MyCat权威指南阅读笔记(基础篇)
1.1何为数据切分?
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主
机)上面,以达到分散单台设备负载的效果。
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表(或者
Schema)来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;另外一种则是根据
表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数
据的水平(横向)切分。
垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很
小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库
中。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库
中,对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
1.2垂直切分
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同
的数据库上面,这样也就将数据或者说压力分担到不同的库上面,如下图:
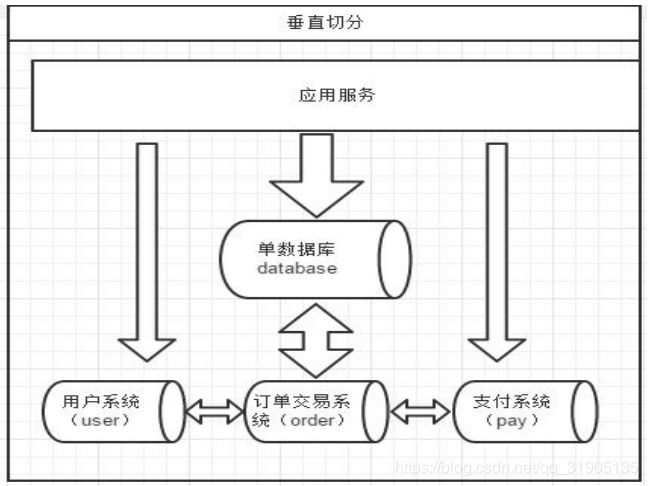
系统被切分成了,用户,订单交易,支付几个模块。
一个架构设计较好的应用系统,其总体功能肯定是由很多个功能模块所组成的,而每一个功能模块所需要的
数据对应到数据库中就是一个或者多个表。而在架构设计中,各个功能模块相互之间的交互点越统一越少,系统
的耦合度就越低,系统各个模块的维护性以及扩展性也就越好。这样的系统,实现数据的垂直切分也就越容易。
但是往往系统之有些表难以做到完全的独立,存在这扩库 join 的情况,对于这类的表,就需要去做平
衡,是数据库让步业务,共用一个数据源,还是分成多个库,业务之间通过接口来做调用。在系统初期,数据量
比较少,或者资源有限的情况下,会选择共用数据源,但是当数据发展到了一定的规模,负载很大的情况,就需
要必须去做分割。
一般来讲业务存在着复杂 join 的场景是难以切分的,往往业务独立的易于切分。如何切分,切分到何种
程度是考验技术架构的一个难题。
下面来分析下垂直切分的优缺点:
优点:
拆分后业务清晰,拆分规则明确;
系统之间整合或扩展容易;
数据维护简单。
缺点:
部分业务表无法 join,只能通过接口方式解决,提高了系统复杂度;
受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高;
事务处理复杂。
由于垂直切分是按照业务的分类将表分散到不同的库,所以有些业务表会过于庞大,存在单库读写与存储瓶
颈,所以就需要水平拆分来做解决。
1.3水平切分
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中
包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分
到一个数据库,而另外的某些行又切分到其他的数据库中,如图:
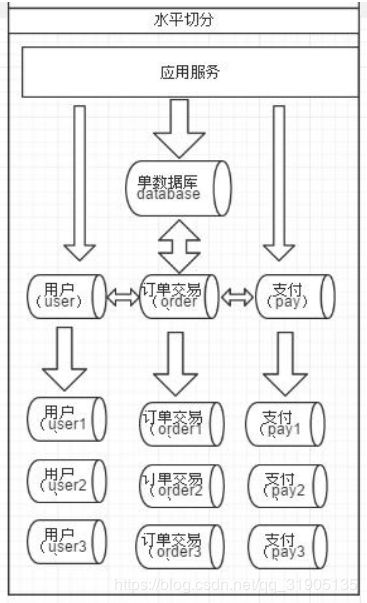
拆分数据就需要定义分片规则。关系型数据库是行列的二维模型,拆分的第一原则是找到拆分维度。比如:
从会员的角度来分析,商户订单交易类系统中查询会员某天某月某个订单,那么就需要按照会员结合日期来拆
分,不同的数据按照会员 ID 做分组,这样所有的数据查询 join 都会在单库内解决;如果从商户的角度来讲,要查
询某个商家某天所有的订单数,就需要按照商户 ID 做拆分;但是如果系统既想按会员拆分,又想按商家数据,则
会有一定的困难。如何找到合适的分片规则需要综合考虑衡量。
几种典型的分片规则包括:
按照用户 ID 求模,将数据分散到不同的数据库,具有相同数据用户的数据都被分散到一个库中;
按照日期,将不同月甚至日的数据分散到不同的库中;
按照某个特定的字段求摸,或者根据特定范围段分散到不同的库中。
如图,切分原则都是根据业务找到适合的切分规则分散到不同的库,下面用用户 ID 求模举例:

既然数据做了拆分有优点也就优缺点。
优点:
拆分规则抽象好,join 操作基本可以数据库做;
不存在单库大数据,高并发的性能瓶颈;
应用端改造较少;
提高了系统的稳定性跟负载能力。
缺点:
20
拆分规则难以抽象;
分片事务一致性难以解决;
数据多次扩展难度跟维护量极大;
跨库 join 性能较差。
前面讲了垂直切分跟水平切分的不同跟优缺点,会发现每种切分方式都有缺点,但共同的特点缺点有:
引入分布式事务的问题;
跨节点 Join 的问题;
跨节点合并排序分页问题;
多数据源管理问题。
针对数据源管理,目前主要有两种思路:
A. 客户端模式,在每个应用程序模块中配置管理自己需要的一个(或者多个)数据源,直接访问各个数据
库,在模块内完成数据的整合;
B. 通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明;
可能 90%以上的人在面对上面这两种解决思路的时候都会倾向于选择第二种,尤其是系统不断变得庞大复杂
的时候。确实,这是一个非常正确的选择,虽然短期内需要付出的成本可能会相对更大一些,但是对整个系统的
扩展性来说,是非常有帮助的。
Mycat 通过数据切分解决传统数据库的缺陷,又有了 NoSQL 易于扩展的优点。通过中间代理层规避了多数
据源的处理问题,对应用完全透明,同时对数据切分后存在的问题,也做了解决方案。下面章节就分析,mycat
的由来及如何进行数据切分问题。
由于数据切分后数据 Join 的难度在此也分享一下数据切分的经验:
第一原则:能不切分尽量不要切分。
第二原则:如果要切分一定要选择合适的切分规则,提前规划好。
第三原则:数据切分尽量通过数据冗余或表分组(Table Group)来降低跨库 Join 的可能。
第四原则:由于数据库中间件对数据 Join 实现的优劣难以把握,而且实现高性能难度极大,业务读取尽量
少使用多表 Join。
2.1Mycat 原理
Mycat 的原理并不复杂,复杂的是代码,如果代码也不复杂,那么早就成为一个传说了。
Mycat 的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的 SQL 语句,首先对 SQL 语句做了
一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库,
并将返回的结果做适当的处理,最终再返回给用户。
上述图片里,Orders 表被分为三个分片 datanode(简称 dn),这三个分片是分布在两台 MySQL Server 上
(DataHost),即 datanode=database@datahost 方式,因此你可以用一台到 N 台服务器来分片,分片规则为
(sharding rule)典型的字符串枚举分片规则,一个规则的定义是分片字段(sharding column)+分片函数(rule
function),这里的分片字段为 prov 而分片函数为字符串枚举方式。
当 Mycat 收到一个 SQL 时,会先解析这个 SQL,查找涉及到的表,然后看此表的定义,如果有分片规则,
则获取到 SQL 里分片字段的值,并匹配分片函数,得到该 SQL 对应的分片列表,然后将 SQL 发往这些分片去执
行,最后收集和处理所有分片返回的结果数据,并输出到客户端。以 select * from Orders where prov=?语句为
例,查到 prov=wuhan,按照分片函数,wuhan 返回 dn1,于是 SQL 就发给了 MySQL1,去取 DB1 上的查询
结果,并返回给用户。
如果上述 SQL 改为 select * from Orders where prov in (‘wuhan’,‘beijing’),那么,SQL 就会发给
MySQL1 与 MySQL2 去执行,然后结果集合并后输出给用户。但通常业务中我们的 SQL 会有 Order By 以及
Limit 翻页语法,此时就涉及到结果集在 Mycat 端的二次处理,这部分的代码也比较复杂,而最复杂的则属两个
表的 Jion 问题,为此,Mycat 提出了创新性的 ER 分片、全局表、HBT(Human Brain Tech)人工智能的
Catlet、以及结合 Storm/Spark 引擎等十八般武艺的解决办法,从而成为目前业界最强大的方案,这就是开源的
力量!
2.2应用场景
Mycat 发展到现在,适用的场景已经很丰富,而且不断有新用户给出新的创新性的方案,以下是几个典型的
应用场景:
单纯的读写分离,此时配置最为简单,支持读写分离,主从切换;
分表分库,对于超过 1000 万的表进行分片,最大支持 1000 亿的单表分片;
多租户应用,每个应用一个库,但应用程序只连接 Mycat,从而不改造程序本身,实现多租户化;
报表系统,借助于 Mycat 的分表能力,处理大规模报表的统计;
替代 Hbase,分析大数据;
作为海量数据实时查询的一种简单有效方案,比如 100 亿条频繁查询的记录需要在 3 秒内查询出来结果,
除了基于主键的查询,还可能存在范围查询或其他属性查询,此时 Mycat 可能是最简单有效的选择。
3.1 linux 服务安装与配置
MyCAT 有提供编译好的安装包,支持 windows、Linux、Mac、Solaris 等系统上安装与运行。
linux 下可以下载 Mycat-server-xxxxx.linux.tar.gz 解压在某个目录下,注意目录不能有空格,在
Linux(Unix)下,建议放在 usr/local/Mycat 目录下,如下:

下面是修改 MyCAT 用户密码的方式(仅供参考):
目录解释如下:
bin 程序目录,存放了 window 版本和 linux 版本,除了提供封装成服务的版本之外,也提供了 nowrap 的
shell 脚本命令,方便大家选择和修改,进入到 bin 目录:
Linux 下运行:./mycat console,首先要 chmod +x *
注:mycat 支持的命令{ console | start | stop | restart | status | dump }
conf 目录下存放配置文件,server.xml 是 Mycat 服务器参数调整和用户授权的配置文件,schema.xml 是逻
辑库定义和表以及分片定义的配置文件,rule.xml 是分片规则的配置文件,分片规则的具体一些参数信息单独存
放为文件,也在这个目录下,配置文件修改,需要重启 Mycat 或者通过 9066 端口 reload.
lib 目录下主要存放 mycat 依赖的一些 jar 文件.
日志存放在 logs/mycat.log 中,每天一个文件,日志的配置是在 conf/log4j.xml 中,根据自己的需要,可
以调整输出级别为 debug,debug 级别下,会输出更多的信息,方便排查问题.
注意:Linux 下部署安装 MySQL,默认不忽略表名大小写,需要手动到/etc/my.cnf 下配置
lower_case_table_names=1 使 Linux 环境下 MySQL 忽略表名大小写,否则使用 MyCAT 的时候会提示找不到
表的错误!
