GitHub超过4700星的TensorFlow(Amirsina Torfi博士)代码学习笔记(二)
上次的比较基础,本章节(第二个文件)主要是基础机器学习模型学习。和笔记(一)相比较复杂,并且很多模型我都没有引用成功。避免文章太长 ,所以本文只学习gradient_boosted_decision_tree.py,kmeans.py和linear_regression.py
完整代码链接(1积分):https://download.csdn.net/download/qq_32166779/10737966
git上链接 https://github.com/open-source-for-science/TensorFlow-Course#why-use-tensorflow
笔记(一)的连接 https://blog.csdn.net/qq_32166779/article/details/83302167
全部代码文件截图

2_BasicModels文件夹附图
一 , gradient_boosted_decision_tree.py
这个模型中文名叫梯度决定决策树
大致介绍 链接 https://blog.csdn.net/shine19930820/article/details/65633436?utm_source=blogxgwz0,
因为这些算法我也不是很了解,所以我就不卖弄了,直接上代码。我用的是TensorFlow2.0 并没有learner_pb2和GradientBoostedDecisionTreeClassifier,但是如下代码 还是可以看懂的。如果有谁跑通了 请告诉我一下准确率怎么样。
from __future__ import print_function
import tensorflow as tf
from tensorflow.contrib.boosted_trees.estimator_batch.estimator import GradientBoostedDecisionTreeClassifier
from tensorflow.contrib.boosted_trees.proto import learner_pb2 as gbdt_learner
batch_size = 4096 # The number of samples per batch
num_classes = 10 # The 10 digits
num_features = 784 # Each image is 28x28 pixels
max_steps = 10000
# GBDT Parameters
learning_rate = 0.1
l1_regul = 0.
l2_regul = 1.
examples_per_layer = 1000
num_trees = 10
max_depth = 16
# Fill GBDT parameters into the config proto
learner_config = gbdt_learner.LearnerConfig()
learner_config.learning_rate_tuner.fixed.learning_rate = learning_rate
learner_config.regularization.l1 = l1_regul
learner_config.regularization.l2 = l2_regul / examples_per_layer
learner_config.constraints.max_tree_depth = max_depth
growing_mode = gbdt_learner.LearnerConfig.LAYER_BY_LAYER
learner_config.growing_mode = growing_mode
run_config = tf.contrib.learn.RunConfig(save_checkpoints_secs=300)
learner_config.multi_class_strategy = (
gbdt_learner.LearnerConfig.DIAGONAL_HESSIAN)\
# Create a TensorFlor GBDT Estimator
gbdt_model = GradientBoostedDecisionTreeClassifier(
model_dir=None, # No save directory specified
learner_config=learner_config,
n_classes=num_classes,
examples_per_layer=examples_per_layer,
num_trees=num_trees,
center_bias=False,
config=run_config)
# Display TF info logs
tf.logging.set_verbosity(tf.logging.INFO)
# Define the input function for training
input_fn = tf.estimator.inputs.numpy_input_fn(
x={'images': mnist.train.images}, y=mnist.train.labels,
batch_size=batch_size, num_epochs=None, shuffle=True)
# Train the Model
gbdt_model.fit(input_fn=input_fn, max_steps=max_steps)
# Evaluate the Model
# Define the input function for evaluating
input_fn = tf.estimator.inputs.numpy_input_fn(
x={'images': mnist.test.images}, y=mnist.test.labels,
batch_size=batch_size, shuffle=False)
# Use the Estimator 'evaluate' method
e = gbdt_model.evaluate(input_fn=input_fn)
print("Testing Accuracy:", e['accuracy'])
部分API请 参考 https://www.w3cschool.cn/tensorflow_python/tensorflow_python-nfws2wiq.html
二,kmeans.py
找到最详细的一篇讲kmeans的是这个.
