Sqoop1一般用于线上、测试脚本环境开发
注意:sqoop部署运算节点一般有hive、hbase、azkaban、oozie的节点上还有数据库的节点上
Sqoop开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,postgresql等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。底层是通过MapReduce作业来完成。它充分利用了MapReduce的并行特点以批处理的方式加快数据的传输,同时也借助MapReduce实现了容错。
目前主要包括两个版本:Sqoop1和Sqoop2,这两个版本不同,是完全不兼容的,版本<=1.4.6的都是Sqoop1,版本>=1.99.2的都是Sqoop2。
Sqoop官网:http://sqoop.apache.org/

下载地址:http://archive.apache.org/dist/sqoop/1.4.6/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
解压安装包
[hadoop@bigdata243 app]$ tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
[hadoop@bigdata243 app]$ mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop1
Sqoop目录下创建两个相关的目录:
# mkdir extra
# mkdir logs
添加Sqoop环境变量
#Sqoop1
export SQOOP_HOME=/home/hadoop/app/sqoop1
# PATH
export PATH=$PATH:$SQOOP_HOME/bin
配置sqoop1
[hadoop@bigdata243 sqoop1]$ cd conf/
[hadoop@bigdata243 conf]$ cp sqoop-env-template.sh sqoop-env.sh
[hadoop@bigdata243 conf]$ vi sqoop-env.sh
修改sqoop-env.sh配置文件,设置HADOOP_COMMON_HOME、HADOOP_MAPRED_HOME、HIVE_HOME这三个属性,如下
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/home/hadoop/app/hadoop2.7
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/home/hadoop/app/hadoop2.7
#Set the path to where bin/hive is available
export HIVE_HOME=/home/hadoop/app/hive2.3

安装依赖Mysql JDBC驱动
将MySQL的JDBC驱动放入server/lib/目录下即可(hive/lib下)
cp /home/hadoop/app/hive2.3/lib/mysql-connector-java-5.1.38.jar /home/hadoop/app/sqoop1/lib
sqoop1/bin目录下存放了sqoop1.x的执行脚本,里面也有windows下的执行脚本,windows下的执行脚本我们不需要,执行如下命令删除
[hadoop@bigdata243 sqoop1]$ cd bin/
[hadoop@bigdata243 bin]$ rm *.cmd
查看help把帮助
[hadoop@bigdata243 bin]$ sqoop help
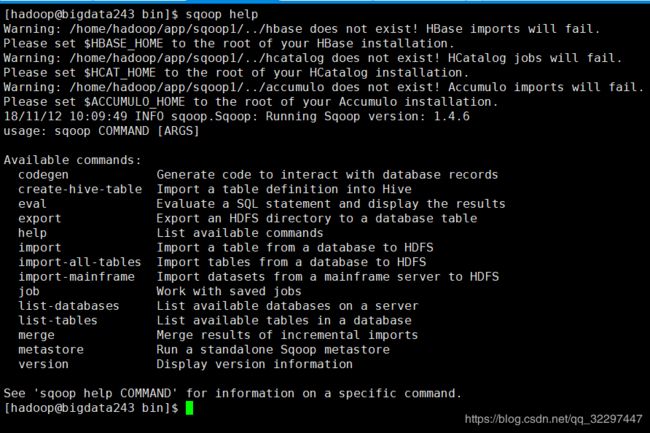
上面提示了一堆之一事项以及没有的目录,不影响,我们不需要直接注释就好
解决方法:修改Sqoop的文件bin/configure-sqoop,注释掉如下内容
[hadoop@bigdata243 bin]$ vi configure-sqoop
HBASE_HOME
HCAT_HOME
ACCUMULO_HOME


