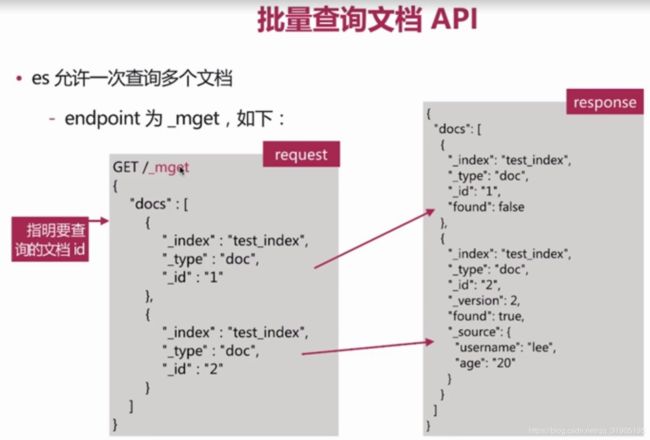
(5)正排索引 与 倒排索引
正排索引 : 文档id到文档内容,单词的关联关系
倒排索引 : 单词到文档id 的关联关系
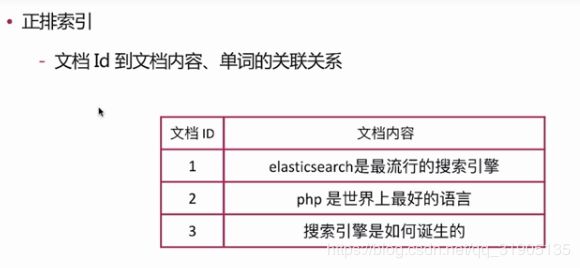
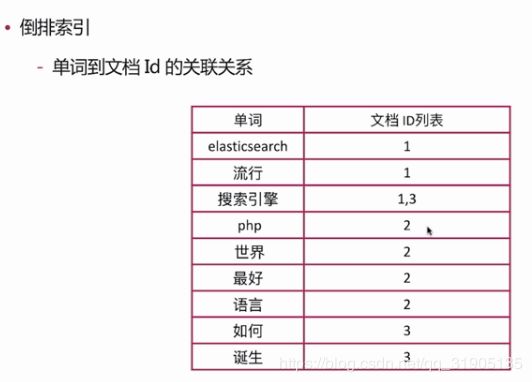
查询包含 “搜索引擎”的文档
通过倒排索引获得“搜索引擎”对应的ID 有 1 和 3 ,然后通过正排索引查询 1和 3 的完整内容 ,最终返回用户完整文档。
(6) 倒排索引组成
倒排索引是搜索引擎的核心,主要包含两个部分
单词 词典 (term dictionary):
记录 所有文档的单词,一般都比较大,记录单词到倒排列表的关联信息。
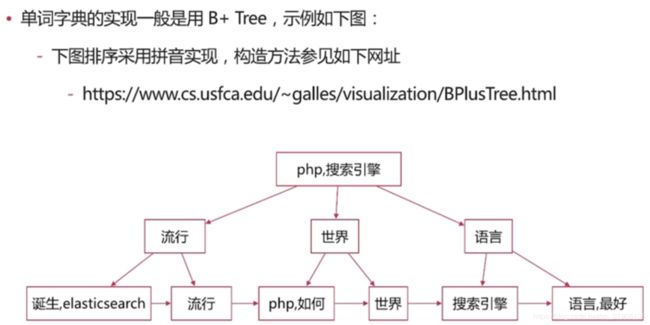
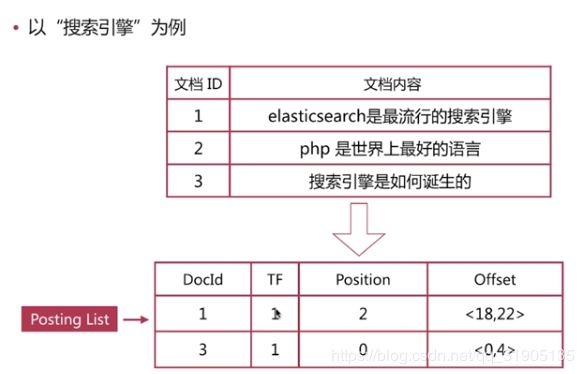
倒排 列表 (posting list):

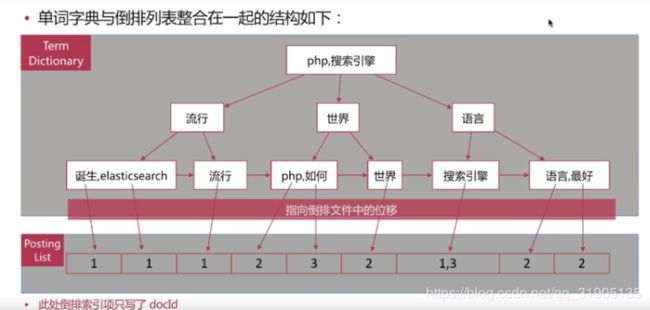

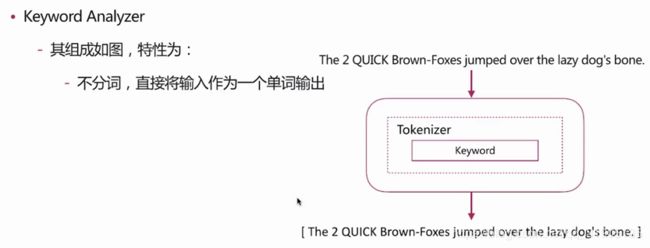
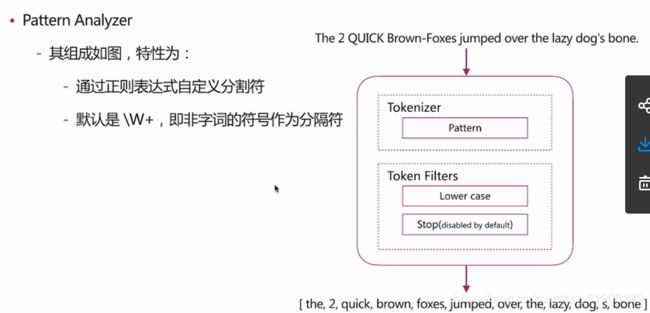
(7) 分词 介绍
分词 是指将文本转换为一系列单词(term or token)的过程,也可以叫做文本分析,在es 里面称为 analysis,如下图所示:

分词器 是 es 中 专门处理分词 的组件,英文为analyzer,它的组成如下 :


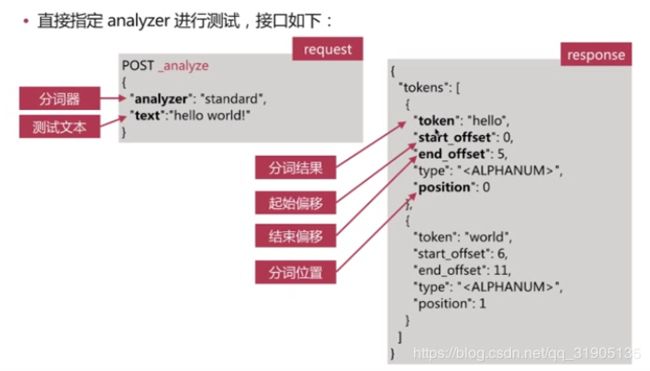
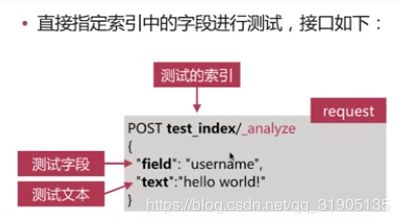

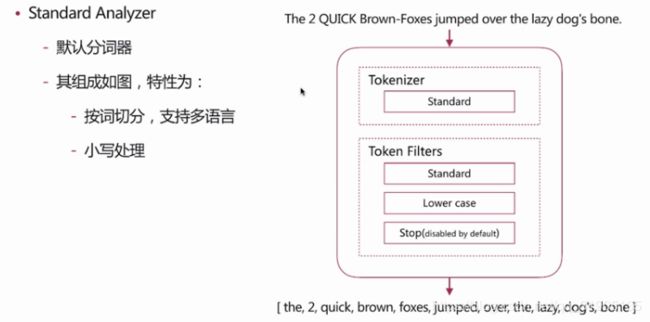
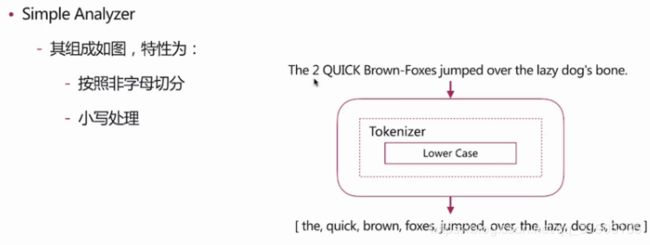
es 自带如下的分词器 :
standard
simple
whitespace

stop

keyword
pattern
language

中文分词
难点 ::中文分词指的是将一个汉字序列切分成一个一个单词的词,在英文中,单词之间之间是以空格作为自然分界符,汉语中词没有一个形式上的分界符。
上下文不同,分词结果迥异,比如交叉歧义问题,比如下面两种分词都合理
乒乓球拍/卖/完了
乒乓球/拍卖/完了
https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247486148&idx=1&sn=817027a204650763c1bea3e837d695ea&source=41#wechat_redirect


自定义分词 :




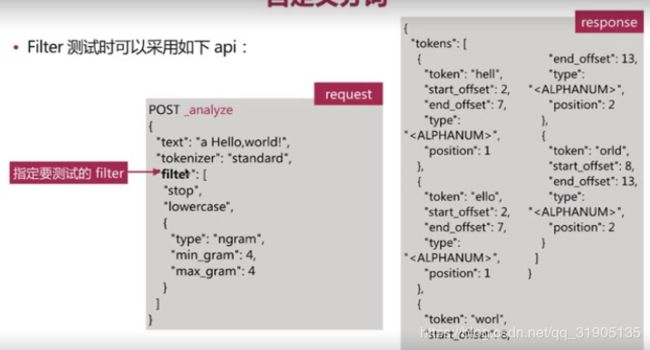
分词 使用说明 :
分词会在 两个 时机使用 ,创建或者更新文档时,会对相应的文档进行 分词 处理
查询时,会对查询 语句进行分词 。
一般不需要特别指定查询时 分词器,直接使用索引时分词器即可,否则会出现无法匹配的情况。
分词使用建议:
明确字段是否需要分词,不需要分词的字段就将type 设置为 keywork,可以节省空间和提高写性能。
善用 _analyze API ,查看文档的具体分词结果 ,
动手测试。
(8)Mapping 简介









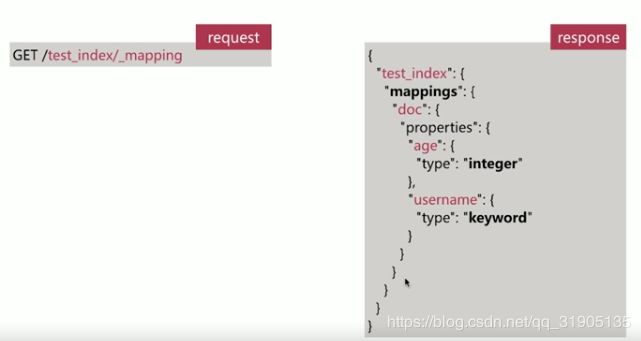

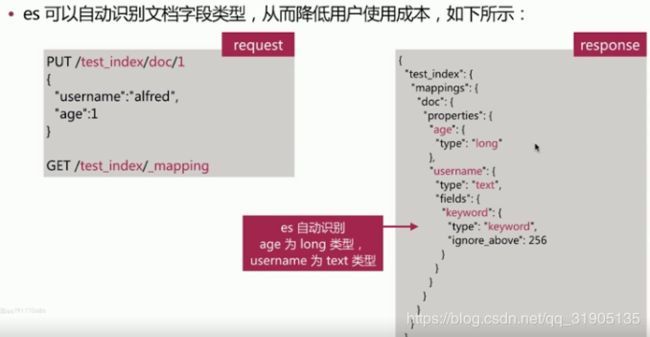
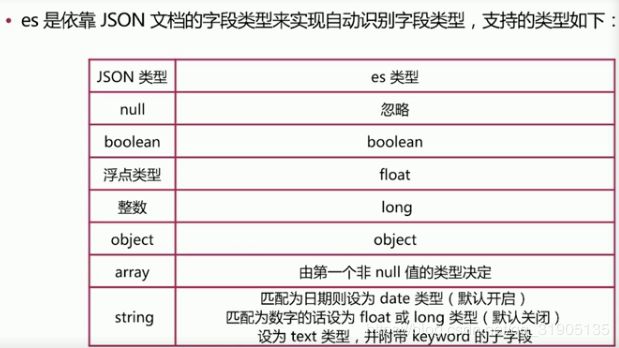
Dynamic Mapping



Dynamic template



(9)es 数据搜索查询api
实现存储的数据进查询分析,endpoint为_search,如下所示:
#search api
GET /_search
GET /my_index/_search
GET /my_index1,my_inedx2/_search
GET /my_*/_search #可以使用通配符一次查询多个
GET /_search #使用"profile":true 可以返回 es 查询的过程语句等信息
{
"profile":true
}



如果不加 括号,查询时 status 包含active 或者 所有字段包含 penging 的 文档,加上括号之后就时 查询
status 包含 active 或者pending 的文档 。





Query DSL
基于json定义的查询语言,主要包含两种类型:
字段类查询 :如 term, match, range 等,只针对某一个字段进行查询
复合查询: 如bool 查询等,包含一个或者 多个字段类 查询 或者复合 查询语句


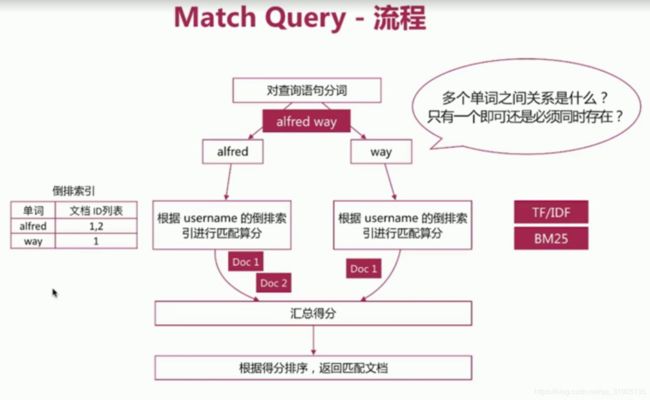
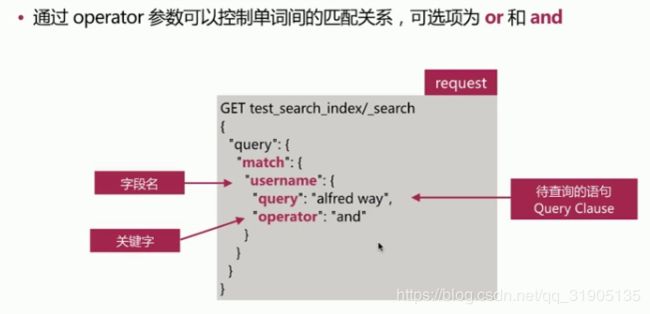
#查询name 中 有张或者三的
GET /my_index/doc/_search
{
"query":{
"match":{
"name":{
"query":"张 三"
}
}
}
}
#查询 name 中 有张并且有三的
GET /my_index/doc/_search
{
"query":{
"match":{
"name":{
"query":"张 三",
"operator": "and",
}
}
}
}
# 查询 name 中至少匹配两个词的
GET /my_index/doc/_search
{
"query":{
"match":{
"name":{
"query":"张 三",
"minimum_should_match": 2
}
}
}
}相关性 算分

es 目前主要 有两个相关性算分模型,TF/IDF 模型 和 (5.x之后的默认模型)BM25模型


BM25相比 TF/IDF 的一大优化是 降低 了 tf 在 过大时的权重。
math_phrase 查询
PUT /my_index/doc/2
{
"name":"java jkl engineer",
"age":17,
"birthday":"2018/09/10 20:50:30"
}
GET /my_index/doc/_search
{
"query":{
"match_phrase":{
"name":{
"query":"java engineer",
"slop": 1 #查询 name 中 java engineer 可以存在一个单词间隔 文档
}
}
}
}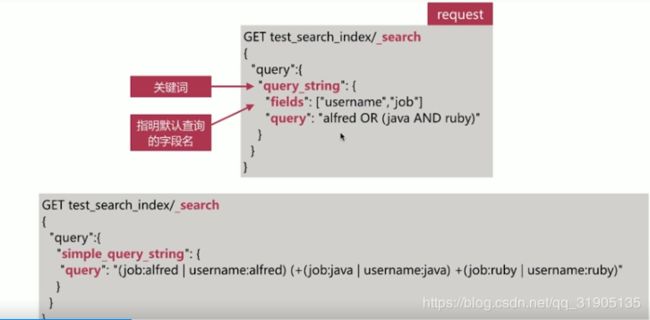

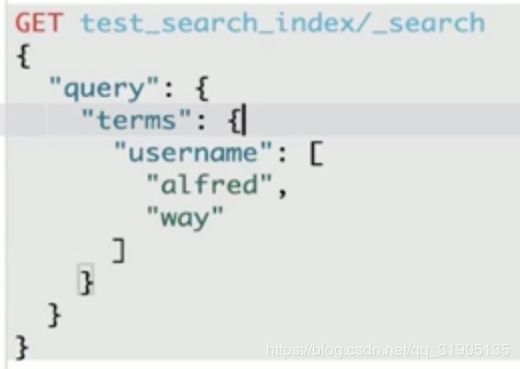
term query / terms query

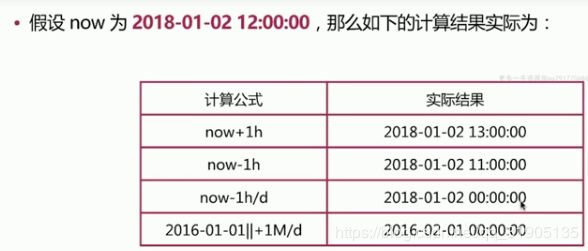
range query



constant_score

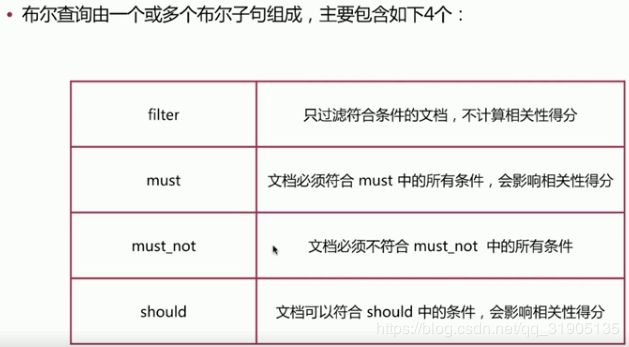
bool query





Count api
获取 符合 条件的文档数 ,endpoint 为 _count
查询 语句
GET /my_index/_count
{
"query":{
"match": {
"name": "java"
}
}
}查询结果
{
"count": 2,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
}
}Source Filtering 只返回 指定的 字段

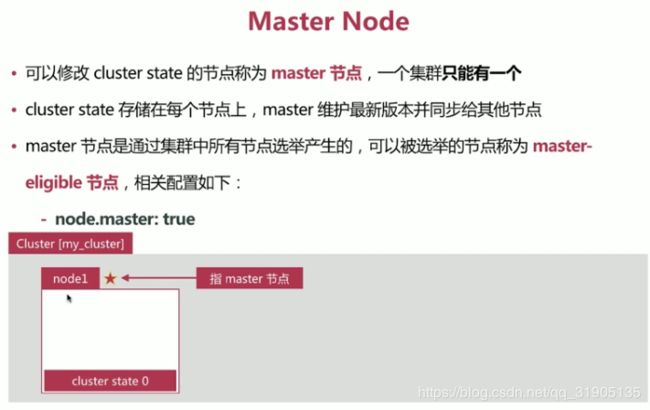
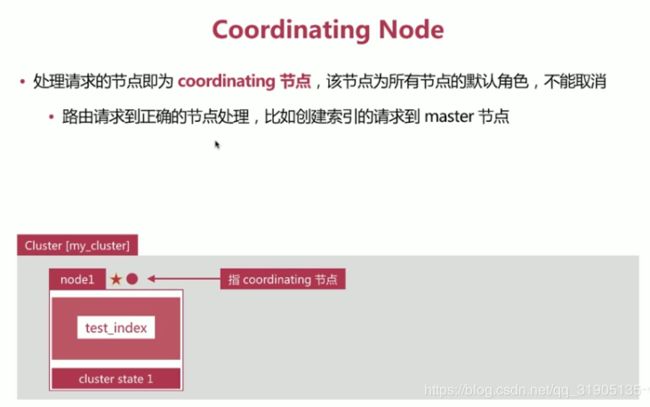
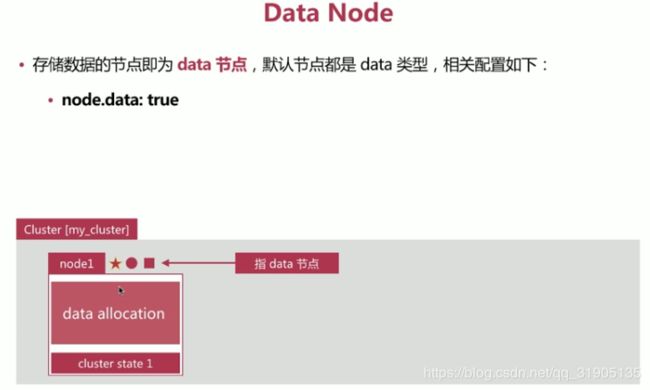
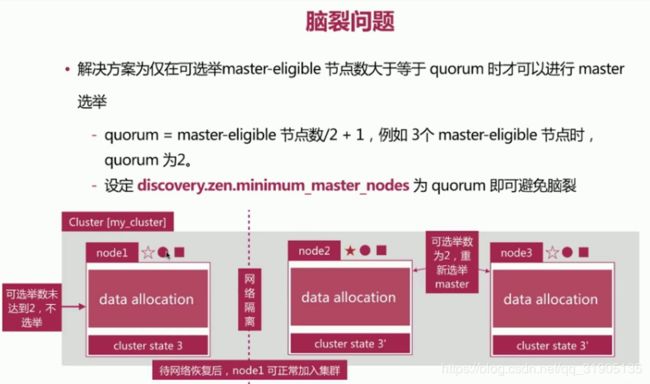
(10)分布式 特性
es 支持 集群模式,是 一个分布式系统,其好处主要有两个:
- 增大系统容量,如内存,磁盘,使得es集群可以支持PB级别的数据
- 提高系统可用性,即使部分节点停止 服务,整个集群依然 可以正常服务
es 集群 由多个es 实例 组成
- 不同集群通过集群名字来区分,可以通过cluster.name 进行修改 ,默认elasticsearch
- 每个es 实例 本质上是一个jvm 进程,且有自己的名字,通过node.name 进行修改
cerebro 的安装及启动
下载 地址 :https://github.com/lmenezes/cerebro/releases
上传至linux ,解压后 修改 conf/application.conf
# A list of known hosts
hosts = [
#{
# host = "http://localhost:9200"
# name = "Some Cluster"
#},
# Example of host with authentication
#{
# host = "http://some-authenticated-host:9200"
# name = "Secured Cluster"
# auth = {
# username = "username"
# password = "secret-password"
# }
#}
{
host = "http://192.168.42.85:9200"
name = "es-cluster"
}
]启动命令
./bin/cerebro
在 浏览器 输入 192.168.42.85:9000 即可看到 es 集群 管理 web 界面 。

提高系统可用性
- 服务 可用性:2个节点 的情况下,允许其中1个节点 停止服务
- 数据可用性 : 引入 副本(Replication)解决,每个节点上都有完备的数据
增大 系统容量




分片数的设定很重要,需要提前规划好
过小会导致后续无法通过增加节点实现水平扩容
过大会导致一个节点上分布过多分片,造成资源浪费,同时会影响查询性能。
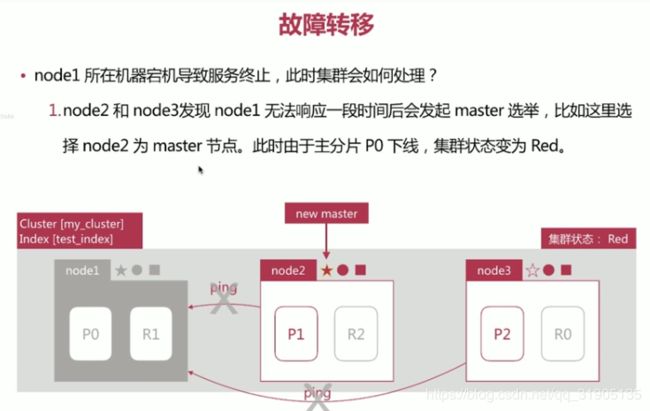
集群健康状况
通过 GET _cluster/health 可以查看集群健康状况,包括以下三种:
集群的故障转移 :
- green 健康状态,指所有主副分片都正常分配
- yellow 指所有主分片都正常分配,但是有副本 分片未正常分配
- red 有主分片未分配


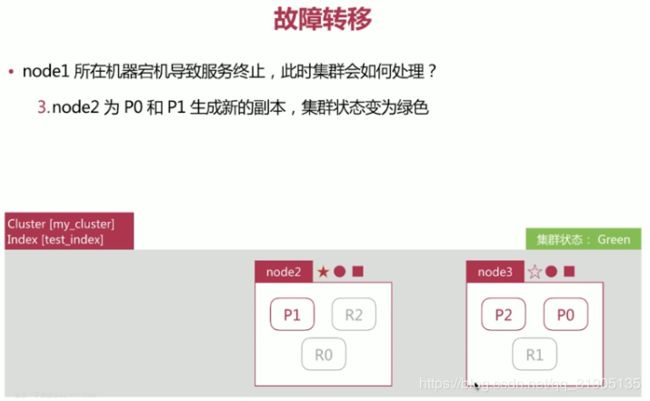
(11)search 的运行机制
search 执行的时候 实际分两个 步骤运作的
- query 阶段
- fetch 阶段
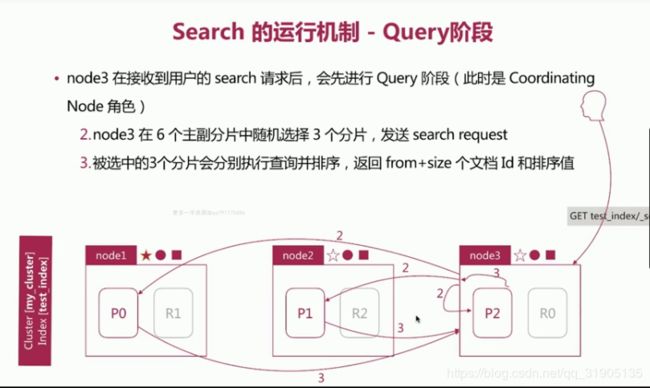
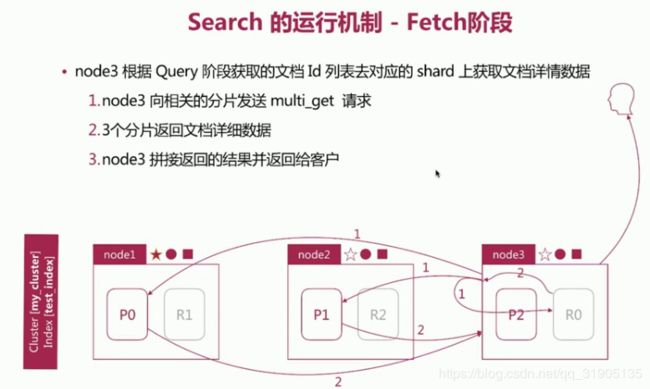
相关性算分 问题
相关性算分在 shard 与 shard 间 是相互独立的,就意味 着同一个 term 的IDF 等值在不同的shard 上是不同的。
文档的相关性算分和它所处的shard 相关
在文档数量不多时,会导致相关性算分严重不准的情况发生。
(12)分页和遍历
from / size
from 指明开始位置
size 指明获取总数
GET /my_index/doc/_search
{
"from": 0,
"size": 2
}
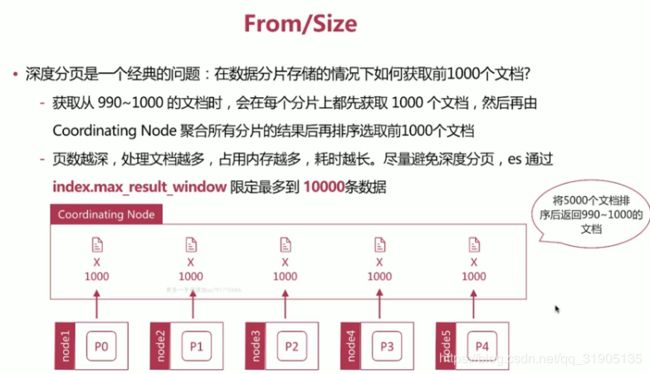
(13)聚合分析