3.2 windows 下 服务安装与配置
MyCAT 有提供编译好的安装包,支持 windows、Linux、Mac、Solaris 等系统上安装与运行。
windows 下可以下载 Mycat-server-xxxxx-win.tar.gz 解压在某个目录下,建议解压到本地某个盘符根目录
下,如下:
目录解释如下:
bin 程序目录,存放了 window 版本和 linux 版本,除了提供封装成服务的版本之外,也提供了 nowrap 的
shell 脚本命令,方便大家选择和修改,进入到 bin 目录:
Windows 下运行:运行: mycat.bat 在控制台启动程序,也可以装载成服务,若此程序运行有问题,也可以
运行 startup_nowrap.bat,确保 java 命令可以在命令执行。
Windows 下将 MyCAT 做成系统服务:MyCAT 提供 warp 方式的命令,可以将 MyCAT 安装成系统服务并
可启动和停止。
1) 进入 bin 目录下, 输入 ./mycat start 启动 mycat 服务。
conf 目录下存放配置文件,server.xml 是 Mycat 服务器参数调整和用户授权的配置文件,schema.xml 是逻
辑库定义和表以及分片定义的配置文件,rule.xml 是分片规则的配置文件,分片规则的具体一些参数信息单独存
放为文件,也在这个目录下,配置文件修改,需要重启 Mycat 或者通过 9066 端口 reload。
lib 目录下主要存放 mycat 依赖的一些 jar 文件。
日志存放在 logs/mycat.log 中,每天一个文件,日志的配置是在 conf/log4j.xml 中,根据自己的需要,可
以调整输出级别为 debug,debug 级别下,会输出更多的信息,方便排查问题。
3.3服务启动与启动设置
3.3.1 linux 下启动
MyCAT 在 Linux 中部署启动时,首先需要在 Linux 系统的环境变量中配置 MYCAT_HOME,操作方式如下:
1) vi /etc/profile,在系统环境变量文件中增加 MYCAT_HOME=/usr/local/Mycat。
2) 执行 source /etc/profile 命令,使环境变量生效。
如果是在多台 Linux 系统中组建的 MyCAT 集群,那需要在 MyCAT Server 所在的服务器上配置对其他 ip 和
主机名的映射,配置方式如下:
vi /etc/hosts
例如:我有 4 台机器,配置如下:
IP 主机名:
192.168.100.2 sam_server_1
192.168.100.3 sam_server_2
192.168.100.4 sam_server_3
192.168.100.5 sam_server_4
编辑完后,保存文件。
经过以上两个步骤的配置,就可以到/usr/local/Mycat/bin 目录下执行:
./mycat start
即可启动 mycat 服务!
3.3.2 windows下启动
MyCAT 在 windows 中部署时,建议放在某个盘符的根目录下,如果不是在根目录下,请尽量不要放在包含
中文的目录下
如:D:\Mycat-server-1.4-win\
命令行方式启动:
从 cmd 中执行命令到达 D:\Mycat-server-1.4-win\bin 目录下,执行 startup_nowrap.bat 即可启动
MyCAT 服务。
45
注:执行此命令时,需要确保 windows 系统中已经配置好了 JAVA 的环境变量,并可执行 java 命令。jdk 版
本必须是 1.7 及以上版本。
3.3.3基于 zk 的启动
1.5 开始会支持本地 xml 启动,以及从 zk 加载配置转为本地 xml 的两种方式,conf 下的 zk.conf 文件里设置
loadfromzk 参数默认为 false
如果没有这个文件,或者没有 loadfromzk 为 true 的参数,即从本地加载。下面介绍从 ZK 启动相关配置。
Zk-create.yaml 说明
1.5 正式引入 zookeeper(以下简称 zk)管理 Mycat-Server,启动 server 第一步是初始化 zk 数据,下面介绍初
始化 zk 数据步骤,信息在 zk-create.yaml。Mycat ZK 配置文件详解:
https://github.com/MyCATApache/Mycat-
doc/blob/master/%E8%AE%BE%E8%AE%A1%E6%96%87%E6%A1%A3/2.0/Mycat%20ZK%E9%85%
8D%E7%BD%AE%E6%96%87%E4%BB%B6%E8%AF%A6%E8%A7%A3.docx
1、zk-create 总体结构

2、参数说明
2.1、zkURL,zk 连接地址
2.2、mycat-cluster



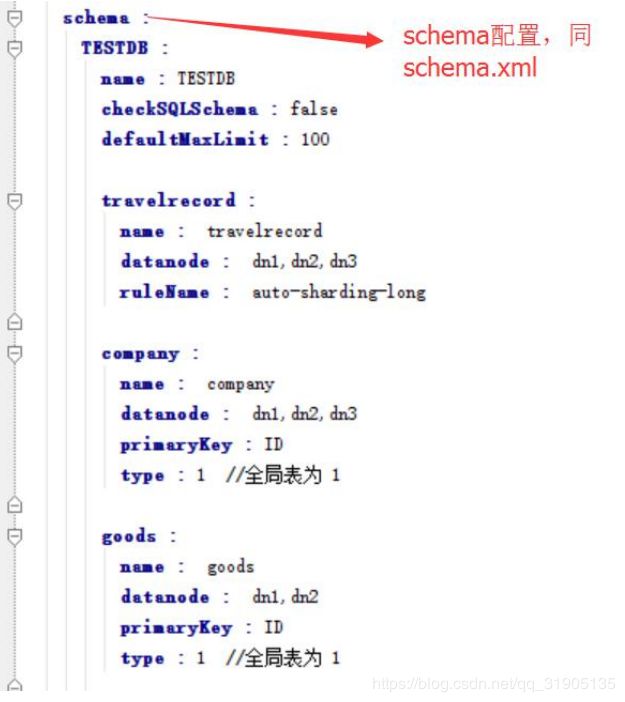
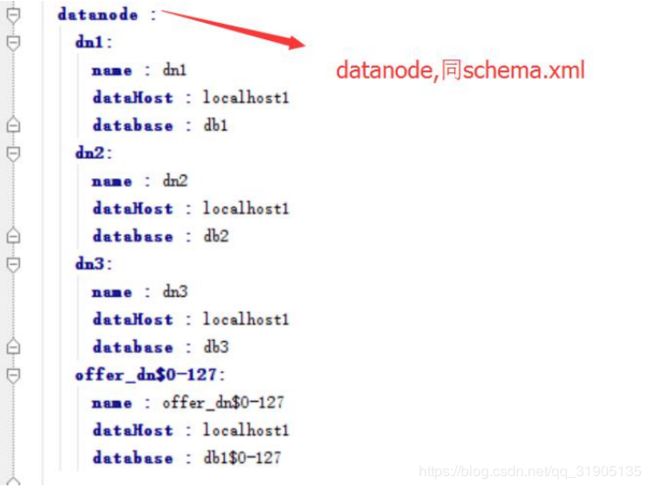
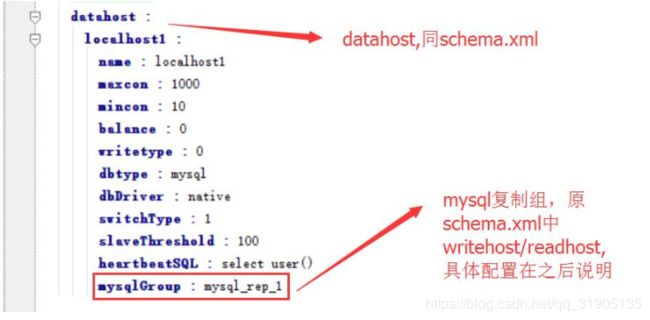




2.7 mysql-reps

Zk 初始化
1、进入 MYCAT/bin 目录
cd /data/test1/mycat/bin
2、修改 MYCAT/conf/zk-create.yaml 内容
修改方法见“Zk-create.yaml 说明”。
3、启动 ZK
启动 ZK: bin/zkServer.sh start
登陆 ZK: bin/zkCli.sh
4、初始化 ZK 数据
sh create_zookeeper_data.sh
等待执行结束后,检查 ZK 数据
5、检查 ZK 数据

OK,数据初始化成功。
4.1 Mycat 的分片 join
8.1 join 概述
Join 绝对是关系型数据库中最常用一个特性,然而在分布式环境中,跨分片的 join 确是最复杂的,最难解决一
个问题。
下面我们简单介绍下各种 Join 操作。
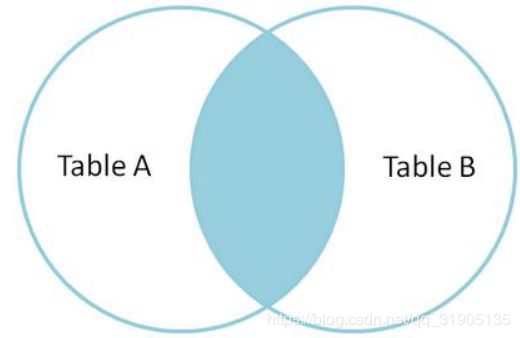
INNER JOIN
内连接,也叫等值连接,inner join 产生同时符合 A 表和 B 表的一组数据。
如图:
LEFT JOIN
左连接从 A 表(左)产生一套完整的记录,与匹配的 B 表记录(右表) .如果没有匹配,右侧将包含 null,在 Mysql 中
等同于 left outer join。
如图:
RIGHT JOIN
同 Left join,AB 表互换即可。
Cross join
交叉连接,得到的结果是两个表的乘积,即笛卡尔积。笛卡尔(Descartes)乘积又叫直积。假设集合
A={a,b},集合 B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1), (b,2)}。可以扩展到多个集合的情
况。类似的例子有,如果 A 表示某学校学生的集合,B 表示该学校所有课程的集合,则 A 与 B 的笛卡尔积表示所
有可能的选课情况。
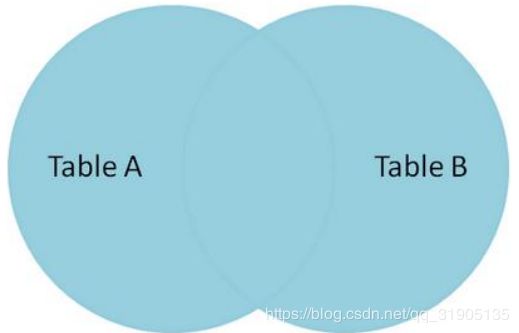
Full join
全连接产生的所有记录(双方匹配记录)在表 A 和表 B。如果没有匹配,则对面将包含 null。
性能建议
尽量避免使用 Left join 或 Right join,而用 Inner join
在使用 Left join 或 Right join 时,ON 会优先执行,where 条件在最后执行,所以在使用过程中,条件尽
可能的在 ON 语句中判断,减少 where 的执行
少用子查询,而用 join。
Mycat 目前版本支持跨分片的 join,主要实现的方式有四种。
全局表,ER 分片,catletT(人工智能)和 ShareJoin,ShareJoin 在开发版中支持,前面三种方式 1.3.0.1 支
持 。
4.1.1 全局表
一个真实的业务系统中,往往存在大量的类似字典表的表格,它们与业务表之间可能有关系,这种关系,可
以理解为“标签”,而不应理解为通常的“主从关系”,这些表基本上很少变动,可以根据主键 ID 进行缓存,下
面这张图说明了一个典型的“标签关系”图:
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较
棘手的问题,考虑到字典表具有以下几个特性:
• 变动不频繁
• 数据量总体变化不大
• 数据规模不大,很少有超过数十万条记录。
鉴于此,MyCAT 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
• 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
• 全局表的查询操作,只从一个节点获取
• 全局表可以跟任何一个表进行 JOIN 操作
将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据 JOIN 的难题。
通过全局表+基于 E-R 关系的分片策略,MyCAT 可以满足 80%以上的企业应用开发。
配置
全局表配置比较简单,不用写 Rule 规则,如下配置即可:
需要注意的是,全局表每个分片节点上都要有运行创建表的 DDL 语句。
4.1.2 ER Join
MyCAT 借鉴了 NewSQL 领域的新秀 Foundation DB 的设计思路,Foundation DB 创新性的提出了 Table
Group 的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了 JION 的效率和性能问
题,根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分
片上。
customer 采用 sharding-by-intfile 这个分片策略,分片在 dn1,dn2 上,orders 依赖父表进行分片,两个表
的关联关系为 orders.customer_id=customer.id。于是数据分片和存储的示意图如下:
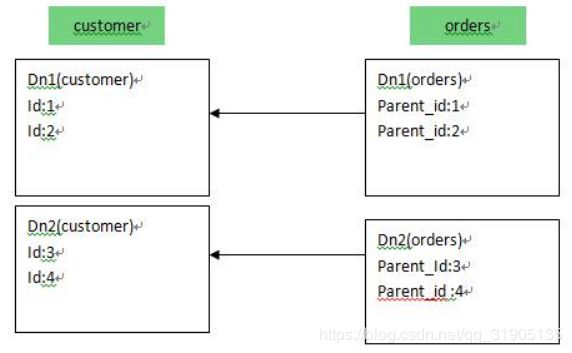
这样一来,分片 Dn1 上的的 customer 与 Dn1 上的 orders 就可以进行局部的 JOIN 联合,Dn2 上也如此,再合
并两个节点的数据即可完成整体的 JOIN,试想一下,每个分片上 orders 表有 100 万条,则 10 个分片就有 1 个亿,基
于 E-R 映射的数据分片模式,基本上解决了 80%以上的企业应用所面临的问题。
配置
以上述例子为例,schema.xml 中定义如下的分片配置:
4.1.3 Share join
ShareJoin 是一个简单的跨分片 Join,基于 HBT 的方式实现。
目前支持 2 个表的 join,原理就是解析 SQL 语句,拆分成单表的 SQL 语句执行,然后把各个节点的数据汇
集。
配置
支持任意配置的 A,B 表如:
A,B 的 dataNode 相同
A,B 的 dataNode 不同
或
代码测试
先把表 company 从全局表修改下配置
重新插入数据
mysql> delete from company;
Query OK, 9 rows affected (0.19 sec)
mysql> insert company (id,name) values(1,'mycat');
Query OK, 1 row affected (0.08 sec)
mysql> insert company (id,name) values(2,'ibm');
Query OK, 1 row affected (0.03 sec)
101
mysql> insert company (id,name) values(3,'hp');
Query OK, 1 row affected (0.03 sec)
下面可以看下普通的 join 和 sharejoin 的区别
mysql> select a.*,b.id, b.name as tit from customer a,company b where a.company_id=b.id;
+----+------+------------+-------------+----+------+
| id | name | company_id | sharding_id | id | tit |
+----+------+------------+-------------+----+------+
| 3 | feng | 3 | 10000 | 3 | hp |
+----+------+------------+-------------+----+------+
1 row in set (0.03 sec)
mysql> /*!mycat:catlet=demo.catlets.ShareJoin */ select a.*,b.id, b.name as tit from customer a,company b
on a.company_id=b.id;
+----+------+------------+-------------+----+-------+
| id | name | company_id | sharding_id | id | tit |
+----+------+------------+-------------+----+-------+
| 3 | feng | 3 | 10000 | 3 | hp |
| 1 | wang | 1 | 10000 | 1 | mycat |
| 2 | xue | 2 | 10010 | 2 | ibm |
+----+------+------------+-------------+----+-------+
3 rows in set (0.05 sec)
其他两种写法
/*!mycat:catlet=demo.catlets.ShareJoin */ select a.*,b.id, b.name as tit from customer a join company b on
a.company_id=b.id;
+----+------+------------+-------------+----+-------+
| id | name | company_id | sharding_id | id | tit |
+----+------+------------+-------------+----+-------+
| 3 | feng | 3 | 10000 | 3 | hp |
| 1 | wang | 1 | 10000 | 1 | mycat |
102
| 2 | xue | 2 | 10010 | 2 | ibm |
+----+------+------------+-------------+----+-------+
3 rows in set (0.01 sec)
/*!mycat:catlet=demo.catlets.ShareJoin */ select a.*,b.id, b.name as tit from customer a join company b where
a.company_id=b.id;
+----+------+------------+-------------+----+-------+
| id | name | company_id | sharding_id | id | tit |
+----+------+------------+-------------+----+-------+
| 3 | feng | 3 | 10000 | 3 | hp |
| 1 | wang | 1 | 10000 | 1 | mycat |
| 2 | xue | 2 | 10010 | 2 | ibm |
+----+------+------------+-------------+----+-------+
3 rows in set (0.01 sec)
对*的支持,还可以这样写 SQL
mysql> /*!mycat:catlet=demo.catlets.ShareJoin */ select a.*,b.* from customer a join company b on
a.company_id=b.id;
+----+------+------------+-------------+-------+
| id | name | company_id | sharding_id | name |
+----+------+------------+-------------+-------+
| 1 | wang | 1 | 10000 | mycat |
| 2 | xue | 2 | 10010 | ibm |
| 3 | feng | 3 | 10000 | hp |
+----+------+------------+-------------+-------+
3 rows in set (0.02 sec)
mysql> /*!mycat:catlet=demo.catlets.ShareJoin */ select * from customer a join company b on
a.company_id=b.id;
+----+------+------------+-------------+-------+
103
| id | name | company_id | sharding_id | name |
+----+------+------------+-------------+-------+
| 1 | wang | 1 | 10000 | mycat |
| 2 | xue | 2 | 10010 | ibm |
| 3 | feng | 3 | 10000 | hp |
+----+------+------------+-------------+-------+
3 rows in set (0.02 sec)
/*!mycat:catlet=demo.catlets.ShareJoin */ select a.id,a.user_id,a.traveldate,a.fee,a.days,b.id as nnid, b.title as
tit from travelrecord a join hotnews b on b.id=a.days order by a.id
4.1.4 catlet(人工智能)
解决跨分片的 SQL JOIN 的问题,远比想象的复杂,而且往往无法实现高效的处理,既然如此,就依靠人工
的智力,去编程解决业务系统中特定几个必须跨分片的 SQL 的 JOIN 逻辑,MyCAT 提供特定的 API 供程序员调
用,这就是 MyCAT 创新性的思路——人工智能。
以一个跨节点的 SQL 为例。
Select a.id,a.name,b.title from a,b where a.id=b.id
其中 a 在分片 1,2,3 上,b 在 4,5,6 上,需要把数据全部拉到本地(MyCAT 服务器),执行 JOIN 逻
辑,具体过程如下(只是一种可能的执行逻辑):
EngineCtx ctx=new EngineCtx();//包含 MyCat.SQLEngine
String sql=,“select a.id ,a.name from a ”;
//在 a 表所在的所有分片上顺序执行下面的本地 SQL
ctx.executeNativeSQLSequnceJob(allAnodes,new DirectDBJoinHandler());
DirectDBJoinHandler 类是一个回调类,负责处理 SQL 执行过程中返回的数据包,这里的这个类,主要目的
是用 a 表返回的 ID 信息,去 b 表上查询对于的记录,做实时的关联:
DirectDBJoinHandler{
Private HashMap
a.id,a.name,b.title 这三个要输出的字段
104
Public Boolean onHeader(byte[] header)
{
//保存 Header 信息,用于从 Row 中获取 Field 字段值
}
Public Boolean onRowData(byte[] rowData)
{
String id=getColumnAsString(“id”);
//放入结果集,b.title 字段未知,所以先空着
rows.put(getColumnRawBytes(“id”),rowData);
//满 1000 条,发送一个查询请求
String sql=”select b.id, b.name from b where id in (………….)”;
//此 SQL 在 B 的所有节点上并发执行,返回的结果直接输出到客户端
ctx.executeNativeSQLParallJob(allBNodes,sql ,new MyRowOutPutDataHandler(rows));
}
Public Boolean onRowFinished()
{
}
Public void onJobFinished()
{
If(ctx.allJobFinished())
{///used total time ….
}
}
}
最后,增加一个 Job 事件监听器,这里是所有 Job 完成后,往客户端发送 RowEnd 包,结束整个流程。
ctx.setJobEventListener(new JobEventHandler(){public void onJobFinished(){ client.writeRowEndPackage()}});
以上提供一个 SQL 执行框架,完全是异步的模式执行,并且以后会提供更多高质量的 API,简化分布式数据
处理,比如内存结合文件的数据 JOIN 算法,分组算法,排序算法等等,期待更多的牛人一起来完善。
4.1.5 Spark/Storm 对 join 扩展
看到这个标题,可能会感到很奇怪,Spark 和 Storm 和 Join 有关系吗? 有必要用 Spark,storm 吗?
mycat 后续的功能会引入 spark 和 storm 来做跨分片的 join,大致流程是这样的在 mycat 调用 spark,storm
的 api,把数据传送到 spark,storm,在 spark,storm 进行 join,在把数据传回 mycat,mycat 在返回给客户端。

4.1.6 两个表标准 Join 的支持
两个表标准 Join 主要包括八方面内容:
两个分片规则,分片都相同的表之间 JOIN
一个分片表和一个全局表之间 JOIN
两表 JOIN 作为子表
待完善
两个分片规则相同,分片不同的表之间 JOIN
两个分片规则不同的表之间 JOIN
一个分片表和一个本地表之间 JOIN
一个本地表和一个全局表之间 JOIN
分布式 JOIN 算法的设计开发
1. 测试计划
1) 在 DB 服务器上新建四个库,库名为 htdb,htdb1,htdb2,htdb3。
2) Htdb 中存放非分片表数据。
3) Htdb1,htdb2,htdb3 三个库用于存放分片表数据。
2. 测试实施
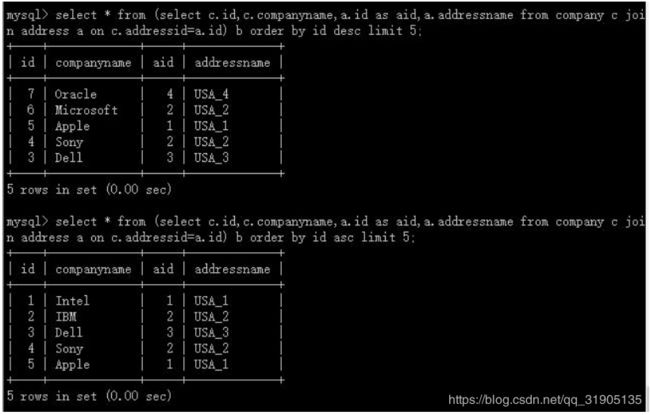
两个分片规则,分片都相同的表之间 JOIN
配置分片规则
准备测试数据
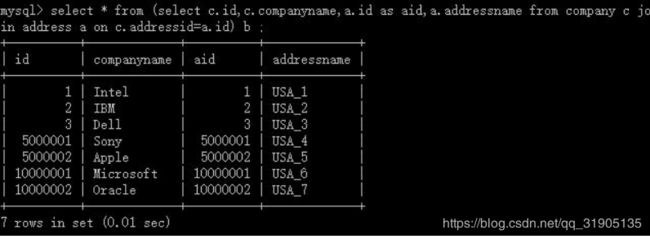
create table company(id int primary key, companyname varchar(20), addressid int);
create table address(id int primary key, addressname varchar(20));
insert into company(id,companyname,addressid) values(1, 'Intel', 1),(2, 'IBM', 2),(3, 'Dell',
3),(5000001, 'Sony', 5000001),(5000002, 'Apple', 5000002),(10000001, 'Microsoft',
10000001),(10000002, 'Oracle', 10000002);
insert into address(id,addressname) values(1, 'USA_1'),(2, 'USA_2'),(3, 'USA_3'),(5000001,
'USA_4'),(5000002, 'USA_5'),(10000001, 'USA_6'),(10000002, 'USA_7');
测试结果:
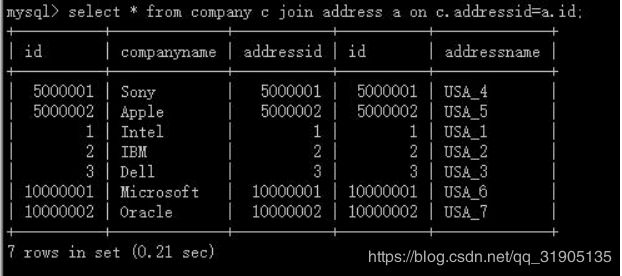
符合规则
一个分片表和一个全局表之间 JOIN
配置分片规则
准备测试数据
create table company(id int primary key, companyname varchar(20), addressid int);
create table address(id int primary key, addressname varchar(20));
insert into company(id,companyname,addressid) values(1, 'Intel', 1),(2, 'IBM', 2),(3, 'Dell', 3),(5000001,
'Sony', 5000001),(5000002, 'Apple', 5000002),(10000001, 'Microsoft', 10000001),(10000002, 'Oracle',
10000002);
insert into address(id,addressname) values(1, 'USA_1'),(2, 'USA_2'),(3, 'USA_3'),(5000001,
'USA_4'),(5000002, 'USA_5'),(10000001, 'USA_6'),(10000002, 'USA_7'),(15000001,
'USA_8'),(15000002, 'USA_9');
测试结果
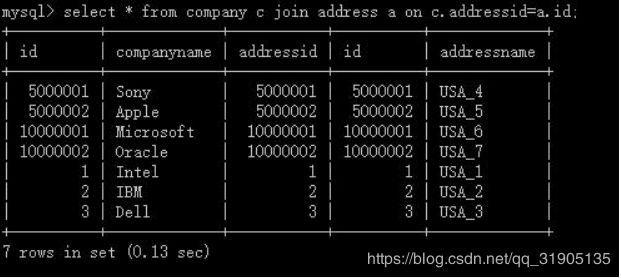
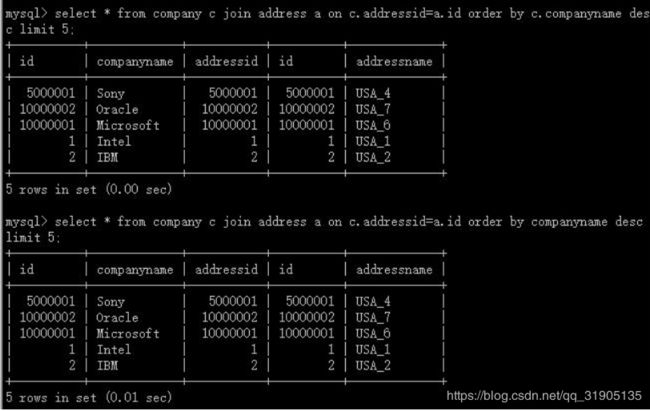
结果相同,符合规则
两表 JOIN 作为子表
配置分片规则
准备测试数据
create table company(id int primary key, companyname varchar(20), addressid int);
create table address(id int primary key, addressname varchar(20));
insert into company(id,companyname,addressid) values(1, 'Intel', 1),(2, 'IBM', 2),(3, 'Dell', 3),(5000001,
'Sony', 5000001),(5000002, 'Apple', 5000002),(10000001, 'Microsoft', 10000001),(10000002, 'Oracle',
10000002);
insert into address(id,addressname) values(1, 'USA_1'),(2, 'USA_2'),(3, 'USA_3'),(5000001,
'USA_4'),(5000002, 'USA_5'),(10000001, 'USA_6'),(10000002, 'USA_7');
测试结果
符合规则
5.1.1 全局序列号介绍
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。为此,MyCat 提供了全局
sequence,并且提供了包含本地配置和数据库配置等多种实现方式。
5.1.2 本地文件方式
原理:此方式 MyCAT 将 sequence 配置到文件中,当使用到 sequence 中的配置后,MyCAT 会更下
classpath 中的 sequence_conf.properties 文件中 sequence 当前的值。
配置方式:
在 sequence_conf.properties 文件中做如下配置:
GLOBAL_SEQ.HISIDS=
GLOBAL_SEQ.MINID=1001
GLOBAL_SEQ.MAXID=1000000000
GLOBAL_SEQ.CURID=1000
其中 HISIDS 表示使用过的历史分段(一般无特殊需要可不配置),MINID 表示最小 ID 值,MAXID 表示最大
ID 值,CURID 表示当前 ID 值。
server.xml 中配置:
注:sequnceHandlerType 需要配置为 0,表示使用本地文件方式。
使用示例:
insert into table1(id,name) values( 1188460863003168768,‘test’);
缺点:当 MyCAT 重新发布后,配置文件中的 sequence 会恢复到初始值。
优点:本地加载,读取速度较快。
5.1.3 数据库方式
原理
在数据库中建立一张表,存放 sequence 名称(name),sequence 当前值(current_value),步长(increment
int 类型每次读取多少个 sequence,假设为 K)等信息;
Sequence 获取步骤:
1).当初次使用该 sequence 时,根据传入的 sequence 名称,从数据库这张表中读取 current_value,和
increment 到 MyCat 中,并将数据库中的 current_value 设置为原 current_value 值+increment 值。
111
.MyCat 将读取到 current_value+increment 作为本次要使用的 sequence 值,下次使用时,自动加 1,当
使用 increment 次后,执行步骤 1)相同的操作。
MyCat 负责维护这张表,用到哪些 sequence,只需要在这张表中插入一条记录即可。若某次读取的
sequence 没有用完,系统就停掉了,则这次读取的 sequence 剩余值不会再使用。
配置方式:
server.xml 配置:
注:sequnceHandlerType 需要配置为 1,表示使用数据库方式生成 sequence。
数据库配置:
1) 创建 MYCAT_SEQUENCE 表
– 创建存放 sequence 的表
DROP TABLE IF EXISTS MYCAT_SEQUENCE;
– name sequence 名称
– current_value 当前 value
– increment 增长步长! 可理解为 mycat 在数据库中一次读取多少个 sequence. 当这些用完后, 下次再从数
据库中读取。
CREATE TABLE MYCAT_SEQUENCE (name VARCHAR(50) NOT NULL,current_value INT NOT
NULL,increment INT NOT NULL DEFAULT 100, PRIMARY KEY(name)) ENGINE=InnoDB;
– 插入一条 sequence
INSERT INTO MYCAT_SEQUENCE(name,current_value,increment) VALUES (‘GLOBAL’, 100000,
100);
2) 创建相关 function
– 获取当前 sequence 的值 (返回当前值,增量)
DROP FUNCTION IF EXISTS mycat_seq_currval;
DELIMITER
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS varchar(64) CHARSET
utf-8
112
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval=“-999999999,null”;
SELECT concat(CAST(current_value AS CHAR),“,”,CAST(increment AS CHAR)) INTO retval FROM
MYCAT_SEQUENCE WHERE name = seq_name;
RETURN retval;
END
DELIMITER;
– 设置 sequence 值
DROP FUNCTION IF EXISTS mycat_seq_setval;
DELIMITER
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),value INTEGER) RETURNS varchar(64)
CHARSET utf-8
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = value
WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END
DELIMITER;
– 获取下一个 sequence 值
DROP FUNCTION IF EXISTS mycat_seq_nextval;
DELIMITER
CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS varchar(64) CHARSET
utf-8
113
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END
DELIMITER;
4) sequence_db_conf.properties 相关配置,指定 sequence 相关配置在哪个节点上:
例如:
USER_SEQ=test_dn1
注意:MYCAT_SEQUENCE 表和以上的 3 个 function,需要放在同一个节点上。function 请直接在具体节
点的数据库上执行,如果执行的时候报:
you might want to use the less safe log_bin_trust_function_creators variable
需要对数据库做如下设置:
windows 下 my.ini[mysqld]加上 log_bin_trust_function_creators=1
linux 下/etc/my.cnf 下 my.ini[mysqld]加上 log_bin_trust_function_creators=1
修改完后,即可在 mysql 数据库中执行上面的函数。
使用示例:
insert into table1(id,name) values( 1188460863007363072,‘test’);
5.1.4本地时间戳方式
ID= 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加)
换算成十进制为 18 位数的 long 类型,每毫秒可以并发 12 位二进制的累加。
使用方式:
a. 配置 server.xml
b. 在 mycat 下配置:sequence_time_conf.properties
WORKID=0-31 任意整数
114
DATAACENTERID=0-31 任意整数
多个个 mycat 节点下每个 mycat 配置的 WORKID,DATAACENTERID 不同,组成唯一标识,总共支持
32*32=1024 种组合。
ID 示例:56763083475511
5.1.5 分布式 ZK ID 生成器
Zk 的连接信息统一在 myid.properties 的 zkURL 属性中配置。
基于 ZK 与本地配置的分布式 ID 生成器(可以通过 ZK 获取集群(机房)唯一 InstanceID,也可以通过配置文
件配置 InstanceID)
ID 结构:long 64 位,ID 最大可占 63 位
* |current time millis(微秒时间戳 38 位,可以使用 17 年)|clusterId(机房或者 ZKid,通过配置文件配置 5
位)|instanceId(实例 ID,可以通过 ZK 或者配置文件获取,5 位)|threadId(线程 ID,9 位)
|increment(自增,6 位)
* 一共 63 位,可以承受单机房单机器单线程 1000*(2^6)=640000 的并发。
* 一共 63 位,可以承受单机房单机器单线程 1000*(2^7)=1280000 的并发。
* 无悲观锁,无强竞争,吞吐量更高
配置文件:sequence_distributed_conf.properties,只要配置里面:INSTANCEID=ZK 就是从 ZK 上获取
InstanceID
5.1.6 Zk 递增方式
Zk 的连接信息统一在 myid.properties 的 zkURL 属性中配置。
4 是 zookeeper 实现递增序列号
* 配置文件:sequence_conf.properties
* 只要配置好 ZK 地址和表名的如下属性
* TABLE.MINID 某线程当前区间内最小值
* TABLE.MAXID 某线程当前区间内最大值
* TABLE.CURID 某线程当前区间内当前值
* 文件配置的 MAXID 以及 MINID 决定每次取得区间,这个对于每个线程或者进程都有效
* 文件中的这三个属性配置只对第一个进程的第一个线程有效,其他线程和进程会动态读取 ZK
5.1.7 其他方式
1) 使用 catelet 注解方式
/*!mycat:catlet=demo.catlets.BatchGetSequence */SELECT mycat_get_seq(‘GLOBAL’,100);
注:此方法表示获取 GLOBAL 的 100 个 sequence 值,例如当前 GLOBAL 的最大 sequence 值为 5000,
则通过此方式返回的是 5001,同时更新数据库中的 BLOBAL 的最大 sequence 值为 5100。
2) 利用 zookeeper 方式实现
5.1.8 自增长主键
MyCAT 自增长主键和返回生成主键 ID 的实现
说明:
1) mysql 本身对非自增长主键,使用 last_insert_id()是不会返回结果的,只会返回 0;
2) mysql 只会对定义自增长主键,可以用 last_insert_id()返回主键值;
MyCAT 目前提供了自增长主键功能,但是如果对应的 mysql 节点上数据表,没有定义 auto_increment,
那么在 MyCAT 层调用 last_insert_id()也是不会返回结果的。
正确配置方式如下:
1) mysql 定义自增主键
CREATE TABLE table1(
‘id_’ INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
‘name_’ INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (‘id_’)
) ENGINE=MYISAM AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
2) mycat 定义主键自增
3) mycat 对应 sequence_db_conf.properties 增加相应设置
TABLE1=dn1
4) 在数据库中 mycat_sequence 表中增加 TABLE1 表的 sequence 记录
测试使用:
127.0.0.1/root:[TESTDB> insert into tt2(name_) values(‘t1’);
Query OK, 1 row affected (0.14 sec)
127.0.0.1/root:[TESTDB> select last_insert_id();
+——————+
| LAST_INSERT_ID() |
+——————+
| 100 |
+——————+
1 row in set (0.01 sec)
127.0.0.1/root:[TESTDB> insert into tt2(name_) values(‘t2’);
Query OK, 1 row affected (0.00 sec)
117
127.0.0.1/root:[TESTDB> select last_insert_id();
+——————+
| LAST_INSERT_ID() |
+——————+
| 101 |
+——————+
1 row in set (0.00 sec)
127.0.0.1/root:[TESTDB> insert into tt2(name_) values(‘t3’);
Query OK, 1 row affected (0.00 sec)
127.0.0.1/root:[TESTDB> select last_insert_id();
+——————+
| LAST_INSERT_ID() |
+——————+
| 102 |
+——————+
1 row in set (0.00 sec)
Myibatis 中新增记录后获取 last_insert_id 的示例:
6.1 分片规则
在数据切分处理中,特别是水平切分中,中间件最终要的两个处理过程就是数据的切分、数据的聚合。选择
合适的切分规则,至关重要,因为它决定了后续数据聚合的难易程度,甚至可以避免跨库的数据聚合处理。
前面讲了数据切分中重要的几条原则,其中有几条是数据冗余,表分组(Table Group),这都是业务上规
避跨库 join 的很好的方式,但不是所有的业务场景都适合这样的规则,因此本章将讲述如何选择合适的切分规
则。
6.1.1 Mycat 全局表
如果你的业务中有些数据类似于数据字典,比如配置文件的配置,常用业务的配置或者数据量不大很少变动
的表,这些表往往不是特别大,而且大部分的业务场景都会用到,那么这种表适合于 Mycat 全局表,无须对数据
进行切分,只要在所有的分片上保存一份数据即可,Mycat 在 Join 操作中,业务表与全局表进行 Join 聚合会优
先选择相同分片内的全局表 join,避免跨库 Join,在进行数据插入操作时,mycat 将把数据分发到全局表对应的
所有分片执行,在进行数据读取时候将会随机获取一个节点读取数据。
目前 Mycat 没有做全局表的数据一致性检查,后续版本 1.4 之后可能会提供全局表一致性检查,检查每个分
片的数据一致性。
全局表的配置如下
6.1.2 ER 分片表
有一类业务,例如订单(order)跟订单明细(order_detail),明细表会依赖于订单,也就是说会存在表的主
从关系,这类似业务的切分可以抽象出合适的切分规则,比如根据用户 ID 切分,其他相关的表都依赖于用户 ID,
再或者根据订单 ID 切分,总之部分业务总会可以抽象出父子关系的表。这类表适用于 ER 分片表,子表的记录与
所关联的父表记录存放在同一个数据分片上,避免数据 Join 跨库操作。
以 order 与 order_detail 例子为例,schema.xml 中定义如下的分片配置,order,order_detail 根据 order_id
进行数据切分,保证相同 order_id 的数据分到同一个分片上,在进行数据插入操作时,Mycat 会获取 order 所在
的分片,然后将 order_detail 也插入到 order 所在的分片。
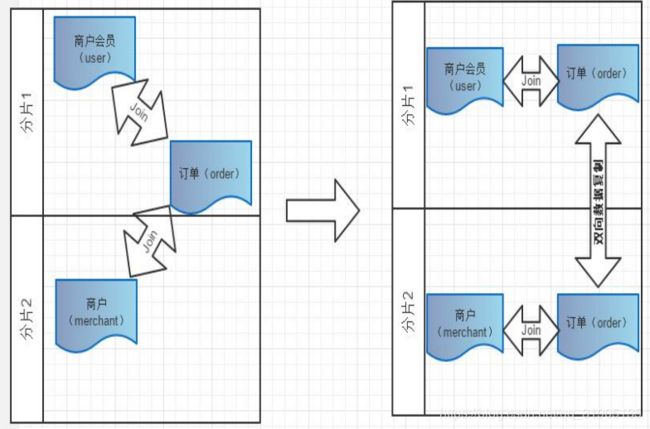
6.1.3 多对多关联
有一类业务场景是 “主表 A+关系表+主表 B”,举例来说就是商户会员+订单+商户,对应这类业务,如何
切分?