查看数据库
查看数据库使用的命令是list-databases
[hadoop@bigdata243 sqoop1]$ sqoop help list-databases
查看mysql中的所有数据库(如果想要换行在末尾加上’\’)
[hadoop@bigdata243 sqoop1]$ sqoop list-databases --connect jdbc:mysql://bigdata245:3306 --username root --password P@ssw0rd
使用sqoop查看mysql中的所有数据库时,出现了两个错误,错误信息及解放方法如下
错误1:
Got exception running Sqoop: java.lang.RuntimeException: Could not load db driver class: com.mysql.jdbc.Driver
解决方法:
1).将mysql的驱动包拷贝到$SQOOP_HOME/lib下
2).检查sqoop的环境变量是否配置成功
错误2:
SQLException: Access denied for user ‘root’@’localhost’ (using password: YES)
原因:mysql没有开启远程访问权限
解决方法:mysql中执行如下命令,开启远程访问权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'P@ssw0rd' WITH GRANT OPTION;
查看数据库中的所有表
[hadoop@bigdata243 sqoop1]$ sqoop list-tables --connect jdbc:mysql://bigdata245:3306/hive_matadata --username root --password P
配置sqoop代理访问
因为sqoop访问Hadoop的MapReduce使用的是代理的方式,必须在Hadoop中配置所接受的proxy用户和组,找到Hadoop的core-site.xml配置文件,添加如下内容,重启Hadoop即可
Sqoop测试及使用
1.MySQL 导入数据到 HDFS
说明:
(1).Sqoop 与数据库进行通信,获取数据库表的元数据信息
(2).Sqoop启动一个Map-Only的MapReduce作业,利用元数据信息并行将数据写入Hadoop
1.数据准备
MySQL 中创建数据库sqoop
mysql> create database sqoop;
Query OK, 1 row affected (0.00 sec)
mysql> use sqoop;
Database changed
mysql>
创建两张表dept及emp
CREATE TABLE DEPT(
DEPTNO int(2) PRIMARY KEY,
DNAME VARCHAR(14),
LOC VARCHAR(13)
);
表结构:
mysql> desc DEPT;
CREATE TABLE EMP(
EMPNO int(4) PRIMARY KEY,
ENAME VARCHAR(10),
JOB VARCHAR(9),
MGR int(4),
HIREDATE DATE,
SAL int(7),
COMM int(7),
DEPTNO int(2),
foreign key(deptno) references DEPT(DEPTNO)
);
表结构:
mysql> desc EMP;
插入数据
DEPT 表:
INSERT INTO DEPT VALUES
(10,'ACCOUNTING','NEW YORK');
INSERT INTO DEPT VALUES (20,'RESEARCH','DALLAS');
INSERT INTO DEPT VALUES
(30,'SALES','CHICAGO');
INSERT INTO DEPT VALUES
(40,'OPERATIONS','BOSTON');
EMP 表:
INSERT INTO EMP VALUES
(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO EMP VALUES
(7499,'ALLEN','SALESMAN',7698,'1981-2-20',1600,300,30);
INSERT INTO EMP VALUES
(7521,'WARD','SALESMAN',7698,'1981-2-22',1250,500,30);
INSERT INTO EMP VALUES
(7566,'JONES','MANAGER',7839,'1981-4-2',2975,NULL,20);
INSERT INTO EMP VALUES
(7654,'MARTIN','SALESMAN',7698,'1981-9-28',1250,1400,30);
INSERT INTO EMP VALUES
(7698,'BLAKE','MANAGER',7839,'1981-5-1',2850,NULL,30);
INSERT INTO EMP VALUES
(7782,'CLARK','MANAGER',7839,'1981-6-9',2450,NULL,10);
INSERT INTO EMP VALUES
(7788,'SCOTT','ANALYST',7566,'87-7-13',3000,NULL,20);
INSERT INTO EMP VALUES
(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO EMP VALUES
(7844,'TURNER','SALESMAN',7698,'1981-9-8',1500,0,30);
INSERT INTO EMP VALUES
(7876,'ADAMS','CLERK',7788,'87-7-13',1100,NULL,20);
INSERT INTO EMP VALUES
(7900,'JAMES','CLERK',7698,'1981-12-3',950,NULL,30);
INSERT INTO EMP VALUES
(7902,'FORD','ANALYST',7566,'1981-12-3',3000,NULL,20);
INSERT INTO EMP VALUES
(7934,'MILLER','CLERK',7782,'1982-1-23',1300,NULL,10);
2.从mysql导入数据到HDFS
导入数据使用import命令,输入如下命令查看帮助说明
[hadoop@bigdata243 ~]$ sqoop help import
输入命令导入数据
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root \
--password P@ssw0rd \
--table EMP -m 1\
查看运行结果
默认导入HDFS路径:/user/用户名/表名
[hadoop@bigdata241 ~]$ hadoop fs -ls /user/hadoop/EMP
-rw-r--r-- 3 hadoop supergroup 0 2018-11-12 11:33 /user/hadoop/EMP/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 663 2018-11-12 11:33 /user/hadoop/EMP/part-m-
[hadoop@bigdata241 ~]$ hadoop fs -text /user/hadoop/EMP/part-m-00000