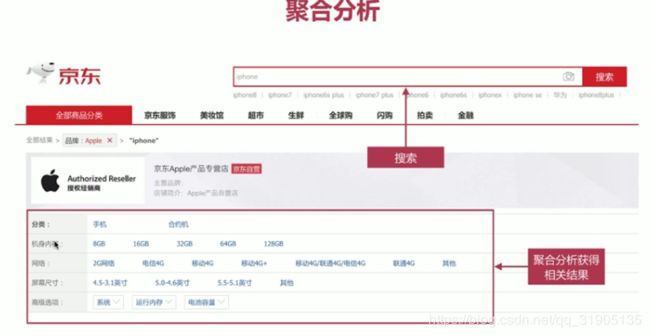


更多聚合分析 参考 官方文档 :https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html
(14)数据建模
- 概念模型 : 确定系统的核心需求和范围边界,设计实体和实体间的关系
- 逻辑模型 : 进一步梳理需求,确定每个实体的属性,关系,和约束等
- 物理模型: 结合 具体的数据库产品,在满足业务 读写性能等需求的前提下 确定最终的的定义,mysql mongoDB,elasticsearch 等,第三范式。
Mapping 字段 属性 设定流程
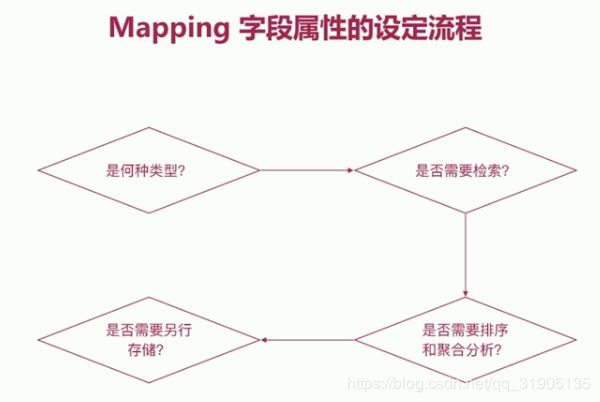




es 建模 示例
首先 对 没有 内容的 博客 建模
| 标题 | title |
| 发布日期 | publish_date |
| 作者 | author |
| 摘要 | abstract |
| 网络地址 | url |
#blog_index 数据建模
PUT blog_index
{
"mappings": {
"doc":{
"properties":{
"title":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword"
}
}
},
"publish_date":{
"type":"date"
},
"author":{
"type":"keyword"
},
"abstract":{
"type":"text"
},
"url":{
"enabled":false
}
}
}
}
}如果 博客 中 多了 一个 content 字段,而且 content 的 内容特别长,就会导致性能差
| 标题 | title |
| 发布日期 | publish_date |
| 作者 | author |
| 摘要 | abstract |
| 内容 | content |
| 网络地址 | url |
#blog_index1 数据建模
PUT blog_index1
{
"mappings": {
"doc":{
"_source":{
"enabled":false
},
"properties":{
"title":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword"
}
},
"store":true
},
"publish_date":{
"type":"date",
"store":true
},
"author":{
"type":"keyword",
"store":true
},
"abstract":{
"type":"text",
"store":true
},
"content":{
"type":"text",
"store":true
},
"url":{
"type":"keyword",
"doc_values":false,
"norms":false,
"ignore_above":100,
"store":true
}
}
}
}
}关联关系处理
es 不擅长处理关系型数据库中的关联关系,比如文章表blog 和 评论表comment之间通过blog_id 关联,在es
中可以通过如下两种手段变相解决
- Nested Object
- Parent/Child

(15) ReIndex 重新索引
重建所有的数据的过程,一般发生如下情况:
- mapping 设置变更,比如字段类型变化,分词器字典更新等
- index 设置变更,比如分片数更改等
- 迁移数据
es 提供了现成的api 用于完成该工作
- _update_by_query 在 现有的索引上重建
- _reindex 在 其他索引上重建


防止字段过多

防止字段过多
一般字段过多的原因是由于没有高质量的数据建模导致的。比如dynamic设置为true
考虑拆分多个索引来解决问题
(16)生产环境部署建议

动态的调用api 修改 es 配置

关于jvm 的内存设定
不要超过31G ,预留一半内存给操作系统,用来做文件缓存。

es 写性能 优化
目标是增大写吞吐量-EPS(Events Per Second)越高越好
优化方案:
- 客户端 : 多线程写,批量些
- es:在 高质量数据建模的前提下,主要在refresh 、translog 、 flush之间做文章。
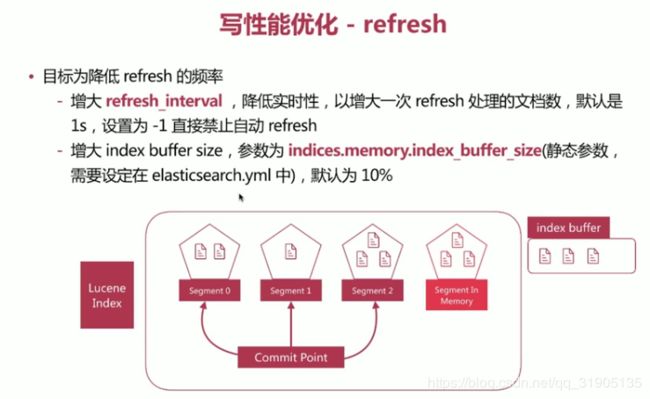
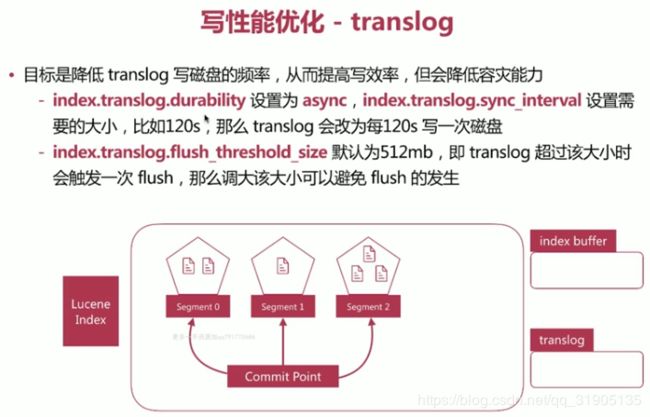



如何设定 shard 数 ?


es 官方集群监控功能x-pack
es6.4.2 或者 kibana6.4.2默认已经安装了x-pack,低版本的可能默认没有安装 x-pack,可以通过执行命令./bin/elasticsearch-plugin install x-pack 和 ./bin/kibana-plugin install x-pack 安装 。

二 、 LogStash 篇
(1)logstash 介绍
- 数据收集处理引擎
- ETL 工具
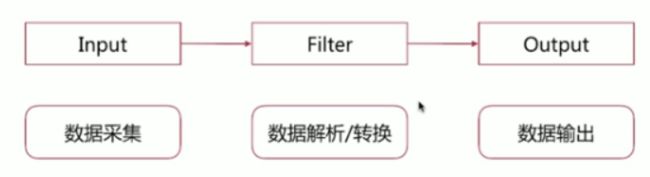
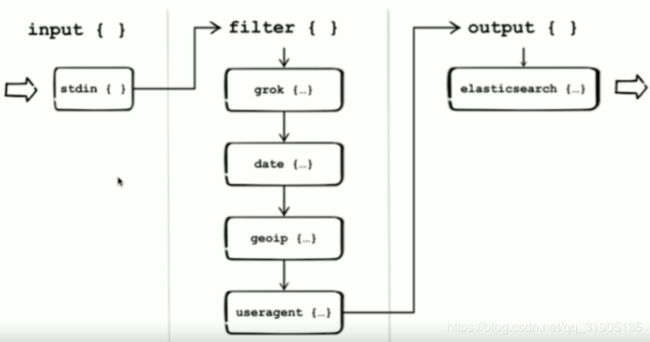
Pipeline
- input-filter-output的3阶段处理流程
- 队列管理
- 插件生命周期管理
Logstash Event
- 内部流转的数据表现形式
- 原始数据input 被 decode 转换为event ,在output event 被encode转换为目标格式
- 在配置文件中可以对event中的属性进行增删改查
编写一个配置文件 logstash-test.conf
input {
stdin{
codec => line
}
}
output {
stdout {
codec => json
}
}echo "foo
bar
"| ./bin/logstash -f logstash-test.conf

(2)logstash 中的 queue


性能 相差不多,所以建议 queue.type设置为persisted
更多队列 配置 参考 :https://www.elastic.co/guide/en/logstash/current/persistent-queues.html

(3)logstash 的配置文件

logstash.yml常用配置



(4)logstash 多实例5运行

(5)pipeline 配置

pipeline 配置语法
主要有如下的数值类型:
- 布尔类型boolean , 如 : isFailed => true
- 数值类型 Number ,如: port => 33
- 字符串类型 String, 如: name => "Hello world"
- 数组类型 Array/list , 如 :users => [{id = >1, name = >bob},{id = > 2, name => jane}] 或者 path = ["/var/log/messages","/var/log/*.log"]
- 哈希类型Hash ,如 :
match = >{
"field1" = > "value1"
"field2" = > "value2"
}
# 号 代表 注释



pipeline 还支持条件判断语法,从而扩展了配置多样性,主要格式:
if EXPRESSION {
...
}else if EXPRESSION {
...
}else{
...
}
示例 :

(6)logstash 插件
- input plugin 插件指定数据输入源,一个pipeline 可以有多个插件,如 : stdin 、file、kafka
| codec | 类型为codec |
| type | 类型为string,自定义该事件的类型,可以用于后续判断 |
| tags | 类型为array,自定义该事件的tag,可用于后续判断 |
| add_field | 类型为hash,为该事件添加字段 |
示例 :编辑一个 test.conf
input{
stdin {
codec => "plain"
tags => ["test"]
type => "std"
add_field => {"key"=>"value"}
}
}
output{
stdout{
codec =>"rubydebug"
}
}./bin/logstash -f ./conf/test.conf 启动 logstash ,并输入 ok,看到返回信息:
{
"host" => "localhost.localdomain",
"@timestamp" => 2018-11-13T01:45:51.355Z,
"tags" => [
[0] "test"
],
"message" => "ok",
"type" => "std",
"@version" => "1",
"key" => "value"
}- input plgin - file






示例:
input{
file {
path => ["/var/log/access_log","/var/log/err_log"],
type =>"web",
start_position =>"beginning"
}
}start_position 设置为 beginning ,只有首次读取log文件的时候生效,之后如果sincedb 有该文件就不再从 头开始读取文件。
调试 文件输入时的常用的配置 : 增加sincedb_path =>"/dev/null" 之后 就不会保存 sincedb 文件,每次都会从头开始读取文件。
input{
file {
path => "/var/log/*.log",
sincedb_path => "/dev/null",
type =>"web",
start_position =>"beginning",
ignore_older=>0,
close_older=>5,
discover_interval=>1
}
}
output{
stdout{codec=>rubydebug{}}
}- input plugin - kafka

