Python网络爬虫(一):爬取51job前程无忧网数据并保存至MongoDB数据库
Python网络爬虫(一):爬取51job前程无忧网数据并保存至MongoDB数据库
前言
参考博客: link.Python爬虫(7):多进程抓取拉钩网十万数据:
版本:Python3.7
编辑器:PyCharm
数据库:MongoDB
整体思路:
1.网页解析,查找所需信息的位置
2.开始网页爬取
3.爬取结果存入MongoDB数据库
爬虫
1.网页解析
打开网页后发现共有四大类求职岗位,分别是:互联网/电子商务、金融/投资/证券、汽车及零配件、房地产。打开开发者工具,查看四大类求职岗位的地址。
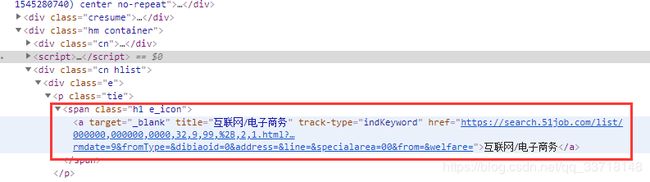
如:进入“互联网/电子商务”该类,对具体岗位信息进行查找。以当时网页第一个职位—“大客户销售”为例,可以发现我们所需的信息即职位、公司、所在地、薪水、发布日期。
 前期准备工作完成,下面就开始爬虫了。
前期准备工作完成,下面就开始爬虫了。
2.网页爬取
整个爬虫项目分为四个部分:主程序、MongoDB信息配置、网页索引、职位爬取与保存
1).主程序
# -*- coding:utf-8 -*-
import time
from multiprocessing import Pool
from job_spider import parse_link
from job_indexspider import parse_index
def main(data):
url = data['url']
print(url)
mongo_table = data['name']
if mongo_table[0] == '.':
mongo_table = mongo_table[1:]
parse_link(url, mongo_table)
if __name__ == '__main__':
t1 = time.time()
pool = Pool(processes=4)
datas = (data for data in parse_index())
pool.map(main, datas)
pool.close()
pool.join()
print(time.time() - t1)
2).MongoDB信息配置
# 配置数据库信息
MONGO_URL = 'localhost' # 数据库地址
MONGO_DB = '51job' # 数据库名称
3).网页索引
通过四大类:互联网/电子商务、金融/投资/证券、汽车及零配件、房地产的网页地址跳转至具体的岗位信息
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
def get_html(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/70.0.3538.77 Safari/537.36'
}
try:
resp = requests.get(url, headers=headers)
resp.encoding = 'gbk'
if resp.status_code == 200:
print('ok')
return resp.text
return None
except RequestException:
return None
def parse_index():
url = 'https://www.51job.com/'
soup = BeautifulSoup(get_html(url), 'lxml')
all_positions = soup.select('div.cn.hlist > div.e > p.tie > span > a')
joburls = [i['href'] for i in all_positions]
jobnames = [i.get_text() for i in all_positions]
for joburl, jobname in zip(joburls, jobnames):
data = {
'url': joburl,
'name': jobname
}
yield data
4).具体职位爬取
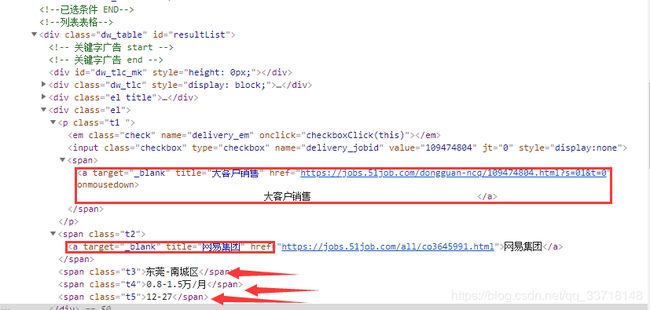
通过网页解析,找出爬取信息所在的位置
# -*- coding:utf-8 -*-
import requests
import pymongo
from job_config import *
from bs4 import BeautifulSoup
import time
client = pymongo.MongoClient(MONGO_URL, 27017)
db = client[MONGO_DB]
headers = { # 添加头文件信息
'Cookie': 'partner=www_baidu_com; guid=37fd16514480c0e72b0eca35e74ce4f6; '
'51job=cenglish%3D0%26%7C%26; '
'nsearch=jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%'
'26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_'
'expansion%3D; search=jobarea%7E%60070300%7C%21ord_field%7E%600%7C%21recentSearch0%7E%601%A1%FB%A1%'
'FA070300%2C00%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA33%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%'
'FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA%BC%BC%CA%F5%D6%A7%'
'B3%D6%A1%FB%A1%FA2%A1%FB%A1%FA%A1%FB%A1%FA-1%A1%FB%A1%FA1541487347%A1%FB%A1%FA0%A1%'
'FB%A1%FA%A1%FB%A1%FA%7C%21recentSearch1%7E%601%A1%FB%A1%FA070300%2C00%A1%FB%A1%'
'FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA26%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA99%A1'
'%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA%D4%EC%BC%DB%CA%A6'
'%A1%FB%A1%FA2%A1%FB%A1%FA%A1%FB%A1%FA-1%A1%FB%A1%FA1541487342%A1%FB%A1%FA0%A1%FB%A1'
'%FA%A1%FB%A1%FA%7C%21recentSearch2%7E%601%A1%FB%A1%FA070300%2C00%A1%FB%A1%FA000000%A1%'
'FB%A1%FA0000%A1%FB%A1%FA32%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1'
'%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA2%A1%FB%A1%FA%A1%FB%A1%FA-1%A1%FB%A1%'
'FA1541486574%A1%FB%A1%FA0%A1%FB%A1%FA%A1%FB%A1%FA%7C%21recentSearch3%7E%601%A1%FB%A1%'
'FA070300%2C00%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA32%A1%FB%A1%FA9%A1%FB%A1%'
'FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%'
'FA%C7%B0%B6%CB%BF%AA%B7%A2%A1%FB%A1%FA2%A1%FB%A1%FA%A1%FB%A1%FA-1%A1%FB%A1%FA1541486453%'
'A1%FB%A1%FA0%A1%FB%A1%FA%A1%FB%A1%FA%7C%21recentSearch4%7E%601%A1%FB%A1%FA020000%2C00%A1'
'%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%'
'FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA%C8%CB%B9%A4%D6%C7%C4%DC%'
'A1%FB%A1%FA2%A1%FB%A1%FA%A1%FB%A1%FA-1%A1%FB%A1%FA1541484969%A1%FB%A1%FA0%A1%FB%A1%FA%A1%'
'FB%A1%FA---------------------+%D7%F7%D5%DF%A3%BA%C6%BD%D4%AD2018+%C0%B4%D4%B4%A3%BACSDN+%'
'D4%AD%CE%C4%A3%BAhttps%2F%2Fblog.csdn.net%2Fsinat_30353259%2Farticle%2Fdetails%2F80600800'
'+%B0%E6%C8%A8%C9%F9%C3%F7%A3%BA%B1%BE%CE%C4%CE%AA%B2%A9%D6%F7%D4%AD%B4%B4%CE%C4%D5%C2%A3%'
'AC%D7%AA%D4%D8%C7%EB%B8%BD%C9%CF%B2%A9%CE%C4%C1%B4%BD%D3%A3%A1%7C%21',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/58.0.3029.110 Safari/537.36',
'Connection': 'keep-alive'
}
def parse_link(url, mongo_table): # 具体求职岗位所在网页,进行爬取
for page in range(1, 400): # 在网页中查看四大类可知页数不超过400
# url_abbr示例:https://search.51job.com/list/070300,000000,0000,03,9,99,%2B,2,2.html?
url_abbr = url.split('lang')[0] # 去除一大段后缀,不影响网页打开
url_1 = url_abbr[:-7]
link = '{}{}.html'.format(url_1, str(page)) # 跳页
resp = requests.get(link, headers=headers)
resp.encoding = 'gbk'
if resp.status_code == 404:
pass
else: # 网页解析
soup = BeautifulSoup(resp.text, 'lxml')
total_list = soup.find('div', attrs={'id': 'resultList'})
total = total_list.find_all('div', attrs={'class': 'el'})
total.pop(0)
for i in total:
if len(total) == 0: # 对total表数目进行判断,为0的可知跳页结束
break
job = i.find('p').find('a')['title']
company = i.find('span', attrs={'class': 't2'}).find('a').string
location = i.find('span', attrs={'class': 't3'}).string
salary = i.find('span', attrs={'class': 't4'}).string
date = i.find('span', attrs={'class': 't5'}).string
data = {
'job': job,
'company': company,
'location': location,
'salary': salary,
'date': date
}
save_database(data, mongo_table)
time.sleep(6) # 合理控制速度,每翻一次页,停止6秒
def save_database(data, mongo_table):
if db[mongo_table].insert_one(data):
print('保存数据库成功', data)
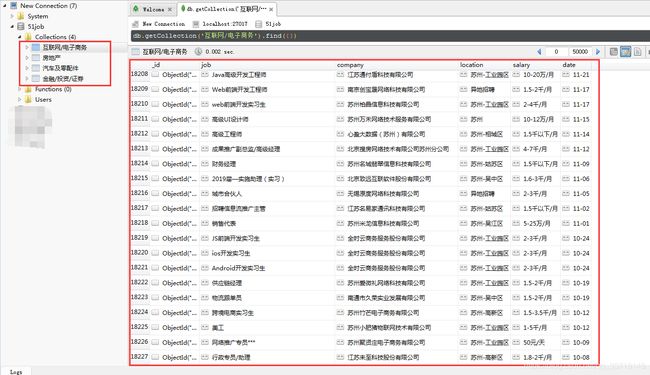
3. 爬虫结果展示
爬虫结果: