scrapy爬取豆瓣电影列表
目标环境:
python 3.6
scrapy 1.5.0
准备:
安装scrapy ,参考:http://blog.csdn.net/yctjin/article/details/70658811
检查是否安装成功 ,在命令行输入:scrapy -version
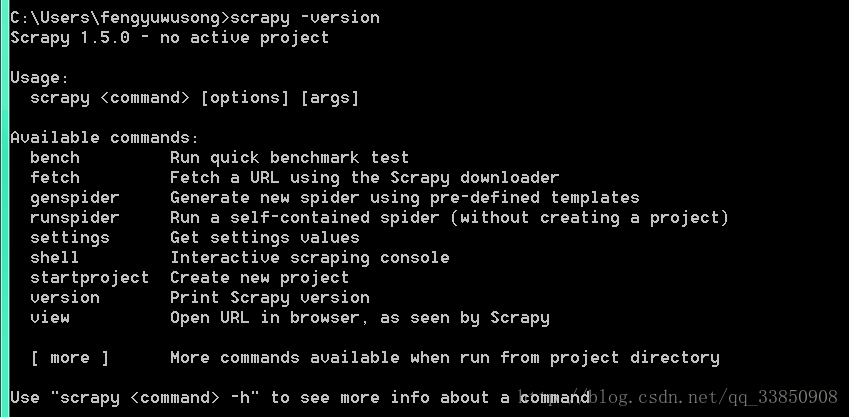
如图所示则安装成功~
开始新建项目
在准备好的文件夹打开命令行,分别输入
scrapy startproject doubanMovie
cd doubanMovie
scrapy genspider doubanMovieSpider movie.douban.com/cinema/nowplaying/guangzhou/
得到结果如下所示:
D:\pythonProject\python\scrapy\test>scrapy startproject doubanMovie
New Scrapy project ‘doubanMovie’, using template directory ‘e:\python\lib\site-packages\scrapy\templates\project’, created in:
D:\pythonProject\python\scrapy\test\doubanMovieYou can start your first spider with:
cd doubanMovie
scrapy genspider example example.comD:\pythonProject\python\scrapy\test>cd doubanMovie
D:\pythonProject\python\scrapy\test\doubanMovie>scrapy genspider doubanMovieSpider movie.douban.com/cinema/nowplaying/guangzhou/
Created spider ‘doubanMovieSpider’ using template ‘basic’ in module:
doubanMovie.spiders.doubanMovieSpider
在文件夹中输入命令 tree/f , 如文件目录如下所示这说明成功:
D:.
│ scrapy.cfg
│
└─doubanMovie
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ init.py
│
├─spiders
│ │ doubanMovieSpider.py
│ │ init.py
│ │
│ └─pycache
│ init.cpython-36.pyc
│
└─pycache
settings.cpython-36.pyc
init.cpython-36.pyc
目录文件解释:
其中最主要用到的文件有4个:分别是items.py,pipelines.py,settings.py,doubanMovieSpider.py
items.py:
定义爬虫最终需要哪些项,相当于python里的字典
settings.py
配置项目,决定由谁去处理爬取的内容
pipelines.py
当scrapy爬虫抓取到网页数据后,数据如何处理取决于该文件如何设置
doubanMovieSpider.py
决定怎么爬取目标网站
其他文件
.pyc文件后缀的为python程序编译得到的字节码文件,_ init _.py文件将上级目录变成一个模块,middlewares.py 中间件,暂时没有用到。
目标url:
https://movie.douban.com/cinema/nowplaying/guangzhou/
抓取该网站上的电影名称
爬虫编写
- 由于我们只需要爬取电影名称,故修改items.py:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
moiveName = scrapy.Field()
与最初对比只是去掉了pass,增加了moiveName = scrapy.Field() 成员,相当于将类当成字典作用
2 . 定义怎么爬取 doubanMovie.py:
# -*- coding: utf-8 -*-
from doubanMovie.items import DoubanmovieItem
import scrapy
class DoubanspiderSpider(scrapy.Spider):
name = 'doubanSpider'
allowed_domains = ['movie.douban.com/cinema/nowplaying/guangzhou/']
start_urls = ['http://movie.douban.com/cinema/nowplaying/guangzhou//']
def parse(self, response):
subSelector = response.xpath('//li[@class="stitle"]')
items = []
for sub in subSelector:
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('./a/text()').extract()
items.append(item)
return items
在该文件类DoubanSpider中,方法parse中的response参数即为抓取后的结果,我们打开目标url:https://movie.douban.com/cinema/nowplaying/guangzhou/,按F12 分析可以发现: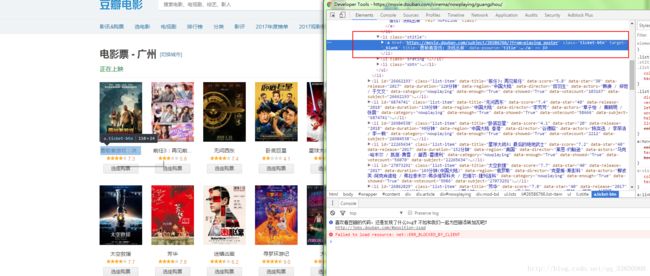
通过F12左上角的小箭头点击电影名称,可以找到电影名称对应的节点:
"stitle">
"https://movie.douban.com/subject/26586766/?from=playing_poster" class="ticket-btn" target="_blank" title="勇敢者游戏:决战丛林" data-psource="title">
勇敢者游戏:决...