从会员的角度,如果需要查询会员购买的订单,那按照会员进行切分即可,但是如果要查询商户当天售出的
订单,那又需要按照商户做切分,可是如果既要按照会员又要按照商户切分,几乎是无法实现,这类业务如何选
择切分规则非常难。目前还暂时无法很好支持这种模式下的 3 个表之间的关联。目前总的原则是需要从业务角度
来看,关系表更偏向哪个表,即“A 的关系”还是“B 的关系”,来决定关系表跟从那个方向存储,未来 Mycat
版本中将考虑将中间表进行双向复制,以实现从 A-关系表 以及 B-关系表的双向关联查询如下图所示:
6.1.4 主键分片 vs 非主键分片
当你没人任何字段可以作为分片字段的时候,主键分片就是唯一选择,其优点是按照主键的查询最快,当采
用自动增长的序列号作为主键时,还能比较均匀的将数据分片在不同的节点上。
若有某个合适的业务字段比较合适作为分片字段,则建议采用此业务字段分片,选择分片字段的条件如下:
120
尽可能的比较均匀分布数据到各个节点上;
该业务字段是最频繁的或者最重要的查询条件。
常见的除了主键之外的其他可能分片字段有“订单创建时间”、“店铺类别”或“所在省”等。当你找到某
个合适的业务字段作为分片字段以后,不必纠结于“牺牲了按主键查询记录的性能”,因为在这种情况下,
MyCAT 提供了“主键到分片”的内存缓存机制,热点数据按照主键查询,丝毫不损失性能。
对于非主键分片的 table,填写属性 primaryKey,此时 MyCAT 会将你根据主键查询的 SQL 语句的第一次执
行结果进行分析,确定该 Table 的某个主键在什么分片上,并进行主键到分片 ID 的缓存。第二次或后续查询
mycat 会优先从缓存中查询是否有 id–>node 即主键到分片的映射,如果有直接查询,通过此种方法提高了非主
键分片的查询性能。
本节主要讲了如何去分片,如何选择合适分片的规则,总之尽量规避跨库 Join 是一条最重要的原则,下一节
将介绍 Mycat 目前已有的分片规则,每种规则都有特定的场景,分析每种规则去选择合适的应用到项目中。
6.1.5 Mycat 常用的分片规则
1.分片枚举
通过在配置文件中配置可能的枚举 id,自己配置分片,本规则适用于特定的场景,比如有些业务需要按照省
份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则,配置如下:
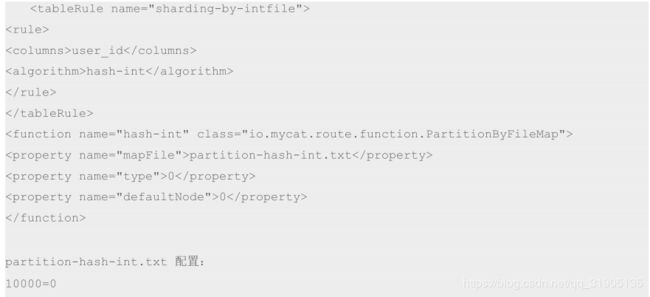

上面 columns 标识将要分片的表字段,algorithm 分片函数,
其中分片函数配置中,mapFile 标识配置文件名称,type 默认值为 0,0 表示 Integer,非零表示 String,
所有的节点配置都是从 0 开始,及 0 代表节点 1
/**
* defaultNode 默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点
* 默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点
* 如果不配置默认节点(defaultNode 值小于 0 表示不配置默认节点),碰到
* 不识别的枚举值就会报错,
* like this:can’t find datanode for sharding column:column_name val:ffffffff
*/
2. 固定分片 hash 算法
本条规则类似于十进制的求模运算,区别在于是二进制的操作,是取 id 的二进制低 10 位,即 id 二进制
&1111111111。
此算法的优点在于如果按照 10 进制取模运算,在连续插入 1-10 时候 1-10 会被分到 1-10 个分片,增
大了插入的事务控制难度,而此算法根据二进制则可能会分到连续的分片,减少插入事务事务控制难度。
配置说明:
上面 columns 标识将要分片的表字段,algorithm 分片函数,
partitionCount 分片个数列表,partitionLength 分片范围列表
分区长度:默认为最大 2^n=1024 ,即最大支持 1024 分区
约束 :
count,length 两个数组的长度必须是一致的。
1024 = sum((count[i]*length[i])). count 和 length 两个向量的点积恒等于 1024
用法例子:
本例的分区策略:希望将数据水平分成 3 份,前两份各占 25%,第三份占 50%。(故本例非均匀分区)
// |<———————1024———————————>|
122
// |<—-256—>|<—-256—>|<———-512————->|
// | partition0 | partition1 | partition2 |
// | 共 2 份,故 count[0]=2 | 共 1 份,故 count[1]=1 |
int[] count = new int[] { 2, 1 };
int[] length = new int[] { 256, 512 };
PartitionUtil pu = new PartitionUtil(count, length);
// 下面代码演示分别以 offerId 字段或 memberId 字段根据上述分区策略拆分的分配结果
int DEFAULT_STR_HEAD_LEN = 8; // cobar 默认会配置为此值
long offerId = 12345;
String memberId = "qiushuo";
// 若根据 offerId 分配,partNo1 将等于 0,即按照上述分区策略,offerId 为 12345 时将会被分配
到 partition0 中
int partNo1 = pu.partition(offerId);
// 若根据 memberId 分配,partNo2 将等于 2,即按照上述分区策略,memberId 为 qiushuo 时将会被
分到 partition2 中
int partNo2 = pu.partition(memberId, 0, DEFAULT_STR_HEAD_LEN);
如果需要平均分配设置:平均分为 4 分片,partitionCount*partitionLength=1024
3.范围约定
此分片适用于,提前规划好分片字段某个范围属于哪个分片,
start <= range <= end.
range start-end ,data node index
K=1000,M=10000.
配置说明:
上面 columns 标识将要分片的表字段,algorithm 分片函数,
rang-long 函数中 mapFile 代表配置文件路径
defaultNode 超过范围后的默认节点。
所有的节点配置都是从 0 开始,及 0 代表节点 1,此配置非常简单,即预先制定可能的 id 范围到某个分片
0-500M=0
500M-1000M=1
1000M-1500M=2
或
0-10000000=0
10000001-20000000=1
4.取模
此规则为对分片字段求摸运算。
user_id
mod-long
3
配置说明:
上面 columns 标识将要分片的表字段,algorithm 分片函数,
此种配置非常明确即根据 id 进行十进制求模预算,相比固定分片 hash,此种在批量插入时可能存在批量插入单
事务插入多数据分片,增大事务一致性难度。
5.按日期(天)分片
此规则为按天分片
create_time
sharding-by-date
yyyy-MM-dd
2014-01-01
124
2014-01-02
10
配置说明:
columns :标识将要分片的表字段
algorithm :分片函数
dateFormat :日期格式
sBeginDate :开始日期
sEndDate:结束日期
sPartionDay :分区天数,即默认从开始日期算起,分隔 10 天一个分区
如果配置了 sEndDate 则代表数据达到了这个日期的分片后后循环从开始分片插入。
Assert.assertEquals(true, 0 == partition.calculate(“2014-01-01”));
Assert.assertEquals(true, 0 == partition.calculate(“2014-01-10”));
Assert.assertEquals(true, 1 == partition.calculate(“2014-01-11”));
Assert.assertEquals(true, 12 == partition.calculate(“2014-05-01”));
6. 取模范围约束
此种规则是取模运算与范围约束的结合,主要为了后续数据迁移做准备,即可以自主决定取模后数据的节点
分布。
user_id
sharding-by-pattern
class="io.mycat.route.function.PartitionByPattern">
256
2
partition-pattern.txt
partition-pattern.txt
# id partition range start-end ,data node index
###### first host configuration
1-32=0
33-64=1
65-96=2
125
97-128=3
######## second host configuration
129-160=4
161-192=5
193-224=6
225-256=7
0-0=7
配置说明:
上面 columns 标识将要分片的表字段,algorithm 分片函数,patternValue 即求模基数,defaoultNode
默认节点,如果配置了默认,则不会按照求模运算
mapFile 配置文件路径
配置文件中,1-32 即代表 id%256 后分布的范围,如果在 1-32 则在分区 1,其他类推,如果 id 非数据,则
会分配在 defaoultNode 默认节点
String idVal = “0”;
Assert.assertEquals(true, 7 == autoPartition.calculate(idVal));
idVal = “45a”;
Assert.assertEquals(true, 2 == autoPartition.calculate(idVal));
7.截取数字做 hash 求模范围约束
此种规则类似于取模范围约束,此规则支持数据符号字母取模。
user_id
sharding-by-prefixpattern
class="io.mycat.route.function.PartitionByPrefixPattern">
256
5
partition-pattern.txt
partition-pattern.txt
# range start-end ,data node index
# ASCII
# 8-57=0-9 阿拉伯数字
# 64、65-90=@、A-Z
# 97-122=a-z
###### first host configuration
1-4=0
5-8=1
9-12=2
13-16=3
###### second host configuration
17-20=4
21-24=5
25-28=6
29-32=7
0-0=7
配置说明:
上面 columns 标识将要分片的表字段,algorithm 分片函数,patternValue 即求模基数,prefixLength
ASCII 截取的位数
mapFile 配置文件路径
配置文件中,1-32 即代表 id%256 后分布的范围,如果在 1-32 则在分区 1,其他类推
此种方式类似方式 6 只不过采取的是将列种获取前 prefixLength 位列所有 ASCII 码的和进行求模
sum%patternValue ,获取的值,在范围内的分片数,
String idVal=“gf89f9a”;
Assert.assertEquals(true, 0==autoPartition.calculate(idVal));
idVal=“8df99a”;
Assert.assertEquals(true, 4==autoPartition.calculate(idVal));
idVal=“8dhdf99a”;
Assert.assertEquals(true, 3==autoPartition.calculate(idVal));
8.应用指定
此规则是在运行阶段有应用自主决定路由到那个分片
user_id
sharding-by-substring
class="io.mycat.route.function.PartitionDirectBySubString">
0
2
8
0
配置说明:
上面 columns 标识将要分片的表字段,algorithm 分片函数
此方法为直接根据字符子串(必须是数字)计算分区号(由应用传递参数,显式指定分区号)。
例如 id=05-100000002
在此配置中代表根据 id 中从 startIndex=0,开始,截取 siz=2 位数字即 05,05 就是获取的分区,如果没传
默认分配到 defaultPartition
9.截取数字 hash 解析
此规则是截取字符串中的 int 数值 hash 分片。
user_id
sharding-by-stringhash
class="io.mycat.route.function.PartitionByString">
512
2
0:2
配置说明:
上面 columns 标识将要分片的表字段,algorithm 分片函数
函数中 partitionLength 代表字符串 hash 求模基数,
partitionCount 分区数,
hashSlice hash 预算位,即根据子字符串中 int 值 hash 运算
hashSlice : 0 means str.length(), -1 means str.length()-1
/**
* “2” -> (0,2)
* “1:2” -> (1,2)
* “1:” -> (1,0)
* “-1:” -> (-1,0)
128
* “:-1” -> (0,-1)
* “:” -> (0,0)
*/
例子:
String idVal=null;
rule.setPartitionLength("512");
rule.setPartitionCount("2");
rule.init();
rule.setHashSlice("0:2");
// idVal = "0";
// Assert.assertEquals(true, 0 == rule.calculate(idVal));
// idVal = "45a";
// Assert.assertEquals(true, 1 == rule.calculate(idVal));
//last 4
rule = new PartitionByString();
rule.setPartitionLength("512");
rule.setPartitionCount("2");
rule.init();
//last 4 characters
rule.setHashSlice("-4:0");
idVal = "aaaabbb0000";
Assert.assertEquals(true, 0 == rule.calculate(idVal));