- codec plugin






- filter plugin

- filter plugin date 将日期字符串解析为日期类型,然后替换@timestamp 字段或者指定的其他字段

- filter plugin - grok 简化了使用 正则表达式解析的复杂度





- filter plugin -dissect

- filter plugin -mutate

- filter plugin json

- filter plugin - geoip

- filet plugin ruby

- output plugin




(7)logstash 实战
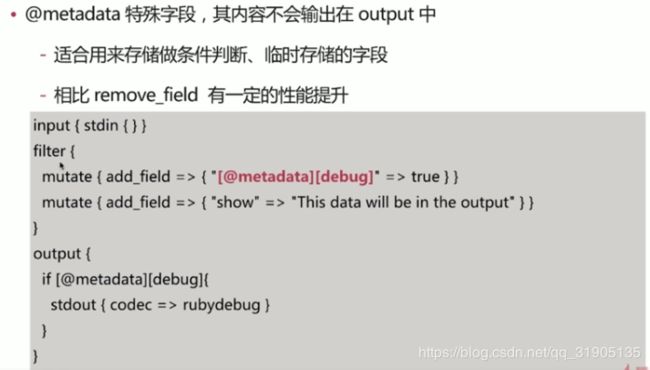
调试的配置建议 :
http 做input ,方便输入测试数据,并且可以结合reload 特性(stdin无法reload)
stdout 做 output ,codec 使用 rubydebug ,即时查看解析结果
测试错误输入情况下的输出,以便对错误情况进行处理
input{
http{
port => 7474
}
}
filter{}
output{
stdout{
codec => rubydebug
}
}
- 实战示例一:解析 如下 所示的 apache log
192.168.42.130 - - [06/Nov/2018:10:49:12 +0800] "GET /devallinone/js/split.js HTTP/1.1" 200 11427
192.168.42.130 - - [06/Nov/2018:10:49:12 +0800] "GET /devallinone/js/dev.allinone.js HTTP/1.1" 200 17032
192.168.42.130 - - [06/Nov/2018:10:49:13 +0800] "GET /devallinone/config/app.xml HTTP/1.1" 200 26478
192.168.42.130 - - [06/Nov/2018:10:49:13 +0800] "GET /devallinone/css/fontSize.14.css HTTP/1.1" 200 1020
192.168.42.130 - - [06/Nov/2018:10:49:13 +0800] "GET /devallinone/image/logo.png HTTP/1.1" 200 9286
编写 apache-log.conf
input{
#http{
# port => 7474
#}
file{
path => "access.20161111.log"
#path => "access.1w.log"
sincedb_path => "/dev/null"
start_position => "beginning"
}
}
filter{
#mutate{add_field => {"[@metadata][debug]"=>true}}
if [@metadata][debug] {
mutate{ remove_field => ["headers"] }
}
grok{
match => {
"message" => '%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:[@metadata][timestamp]}\] "%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}" %{NOTSPACE:response_status_code} (?:%{NUMBER:bytes}|-) %{QS:hostname} %{QS:referrer} (?:-|%{DATA:params}) %{QS:agent} %{QS:xforwardedfor} (?:-|%{MY_URI:upstream_host}) (?:-|%{MY_RESP:upstream_response_status_code}) (?:-|%{MY_RESP_TIME:upstream_response_time}) %{BASE10NUM:response_time:float}'
}
pattern_definitions=>{
"MY_URI" => '%{URIHOST}(, %{URIHOST})*'
"MY_RESP" => '%{NUMBER}(, %{NUMBER})*'
"MY_RESP_TIME" => '%{BASE10NUM}(, %{BASE10NUM})*'
}
}
date{
match => ["[@metadata][timestamp]","dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate{
split => {"upstream_host" => ", "}
split => {"upstream_response_status_code" => ", "}
split => {"upstream_response_time" => ", "}
gsub => ["hostname",'"','']
}
mutate{
convert => {"upstream_response_time"=>"float"}
}
geoip{
source => "clientip"
}
useragent{
source => "agent"
target => "useragent"
}
mutate{
add_field => {
"[@metadata][index]" => "nginx_logs_%{+YYYY.MM.dd}"
}
}
if [referrer] =~ /^"http/ {
grok{
match => {
"referrer" => '%{URIPROTO}://%{URIHOST:referrer_host}'
}
}
#if "www.imooc.com" in [referrer] {
#if [referrer] =~ /^"http://www.imooc.com/ {
if "imooc.com" in [referrer_host] {
grok{
match => {
"referrer" => ['%{URIPROTO}://%{URIHOST}/(%{NOTSPACE:imooc_type}/%{NOTSPACE:imooc_res_id})?"','%{URIPROTO}://%{URIHOST}/(%{NOTSPACE:imooc_type})?"']
}
}
}
}
mutate{
gsub => ["referrer",'"','']
}
if "_grokparsefailure" in [tags] {
mutate{
replace => {
"[@metadata][index]" => "nginx_logs_parsefailure_%{+YYYY.MM.dd}"
}
}
}else{
mutate{remove_field=>["message"]}
}
}
output{
if [@metadata][debug]{
stdout{
#codec=>json_lines
codec => rubydebug{
metadata => true
}
}
}else{
stdout{codec=>dots}
elasticsearch{
index => "%{[@metadata][index]}"
}
}
}
- 实战 示例 二:将 csv 文件中的数据 导入到 es 中

编写 logstash 的 csv.conf 配置文件
input{
file{
path =>"/opt/elk/user.csv"
start_position =>"beginning"
sincedb_path => "/dev/null"
}
}
filter{
csv{
columns => ["id","age","name"]
#convert=>{"accommodates"=>"integer"}
#convert=>{"bathrooms"=>"float"}
}
date{
match =>["date_from","yyyyMMdd"]
}
date{
match =>["date_to","yyyyMMdd"]
}
}
output{
elasticsearch{
hosts =>["192.168.42.85:9200"]
index =>"csv_test"
}
}
执行 ./bin/logstash -f ./config/csv.conf , user.csv中的 数据 自动会导入到es 的 csv_test 索引中 。

三 、 beats 篇
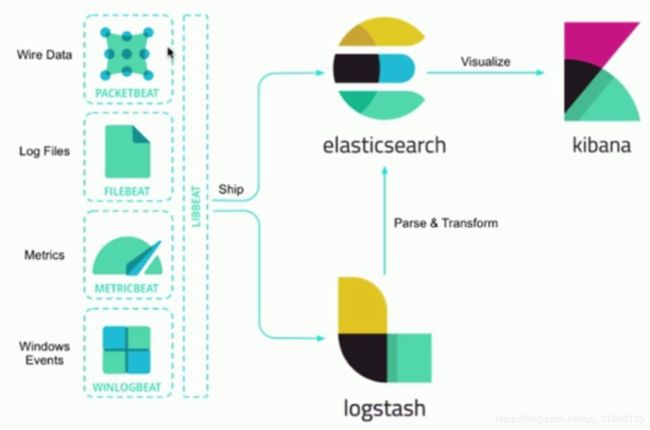
(1)filebeat

读取日志文件,但不做数据的解析处理
保证数据 至少被读取一次,数据不丢失
其他能力 : 处理多行数据,解析json格式数据,简单的过滤功能
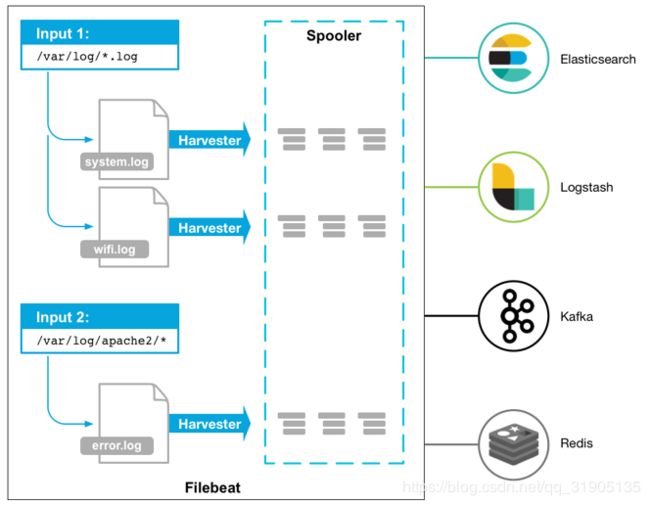
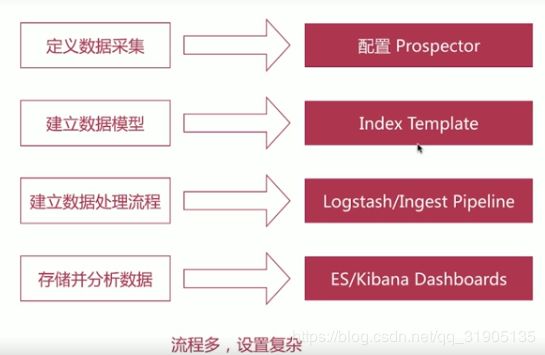
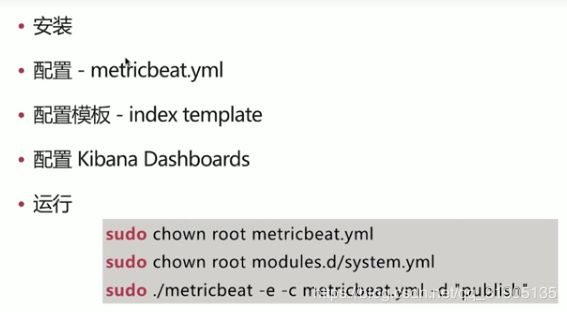
filebeat 使用流程
- 安装 开箱即用
- 配置filebeat.yml
- 配置模版 index template
- 配置 kibana dashboards
- 运行
filebeat.yml 配置文件



./filebeat setup --template -E 'output.elasticsearch.hosts=["localhost:9200"]'
建议大家通过es api 的方式创建 template
filebeat 集成 kibana dashboard ,可用于快速展示数据
结合 Modules 使用 ,一次性全部导入 ,./filebeat setup --dashboard
- elasticsearch ingest node 当我们不需要 logstash 的时候,可以利用 ingest node 节点 达到同样的数据解析,处理效果

5.x 新增的一个节点类型
在 数据写入es 前 (bulk/index 操作)对数据斤进行处理
可设置 独立的ingest node 专门进行数据转换处理 , node.ingest: true
api endpoint 为pipeline

pipeline api 中的 processor 对应的logstash 的filter plugin ,基本都涵盖了 Convert 、 grok 、Date 、gsub、join
json、remove、script。