发现其在class=’stitle‘的 li标签中 ,故我们可以利用scrapy的xpath嵌套查询,先是查找所有该li标签
subSelector = response.xpath('//li[@class="stitle"]')然后再通过for循环进一步获得所有电影的名称并添加到items中:
items = []
for sub in subSelector:
item = DoubanmovieItem()
item['moiveName'] = sub.xpath('./a/text()').extract()
items.append(item)
return items这里注意返回的是items。items是由DoubanmovieItem()对象组成的列表。
3 . 保存抓取结果 pipelines.py
修改pipelines.py:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import time
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
now = time.strftime('%Y-%m-%d', time.localtime())
fileName = 'douban' + now + '.txt'
with open(fileName, 'a', encoding='utf-8') as fp:
fp.write(item['moiveName'][0])
return item
这里的参数item是由之前返回的,故将其写入文件中即可。
- 分配任务的settings.py:
修改settings.py,将下列内容注释取消,这里的意思是告诉scrapy最终结果由pipelines模块的DoubanmoviePipeline类来执行处理,value300的意思是执行顺序,多个处理方式的时候,数字越小的优先执行:
ITEM_PIPELINES = {
‘doubanMovie.pipelines.DoubanmoviePipeline’: 300,}
并且注意添加header头,否则会出现403跳转
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'具体内容如下所示:
# -*- coding: utf-8 -*-
# Scrapy settings for doubanMovie project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'doubanMovie'
SPIDER_MODULES = ['doubanMovie.spiders']
NEWSPIDER_MODULE = 'doubanMovie.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'doubanMovie (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'doubanMovie.middlewares.DoubanmovieSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'doubanMovie.middlewares.DoubanmovieDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'doubanMovie.pipelines.DoubanmoviePipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
测试结果
在项目任意目录中打开命令行,输入scrapy crawl doubanSpider 可得结果:
D:\pythonProject\python\scrapy\doubanMovie>scrapy crawl doubanSpider
2018-01-15 12:58:56 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: doubanMovie)
2018-01-15 12:58:56 [scrapy.utils.log] INFO: Versions: lxml 4.1.1.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.3.1, w3lib 1.18.0, Twisted 17.9.0, Python 3.6.0 (v3.6.0:
41df79263a11, Dec 23 2016, 07:18:10) [MSC v.1900 32 bit (Intel)], pyOpenSSL 17.5.0 (OpenSSL 1.1.0g 2 Nov 2017), cryptography 2.1.4, Platform Windows-7-6.1.7601-SP1
2018-01-15 12:58:56 [scrapy.crawler] INFO: Overridden settings: {‘BOT_NAME’: ‘doubanMovie’, ‘NEWSPIDER_MODULE’: ‘doubanMovie.spiders’, ‘ROBOTSTXT_OBEY’: True, ‘SPIDER
_MODULES’: [‘doubanMovie.spiders’], ‘USER_AGENT’: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36’}
2018-01-15 12:58:57 [scrapy.middleware] INFO: Enabled extensions:
[‘scrapy.extensions.corestats.CoreStats’,
‘scrapy.extensions.telnet.TelnetConsole’,
‘scrapy.extensions.logstats.LogStats’]
2018-01-15 12:58:58 [scrapy.middleware] INFO: Enabled downloader middlewares:
[‘scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware’,
‘scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware’,
‘scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware’,
‘scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware’,
‘scrapy.downloadermiddlewares.useragent.UserAgentMiddleware’,
‘scrapy.downloadermiddlewares.retry.RetryMiddleware’,
‘scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware’,
‘scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware’,
‘scrapy.downloadermiddlewares.redirect.RedirectMiddleware’,
‘scrapy.downloadermiddlewares.cookies.CookiesMiddleware’,
‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware’,
‘scrapy.downloadermiddlewares.stats.DownloaderStats’]
2018-01-15 12:58:58 [scrapy.middleware] INFO: Enabled spider middlewares:
[‘scrapy.spidermiddlewares.httperror.HttpErrorMiddleware’,
‘scrapy.spidermiddlewares.offsite.OffsiteMiddleware’,
‘scrapy.spidermiddlewares.referer.RefererMiddleware’,
‘scrapy.spidermiddlewares.urllength.UrlLengthMiddleware’,
‘scrapy.spidermiddlewares.depth.DepthMiddleware’]
2018-01-15 12:58:58 [scrapy.middleware] INFO: Enabled item pipelines:
[‘doubanMovie.pipelines.DoubanmoviePipeline’]
2018-01-15 12:58:58 [scrapy.core.engine] INFO: Spider opened
2018-01-15 12:58:58 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-01-15 12:58:58 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-01-15 12:58:59 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to
若response为200 则为成功,可在目录下找到文件douban+日期.txt 内容为:
勇敢者游戏:决...
前任3:再见前...
无问西东
卧底巨星
星球大战8:最...
太空救援
芳华
迷镇凶案
寻梦环游记
大世界
妖猫传
二代妖精之今生...
妖铃铃
时空终点
解忧杂货店
帕丁顿熊2
心理罪之城市之...
尼斯·疯狂的心...
机器之血
至爱梵高·星空...
至暗时刻
小猫巴克里
天籁梦想
我的影子在奔跑...
一个人的课堂
芒刺
英雄本色201...
奇迹男孩
第一夫人
神秘巨星
公牛历险记
谜巢
梭哈人生