迁移学习(Transfer Learning)
本博客是针对李宏毅教授在youtube上上传的Machine Learning课程视频的学习笔记。课程链接
- 概念
- 概览
- Model Fine-tuning labelled source labelled target
- Multitask Learning labelled source labelled target
- Domain-adversarial training labelled source unlabelled target
- Zero-shot Leaning labelled source unlabelled target
- Self-taught learning 和 Self-taught Clustering
概念
迁移学习是什么?
假设手上有一些和现在要进行的学习任务不相关的数据,那么能不能用这些数据帮助完成学习任务。
如下图,比如我们想做一个猫狗分类器,
但是我们没有猫狗的图片数据,而只有以下数据:
- 大象和老虎图片(都是动物图片,所以属于相似的域(domain),但是与猫狗分类相比是完全不同的学习任务)
- 招财猫和高飞狗图片(都是卡通人物图片,所以属于不同的域,但是同属于猫狗分类任务)

为什么要研究迁移学习?

- 比如如果要做台语的语音识别,但是网络上的训练数据很少,于是想到能不能利用youtube上海量的其它语音数据来做台语的语音识别训练。
- 做医学图像识别,但是医学图像的存量往往很少,那么海量的其它图片能不能帮忙呢
- 做文本分析,可能特定领域的文本数据少,那么能不能利用其它领域的文本来帮忙呢
可行性
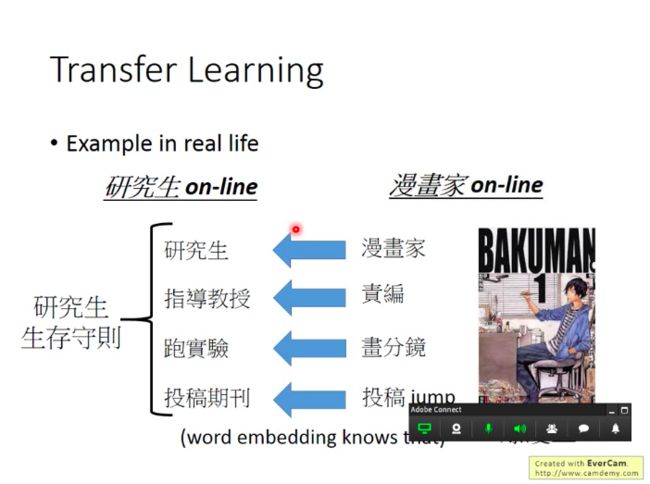
迁移学习的可行性一定基础上建立在人类的行为上,因为人类是不断在做迁移学习的。
如下图所示,比如如果想要做好一名研究生,你可以参考称为一名好的漫画家应该如何做。