3.sqoop import 命令常用参数使用
(1).导入数据前先删除目录(–delete-target-dir)
如果重复执行上面的命令导入数据到hdfs会报如下错误
Encountered IOException running import job:
org.apache.hadoop.mapred.FileAlreadyExistsException:
Output directory hdfs://hdpcomprs:9000/user/hadoop/EMP already exists
错误原因:hdfs中文件路径已存在
解决方法:
①.手工把存在的目录删除
②.执行导入时,加上参数–delete-target-dir
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root \
--password P@ssw0rd \
--delete-target-dir \
--table EMP -m 1
(2).设置mapreduce作业名称(–mapreduce-job-name)
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root \
--password P@ssw0rd \
--delete-target-dir \
--mapreduce-job-name MysqlSqoopEMPTOHDFS \
--table EMP -m 1
(3).导入数据时指定hdfs路径(–target-dir)
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root \
--password P@ssw0rd \
--delete-target-dir \
--mapreduce-job-name MysqlSqoopEMPTOHDFS \
--target-dir EMP_INFO \
--table EMP -m 1
数据导入到hdfs的路径为:/user/hadoop/EMP_INFO
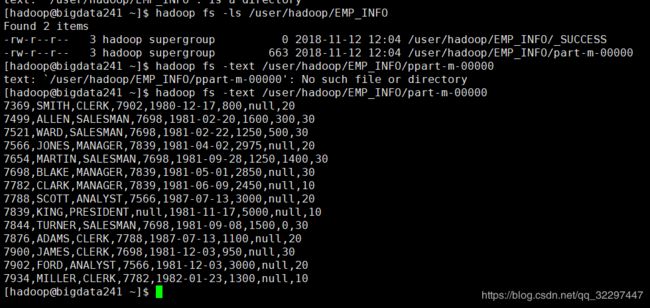
(4).设置只导入指定列的数据(–columns)
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root \
--password P@ssw0rd \
--delete-target-dir \
--mapreduce-job-name FromMySQLToHDFS \
--target-dir EMP_COLUMN \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--table EMP -m 1
运行结果:
[hadoop@bigdata241 ~]$ hadoop fs -ls /user/hadoop/EMP_COLUMN
[hadoop@bigdata241 ~]$ hadoop fs -text /user/hadoop/EMP_COLUMN/part-m-00000