日志处理 中常用 的 两个es 插件
bin/elasticsearch-plugin install ingest-geoip
bin/elasticsearch-plugin install ingest-user-agent


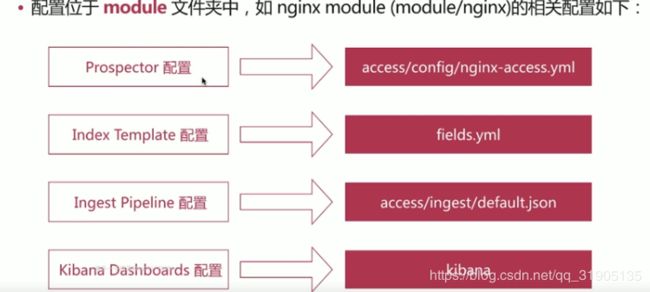
- filebeat module
file beat 提供了众多开箱即用的module
./filebeat moudles list
./filebeat moudles enable nginx
(2)metric beat
定期收集 操作系统,软件或服务的指标数据,存储在es 中进行实时的分析



更多moudle 参考 官方文档:https://www.elastic.co/guide/en/beats/metricbeat/current/metricbeat-modules.html
(3)packet beat




packet beat 实战

(4)Heart beat

(5)社区 beats
参考 https://www.elastic.co/guide/en/beats/libbeat/current/community-beats.html
四 、kibana 篇
Kibana是一个开源的分析和可视化平台,设计用于elastic search搜索。您使用KiBaba搜索、查看和与 elastic search搜索索引中存储的数据交互。您可以在各种图表、表格和地图中轻松地执行高级数据分析和可视化数据。Kibana使人们容易理解大量的数据。其简单的、基于浏览器的接口使您可以快速创建和共享动态仪表板,这些仪表板实时显示对Elasticsearch查询的更改。 您可以安装Kibana,并在几分钟内开始探索Elasticsearch索引,无需代码,也不需要额外的基础设施。
(1) 下载安装kibana ,修改 配置
vim /usr/local/kibana-5.3.1-linux-x86_64/config/kibana.yml
需要修改以下地方
# Kibana is served by a back end server. This setting specifies the port to use.
server.port: 5601 #默认端口号为5601
# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
server.host: "192.168.42.85" # 修改为本机ip
# Enables you to specify a path to mount Kibana at if you are running behind a proxy. This only affects
# the URLs generated by Kibana, your proxy is expected to remove the basePath value before forwarding requests
# to Kibana. This setting cannot end in a slash.
#server.basePath: ""
# The maximum payload size in bytes for incoming server requests.
#server.maxPayloadBytes: 1048576
# The Kibana server's name. This is used for display purposes.
#server.name: "your-hostname"
# The URL of the Elasticsearch instance to use for all your queries.
elasticsearch.url: "http://192.168.42.85:9200" #指向elastic search服务地址
# When this setting's value is true Kibana uses the hostname specified in the server.host
# setting. When the value of this setting is false, Kibana uses the hostname of the host
# that connects to this Kibana instance.
#elasticsearch.preserveHost: true
# Kibana uses an index in Elasticsearch to store saved searches, visualizations and
# dashboards. Kibana creates a new index if the index doesn't already exist.
kibana.index: ".kibana" #默认index
# The default application to load.
#kibana.defaultAppId: "discover"
# If your Elasticsearch is protected with basic authentication, these settings provide
# the username and password that the Kibana server uses to perform maintenance on the Kibana
# index at startup. Your Kibana users still need to authenticate with Elasticsearch, which
# is proxied through the Kibana server.
#elasticsearch.username: "user"
#elasticsearch.password: "pass"
# Enables SSL and paths to the PEM-format SSL certificate and SSL key files, respectively.
# These settings enable SSL for outgoing requests from the Kibana server to the browser.
#server.ssl.enabled: false
#server.ssl.certificate: /path/to/your/server.crt
#server.ssl.key: /path/to/your/server.key
# Optional settings that provide the paths to the PEM-format SSL certificate and key files.
# These files validate that your Elasticsearch backend uses the same key files.
#elasticsearch.ssl.certificate: /path/to/your/client.crt
#elasticsearch.ssl.key: /path/to/your/client.key
# Optional setting that enables you to specify a path to the PEM file for the certificate
# authority for your Elasticsearch instance.
#elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ]
# To disregard the validity of SSL certificates, change this setting's value to 'none'.
#elasticsearch.ssl.verificationMode: full
# Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of
# the elasticsearch.requestTimeout setting.
#elasticsearch.pingTimeout: 1500
# Time in milliseconds to wait for responses from the back end or Elasticsearch. This value
# must be a positive integer.
#elasticsearch.requestTimeout: 30000
# List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side
(2)启动 kibana
cd /usr/local/kibana-5.3.1-linux-x86_64/bin
./kibana
在浏览器中输入 192.168.42.85:5601 ,显示如下界面说明启动 成功。

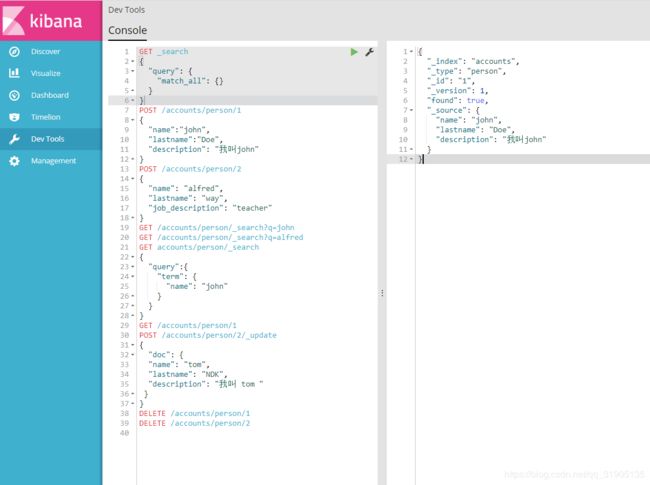
(3)使用kibana 完成 elastic search 的增删改查 操作(更加全面的查询)
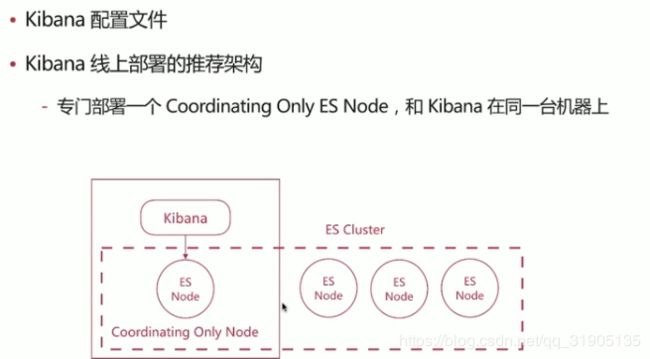
kibana 线上部署的推荐架构
更多kibana 指南 参考 官方文档 :https://www.elastic.co/guide/en/kibana/current/index.html
五 、es 搜索 实战项目
利用 logstash 的 csv filter 将 csv 文件房屋数据,导入到es 中
| accommodates | bathrooms | bed_type | bedrooms | beds | date_from | date_o | date_rom | date_to | has_availability | host_image | host_name | image | listing_url | location | name | price | property_type | room_type | |
| 3 | 1 | Real Bed | 1 | 1 | 20170417 | 20170519 | TRUE | https://a2.muscache.com/ac/users/1849458/profile_pic/1434517551/original.jpg?interpolation=lanczos-none&crop=w:w;*,*&crop=h:h;*,*&resize=50:*&output-format=jpg&output-quality=70 | Dawn Marie | https://a2.muscache.com/im/pictures/89646919/d751f179_original.jpg?aki_policy=medium | https://www.airbnb.com/rooms/366301 | Paint by Number Paradise | 153 | Apartment | Entire home/apt | ||||
| 2 | 1.5 | Real Bed | 1 | 1 | 20170426 | 20170421 | TRUE | https://a1.muscache.com/ac/users/3686989/profile_pic/1433207682/original.jpg?interpolation=lanczos-none&crop=w:w;*,*&crop=h:h;*,*&resize=50:*&output-format=jpg&output-quality=70 | Alyson | https://a1.muscache.com/im/pictures/83758454/c4d97c57_original.jpg?aki_policy=medium | https://www.airbnb.com/rooms/6644628 | Convenient N. Beacon Hill Townhome | 124 | Townhouse | Private room | ||||
| 5 | 2.5 | Real Bed | 2 | 2 | 20170408 | 20170428 | TRUE | https://a0.muscache.com/ac/users/18104211/profile_pic/1405380363/original.jpg?interpolation=lanczos-none&crop=w:w;*,*&crop=h:h;*,*&resize=50:*&output-format=jpg&output-quality=70 | Tony | https://a0.muscache.com/im/pictures/56211752/eb82b540_original.jpg?aki_policy=medium | https://www.airbnb.com/rooms/3593582 | 2 BR 2.25 Bath Townhome | 124 | House | Entire home/apt | ||||
| 2 | 0.5 | Airbed | 1 | 1 | 20170508 | 20170418 | TRUE | https://a0.muscache.com/ac/users/301107/profile_pic/1433688394/original.jpg?interpolation=lanczos-none&crop=w:w;*,*&crop=h:h;*,*&resize=50:*&output-format=jpg&output-quality=70 | Perry | https://a2.muscache.com/im/pictures/84797325/4ad8f6d0_original.jpg?aki_policy=medium | https://www.airbnb.com/rooms/6716620 | Sven's Urban Seattle Tent #Glamping | 188 | Tent | Entire home/apt | ||||
| 1 | 1 | Real Bed | 1 | 1 | 20170404 | 20170405 | TRUE | https://a2.muscache.com/ac/users/1466280/profile_pic/1340050269/original.jpg?interpolation=lanczos-none&crop=w:w;*,*&crop=h:h;*,*&resize=50:*&output-format=jpg&output-quality=70 | Ane | https://a2.muscache.com/im/pictures/4bb5ff1a-70c7-40d3-8800-129937e26d31.jpg?aki_policy=medium | https://www.airbnb.com/rooms/6796066 | Make a home amongst the succulents | 182 | House | Private room | ||||
| 1 | 1 | Airbed | 1 | 1 | 20170421 | 20170418 | TRUE | https://a0.muscache.com/ac/users/18422078/profile_pic/1432299910/original.jpg?interpolation=lanczos-none&crop=w:w;*,*&crop=h:h;*,*&resize=50:*&output-format=jpg&output-quality=70 | Carol | https://a0.muscache.com/im/pictures/94342097/4e6a93b7_original.jpg?aki_policy=medium | https://www.airbnb.com/rooms/3977450 | N Beacon Hill Zen Room w/ Parking | 24 | House | Private room | ||||
| 2 | 1 | Real Bed | 1 | 1 | 20170404 | 20170525 | TRUE | https://a0.muscache.com/ac/users/4181120/profile_pic/1353410412/original.jpg?interpolation=lanczos-none&crop=w:w;*,*&crop=h:h;*,*&resize=50:*&output-format=jpg&output-quality=70 | Candace | https://a1.muscache.com/im/pictures/11761392/455c9074_original.jpg?aki_policy=medium | https://www.airbnb.com/rooms/793629 | Cheery Seattle House with View | 57 | House | Entire home/apt | ||||
| 2 | 1 | Real Bed | 1 | 1 | 20170428 | 20170601 | TRUE | https://a2.muscache.com/ac/pictures/cb3215bb-4a5c-4225-9fec-e683f6f95aa2.jpg?interpolation=lanczos-none&crop=w:w;*,*&crop=h:h;*,*&resize=50:*&output-format=jpg&output-quality=70 | Kc | https://a2.muscache.com/im/pictures/00bc83c6-274f-4dd3-ac2f-d61a318945d1.jpg?aki_policy=medium | https://www.airbnb.com/rooms/9110410 | Garden Apt across from Park | 168 | Apartment | Entire home/apt |
(1)创建索引
#创建索引 ,配置 自动补全 分词器
PUT myairbnb
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
"autosuggest_analyzer": {
"filter": [
"lowercase",
"asciifolding",
"autosuggest_filter"
],
"tokenizer": "standard",
"type": "custom"
},
"ngram_analyzer": {
"filter": [
"lowercase",
"asciifolding",
"ngram_filter"
],
"tokenizer": "standard",
"type": "custom"
}
},
"filter": {
"autosuggest_filter": {
"max_gram": "20",
"min_gram": "1",
"token_chars": [
"letter",
"digit",
"punctuation",
"symbol"
],
"type": "edge_ngram"
},
"ngram_filter": {
"max_gram": "9",
"min_gram": "2",
"token_chars": [
"letter",
"digit",
"punctuation",
"symbol"
],
"type": "ngram"
}
}
}
}
},
"mappings": {
"doc": {
"dynamic": false,
"properties": {
"accommodates": {
"type": "integer"
},
"bathrooms": {
"type": "integer"
},
"bed_type": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"bedrooms": {
"type": "integer"
},
"beds": {
"type": "integer"
},
"date_from": {
"type": "date",
"format": "yyyyMMdd"
},
"date_to": {
"type": "date",
"format": "yyyyMMdd"
},
"has_availability": {
"type": "boolean"
},
"host_image": {
"type": "keyword",
"ignore_above": 256,
"index": false
},
"host_name": {
"type": "text",
"analyzer": "autosuggest_analyzer",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"image": {
"type": "keyword",
"ignore_above": 256,
"index": false
},
"listing_url": {
"type": "keyword",
"ignore_above": 256
},
"location": {
"type": "geo_point"
},
"name": {
"type": "text",
"analyzer": "autosuggest_analyzer",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"price": {
"type": "float"
},
"property_type": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"room_type": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}(2)在 logstash 的 config 文件夹 下编写 一个 ls.conf
input{
stdin{}
}
filter{
csv{
columns =>["accommodates","bathrooms","bed_type","bedrooms","beds","date_from","date_o","date_rom","date_to","has_availability","host_image","host_name" ,"image","listing_url","location","name","price","property_type","room_type"]
}
mutate{
remove_field =>["message"]
lowercase=>["has_availability"]
}
}
output{
elasticsearch{
hosts =>["192.168.42.85:9200"]
index =>"myairbnb"
}
stdout{
codec =>rubydebug
}
}(3) 执行命令
cat airbnb.csv | ./logstash-6.4.2/bin/logstash -f ./logstash-6.4.2/config/ls.conf 数据就会导入到 es 中
(4)修改 url 、image 字段的format
如; 页面连接的 字段,就将 format 修改为 url ,type 为 link
需要展示为图片的字段,就将format 修改为url,template 修改为 {{rawValue}} ,type为image
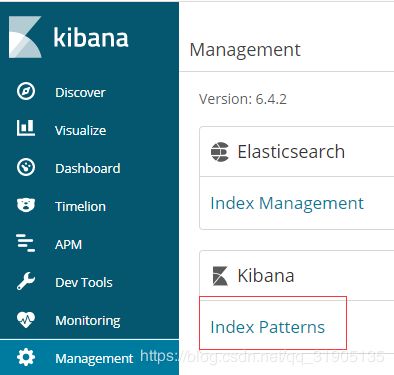

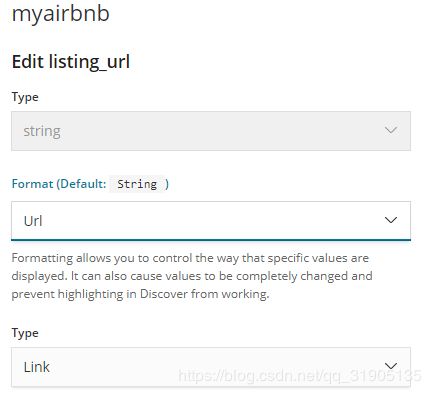
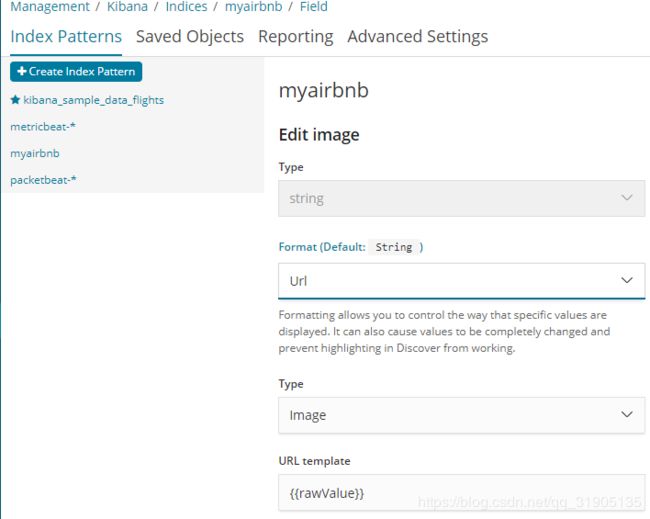
(5)discovery
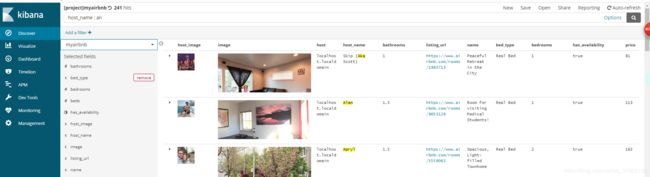
(6)搭建搜索页面
ReactiveSearch 开源项目
- https://opensource.appbase.io/reactive-manual/
- https://github.com/appbaseio/reactivesearch
安装nodejs ,yarn
demo : https://github.com/appbaseio-apps/airbeds
yarn安装完成之后可能会报错 : Could not create the Java Virtual Machine.
只需要将 环境变量中的 nodejs 和 yarn 环境变量 移动到 jdk 就可以了。
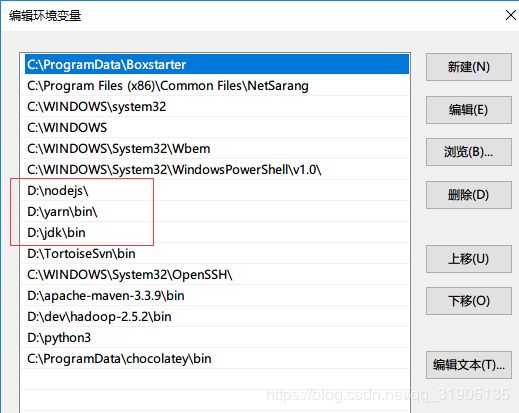
详细解决方案参考 :https://blog.csdn.net/wu5229485/article/details/82992627
$ git clone https://github.com/appbaseio-apps/airbeds.git
用idea 打开 项目,并修改如下所示的代码 :
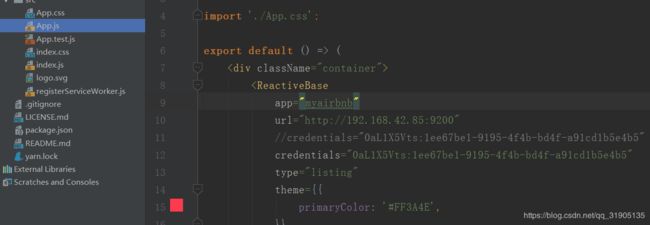
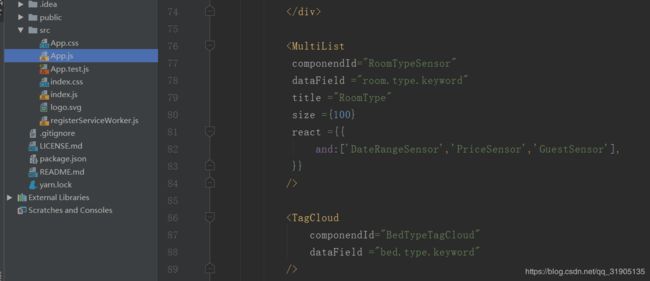
将 es 的配置 elasticsearch.yml 中的最后几行的跨域配置注释打开
$ cd airbeds/
$ yarn
$yarn start
六 、nginx 日志采集 实战

