python 深度学习(2) -- 神经网络回归模型
我们使用波士顿数据构建我们的神经网络回归模型,样本包含了 14 个变量的 506 个例子/观察 结果。波士顿数据包含在 sklearn 包中
from sklearn import datasets
boston = datasets.load_boston()
x,y = boston.data,boston.target
然后我们将数据进行标准化,在传统的统计分析中,通常将变量进行标准化,以使其分布近似为高斯分布。高斯分布具有一些不错的理论性质,使得模型表现更好。标准正态分布的平均值为 0,方差为 1
一种直观的标准化方法就是先从属性中减去平均值,然后除以该属性值的标准方差,例如对于属性 xi:
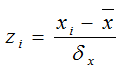
或者可以考虑另外两个流行的标准化公式:
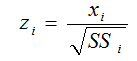
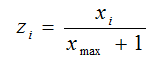
还有一种方法能将属性缩放到给定的最大值和最小值之间,通常是[0,1]
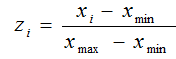
具体使用哪一个?只能通过实际实验确定。针对缩放到 [0,1] 之间的最后一个公式,可以用 sklearn 预处理模块中的 MinMaxScaler 进行处理。
from sklearn import preprocessing
x_MinMax = preprocessing.MinMaxScaler()
y_MinMax = preprocessing.MinMaxScaler()
import numpy as np
''' 将 y 转换成 列 '''
y = np.array(y).reshape(len(y),1)
x = x_MinMax.fit_transform(x)
y = y_MinMax.fit_transform(y)
''' 打印列平均值 共 13 列 '''
print x.mean(axis = 0)
''' 打印 x 中的缩放值,共 13 列'''
print x_MinMax.scale_
''' 打印 y 中的缩放值, 共 1 列 '''
print y_MinMax.scale_
''' 按二八原则划分训练集和测试集 '''
import random
from sklearn.cross_validation import train_test_split
np.random.seed(2018)
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size = 0.2)安装 scikit-neuralnetwork 软件包
pip install scikit-neuralnetwork使用 sknn.mlp 模块创建深度神经网络回归模型
from sknn.mlp import Regressor,Layer
'''
创建模型 fit1,包含两个使用 sigmoid 激活函数的隐藏层
输出层使用线性激活函数,输出神经元的激活函数是隐藏层输出的加权和
random_state 参数用来再现相同的数据
学习率为 0.02 允许的最大迭代次数 n_iter = 10
'''
fit1 = Regressor(
layers = [Layer("Sigmoid",units = 6),Layer("Sigmoid",units = 14),Layer("Linear")],
learing_rate = 0.02,
random_state = 2018,
n_iter = 10)
# 拟合实际数据,训练属性在 x_train 中,目标存储在 y_train 中
print "fitting model right now"
fit1.fit(x_trian,y_train)获取模型预测和度量性能
针对于回归问题,常用的度量方式就是计算目标(y)和预测值(^y) 之间误差平方的平均值。也就是均方差
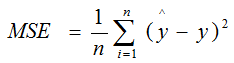
# 预测值
pred1_train = ft1.predict(x_train)
# 计算 MSE
from sklearn.metrics import mean_squared_error
mse_1 = mean_squared_error(pred1_train,y_train)
print "Train ERROR = ", mse_1![]()