idVal = "aaaabbb2359";
Assert.assertEquals(true, 0 == rule.calculate(idVal));
10 一致性 hash
一致性 hash 预算有效解决了分布式数据的扩容问题。
11 按单月小时拆分
此规则是单月内按照小时拆分,最小粒度是小时,可以一天最多 24 个分片,最少 1 个分片,一个月完后下月
从头开始循环。
每个月月尾,需要手工清理数据
create_time
sharding-by-hour
24
配置说明:
columns: 拆分字段,字符串类型(yyyymmddHH)
splitOneDay : 一天切分的分片数
LatestMonthPartion partion = new LatestMonthPartion();
partion.setSplitOneDay(24);
Integer val = partion.calculate("2015020100");
assertTrue(val == 0);
val = partion.calculate("2015020216");
assertTrue(val == 40);
val = partion.calculate("2015022823");
assertTrue(val == 27 * 24 + 23);
Integer[] span = partion.calculateRange("2015020100", "2015022823");
assertTrue(span.length == 27 * 24 + 23 + 1);
assertTrue(span[0] == 0 && span[span.length - 1] == 27 * 24 + 23);
span = partion.calculateRange("2015020100", "2015020123");
assertTrue(span.length == 24);
assertTrue(span[0] == 0 && span[span.length - 1] == 23);
12.范围求模分片
先进行范围分片计算出分片组,组内再求模
优点可以避免扩容时的数据迁移,又可以一定程度上避免范围分片的热点问题
综合了范围分片和求模分片的优点,分片组内使用求模可以保证组内数据比较均匀,分片组之间是范围分片可以
兼顾范围查询。
最好事先规划好分片的数量,数据扩容时按分片组扩容,则原有分片组的数据不需要迁移。由于分片组内数据比
较均匀,所以分片组内可以避免热点数据问题。
id
rang-mod
class="io.mycat.route.function.PartitionByRangeMod">
partition-range-mod.txt
21
配置说明:
上面 columns 标识将要分片的表字段,algorithm 分片函数,
rang-mod 函数中 mapFile 代表配置文件路径
defaultNode 超过范围后的默认节点顺序号,节点从 0 开始。
partition-range-mod.txt
range start-end ,data node group size
以下配置一个范围代表一个分片组,=号后面的数字代表该分片组所拥有的分片的数量。
0-200M=5 //代表有 5 个分片节点
200M1-400M=1
400M1-600M=4
600M1-800M=4
800M1-1000M=6
13. 日期范围 hash 分片
思想与范围求模一致,当由于日期在取模会有数据集中问题,所以改成 hash 方法。
先根据日期分组,再根据时间 hash 使得短期内数据分布的更均匀
优点可以避免扩容时的数据迁移,又可以一定程度上避免范围分片的热点问题
要求日期格式尽量精确些,不然达不到局部均匀的目的
< tableRule name="rangeDateHash">
sPartionDay 代表多少天分一个分片
groupPartionSize 代表分片组的大小
14 .冷热数据分片
根据日期查询日志数据 冷热数据分布 ,最近 n 个月的到实时交易库查询,超过 n 个月的按照 m 天分片。
15. 自然月分片
按月份列分区 ,每个自然月一个分片,格式 between 操作解析的范例。
配置说明:
columns: 分片字段,字符串类型
dateFormat : 日期字符串格式,默认为 yyyy-MM-dd
sBeginDate : 开始日期,无默认值
sEndDate:结束日期,无默认值
节点从 0 开始分片
使用场景:
场景 1:
默认设置;节点数量必须是 12 个,从 1 月~12 月
"2014-01-01" = 节点 0
"2013-01-01" = 节点 0
"2018-05-01" = 节点 4
"2019-12-01" = 节点 11
场景 2:
sBeginDate = "2017-01-01"
该配置表示"2017-01 月"是第 0 个节点,从该时间按月递增,无最大节点
"2014-01-01" = 未找到节点
"2017-01-01" = 节点 0
"2017-12-01" = 节点 11
"2018-01-01" = 节点 12
"2018-12-01" = 节点 23
场景 3:
sBeginDate = "2015-01-01"sEndDate = "2015-12-01"
该配置可看成与场景 1 一致;场景 1 的配置效率更高
"2014-01-01" = 节点 0
"2014-02-01" = 节点 1
"2015-02-01" = 节点 1
"2017-01-01" = 节点 0
"2017-12-01" = 节点 11
"2018-12-01" = 节点 11
该配置可看成是与场景 1 一致
场景 4:
sBeginDate = "2015-01-01"sEndDate = "2015-03-01"
该配置标识只有 3 个节点;很难与月份对应上;平均分散到 3 个节点上
自然月分片算法功能测试用例:
PartitionByMonth partition = new PartitionByMonth();
partition.setDateFormat("yyyy-MM-dd");
partition.setsBeginDate("2014-01-01");
partition.init();
Assert.assertEquals(true, 0 == partition.calculate("2014-01-01"));
Assert.assertEquals(true, 0 == partition.calculate("2014-01-10"));
Assert.assertEquals(true, 0 == partition.calculate("2014-01-31"));
Assert.assertEquals(true, 1 == partition.calculate("2014-02-01"));
Assert.assertEquals(true, 1 == partition.calculate("2014-02-28"));
Assert.assertEquals(true, 2 == partition.calculate("2014-03-1"));
Assert.assertEquals(true, 11 == partition.calculate("2014-12-31"));
Assert.assertEquals(true, 12 == partition.calculate("2015-01-31"));
Assert.assertEquals(true, 23 == partition.calculate("2015-12-31"));
16 .有状态分片算法
有状态分片算法与之前的分片算法不同,它是为(在线)数据自动迁移而设计的.
数据自动迁移分片算法需要满足一致性哈希的要求,尤其是单调性。
直至 2018 年 7 月 24 日为止,现支持有状态算法的分片策略只有 crc32slot 欢迎大家提供更多有状态分片算法.
一个有状态分片算法在使用过程中暂时存在两个操作
一种是初始化,使用 mycat 创建配置带有有状态分片算法的 table 时(推介)或者第一次配置有状态分片算法的
table 并启动 mycat 时,有状态分片算法会根据表的 dataNode 的数量划分分片范围并生成 ruledata 下的文件,
这个分片范围规则就是’状态’,一个表对应一个状态,对应一个有状态分片算法实例,以及对应一个满足以下命
名规则的文件:
算法名字_schema 名字_table 名字.properties
文件里内容一般具有以下特征
8 8= 91016-102399
7 7= 79639-91015
6 6= 68262-79638
5 5= 56885-68261
4 4= 45508-56884
3 3= 34131-45507
2 2= 22754-34130
1 1= 11377-22753
0 0= 0-11376
行数就是 table 的分片节点数量,每行的’数字-数字’就是分片算法生成的范围,这个范围与具体算法实现有关,一
个分片节点可能存在多个范围,这些范围以逗号,分隔.一般来说,不要手动更改这个文件,应该使用算法生成范围,而
且需要注意的是,物理库上的数据的分片字段的值一定要落在对应范围里.
一种是添加操作,即数据扩容,具体参考第六章的 6.8 与 6.9
添加节点,有状态分片算法根据节点的变化,重新分配范围规则,之后执行数据自动迁移任务.
17 .crc32slot 分片算法
crc32solt 是有状态分片算法的实现之一,是一致性哈希,具体参考第六章 数据自动迁移方案设计
crc32(key)%102400=slot
slot 按照范围均匀分布在 dataNode 上,针对每张表进行实例化,通过一个文件记录 slot 和节点
映射关系,迁移过程中通过 zk 协调
其中需要在分片表中增加 slot 字段,用以避免迁移时重新计算,只需要迁移对应 slot 数据即可
分片最大个数为 102400 个,短期内应该够用,每分片一千万,总共可以支持一万亿数据
值得注意的是 crc32 算法对字段计算的结果与字符集有关
crc32 会根据用户指定的分片字段,即图中的 id,算出 slot 的值
< rule>
< columns>id
< algorithm>crc32slot
然后根据 slot 找到对应的节点
c public Integer calculate(String columnValue) {
f if (e ruleName == null)
w throw w new RuntimeException();
PureJavaCrc32 crc32 = w new PureJavaCrc32();
byte[] bytes = columnValue.getBytes( DEFAULT_CHARSET );
crc32.update(bytes, 0, bytes. length);
g long x = crc32.getValue();
t int slot = ( int) (x % DEFAULT_SLOTS_NUM );
this.t slot = slot;
n return rangeMap2[slot];
}
因为算法中的_slot 字段字段被算法占用,所以使用 crc32slot 的 tableRule 中的 rule 的 columns 分片字段
不能为_slot.。_slot 是为了数据自动迁移过程中不需要重复根据分片字段计算_slot 而在数据库存储层面做的数
据冗余。考虑数据冗余带来的数据存储空间与传输层面的开销与重复计算_slot 的时间开销,冗余 crc32 计算
结果是值得的。如果有特殊原因可以提供一个选项给用户选择是否创建_slot 字段.此为后续 mycat 开发的一个
任务。
配置说明:
使用 mycat 配置完表后使用 mycat 创建表。
需要注意的是,在 rule.xml 中 crc32slot 的信息请保持如下配置,不需要配置 count
USE TESTDB;
CREATE TABLE `travelrecord` (
id xxxx
xxxxxxx
) ENGINE=INNODB DEFAULT CHARSET=utf8;
7.1权限控制
7.1.1 远程连接配置(读、写权限)
目前 Mycat 对于中间件的连接控制并没有做太复杂的控制,目前只做了中间件逻辑库级别的读写权限控制
mycat
order
true
mycat
order
配置说明:
配置中 name 是应用连接中间件逻辑库的用户名。
mycat 中 password 是应用连接中间件逻辑库的密码。
order 中是应用当前连接的逻辑库中所对应的逻辑表。schemas 中可以配置一个或多个。
true 中 readOnly 是应用连接中间件逻辑库所具有的权限。true 为只读,false 为读写都有,默认为 false。
7.1.2 多租户支持
单租户就是传统的给每个租户独立部署一套 web + db 。由于租户越来越多,整个 web 部分的机器和运维成
本都非常高,因此需要改进到所有租户共享一套 web 的模式(db 部分暂不改变)。
基于此需求,我们对单租户的程序做了简单的改造实现 web 多租户共享。具体改造如下:
1.web 部分修改:
a.在用户登录时,在线程变量(ThreadLocal)中记录租户的 id
b.修改 jdbc 的实现:在提交 sql 时,从 ThreadLocal 中获取租户 id, 添加 sql 注释,把租户的 schema
放到注释中。例如:/*!mycat : schema = test_01 */ sql ;
2.在 db 前面建立 proxy 层,代理所有 web 过来的数据库请求。proxy 层是用 mycat 实现的,web 提交的 sql 过
来时在注释中指定 schema, proxy 层根据指定的 schema 转发 sql 请求。
3.Mycat 配置:
mycat
order
true
mycat
order
8.1常见问题与解决方案
8.1.1 Mycat 目前有哪些功能与特性
• 支持 SQL 92 标准;
• 支持 Mysql 集群,可以作为 Proxy 使用;
• 支持 JDBC 连接多数据库;
• 支持 NoSQL 数据库;
• 支持 galera for mysql 集群,percona-cluster 或者 mariadb cluster,提供高可用性数据分片集群;
• 自动故障切换,高可用性;
• 支持读写分离,支持 Mysql 双主多从,以及一主多从的模式;
• 支持全局表,数据自动分片到多个节点,用于高效表关联查询;
• 支持独有的基于 E-R 关系的分片策略,实现了高效的表关联查询;
• 支持一致性 Hash 分片,有效解决分片扩容难题;
• 多平台支持,部署和实施简单;
• 支持 Catelet 开发,类似数据库存储过程,用于跨分片复杂 SQL 的人工智能编码实现,143 行 Demo 完成
跨分片的两个表的 JION 查询;
• 支持 NIO 与 AIO 两种网络通信机制,Windows 下建议 AIO,Linux 下目前建议 NIO;
• 支持 Mysql 存储过程调用;
• 以插件方式支持 SQL 拦截和改写;
• 支持自增长主键、支持 Oracle 的 Sequence 机制。
Mycat 除了 Mysql 还支持哪些数据库?
答:mongodb、oracle、sqlserver 、hive 、db2 、 postgresql。
8.1.2 Mycat 目前有生产案例了么?
答:目前 Mycat 初步统计大概 600 家公司使用。
8.1.3 Mycat 稳定性与 Cobar 如何?
答:目前 Mycat 稳定性优于 Cobar,而且一直在更新,Cobar 已经停止维护,可以放心使用。
8.1.4 Mycat 支持集群么?
答:目前 Mycat 没有实现对多 Mycat 集群的支持,可以暂时使用 haproxy 来做负载,或者统计硬件负载。
8.1.5 Mycat 多主切换需要人工处理么?
答:Mycat 通过心跳检测,自主切换数据库,保证高可用性,无须手动切换。
8.1.6 Mycat 目前有多少人开发?
答:Mycat 目前开发全部是志愿者无偿支持,主要有以 leaderus 为首的 Mycat-Server 开始、以 rainbow
为首的 Mycat-web 开发、以海王星为首的产品发布及代码管理,还有以 Marshy 为首的推广。
8.1.7 Mycat 目前有哪些项目?
答:Mycat-Server :Mycat 核心服务;
Mycat-spider : Mycat 爬虫技术;
Mycat-ConfigCenter :Mycat 配置中心 ;
Mycat-BigSQL : Mycat 大数据处理(暂未更细);
Mycat-Web : Mycat 监控及 web(新版开发中) ;
Mycat-Balance :Mycat 集群负载(暂未更细)。
8.1.8 Mycat 最新的稳定版本是哪个到哪里下载?
答:打包代码:Mycat 最新稳定版是 1.5.1 ,1.6 为 aphla,下载地址是:
https://github.com/MyCATApache/Mycat-download。
文档:https://github.com/MyCATApache/Mycat-doc。
源码:https://github.com/MyCATApache/Mycat-Server。
8.1.9 Mycat 如何配置字符集?
答:在配置文件 server.xml 配置,默认配置为 utf8。
8.1.10Mycat 后台管理监控如何使用?
答:9066 端口可以用 JDBC 方式执行命令,在界面上进行管理维护,也可以通过命令行查看命令行操作。
命令行操作是:mysql -h127.0.0.1 -utest -ptest -P9066 登陆,然后执行相应命令。
8.1.11 Mycat 主键插入后应用如何获取?
答:获得自增主键,插入记录后执行 select last_insert_id()获取。
8.1.12Mycat 如何启动与加入服务?
答:目前 Mycat 暂未封装加入服务,需要自己封装。
linux 环境为:
./mycat start 启动
./mycat stop 停止
./mycat console 前台运行
./mycat restart 重启服务
./mycat pause 暂停
./mycat status 查看启动状态
window 启动为:
直接双击运行 startup_nowrap.bat ,如果闪退用 cmd 模式运行查看日志。
8.1.13Mycat 运行 sql 时经常阻塞或卡死是什么原因?
答: 如果出现执行 sql 语句长时间未返回,或卡死,请检查是否是虚机下运行或 cpu 为单核,具体解决方式
请参 考:https://github.com/MyCATApache/Mycat-Server/issues/73,如果仍旧无法解决,可以
暂时跳过,目前有些环境阻塞卡死原因未知。
8.1.14Mycat 中,旧系统数据如何迁移到 Mycat 中?
答:旧数据迁移目前可以手工导入,在 mycat 中提取配置好分配规则及后端分片数据库,然后通过 dump
或 loaddata 方式导入,后续 Mycat 就做旧数据自动数据迁移工具。
8.1.15Mycat 如何对旧分片数据迁移或扩容,支持自动扩容么?
答:目前除了一致性 hash 规则分片外其他数据迁移比较困难,目前暂时可以手工迁移,未提供自动迁移方
案,具体迁移方案情况 Mycat 权威指南对应章节。
8.1.16Mycat 支持批量插入吗?
答:目前 Mycat1.3.0.3 以后支持多 values 的批量插入,如 insert into(xxx) values(xxx),(xxx) 。
8.1.17Mycat 支持多表 Join 吗?
答:Mycat 目前支持 2 个表 Join,后续会支持多表 Join,具体 Join 请看 Mycat 权威指南对应章节。
8.1.18Mycat 启动报主机不存在的问题?
答:需要添加 ip 跟主机的映射。
8.1.19Mycat 连接会报无效数据源(Invalid datasource)?
答:例如报错:mysql> select * from company;
ERROR 3009 (HY000): java.lang.IllegalArgumentException: Invalid DataSource:0
这类错误最常见是一些配置问题例如 schema.xml 中的 dataNode 的配置和实际不符合,请先仔细检查配置
项,确保配置没有问题。如果不是配置问题,分析具体日志看出错原因,常见的有:
如果是应用连:在某些版本的 Mysql 驱动下连接 Mycat 会报错,可升级最新的驱动包试下。
如果是服务端控制台连,确认 mysql 是否开启远程连接权限,或防火墙是否设置正确,或者数据库
database 是否配置,或用户名密码是否正确。
8.1.20Mycat 使用中如何提需求或 bug?
答:bug 或新需求可以到群里提问,同时最好到 github 发起以 isuues:
https://github.com/MyCATApache/Mycat-Server/issues
8.1.21 Mycat 如何建表与创建存储过程?
答:注意注解中语句是节点的表请替换成自己表如 select 1 from 表 ,查出来的数据在那个节点往哪个节点
建
存储过程
/*!mycat: sql=select 1 from 表 */ CREATE DEFINER=`root`@`%` PROCEDURE `proc_test`() BEGIN
END ;
表:
/*!mycat: sql=select 1 from 表 */create table ttt(id int);
8.1.21 Mycat 目前有多少人维护?
答:目前初步统计有 10 人以上核心人员维护。
8.1.22 Mycat 支持的或者不支持的语句有哪些?
答:insert into,复杂子查询,3 表及其以上跨库 join 等不支持。
8.1.23 MycatJDBC 连接报 PacketTooBigException 异常
答:检查 mysqljdbc 驱动的版本,在使用 mycat1.3 和 mycat1.4 版本情况下,不要使用 jdbc5.1.37 和 38
版本的驱动,会出现如下异常报错:com.mysql.jdbc.PacketTooBigException: Packet for query is too large
(60 > -1). You can change this value on the server by setting the max_allowed_packet' variable。建议使
用 jdbc5.1.35 或者 36 的版本。
8.1.24 Mycat 中文乱码的问题
答:如果在使用 mycat 出现中文插入或者查询出现乱码,请检查三个环节的字符集设置:1)客户端环节
(应用程序、mysql 命令或图形终端工具)连接 mycat 字符集 2)mycat 连接数据库的字符集 3)数据库
(mysql,oracle)字符集。这三个环节的字符集如果配置一致,则不会出现中文乱码,其中尤其需要注意的是客
户端连接 mycat 时使用的连接字符集,通常的中文乱码问题一般都由此处设置不当引出。其中 mycat 内部默认使
用 utf8 字符集,在最初启动连接数据库时,mycat 会默认使用 utf8 去连接数据库,当客户端真正连接 mycat 访
问数据库时,mycat 会使用客户端连接使用的字符集修改它连接数据库的字符集,在 mycat 环境的管理 9066 端
口,可以通过 show @@backend 命令查看后端数据库的连接字符集,通过 show @@connection 命令查看前
端客户端的连接字符集。客户端的连接可以通过指定字符集编码或者发送 SET 命令指定连接 mycat 时
connection 使用的字符集,常见客户端连接指定字符集写法如下:
1)jdbcUrl=jdbc:mysql://localhost:8066/databaseName? characterEncoding=iso_1
2)SET character_set_client = utf8;用来指定解析客户端传递数据的编码
SET character_set_results = utf8;用来指定数据库内部处理时使用的编码
SET character_set_connection = utf8;用来指定数据返回给客户端的编码方式
3) mysql –utest –ptest –P8066 --default-character-set=gbk
8.1.25 Mycat 无法登陆 Access denied
答:Mycat 正常安装配置完成,登陆 mycat 出现以下错误:
[mysql@master ~]$ mysql -utest -ptest -P8066
ERROR 1045 (28000): Access denied for user 'test'@'localhost' (using password: YES)
请检查在 schema.xml 中的相关 dataHost 的 mysql 主机的登陆权限,一般都是因为配置的 mysql 的用户登
陆权限不符合,mysql 用户权限管理不熟悉的请自己度娘。只有一种情况例外,mycat 和 mysql 主机都部署在同
一台设备,其中主机 localhost 的权限配置正确,使用-hlocalhost 能正确登陆 mysql 但是无法登陆 mycat 的情
况,请使用-h127.0.0.1 登陆,或者本地网络实际地址,不要使用-hlocalhost,很多使用者反馈此问题,原因未
明。
8.1.26 Mycat 的分片数据插入报异常 IndexOutofBoundException
答:在一些配置了分片策略的表进行数据插入时报错,常见的报错信息如下:
java.lang.IndexOutOfBoundsException:Index:4,size:3 这类报错通常由于分片策略配置不对引起,请仔细检查
并理解分片策略的配置,例如:使用固定分片 hash 算法,PartitionByLong 策略,如果 schema.xml 里面设置的
分片数量 dataNode 和 rule.xml 配置的 partitionCount 分片个数不一致,尤其是出现分片数量 dataNode 小于
partitionCount 数量的情况,插入数据就可能会报错。很多使用者都没有仔细理解文档中对分片策略的说明,用
默认 rule.xml 配置的值,没有和自己实际使用环境进行参数核实就进行分片策略使用造成这类问题居多。
8.1.27 Mycat ER 分片子表数据插入报错
答:一般都是插入子表时出现不能找到父节点的报错。报错信息如: [Err] 1064 - can't find (root) parent
sharding node for sql:。此类 ER 表的插入操作不能做为一个事务进行数据提交,如果父子表在一个事务中进行
提交,显然在事务没有提交前子表是无法查到父表的数据的,因此就无法确定 sharding node。如果是 ER 关系
的表在插入数据时不能在同一个事务中提交数据,只能分开提交。
8.1.28 Mycat 最大内存无法调整至 4G 以上
答:mycat1.4 的 JVM 使用最大内存调整如果超过 4G 大小,不能使用 wrapper.java.maxmemory 参数,需
要使用 wrapper.java.additional 的写法,注意将 wrapper.java.maxmemory 参数注释,例如增加最大内存至
8G:wrapper.java.additional.10=-Xmx8G。
8.1.29 Mycat 使用过程中报错怎么办
答:记住无论什么时候遇到报错,如果不能第一时间理解报错的原因,首先就去看日志,无论是启动
(wrapper.log)还是运行过程中(mycat.log),请相信良好的日志是编程查错的终极必杀技。日志如果记录信
息不够,可以调整 conf/log4j.xml 中的 level 级别至 debug,所有的详细信息均会记录。另外如果在群里面提
问,尽量将环境配置信息和报错日志提供清楚,这样别人才能快速帮你定位问题。
9.1 Mycat 性能测试指南
Mycat 自身提供了一套基准性能测试工具,这套工具可以用于性能测试、疲劳测试等,包括分片表插入性能
测试、分片表查询性能测试、更新性能测试、全局表插入性能测试等基准测试工具。
这里需要说明的一点是,分片表的性能测试不同于普通单表,因为它的数据是分布在几个 Datahost 上的,因
此插入和查询,都必需要特定的工具,才能做到多个节点同时负载请求,通过观察每个主机的负载,能够确定是
否你的测试是合理和正确的。
大量测试表明,当带宽不是问题而且带宽没有占满,比如千兆网网络连接的 Mycat 和 MySQL 服务器,以及
测试客户端,(通常个人电脑到服务器的连接为 100M),分片表的性能取决于后端部署 MySQL 的物理机的个
数,比如每个 MySQL 的性能是 5 万 Tps,则 3 台理论上是 15 万,而 Mycat 能达到 80-95%之间,即 12 万以
上。
关于带宽问题,是一个比较棘手的问题,通常需要监控交换机、MySQL 服务器、Mycat 服务器、以获取测试
过程中的端口流量信息,才能确定是否带宽存在问题,另外,很多企业里,千兆交换机采用了百兆的普通网线的
情况时有发生,防不胜防,所以,在不能控制的网络环境里,测试最大性能的目标通常无法实现。
另外,很多人测试的时候,并不知道 MySQL 直连的性能,因此无法正确比较 Mycat 的性能,所以,建议性
能测试过程里,首先直连 MySQL 进行性能测试,可以同时直连多个 MYSQL 服务器,然后把测试结果累计,作
为直连的性能指标,然后改为连接 Mycat 进行测试,这样的对比才是有价值的,当插件过大的时候,需要先排除
是否存在 MySQL 冷热不均的现象,然后考虑 Mycat 性能调优。
测试工具在单独的包中,解压到任意机器中执行使用,跟 MyCAT Server 没有关联关系,此测试工具很强
大,可以测试任意表,和任意数据库,测试工具下载:
https://github.com/MyCATApache/Mycat-download 目录下的 testtool.tar.gz 中。
解压后,在 bin 目录里运行文中的测试脚本。
标准插入性能测试脚本 test_stand_insert_perf.sh 支持任意表的定制化业务数据的随机生成功能了,在 sql 模板文件中
用${int(1-100)}这种变量,测试程序会随机生成符合要求的值并插入数据库。
./test_stand_insert_perf.sh jdbc:mysql://localhost:8066/TESTDB test test 10 file=mydata-create.sql
其中 mydata-create.sql 的内容如下:
total=10000000
sql=insert into my_table1 (….) values ('${date(yyyyMMddHHmmssSSS-[2014-2015]y)}-${int(0-
9999)}ok${int(1111-9999)}xxx ','${char([0-9]2:2)} OPP_${enum(BJ,SH,WU,GZ)}_1',10,${int(10-999)},${int(10-
99)},100,3,15,'${date(yyyyMMddHHmmssSSS-[2014-2015]y}${char([a-f,0-9]8:8)} ',${phone(139-
189)},2,${date(yyyyMMddHH-[2014-2015]y},${date(HHmmssSSS)},${int(100-1000)},'${enum(0000,0001,0002)}')
目前支持的有以下类型变量:
Int:${int(..)} 可以是,${int(10-999)}或者,${int(10,999)}前者表示从 10 到 999 的值,后者表示 10 或者 999
Date:日期如${date(yyyyMMddHHmmssSSS-[2014-2015]y)}表示从 2014 到 2015 年的时间,前面是输出格式,符
合 Java 标准
Char:字符串${char([0-9]2:2)}表示从 0 到 9 的字符,长度为 2 位(2:2),}${char([a-f,0-9]8:8)}表示从 a 到 f 以及 0 到
9 的字符串随机组成,定常为 8 位。
Enmu:枚举,表示从指定范围内获取一个值,${enum(0000,0001,0002)},里面可以是任意字符串或数字等内容。
标准查询性能测试脚本 test_stand_select_perf 也支持 sqlTemplate 的变量方式,查询任意指定的 sql
./test_stand_select_perf.sh jdbc:mysql://localhost:8066/TESTDB test test 10 100000 file=mysql-select.sql
其中 oppcall-select.sql 的内容类似下面:
sql=select * from mytravelrecord where id = ${int(1-1000000)}
表明查询 id 为 1 到 1000000 之间的随机 SQL。
注意:Windows 下 file=xxx.slq 需要加引号:
test_stand_insert_perf.bat jdbc:mysql://localhost:8066/TESTDB test test 50 "file=oppcall.sql"
首先参考 MyCAT 性能调优,确保整个系统达到最优配置。
性能测试,建议先小规模压力预热 10-20 分钟,这是众所周知的 Java 的特性,越跑越快。
测试的硬件和网络条件:
• 建议至少 3 台服务器;
• MyCAT Server 一台;
• Mysql 一台;
• 带宽应该是至少 100M,建议千兆;
• 压力程序在另一台,压力程序的机器也可以由性能差的机器来代替。
有条件的话,分片库在不同的 MYSQL 实例上,如 20 个分片,每个 MYSQL 实例 7 个分片,而且最好有多台
MYSQL 物理机。
分片表的录入性能测试-T01
测试案例:分片表的并发录入性能测试,测试 DEMO 中的 travelrecord 表,此表的基准 DDL 语句:create
travelrecord: create table travelrecord (id bigint not null primary key,user_id varchar(100),traveldate
DATE, fee decimal,days int);
此表的标准分片方式为基于 ID 范围的自动分片策略。Schema.xml 中配置如下:
默认是 3 个分片,分片 ID 范围定义在 autopartition-long.txt 中,建议修改为以下或更大的数值范围分片,
每个分片 500 万数据
# range start-end ,data node index
0-2000000=0
2000001-4000000=1
4000001-6000000=2
根据自己的情况,可以每个分片放更多的数据,进行对比性能测试,当分片 index 增加时,注意 dataNode
也增加(dataNode=“dn1,dn2,dn3”)。
测试的输入参数如下[jdbcurl] [user] [password] [threadpoolsize] [recordrange]:
Jdbcurl:连接 mycat 的地址,格式为 jdbc:mysql://localhost:8066/TESTDB
User 连接 Mycat 的用户名
Password:密码
Threadpoolsize:并发线程请求,可以在 50-2000 左右调整,看看哪种情况下的性能最好
Recordrang:插入的分片系列以及对应的 ID 范围,minId-maxId 然后逗号分开,对应多组分片的 ID 范围,如 0-
200000,200001-400000,400001-600000,跟分片配置保持一致。
测试过程:
每次测试,建议先执行重建表的操作,以保证测试环境的一致性:
连接 mycat 8066 端口,在命令行执行下面的操作:
drop table travelrecord;
create table travelrecord (id bigint not null primary key,user_id varchar(100),traveldate DATE, fee
decimal,days int);
先预测试:
执行命令:
test_stand_insert_perf jdbc:mysql://localhost:8066/TESTDB test test 100 “0-100M,100M1-200M,200M1-
400”
MyCAT 温馨提示:并发线程数表明同时至少有多少个 Mysql 连接会被打开,当 SQL 不跨分片的时候,并发线程数
=MYSQL 连接数,在 Mycat conf/schema.xml 中,将 minCon 设置为>=并发连接数,这种情况下重启 MYCAT,会
初始建立 minCon 个连接,并发测试结果更好,另外,也可以验证是否当前内存设置,以及 MYSQL 是否支持开启这么
多连接,若无法支持,则 logs/mycat.log 日志中会有告警错误信息,建议测试过程中 tail –f logs/mycat.log 观察有无
错误信息。另外,开启单独的 Mycat 管理窗口,mysql –utest –ptest –P9066 然后运行 show @@datasource 可以
看到后端连接的使用情况。Show @@threadpool 可以看线程和 SQL 任务积压的情况。
也可以同时启动多个测试程序,在不同的机器上,并发进行测试,每个测试程序写入一个分片的数据范围,对于 1 个亿的
数据插入测试来说,可能效果更好,毕竟单机并发线程 50 个左右已经差不多极限:
test_stand_insert_perf jdbc:mysql://localhost:8066/TESTDB test test 100 “0-100M”
est_stand_insert_perf jdbc:mysql://localhost:8066/TESTDB test test 100 100M1-200M”
全局表的查询性能测试 T02:
全局表自动在多个节点上同步插入,因此其插入性能有所降低,这里的插入表为 goods 表,执行的命令类似
T01 的测试。温馨提示:全局表是同时往多个分片上写数据,因此所需并发 MYSQL 数连接为普通表的 3 倍,最
好的模式是全局表分别在多个 mysql 实例上。
建表语句:
drop table goods;
create table goods(id int not null primary key,name varchar(200),good_type tinyint,good_img_url
varchar(200),good_created date,good_desc varchar(500), price double);
test_globaltable_insert_perf.bat jdbc:mysql://localhost:8066/TESTDB test test 100 1000000
本机笔记本,4G 内存,数据库与 Mycat 以及测试程序都在一起,跑出来每秒 1000 多的插入速度:
分片表的查询性能测试 T03:
此测试可以在 T01 的集成上运行,先生成大量 travelrecord 记录,然后进行并发随机查询,此测试是在分片
库上,基于分片的主键 ID 进行随机查询,返回单条记录,多线程并发随机执行 N 此记录查询,每次查询的记录主
键 ID 是随机选择,在 maxID(参数)范围之内。
测试工具 test_stand_select_perf 的参数如下
[jdbcurl] [user] [password] [threadpoolsize] [executetimes] [maxId]
Executetimes:每个线程总共执行多少次随机查询,建议 1000 次以上
maxId:travelrecord 表的最大 ID,可以执行 select max(id) from travelrecord 来获取。
Example:
test_stand_select_perf.bat jdbc:mysql://localhost:8066/TESTDB test test 100 10000 50000
分片表的汇聚性能测试 T04:
此测试可以在 T01 的集成上运行,先生成大量 travelrecord 记录,然后进行并发随机查询,此测试执行分片
库上的聚合、排序、分页的性能,SQL 如下:
select sum(fee) total_fee, days,count(id),max(fee),min(fee) from travelrecord group by days order by
days desc limit ?
测试工具 test_stand_merge_sel_perf 的参数如下
[
jdbcurl] [user] [password] [threadpoolsize] [executetimes] [limit]
Executetimes:每个线程总共执行多少次随机查询,建议 1000 次以上
limit:分页返回的记录个数,必须大于 30
Example:
test_stand_merge_sel_perf.bat jdbc:mysql://localhost:8066/TESTDB test test 10 100 100
分片表的更新性能测试 T05:
此测试可以在 T01 的集成上运行,先生成大量 travelrecord 记录,然后进行并发更新操作,
update travelrecord set user =? ,traveldate=?,fee=?,days=? where id=?
测试工具 test_stand_update_perf 的参数如下
[jdbcurl] [user] [password] [threadpoolsize] [record]
record:总共修改多少条记录,>5000
Example:
test_stand_update_perf.bat jdbc:mysql://localhost:8066/TESTDB test test 10 10000