(5).导入数据时设置文件的存储格式
使用参数–as-parquetfile 设置存储格式为parquet格式
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root \
--password P@ssw0rd \
--delete-target-dir \
--mapreduce-job-name FromMySQLToHDFS \
--target-dir EMP_COLUMN_PARQUET \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--as-parquetfile \
--table EMP -m 1
导入完成后,在hdfs中可以看到文件的存储格式为parquetfile
[hadoop@bigdata241 ~]$ hadoop fs -ls /user/hadoop/EMP_COLUMN_PARQUET
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2018-11-12 12:09 /user/hadoop/EMP_COLUMN_PARQUET/.metadata
-rw-r--r-- 3 hadoop supergroup 1318 2018-11-12 12:09 /user/hadoop/EMP_COLUMN_PARQUET/01a7cecb-e9a4-4c1a-814c-3f47cc5a1eed.parquet
(6).设置导入数据字段与字段、行与行之间的分隔符
设置字段与字段之间的分隔符使用参数–fields-terminated-by,设置行与行之间的分隔符使用–lines-terminated-by
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root \
--password P@ssw0rd \
--delete-target-dir \
--mapreduce-job-name FromMySQLToHDFS \
--target-dir EMP_SPLIT \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
--table EMP -m 1
[hadoop@bigdata241 ~]$ hadoop fs -ls /user/hadoop/EMP_SPLIT
[hadoop@bigdata241 ~]$ hadoop fs -text /user/hadoop/EMP_SPLIT/part-m-00000
(7).条件导入
实现需求:将emp表中工资大于2000的员工信息导入到hdfs
方式一:–where
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root --password P@ssw0rd \
--delete-target-dir \
--target-dir EMP_COLUMN_WHERE \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--mapreduce-job-name FromMySQLToHDFS \
--where 'SAL>2000' \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
--table EMP -m 2
命令中-m 写的是2,表示会有两个map,也就是两个输出文件,即执行完成后,在hdfs中会有两个文件
查看结果:
hadoop fs -ls /user/hadoop/EMP_COLUMN_WHERE
hadoop fs -text /user/hadoop/EMP_COLUMN_WHERE/part-m-00000
hadoop fs -text /user/hadoop/EMP_COLUMN_WHERE/part-m-00001
方式二:–query
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root \
--password P@ssw0rd \
--delete-target-dir \
--target-dir EMP_COLUMN_QUERY \
--query 'select * from EMP where SAL>2000' \
--mapreduce-job-name FromMySQLToHDFS \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
--table EMP -m 1
执行命令报如下错误:
Cannot specify –query and –table together.
错误原因:在使用–query后,查询条件已经指定了表名,不需要再使用–table参数来指定表名了
解决方法:去掉–table参数
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root \
--password P@ssw0rd \
--delete-target-dir \
--target-dir EMP_COLUMN_QUERY \
--query 'select * from EMP where SAL>2000' \
--mapreduce-job-name FromMySQLToHDFS \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
-m 1
修改后再次执行报如下错误:
IOException: Query [select * from EMP where
SAL>2000] must contain ‘$CONDITIONS’ in WHERE clause
解决方法:在where条件后添加 and $CONDITIONS
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root \
--password P@ssw0rd \
--delete-target-dir \
--target-dir EMP_COLUMN_QUERY \
--query 'select * from EMP where SAL>2000 and $CONDITIONS' \
--mapreduce-job-name FromMySQLToHDFS \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
-m 1
–query 不仅支持单表查询,也支持多表查询
实现需求:查询员工编号、名称及员工所属部门导入到hdfs
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root \
--password P@ssw0rd \
--delete-target-dir \
--target-dir EMP_COLUMN_QUERY_JOIN \
--query 'select E.EMPNO,E.ENAME,D.DNAME from EMP E inner join DEPT D on D.DEPTNO = E.DEPTNO and $CONDITIONS' \
--mapreduce-job-name FromMySQLToHDFS \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
-m 1
(8).导入时将文件作为参数传入(–options-file)
新建文件touch emp.opt,文件内容如下:
import
--connect
jdbc:mysql://bigdata245:3306/sqoop
--username
root
--password
P@ssw0rd
--delete-target-dir
--target-dir
EMP_OPTIONS_FILE
--mapreduce-job-name
FromMySQLToHDFS
--table
EMP
-m
注意:如果使用将文件作为参数,在文件中每个命令参数必须为一行
输入如下命令导入数据到hdfs
sqoop --options-file emp.opt
查看运行结果:
hadoop fs -ls /user/hadoop/EMP_OPTIONS_FILE
hadoop fs -text /user/hadoop/EMP_OPTIONS_FILE/part-m-00000
2.HDFS 导出数据到 MySQL
说明:
(1).Sqoop与数据库通信,获取数据库表的元数据信息;
(2).将Hadoop上的文件划分成若干个Split,每个Split由一个Map Task进行数据导出操作;
1.HDFS 导出数据到MySQL
导出命令使用export,输入如下命令查看命令帮助说明
$ sqoop help export
导出数据到mysql(mysql 中 没有表 EMP_DEMO)
sqoop export \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root --password P@ssw0rd \
--table EMP_DEMO \
--export-dir /user/hadoop/EMP \
-m 1
执行命令后报错:
Table ‘sqoop.EMP_DEMO’ doesn’t exist
说明sqoop不会在mysql中自动创建表
mysql中创建表EMP_DEMO(列明属性要一直)
CREATE TABLE EMP_DEMO(
EMPNO int(4) PRIMARY KEY,
ENAME VARCHAR(10),
JOB VARCHAR(9),
MGR int(4),
HIREDATE DATE,
SAL int(7),
COMM int(7),
DEPTNO int(2),
foreign key(deptno) references DEPT(DEPTNO)
);
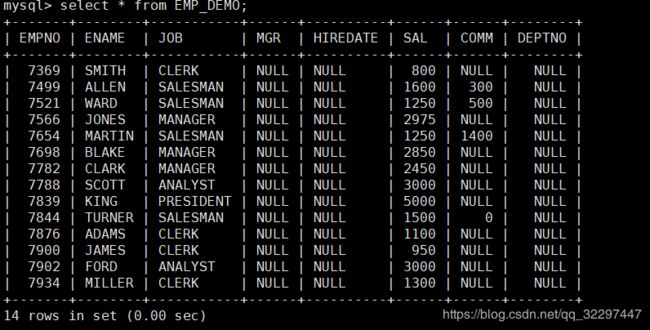
再次执行命令后(如果多次执行导出数据会一致追加到表EMP_DEMO中),运行结果如下

2.sqoop export 命令常用参数使用,只有指定的列中有数据
sqoop export \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root --password P@ssw0rd \
--table EMP_DEMO \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--export-dir /user/hadoop/EMP_COLUMN \
-m 1
运行中到job卡住不动,这里是运行mr的操作,参考解决地址https://hortonworks.com/blog/how-to-plan-and-configure-yarn-in-hdp-2-0/。在资源页面任务也没有运行完成,我多试了几次都是一样 either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
18/11/12 13:43:09 INFO db.DBInputFormat: Using read commited transaction isolation
18/11/12 13:43:09 INFO mapreduce.JobSubmitter: number of splits:1
18/11/12 13:43:09 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1541991367874_0014
18/11/12 13:43:09 INFO impl.YarnClientImpl: Submitted application application_1541991367874_0014
18/11/12 13:43:09 INFO mapreduce.Job: The url to track the job: http://bigdata241:8088/proxy/application_1541991367874_0014/
18/11/12 13:43:09 INFO mapreduce.Job: Running job: job_1541991367874_0014
出现此故障的原因应该是,在每个Docker分配的内存和CPU资源太少,不能满足Hadoop和sqoop/hive运行所需的默认资源需求

点击ApplicationMaster

再次执行
导出数据时设置字段与字段、行与行之间的分隔符
hdfs中/user/hadoop下EMP_SPLIT文件中的数据是前面通过mysql导入的,使用了分隔符,所以在导出时也需要指定分隔符,否则导出不成功。EMP_SPLIT文件内容如下
sqoop export \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root --password P@ssw0rd \
--delete-target-dir \
--table EMP_DEMO \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
--export-dir /user/hadoop/EMP_SPLIT \
-m 1
3.MySQL 导入数据到 Hive
全部导入
实现需求:将mysql中表emp导入到hive中
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root --password P@ssw0rd \
--table EMP \
--delete-target-dir \
--hive-import \
--hive-database test --create-hive-table --hive-table emp_import \
-m 1
注意:
运行完成后在hive中自动创建了一张表emp_import,通过命令查看表的信息,可以看到sal的数据类型为int,实际我们一般都是double类型,所以不建议使用–create-hive-table参数来自动创建hive表,建议手动创建表,再使用命令导入。
部分导入
hive 中 创建表
create table emp_column(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
row format delimited fields terminated by '\t' lines terminated by '\n';
执行如下命令,将指定的列导入数据到hive
sqoop import \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root --password P@ssw0rd \
--table EMP \
--delete-target-dir \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
--hive-import --hive-database test --hive-table emp_column --hive-overwrite \
-m 1
4.Hive 导出数据到 MySQL
实现需求:将hive 表 emp_import 中的数据导出到 Mysql 表 EMP_DEMO
hive 表 emp_import对应hdfs路径:/user/hive/warehouse/test.db/emp_import
mysql 中 EMP_DEMO 表结构如下

注意:mysql中日期为date类型,hive中对应的字段为字符串类型,其存储格式必须为:yyyy-mm-dd
导出时指定null字段的填充符,如果不指定会报一个异常NumberFormatException
–input-null-string:如果没有这个选项,那么在字符串类型列中,字符串”null”会被转换成空字符串,所以最好写上这个,指定为’\N’ –input-null-non-string:如果没有这个选项,那么在非字符串类型的列中,空串和”null”都会被看作是null
执行命令导出(相当于hdfs导出到mysql)
sqoop export \
--connect jdbc:mysql://bigdata245:3306/sqoop \
--username root --password P@ssw0rd \
--table EMP_DEMO \
--export-dir /user/hive/warehouse/test.db/emp_import \
--input-fields-terminated-by '\001' \
--input-null-string 'null' --input-null-non-string 'null' \
-m 1
运行结果:
