CP-CNN 论文笔记
Generating High-Quality Crowd Density Maps using Contextual Pyramid CNNs
参考:
- https://blog.csdn.net/zhangjunhit/article/details/78029133
- https://buptldy.github.io/2016/10/29/2016-10-29-deconv/
总的思路:
CP-CNN,设计了两个网络分别用于提取全局上下文信息和局部上下文信息,设计了一个类似mcnn的多列cnn用于将输入数据映射到一个高维度的特征图,将之前提取到的上下文信息和高维特征图融合在一起,输入最后的融合网络,由最后的融合网络生成最终的密度图.
0. Abstract
我们提出了一个新颖的方法,称为上下文金字塔神经网络,通过结合全局的上下文信息和局部的上下文信息来生成高质量的人群密度图和人数估计.
CP-CNN包含了四个模块,全局上下文预测器(GCE),局部上下文预测器(LCE),密度图预测器(DME)以及一个融合网络(F-CNN).
- GCE:是一个基于
VGG-16的神经网络,通过解析全局的上下文信息将输入图片分成不同密度等级. - LCE:类似的,LCE通过解析局部的上下文信息将输入图片patch分成不同密度等级.
- DME:是一个多列的神经网络,(结构类似与MCNN).用于从输入图片生成高维的特征图.该特征图将和GCE及LCE生成的上下文信息融合在一起作为F-CNN的输入.
- F-CNN:使用了一系列的卷积层和小数步长卷积层(解卷积层),使用对抗损失和像素级欧氏损失的组合,以端到端的方式与DME一起进行训练。
1. Introduction
当今社会,人群密度估计被广泛估计.
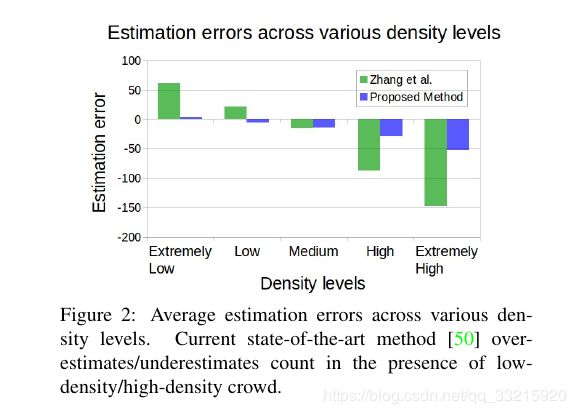
现有的基于CNN的方法运用了不同的多尺度结构,在人群密度估计上取得了巨大的成功.但这些方法在人群低密度和高密度的情况下,估计的误差都比较大.如Figure 2所示.
- 一个可能的解决方法是在训练的时候加入上下文信息的学习.鉴于上下文信息在语义分割等问题上取得的成功,我们相信他会对人群计数很有帮助.
- 现有的方法使用最大池化实现了小的平移不变性,同时也生成了低分辨率,低质量的密度图.
- 同时,据我们所指,现有的大多数方法只关注了人群总数估计的准确性而忽略了生成密度图的质量.
考虑到上述问题,我们提出将上下文信息加入学习过程,以提高密度图的质量.
由于在DME中使用最大池化层会导致低分辨率的密度图,F-CNN被设计成使用一系列的小数步长卷积层(解卷积层)来提高分辨率,从而产生高质量的密度图.同时损失函数使用了对抗损失和像素级欧氏损失的组合.对抗性损失的使用帮助我们克服了通过将欧几里得损失最小化而获得的模糊结果的问题。
总的来说,我们的主要的贡献为:
- 提出了CP-CNN,在密度估计过程中加入了全局和局部的上下文信息
- 我们是第一个专注与生成高密度的密度图,通过和其他几个方法的比较,我们获得了当前最好的结果
- 加入了对抗损失
- 我们在三个数据集上进行了测试,并与现存的最好的方法进行了对比.进行了模型简化测试来证明加入上下文信息和对抗损失后得到的提升.
2. Related work
3. Proposed method (CP-CNN)
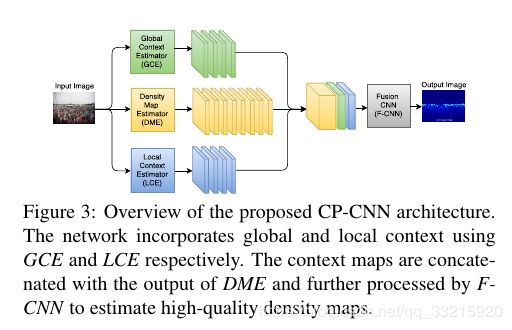
CP-CNN的结构如Figure3所示,包含了GCE, LCE, DME,F-CNN四个模块.
GCE和LCE用于提取输入图像的全局和局部的上下文信息,并和DME生成的高维特征图融合在一起输入F-CNN,最后由F-CNN生成高质量的密度图.
3.1 Global Context Estimator (GCE)
如前面所述,现有的多尺度,多列方法在低密度和高密度的情况下会产生错误的估计,我们相信加入全局的
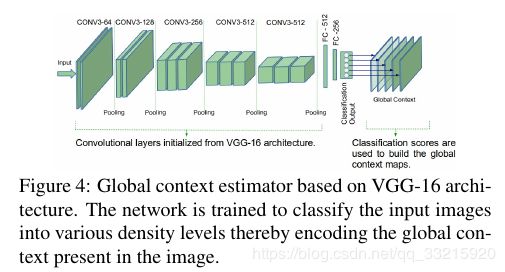
的上下文信息能改善这种情况.为达到这种目的,我们考虑通过学习图片的全局上下文信息,来将输入图片分成五类:极低密度(ex-lo),低密度(lo),中等密度(med),高密度(hi),极高密度(ex-hi).
Note:不同的数据集需要的密度类别数量不同,尺度变化多的会需要更多的密度类别,但是我们发现仅适用五类就可以明显提升密度图估计效果.
我们微调了VGG-16来完成分类任务,GCE的结构如Figure4所示,我们保留了VGG-16的所有卷积层,用新的全连接层替换掉了最后的三个全连接层来完成分类任务.后面两个卷积层参数被微调,其他卷积层参数固定不变。
3.2. Local Context Estimator (LCE)
当前的人群密度估计方法更侧重于降低人群总数估计的误差,所以它们的人群密度图质量相对降低,我们相信某些局部的上下文信息能够帮助我们提升密度图质量。和 GCE 思路类似,这里我们使用一个 CNN网络将图像根据其人群密度分为5类, {ex-lo, lo,med, hi, ex-hi} ,LCE的结构如Figure5.包括一系列的卷积层和最大池化层,然后是三个全连接层,在前两个全连接层之后加入了适当drop-out层,最后一个全连接层之后跟着一个sigmoid层,其他所有卷积层和全连接层都跟着RELU层.

3.3. Density Map Estimator (DME)
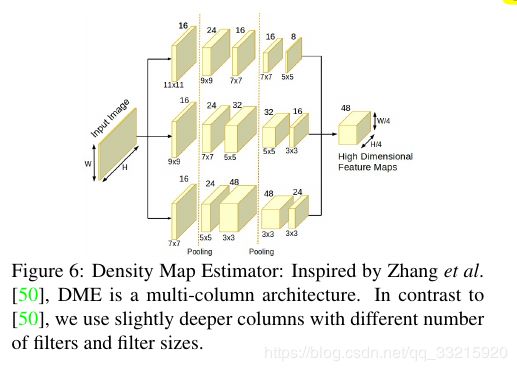
我们使用类似MCNN的多列网络结构,并使用了更深的网络,修改了卷积核的尺寸和个数.DME将输入图片映射到高维的特征图,而不是直接生成密度图.网络细节如Figure 6 所示.
注意:不同的数据集的人头尺寸不同,卷积核需要进行相应的修改,下面网络是针对所有数据集,并不是最佳的解决办法.
3.4. Fusion-CNN (F-CNN)
在DME中使用最大池化层(这对于实现平移不变性是必不可少的),导致了变小的特征图和细节的丢失.为了生成高分辨率高质量的密度图,F-CNN使用了一系列卷积层和小数步长卷积层,小数步长卷积层帮助我们重建密度图的细节.
F-CNN的结构为:CR(64,9)-CR(32,7)-TR(32)-CR(16,5)-TR(16)-C(1,1),C:卷积层,R:relu层,T:小数步长卷积层(反卷积层),小数步长卷积层保证了输入和输出的大小相同.
上下文预测网络(GCE,LCE)预先训练,DME和F-CNN采用端到端的训练方式.为了弥补L2损失的模糊效果,我们加入了对抗损失,F-CNN和DME的损失函数定义如下:
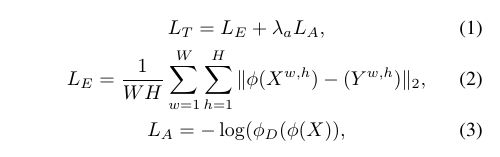
L T L_T LT:总的损失, L E L_E LE:L2损失, L A L_A LA:对抗损失.X是W x H的输入图像,Y是ground truth密度图.
φ φ φ是DME和F-CNN网络, φ D φ_D φD:用于计算对抗损失的判别器网络.其结构为: CP(64)-CP(128)-M-CP(256)-M-CP(256)-CP(256)-M-C(1)-Sigmoid,C:卷积层,P:PRelu层,M:max-pooling层.
4. Training and evaluation details
- 数据集:GCE训练集取原图随机位置的1/4大小的patch,LCE训练集取原图随机位置64x64的pathch.
- GCE基于
VGG-16,所以输入图片被resize成224x224,LCE用64x64的patch训练,训练的ground truth种类由图片的人数决定.GCE,LCE都使用交叉熵损失.
全局上下文信息 F g c i F^i_{gc} Fgci由以下方法生成:
- 先生成一个空的 F g c i F^i_{gc} Fgci尺寸为 5 ∗ W i / 4 ∗ H i / 4 5 * W_i/4 * H_i/4 5∗Wi/4∗Hi/4,(W,H是X的尺寸,5是类别数), X i X_i Xi输入GCE后会得到五个类别的分类分数 y g c i , j y_{gc}^{i,j} ygci,j, F g c i , j F^{i,j}_{gc} Fgci,j每一层,用相应的分类分数 y g i , j y^{i,j}_g ygi,j填充.
- 局部上下文信息 F l c i F^i_{lc} FlciKaTeX数学公式采用类似方法.
5. Experimental results
评估方法:
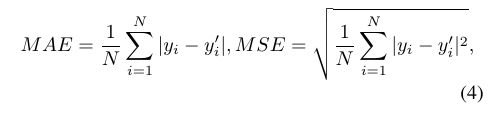
5.1. Ablation study using ShanghaiTech Part A

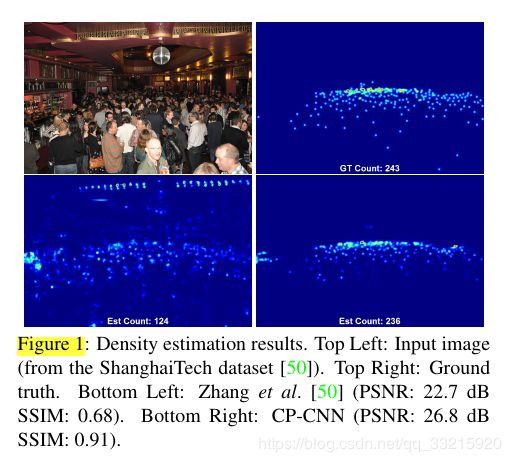
效果图:
上海Tech数据集的结果:
