AAAI 2018: 基于强化学习的文本分类
看这篇论文前,建议先了解一下policy gradient RL,就更很容易理解论文思想了。
论文:《Learning Structured Representation for Text Classification via Reinforcement Learning》
代码:http://coai.cs.tsinghua.edu.cn/publications/
一、论文原理
这篇论文在文本分类任务中,应用了policy gradient强化学习的方法,来得到更好的句子结构化表征(ID-LSTM model保留有用单词,删除无用的单词如"a","the"等;HS-LSTM model将整个序列划分为多个短语结构),从而得到更好的文本分类效果。
二、模型结构
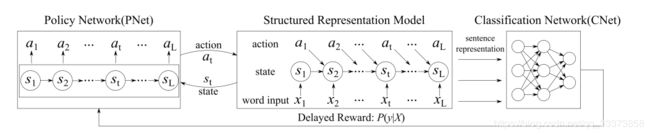
模型分为三个部分:
策略网络(PNet)、结构化表示结构(两个LSTM Module)、分类网络(CNet).
这里的两个LSTM Module是分别训练的,PNet决定Information Distilled LSTM (ID-LSTM)中是否保留当前单词,action为{Retain, Delete};PNet决定Hierarchically Structured LSTM (HS-LSTM) 中word-level lstm当前单词是否是短语结束位置/短语中,action为{Inside, End},再将判断的短语输入phrase-level lstm得到序列结构化特征。 下面会详细介绍。
-
策略网络(PNet)根据 结构化表示模型(LSTM Model) 中每一个step的输入和上一层隐层状态决定当前采取的action (即是否保留/删除该单词、该单词是否在短语中/结束处)。
-
在完成一序列action后,结构化表示模型(LSTM Model) 输出最终的文本特征。
-
分类网络(CNet)对输入的文本特征分类,根据分类结果对策略网络(PNet)提供Reward,训练PNet。
三、具体公式
1.Policy Network (PNet)
PNet采用随机策略:
![]()
上述公式中, 为当前状态, 为sigmoid, 为采用action 的概率
由分类网络CNet文本分类的结果得到,再送入PNet进行策略网络的训练。
2. Structured Representation Models
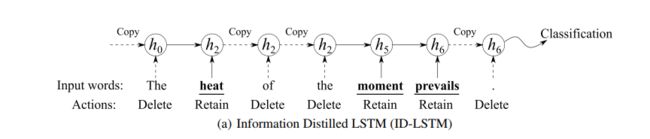

(a) Information Distilled LSTM (ID-LSTM)
1)PNet决定输入序列 的每一个step的action
也就是在每一个 输入时,决定该单词是保留还是删除,具体公式如下:
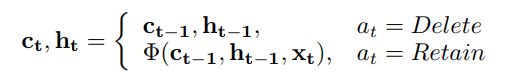
如果delete,则复制上一个step网络的状态, 不作输入。 如果retain,则将上一step状态以及当前 输入lstm中。
2)PNet网络状态 的计算:
![]()
也就是上一个step状态与当前输入拼接。
这样做的目的是保留序列中的有用的单词,删去无用的单词,获得更好的文本特征。
3)将文本特征输入分类网络CNets,根据分类结果,得到Reward:
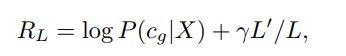
其中,超参的损失项部分 是为了尽可能多的删除无用单词。
(b)Hierarchically Structured LSTM (HS-LSTM)
HS-LSTM为两级结构:连接单词序列以形成短语的 word-level LSTM;以及连接短语以形成句子特征的phrase-level LSTM
1)word-level LSTM
在每一个 输入时,PNet策略网络决定该单词是处于短语中还是短语结束处,最终连接单词形成短语的结构,具体公式如下:
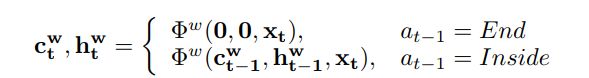
如果上一个step为end,则代表当前位置是一个新的短语,应该丢去上一step的特征,只输入当前 x_{t} 如果上一个step为end, 则代表当前位置与之前的单词是在一个短语中,则将上一step状态以及当前 x_{t} 输入lstm中。
下面的表格表达了{inside,end}表示的含义:

2)phrase-level LSTM
将word-level LSTM中,每一个action为end处(每当连接成一个短语时)的状态向量输入phrase-level LSTM中,再通过策略网络决定当前step是否在句子中还是在结尾处:
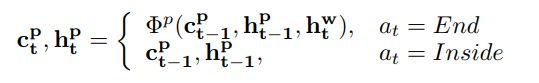
3)PNet网络状态 的计算:
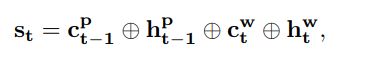
3)将结构化文本特征输入分类网络CNets,根据分类结果,得到Reward:
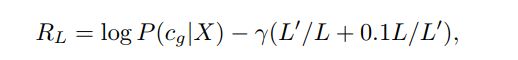
这里的损失项:
![]()
限制一个句子的短语数不多也不少,例如在单词长度为10的句子中,短语数为3~4个
3. Classification Network (CNet)
分类网络CNet使用交叉熵损失:
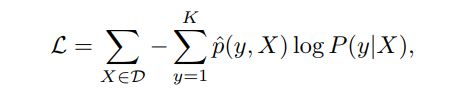
四、训练细节

五、总结
通过强化学习的方法得到更好的句子结构特征,再进行分类,可以得到更好的分类效果。