https://blog.csdn.net/loveliuzz/article/details/78783773 这篇文章可以不看,看这个图(转自loveliuzz)即可

上图变量只有一个k需要提前定义,现在结合TensorFlow的api:就是第二个形参num_clusters=k,k的取值是自己定义的。k越大 最后结果越准确。
kmeans = KMeans(inputs=X, num_clusters=k, distance_metric='cosine',
use_mini_batch=True)
博士提供的代码有一个参数batch_size = 1024是无用的,没看懂为什么要写出来。
代码主要考虑的是如下这段,代码注释已非常详细,
其中cluster_label = tf.nn.embedding_lookup(labels_map, cluster_idx) 其实就是输出labels_map里面的第cluster_idx个张量。
完整中文版注释代码如下
from __future__ import print_function
import numpy as np
import tensorflow as tf
from tensorflow.contrib.factorization import KMeans
# Ignore all GPUs, tf random forest does not benefit from it.
import os
os.environ["CUDA_VISIBLE_DEVICES"] = ""
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
full_data_x = mnist.train.images
# 定义超参数
num_steps = 50 # Total steps to train
batch_size = 1024 # The number of samples per batch
k = 1000 # The number of clusters
num_classes = 10 # The 10 digits
num_features = 784 # Each image is 28x28 pixels
# 定义输入输出
X = tf.placeholder(tf.float32, shape=[None, num_features])
# Labels (for assigning a label to a centroid and testing)
Y = tf.placeholder(tf.float32, shape=[None, num_classes])
# 构建kmeans图
kmeans = KMeans(inputs=X, num_clusters=k, distance_metric='cosine',
use_mini_batch=True)
# Build KMeans graph
training_graph = kmeans.training_graph()
# tensorflow版本不同所以启用不同参数 tensorflow1.4+多了一个参数
if len(training_graph) > 6: # Tensorflow 1.4+
(all_scores, cluster_idx, scores, cluster_centers_initialized,
cluster_centers_var, init_op, train_op) = training_graph
else:
(all_scores, cluster_idx, scores, cluster_centers_initialized,
init_op, train_op) = training_graph
cluster_idx = cluster_idx[0] # 存放所有数据的质心序号
avg_distance = tf.reduce_mean(scores)# 存放平均距离
# Initialize the variables (i.e. assign their default value)
init_vars = tf.global_variables_initializer()
# Start TensorFlow session
sess = tf.Session()
# Run the initializer
sess.run(init_vars, feed_dict={X: full_data_x})
sess.run(init_op, feed_dict={X: full_data_x})
# Training
for i in range(1, num_steps + 1):
_, d, idx = sess.run([train_op, avg_distance, cluster_idx],
feed_dict={X: full_data_x})
if i % 10 == 0 or i == 1:
print("Step %i, Avg Distance: %f" % (i, d))
# 给每个图心分配一个标签
# 计算每个图心的样本个数,把样本归入离它最近的质心(使用idx)
counts = np.zeros(shape=(k, num_classes))
# counts的shape是(25, 10),用于存放25个质心分类的频率计数
for i in range(len(idx)):
# idx的shape是(55000,),每个成员都是0~24之间的值,对应所属质心的编号
counts[idx[i]] += mnist.train.labels[i]
# mnist.train.labels的shape是(55000, 10), 每个成员都是独热编码,用来标注属于哪个数字
# 将最高频的标注分配给质心。 len(labels_map)是25,也就是每个质心一个成员,记录每个图心所属的数字分类
labels_map = [np.argmax(c) for c in counts]
# 转换前,labels_map的shape为(25,)
labels_map = tf.convert_to_tensor(labels_map)
# 此时labels_map变成了一个const op,输出就是上面(25,)包含的值
# 评估模型。下面开始构建评估计算图
# 注意:centroid_id就是对应label
cluster_label = tf.nn.embedding_lookup(labels_map, cluster_idx)