概览
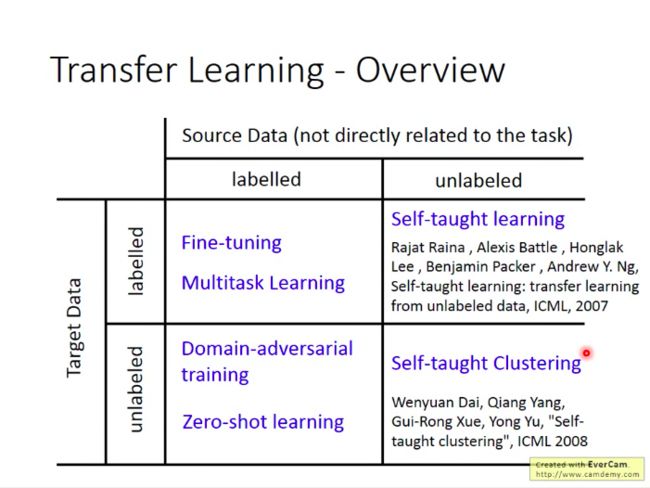
根据源数据(我们手上已有数据)和目标数据(目标学习任务所需数据)是否有label,我们将迁移学习分成四种不同的类别。
Model Fine-tuning (labelled source, labelled target)
任务描述
目标数据量很少,源数据量很多。(One-shot learning:在目标域中只有几个或非常少的样例)
例子:(有监督)讲话者调整
目标数据:语音数据和某一特定讲话者的稿子。
源数据:语音数据和很多讲话者的稿子。

想法:用源数据训练一个模型,然后用目标数据微调模型
难点:只有很有限的目标数据,所以要注意过拟合问题。
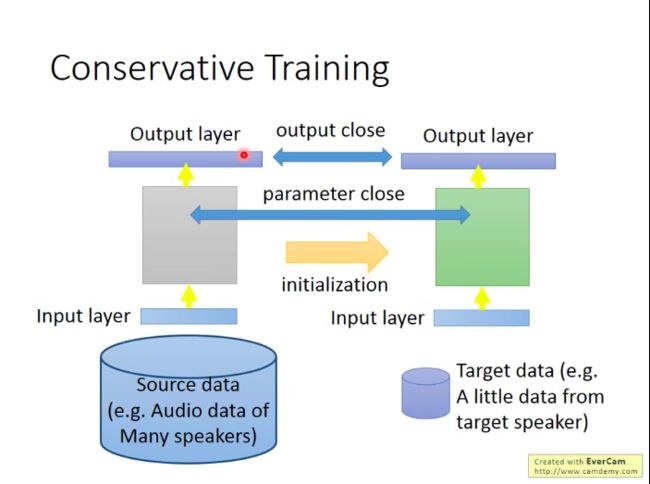
一个解决过拟合难点的训练方法: Conservative Training(保留训练)
在微调新模型时加入限制(regularization),比如要求微调后的新模型与旧模型针对相同的输入的输出越相似越好,或者说模型的参数越相似越好。
- 另一种方法:Layer Transfer(层转移器)
将用源数据训练好的模型的某几层取出/拷贝(连带参数),然后用目标数据去训练没有保留(拷贝出来)的层。
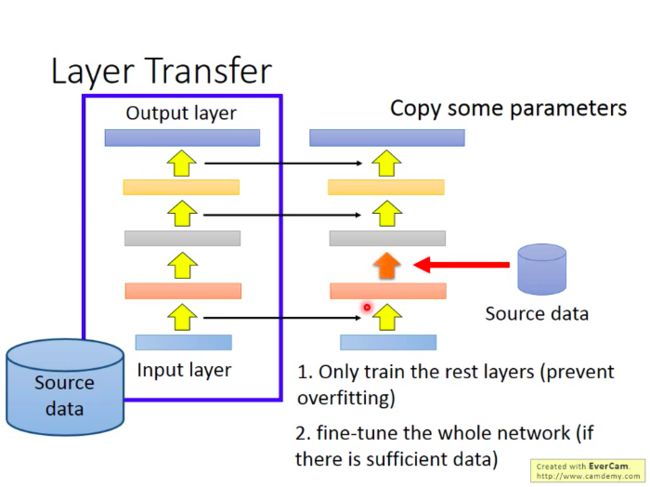
那么,这里就产生一个问题:究竟哪些层应该被转移(拷贝)呢?答案是:针对不同的学习任务,往往是需要不一样的层。
在语音识别上,一般拷贝最后几层。(直觉:不同的人由于口腔结构差异,同样的发音方式得到的声音可能不同。而模型的前几层做的事是讲话者的发音方式,后面的几层再根据发音方式就可以获得被辨识的文字,即是跟具体讲话者没有太大关系的,所以做迁移时,只保留后面几层即可,而前面几层就利用新的特定讲话者的目标数据来做训练)
在图像识别上,一般拷贝前几层。(直觉:网络的前几层一般学到的是最简单的模式(比如直线,横线或最简单的几何模型),比较通用,而后几层学习到的模式已经很抽象了,很难迁移到其它的领域)

《How transferable are features in deep neural networks》论文的相关实验结果:做图像识别,拷贝不同的层,并对迁移模型做不同的操作,观察效果。
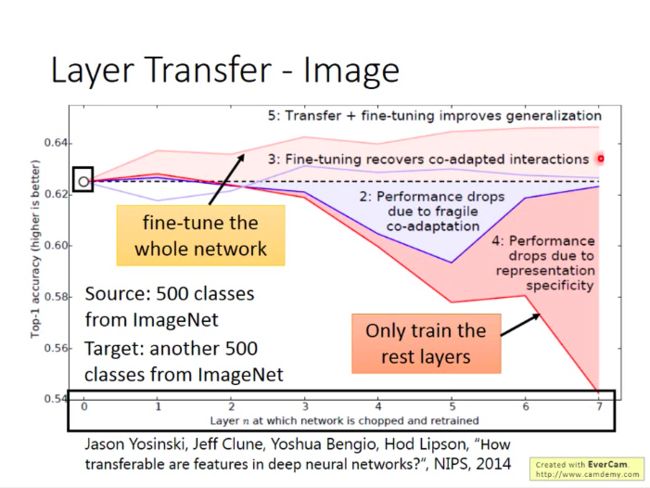
另外一个实验结果:将源数据与目标数据的域划分开,比如源数据都是自然界的东西,而目标数据都是人造的东西,那么这对迁移模型的效果会有怎样的影响。
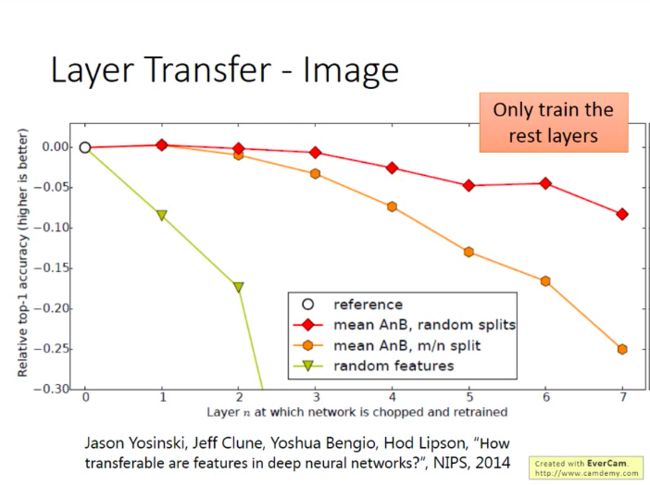
可以从上图看出,这对迁移模型的前几层的影响是不大的,说明迁移模型不管是识别自然界事物还是人造事物,其在前几层上面做的事情其实是很相似的。
Multitask Learning (labelled source, labelled target)
在Fine-tuning上,我们其实只关心迁移模型在目标数据域上的学习任务完成的好不好,而不关心在源数据域上表现如何。而Multitask Learning是会同时关注这两点的。
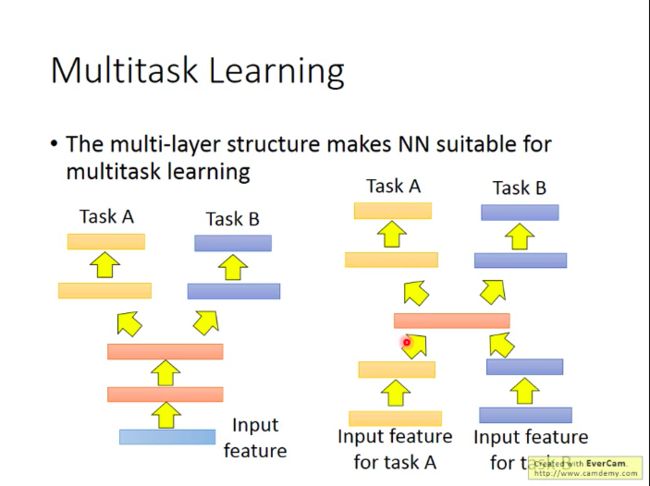
如上图,我们针对两种任务A和B,我们用它们的数据一起训练NN模型的前几层,再分别训练模型的后面几层包括输出层,以针对各自任务输出针对性的结果,这样的好处是由于训练数据量的增加,模型的性能可能会更好。关键是要确定两个任务有没有共通性,即是不是能共用前面几层。
另外,也可以在中间几层用共同数据来训练。
多任务学习比较成果的一个应用实例是:多语言识别。
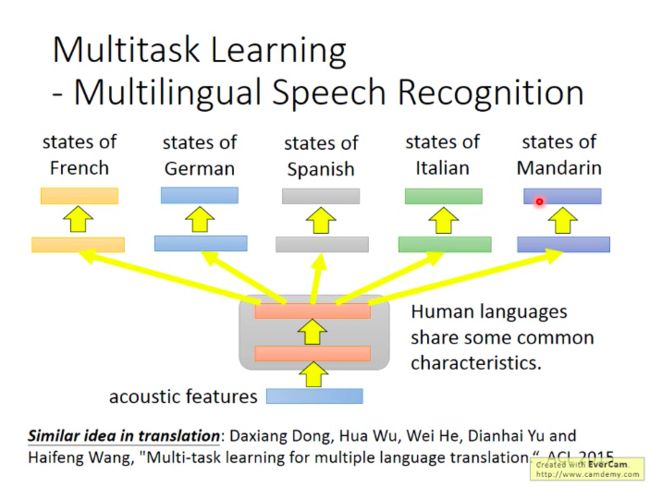
如上图,多国语言语音识别模型的前几层共享一些公共特征。
那么,就又产生了一个问题:语言迁移的范围可以有多广呢?
下图是:借助欧洲语言帮助中文的识别(在有欧洲语言数据辅助的情况下,只用大约50小时的中文数据可以达到用100小时中文数据单独训练的效果)。

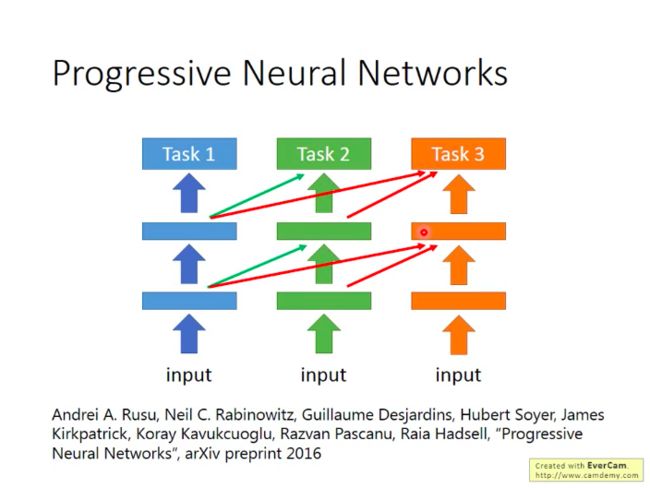
- Progressive Neural Network
先针对Task1训练一个NN,在训练Task2的NN时,它的每一个隐层都会借用一个Task1中的NN的隐层(也可以直接设为全0的参数,相当于不借用),这样对Task1的模型性能不会有影响,也可以在Task2中对其已有参数进行借用。
Domain-adversarial training (labelled source, unlabelled target)
- 任务描述
源数据对应的学习任务和目标数据对应的学习任务是比较相似的,都是做数字识别,但是两者的输入数据差别很大(目标数据加入了背景),那如何让源数据上学出来的模型也能在目标数据上发挥良好呢?
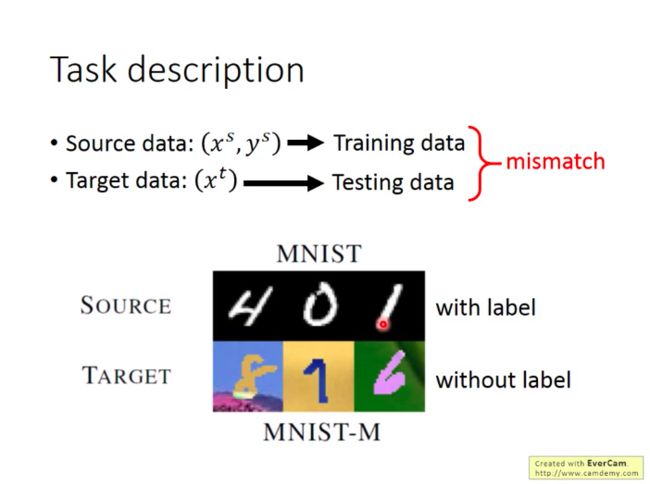
而既然源数据的标签已知,目标数据的标签未知,那么我们可以将源数据当做训练数据,目标数据作测试数据来进行迁移。
- Domain-adversarial training
而如果我们直接用MNIST的数据学一个model,去做MNIST-M的识别,效果是会非常差的。
而我们知道,一个NN前几层做的事情相当于特征抽取(feature extraction),后几层做的事相当于分类(Classification),所以我们将前面几层的输出结果拿出来看一下会是什么样子。
如下图,MNIST的数据可以看做蓝色的点,MNIST-M的点可以看做红色的点,所以它们分别对应的特征根本不一样,所以做迁移时当然效果很差。
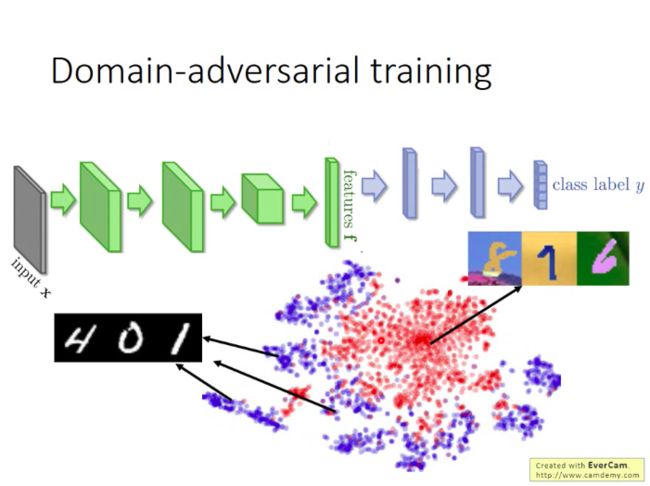
于是思考:能不能让NN的前几层将不同域的各自特性消除掉,即把不同的域特性消除掉。

怎么训练这样一个NN呢?
训练一个域分类器,让它无法准确地对特征提取器的结果进行分类。(“骗过”分类器,类似GAN的思想)。但是,在GAN里面,生成器是要生成一张图片来骗过判别器,这个是很困难的,而这里如果只是要骗过域分类器就太简单了,直接让域分类器对任意输入都输出0就行了。这样学出来的特征提取器很可能是完全无效的。所以,我们应该给特征提取器增加学习难度。
所以,我们还要求特征提取器的输出能够满足标签预测器(label predictor)的高精度判别需求。
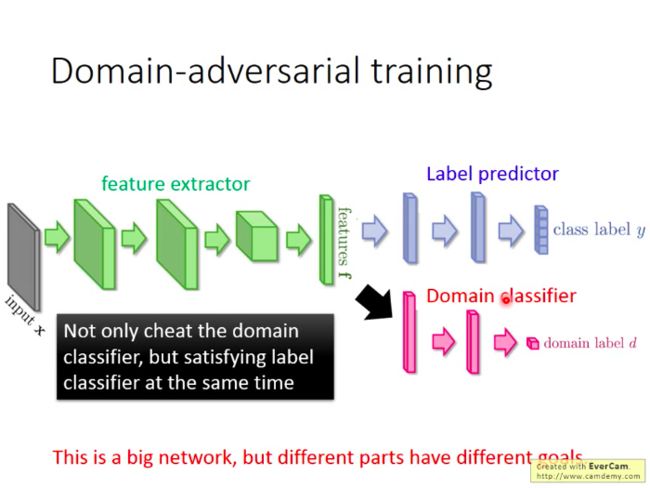
那么如何让特征提取器的训练满足我们上述两个要求呢?也不难,针对标签预测器的反向传播的误差,我们按照误差的方向进行正常的参数调整,而针对域分类器反向传回的误差,我们则按照误差的反方向进行误差调整(即域分类器要求调高某个参数值以提高准确度,而我们就故意调低对应参数值,以“欺负”它)。所以在域分类器的误差上加个负号就可以。
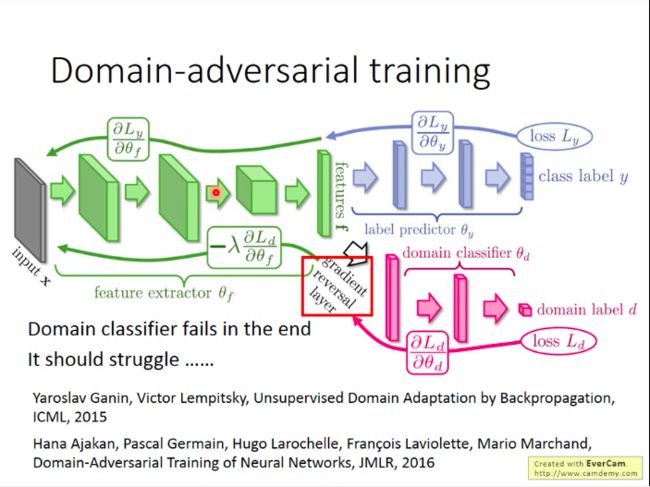
但是还需要注意的是,我们要让域分类器“奋力挣扎”,否则如果特征提取器随便生成的输出都能够骗过域生成器,那可能是域生成器本身的判别能力太差,那这样训练出来的特征提取器可能也其实是很弱的,所以
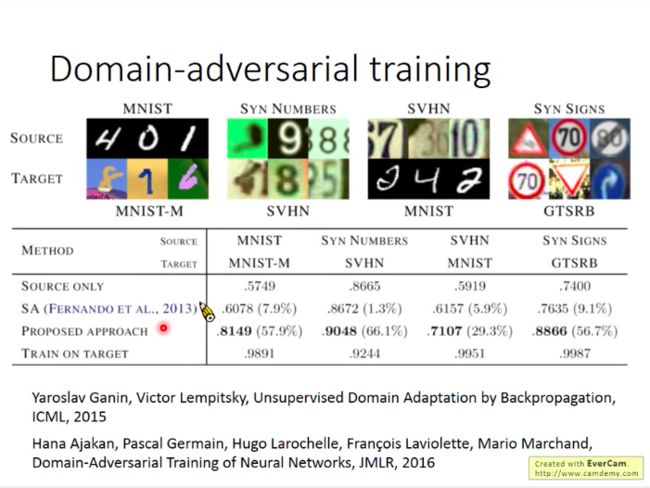
下图是对应论文的一个实验结果:
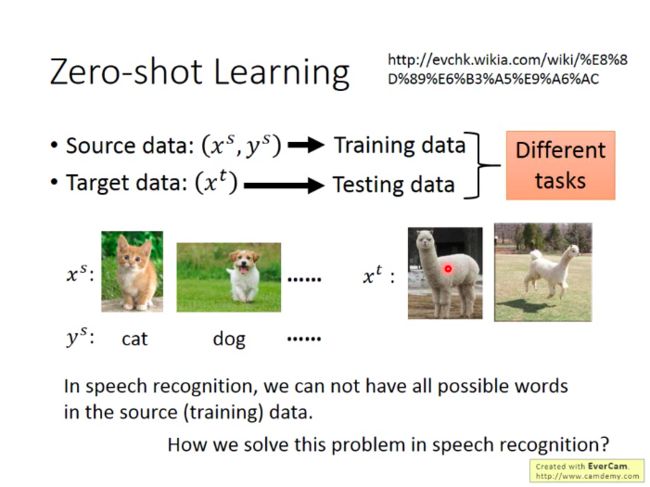
Zero-shot Leaning (labelled source, unlabelled target)
在Zero-shot Learning里面,相对有比Domain-adversarial training更严苛的定义,它要求迁移的两种任务差别也是很大的。
如下图,源数据是猫狗图片,而目标数据是草泥马图片,这两种分类任务属于不同的任务了。
- 影像识别上的做法
我们首先将分类任务中对应的所有分类目标的属性存在数据库里,并且必须保证每个分类目标的属性组合独一无二(属性组合重复的两者将无法在下述方法中区分)。
如下图,那么,我们在学习NN模型时,不再要求NN的输出直接是样例的分类,而要求是对应的分类目标包含哪些属性
。那么,我们再在目标数据/测试数据上做分类时,也只要先用模型获提取出样例的属性,再查表即可。
而如果数据特征变得复杂(比如是图片作为输入),那么我们就可以做embedding,即尝试训练一个NN,将样例特征映射到一个低维的embedding空间,然后让映射后的结果和样例对应的属性尽可能地相近。
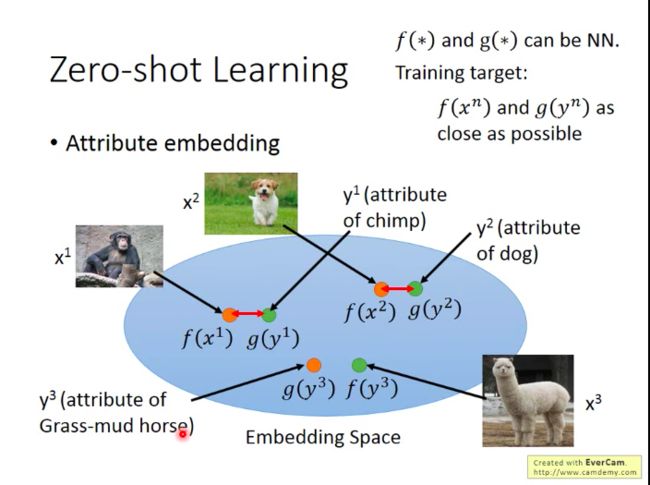
但是,如果我们没有数据库(没有属性数据)呢?
借用Word Vector的概念:word vector的每一个dimension代表了当前这个word的某一个属性,所以其实我们也不需要知道具体每个动物对应的属性是什么,只要知道每个动物对应的word vector就可以了。即将属性换成word vector,再做embedding。
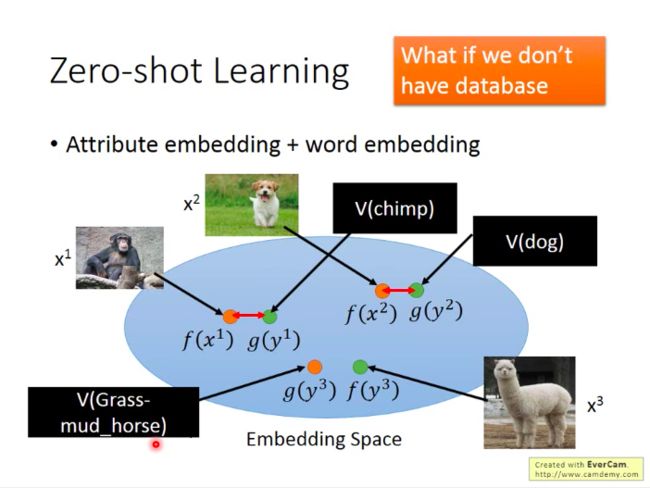
- Zero-shot Learning 的训练
思想:让同一对的x与y尽量靠近,让不同对的x与y尽量远离。

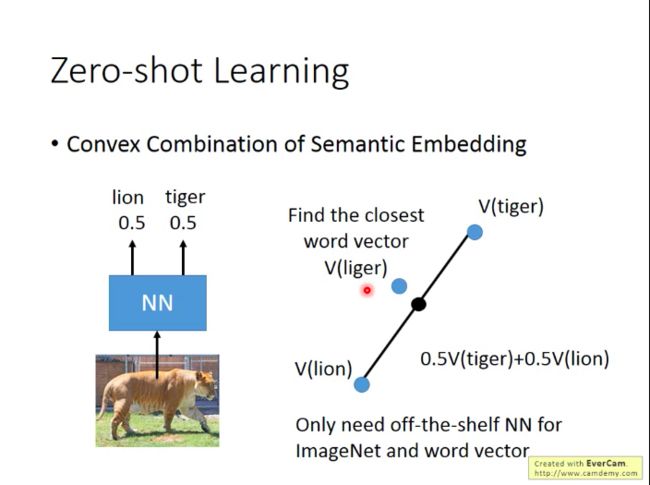
还有一种训练方法更简单:Convex Combination of Semantic Embedding
假设训练出一个狮虎分类器,它对于一张图片给出了“50%是狮子,50%是老虎”的结果,那么我们就将狮子和老虎对应的word vector分别乘以0.5再加和,获得新的vector,看这个vector和哪个动物对应的vector最相近(比如狮虎兽liger最相近)。
而做这个只要求我们有一组word vector和一个语义辨识系统即可。
下图是一个对比普通CNN,做Embedding的Zero-shot Leaning,和Convex Combination of Semantic Embedding三种方法对于Stellar Sealion识别的效果比较:

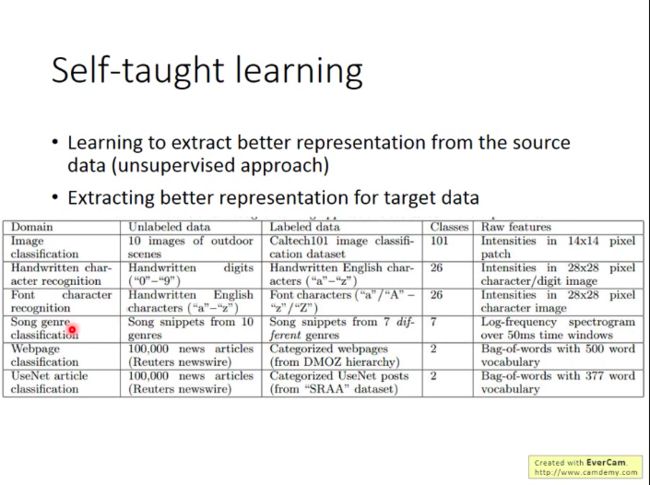
Self-taught learning 和 Self-taught Clustering
这两种都是源数据无标签的。
self-taught learning可以看做一种半监督学习(semi-supervised learning),只是源数据和目标数据关系比较“疏远”。我们可以尝试利用源数据去提取出更好的representation(无监督方法),即学习一个好的Feature extractor,再用这个extractor去帮助有标签的目标数据的学习任务。