PUT _template/nginx_logs
{
"index_patterns":"nginx_logs_*",
"setting":{
"index":{
"number_of_shards":1,
"number_of_replicas":0,
"refresh_interval":30s
}
},
"mappings":{
"doc":{
"dynamic":false,
"properties":{
"@timestamp":{
"type":"date"
},
"@version":{
"type":"keyword",
"ignore_above":256
},
"agent":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"auth":{
"type":"keyword",
"ignore_above":256
},
"bytes":{
"type":"long"
},
"clientip":{
"type":"keyword",
"ignore_above":256
},
"geoip":{
"properties":{
"city_name":{
"type":"keyword",
"ignore_above":256
}
}
},
}
}
}
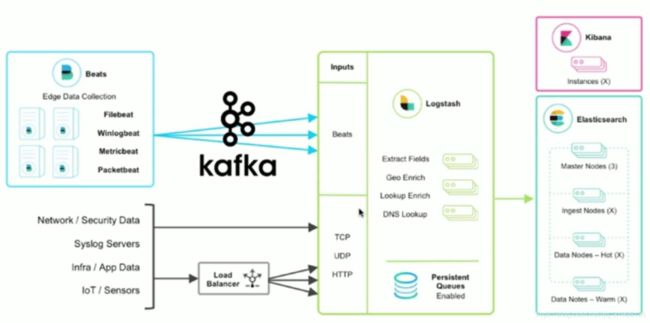
}日志常见收集架构
input{
#http{
# port => 7474
#}
file{
path => "access.20161111.log"
#path => "access.1w.log"
sincedb_path => "/dev/null"
start_position => "beginning"
}
}
filter{
#mutate{add_field => {"[@metadata][debug]"=>true}}
if [@metadata][debug] {
mutate{ remove_field => ["headers"] }
}
grok{
match => {
"message" => '%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:[@metadata][timestamp]}\] "%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}" %{NOTSPACE:response_status_code} (?:%{NUMBER:bytes}|-) %{QS:hostname} %{QS:referrer} (?:-|%{DATA:params}) %{QS:agent} %{QS:xforwardedfor} (?:-|%{MY_URI:upstream_host}) (?:-|%{MY_RESP:upstream_response_status_code}) (?:-|%{MY_RESP_TIME:upstream_response_time}) %{BASE10NUM:response_time:float}'
}
pattern_definitions=>{
"MY_URI" => '%{URIHOST}(, %{URIHOST})*'
"MY_RESP" => '%{NUMBER}(, %{NUMBER})*'
"MY_RESP_TIME" => '%{BASE10NUM}(, %{BASE10NUM})*'
}
}
date{
match => ["[@metadata][timestamp]","dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate{
split => {"upstream_host" => ", "}
split => {"upstream_response_status_code" => ", "}
split => {"upstream_response_time" => ", "}
gsub => ["hostname",'"','']
}
mutate{
convert => {"upstream_response_time"=>"float"}
}
geoip{
source => "clientip"
}
useragent{
source => "agent"
target => "useragent"
}
mutate{
add_field => {
"[@metadata][index]" => "nginx_logs_%{+YYYY.MM.dd}"
}
}
if [referrer] =~ /^"http/ {
grok{
match => {
"referrer" => '%{URIPROTO}://%{URIHOST:referrer_host}'
}
}
#if "www.imooc.com" in [referrer] {
#if [referrer] =~ /^"http://www.imooc.com/ {
if "imooc.com" in [referrer_host] {
grok{
match => {
"referrer" => ['%{URIPROTO}://%{URIHOST}/(%{NOTSPACE:imooc_type}/%{NOTSPACE:imooc_res_id})?"','%{URIPROTO}://%{URIHOST}/(%{NOTSPACE:imooc_type})?"']
}
}
}
}
mutate{
gsub => ["referrer",'"','']
}
if "_grokparsefailure" in [tags] {
mutate{
replace => {
"[@metadata][index]" => "nginx_logs_parsefailure_%{+YYYY.MM.dd}"
}
}
}else{
mutate{remove_field=>["message"]}
}
}
output{
if [@metadata][debug]{
stdout{
#codec=>json_lines
codec => rubydebug{
metadata => true
}
}
}else{
stdout{codec=>dots}
elasticsearch{
index => "%{[@metadata][index]}"
}
}
}
七、数据分析实战 filebeat + ingest node es
北京天气 质量数据分析
| Site | Parameter | Date (LST) | Year | Month | Day | Hour | Value | Unit | Duration | QC Name |
| Beijing | PM2.5 | 1/1/2015 0:00 | 2015 | 1 | 1 | 0 | 22 | 碌g/m鲁 | 1 Hr | Valid |
| Beijing | PM2.5 | 1/1/2015 1:00 | 2015 | 1 | 1 | 1 | 9 | 碌g/m鲁 | 1 Hr | Valid |
| Beijing | PM2.5 | 1/1/2015 2:00 | 2015 | 1 | 1 | 2 | 9 | 碌g/m鲁 | 1 Hr | Valid |
| Beijing | PM2.5 | 1/1/2015 3:00 | 2015 | 1 | 1 | 3 | 13 | 碌g/m鲁 | 1 Hr | Valid |
| Beijing | PM2.5 | 1/1/2015 4:00 | 2015 | 1 | 1 | 4 | 10 | 碌g/m鲁 | 1 Hr | Valid |
| Beijing | PM2.5 | 1/1/2015 5:00 | 2015 | 1 | 1 | 5 | 6 | 碌g/m鲁 | 1 Hr | Valid |
创建 索引 mapping 和 pipeline
PUT air_quality
{
"mappings": {
"doc": {
"dynamic": false,
"properties": {
"@timestamp": {
"type": "date"
},
"city": {
"type": "keyword",
"ignore_above": 256
},
"parameter": {
"type": "keyword",
"ignore_above": 256
},
"status": {
"type": "keyword",
"ignore_above": 256
},
"value": {
"type": "long"
}
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}
PUT /_ingest/pipeline/airquality
{
"processors": [
{
"grok": {
"field": "message",
"patterns": [
"%{DATA:city},%{DATA:parameter},%{DATA:date},%{NUMBER:year},%{NUMBER:month},%{NUMBER:day},%{NUMBER:hour},%{NUMBER:value},%{DATA:unit},%{DATA:duration},%{WORD:status}"
]
}
},
{
"set": {
"field": "_id",
"value": "{{city}}-{{date}}"
}
},
{
"date": {
"field": "date",
"target_field": "@timestamp",
"formats": [
"MM/dd/yyyy HH:mm",
"yyyy-MM-dd HH:mm"
],
"timezone": "Asia/Shanghai"
}
},
{
"remove": {
"field": "message"
}
},
{
"remove": {
"field": "beat"
}
},
{
"remove": {
"field": "offset"
}
},
{
"remove": {
"field": "source"
}
},
{
"remove": {
"field": "date"
}
},
{
"convert": {
"field": "year",
"type": "integer"
}
},
{
"convert": {
"field": "month",
"type": "integer"
}
},
{
"convert": {
"field": "day",
"type": "integer"
}
},
{
"convert": {
"field": "hour",
"type": "integer"
}
},
{
"remove": {
"field": "duration"
}
},
{
"remove": {
"field": "unit"
}
},
{
"convert": {
"field": "value",
"type": "integer"
}
}
],
"on_failure": [
{
"set": {
"field": "error.message",
"value": "{{ _ingest.on_failure_message }}"
}
}
]
}修改 filebeat 的 配置文件
#=========================== Filebeat inputs =============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
#修改为标准输入
- type: stdin
#设置为true
# Change to true to enable this input configuration.
enabled: true
#==================== Elasticsearch template setting ==========================
#在下面 es output 地方修改了index 之后要在这里设置 name 和 pattern
setup.template.name: "air"
setup.template.pattern: "air-*"
setup.template.settings:
index.number_of_shards: 3
#index.codec: best_compression
#_source.enabled: false
#============================== Kibana =====================================
# Starting with Beats version 6.0.0, the dashboards are loaded via the Kibana API.
# This requires a Kibana endpoint configuration.
setup.kibana:
# Kibana Host
# Scheme and port can be left out and will be set to the default (http and 5601)
# In case you specify and additional path, the scheme is required: http://localhost:5601/path
# IPv6 addresses should always be defined as: https://[2001:db8::1]:5601
host: "192.168.42.85:5601"
#================================ Outputs =====================================
# Configure what output to use when sending the data collected by the beat.
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["192.168.42.85:9200"]
# 设置 pipeline 名称和索引名称
pipeline: "airquality"
index: "air_quality"
执行 命令 cat Beijing_2017_HourlyPM25_created20170803.csv | ./filebeat-6.4.2-linux-x86_64/filebeat -e -c ./filebeat-6.4.2-linux-x86_64/filebeat.yml -d "publish"
csv 数据 就会 导入到es 的 air_quality索引中。
利用 python 获取 每天的 pm2.5的最大值,最小值,平均值 ,并导入到es 中
pip install elasticsearch
from datetime import datetime
from elasticsearch import Elasticsearch
es = Elasticsearch(['192.168.42.85:9200'])
search_query={
"query":{
"range":{
"value":{
"gte":1
}
}
},
"aggs":{
"days":{
"date_histogram":{
"field":"@timestamp",
"interval":"day",
"time_zone":"+08:00"
},
"aggs":{
"pm25":{
"stats":{
"field":"value"
}
}
}
}
},
"size": 0
}
res = es.search(index='air_quality',body=search_query)
index_name='air_auality_days'
index_type='doc'
es.indices.delete(index=index_name, ignore=[400,404])
for info in res['aggregations']['days']['buckets']:
cur_date = datetime.strptime(info['key_as_string'], '%Y-%m-%dT%H:%M:%S.%f+08:00')
new_doc={
"@timestamp":info['key_as_string'],
"year":cur_date.year,
"month":cur_date.month,
"day":cur_date.day,
"value_max":info['pm25']['max'],
"value_avg":info['pm25']['avg'],
"value_min":info['pm25']['min'],
}
es.index(index=index_name,doc_type=index_type,
id=new_doc['@timestamp'],body=new_doc)
print(new_doc)之后 就可以 利用 kibana 的可视化分析制作 各种 图表分析 了。
es 学习 资料:
- https://www.elastic.co/learn
es 中文社区:
- https://elasticsearch.cn/
重视数据实践分析
- https://github.com/elastic/examples
- https://www.kaggle.com/datasets