# cluster_idx输出的tensor,每个成员都映射到labels_map的一个值。
# cluster_label的输出就是映射的label值,后面用来跟标注比较计算准确度
# 计算准确率
correct_prediction = tf.equal(cluster_label, tf.cast(tf.argmax(Y, 1), tf.int32))
accuracy_op = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# Test Model
test_x, test_y = mnist.test.images, mnist.test.labels
print("Test Accuracy:", sess.run(accuracy_op, feed_dict={X: test_x, Y: test_y}))
三,linear_regression.py
线性回归例子非常经典
from __future__ import print_function
import tensorflow as tf
import numpy
import matplotlib.pyplot as plt
rng = numpy.random
# Parameters
learning_rate = 0.01
training_epochs = 1000
display_step = 50
# Training Data
train_X = numpy.asarray([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,
7.042,10.791,5.313,7.997,5.654,9.27,3.1])
train_Y = numpy.asarray([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,
2.827,3.465,1.65,2.904,2.42,2.94,1.3])
n_samples = train_X.shape[0]
# tf Graph Input
X = tf.placeholder("float")
Y = tf.placeholder("float")
# Set model weights
W = tf.Variable(rng.randn(), name="weight")
b = tf.Variable(rng.randn(), name="bias")
# Construct a linear model
pred = tf.add(tf.multiply(X, W), b)
# Mean squared error
cost = tf.reduce_sum(tf.pow(pred-Y, 2))/(2*n_samples)
# Gradient descent
# Note, minimize() knows to modify W and b because Variable objects are trainable=True by default
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
# Start training
with tf.Session() as sess:
# Run the initializer
sess.run(init)
# Fit all training data
for epoch in range(training_epochs):
for (x, y) in zip(train_X, train_Y):
sess.run(optimizer, feed_dict={X: x, Y: y})
# Display logs per epoch step
if (epoch+1) % display_step == 0:
c = sess.run(cost, feed_dict={X: train_X, Y:train_Y})
print("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(c), \
"W=", sess.run(W), "b=", sess.run(b))
print("Optimization Finished!")
training_cost = sess.run(cost, feed_dict={X: train_X, Y: train_Y})
print("Training cost=", training_cost, "W=", sess.run(W), "b=", sess.run(b), '\n')
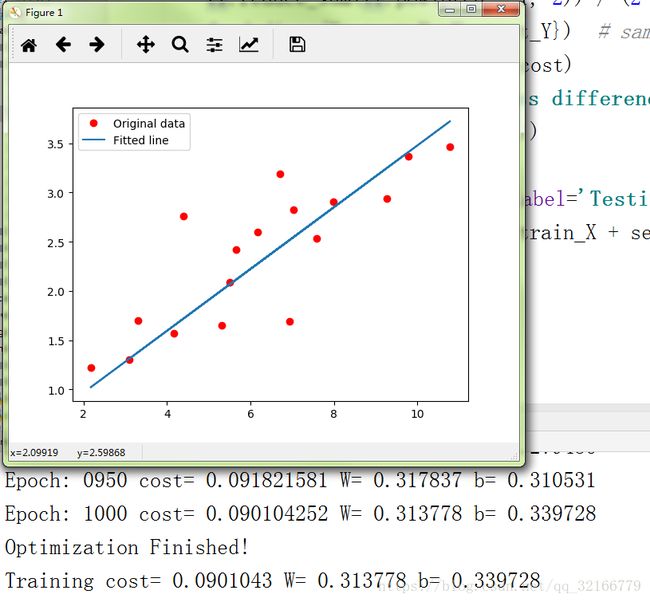
# Graphic display
plt.plot(train_X, train_Y, 'ro', label='Original data')
plt.plot(train_X, sess.run(W) * train_X + sess.run(b), label='Fitted line')
plt.legend()
plt.show()
# Testing example, as requested (Issue #2)
test_X = numpy.asarray([6.83, 4.668, 8.9, 7.91, 5.7, 8.7, 3.1, 2.1])
test_Y = numpy.asarray([1.84, 2.273, 3.2, 2.831, 2.92, 3.24, 1.35, 1.03])
print("Testing... (Mean square loss Comparison)")
testing_cost = sess.run(
tf.reduce_sum(tf.pow(pred - Y, 2)) / (2 * test_X.shape[0]),
feed_dict={X: test_X, Y: test_Y}) # same function as cost above
print("Testing cost=", testing_cost)
print("Absolute mean square loss difference:", abs(
training_cost - testing_cost))
plt.plot(test_X, test_Y, 'bo', label='Testing data')
plt.plot(train_X, sess.run(W) * train_X + sess.run(b), label='Fitted line')
plt.legend()
plt.show()
显示: