RANSAC算法
RANSAC算法全称是随机抽样一致算法(random sample consensus,RANSAC),RANSAC算法的基本假设是样本中包含正确数据(inliers,可以被模型描述的数据),也包含异常数据(outliers,偏离正常范围很远、无法适应数学模型的数据),即数据集中含有噪声。这些异常数据可能是由于错误的测量、错误的假设、错误的计算等产生的。同时RANSAC也假设,给定一组正确的数据,存在可以计算出符合这些数据的模型参数的方法。数据分两种:有效数据(inliers)和无效数据(outliers)。偏差不大的数据称为有效数据,偏差大的数据是无效数据。如果有效数据占大多数,无效数据只是少量时,我们可以通过最小二乘法或类似的方法来确定模型的参数和误差;如果无效数据很多(比如超过了50%的数据都是无效数据),最小二乘法就失效了,我们需要新的算法。
如果一组二位的数据点含有许多噪声点,直接采用最小二乘法求出的数学模型不够准确。而比较好的方法就是用RANSAC算法剔除那些噪声点,获得最大的支持数据集合,再用最大支持数据通过最小二乘求出最佳数学模型。
首先如果没有使用RANSAC算法,通过最小二乘法模拟出的数学模型如下图所示,其中的二位数据是我们随机生成的包含噪声点的数据集合。
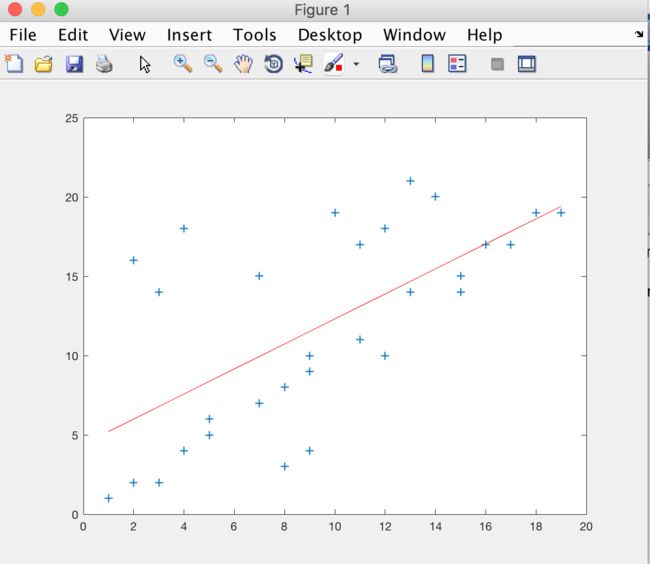
可以看出,上半部分是误差较大的点,而通过最小二乘拟合的直线将噪声点也考虑进去,得到的不是最佳数学模
型。
现在我们采用RANSAC算法剔除一些噪声点后,在进行最小二乘拟合得到的图如下所示。

其中红色的直线是未使用RANSAC算法拟合的直线,蓝色的直线是使用RANSAC算法拟合的直线。从中可以看出使用RANSAC算法之后的数学模型更佳。
算法:
伪代码的算法如下所示:
输入:
Data 一组观测数据
Model 适应于数据的模型
n 适应于模型的最小数据个数
k 算法的迭代次数
t 用于决定数据是否适应于模型的阈值
d 判定模型是否适用于数据集的数据数目
Best_model 与数据最匹配的模型参数(没有返回null)
Best_consensus_set 估计出模型的数据点
Best_error 跟数据相关的估计出的模型错误
iterations = 0
best_model = null
best_consensus_set = null
best_error = 无穷大
while ( iterations < k )
maybe_inliers = 从数据集中随机选择n个点
maybe_model = 适合于maybe_inliers的模型参数
consensus_set = maybe_inliers
for ( 每个数据集中不属于maybe_inliers的点 )
if ( 如果点适合于maybe_model,且错误小于t )
将点添加到consensus_set
if ( consensus_set中的元素数目大于d )
已经找到了好的模型,现在测试该模型到底有多好
better_model = 适合于consensus_set中所有点的模型参数
this_error = better_model究竟如何适合这些点的度量
if ( this_error < best_error )
我们发现了比以前好的模型,保存该模型直到更好的模型出现
best_model = better_model
best_consensus_set = consensus_set
best_error = this_error
增加迭代次数
返回 best_model, best_consensus_set, best_error
这次的模拟实验是使用matlab实现的,详细代码可在此处下载点击打开链接