python爬虫爬取拉勾网职业信息
先放成果
- 招聘关键字词云

- 公司关键字词云

代码git地址:https://github.com/fengyuwusong/lagou-scrapy
目标
抓取拉钩关于java工程师的招聘信息并制作成词云图。
研究目标网站
打开拉钩网可以发现目标url为:https://www.lagou.com/zhaopin/Java/2/?filterOption=2 ,这通过翻页发现filterOption=2对应的是页码,这可以通过总页数遍历的方式爬取所有信息。
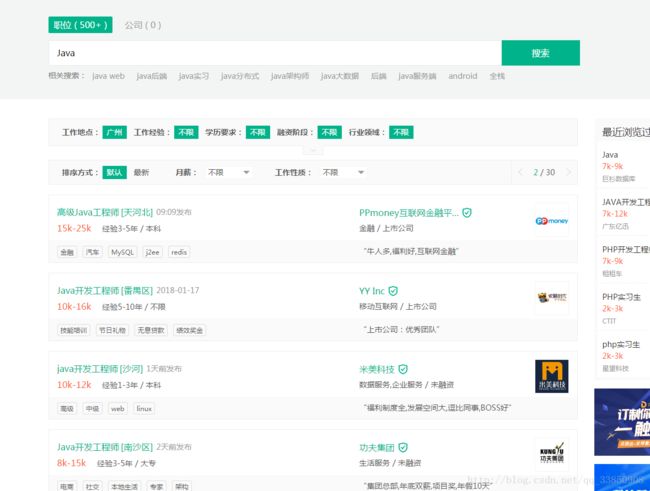
我们可以抓取得数据有:
公司名、发布日期、工资、最低需求、工作标签、公司名、公司类型、公司地址、公司关键词
开始scrapy项目:
具体参考我的上一遍文章:http://blog.csdn.net/qq_33850908/article/details/79063271
编写代码:
items.py:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class LagouItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
day = scrapy.Field()
salary = scrapy.Field()
require = scrapy.Field()
tag = scrapy.Field()
keyWord = scrapy.Field()
companyName = scrapy.Field()
companyType = scrapy.Field()
location = scrapy.Field()
这里没什么好说的,就是吧要抓取的数据列出来。
middlewares.py
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
import random
from scrapy import signals
import unit.userAgents as userAgents
from unit.proxyMysql import sqlHelper
class LagouSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class LagouDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# 设置随机header
PIUA = random.choice(userAgents.pcUserAgent)
request.headers.setdefault('User-Agent', PIUA)
# mysql = sqlHelper("localhost", "root", "admin", "proxy")
# server = mysql.getByRandom()
# request.meta['proxy'] = server
request.meta['proxy'] = 'https://116.11.254.37:80'
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
这里修改75行代码,作用是随机选择一个header头进行请求,防止拉钩检测到我们是一个爬虫。并且使用代理ip。https://116.11.254.37:80。这里需要将userAgents类放入python的lib中,他是一个header字典。
lagouSpider.py:
# -*- coding: utf-8 -*-
import scrapy
from lagou.items import LagouItem
class LagouspiderSpider(scrapy.Spider):
name = 'lagouSpider'
allowed_domains = ['www.lagou.com']
start_urls = []
for i in range(1, 30):
start_urls.append('https://www.lagou.com/zhaopin/Java/2/?filterOption=' + str(i))
def parse(self, response):
items = []
datas = response.xpath("//ul[@class='item_con_list']/li")
for data in datas:
item = LagouItem()
item['name'] = data.xpath(".//a[@class='position_link']/h3/text()").extract()[0]
item['location'] = data.xpath(".//a[@class='position_link']/span/em/text()").extract()[0]
item['day'] = data.xpath(".//span[@class='format-time']/text()").extract()[0]
item['companyName'] = data.xpath(".//div[@class='company_name']/a/text()").extract()[0]
item['companyType'] = data.xpath(".//div[@class='industry']/text()").extract()[0].strip()
item['salary'] = data.xpath(".//div[@class='li_b_l']/span[@class='money']/text()").extract()[0]
item['require'] = data.xpath(".//div[@class='p_bot']/div[@class='li_b_l']/text()").extract()[2].strip()
item['tag'] = str(data.xpath(".//div[@class='list_item_bot']/div[@class='li_b_l']/span/text()").extract())
item['keyWord'] = data.xpath(".//div[@class='list_item_bot']/div[@class='li_b_r']/text()").extract()[0]
items.append(item)
return items
lagouSpider负责解析抓取到的页面,打开拉钩网后打开F12 通过点击需要爬取的内容可以发现他在对应的那个标签下,在通过xpath进行解析获取。例如:
通过截图页面发现,工作名称在class名为’item_con_list’的li下的a下的h3标签内,而其他内容也在这个ul的li下:
故我们可以先获取这个ul的每个li:datas = response.xpath("//ul[@class='item_con_list']/li"),然后再通过嵌套的方法用for循环依次获取内容,例如获取职位名称:item['name'] = data.xpath(".//a[@class='position_link']/h3/text()").extract()[0]
这里最后通过scrapy shell ‘目标url’的方法先是测试一下再开始写。
pipelines.py:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import time
import pymysql
class sqlHelper(object):
def __init__(self, host, user, password, database):
# 打开数据库连接
self.db = pymysql.connect(host, user, password, database, use_unicode=True, charset="utf8")
# 使用 cursor() 方法创建一个游标对象 cursor
self.cursor = self.db.cursor()
# 析构函数关闭连接
def __del__(self):
self.cursor.close()
# 关闭数据库连接
self.db.close()
# 插入数据库
def insert(self, name, salary, require, tag, companyName, companyType, location, keyWord, day):
sql = "insert into lagou values(null,\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\")" % (
name, salary, require, tag, companyName, companyType, location, keyWord, day)
print(sql)
try:
# 执行sql语句
self.cursor.execute(sql)
# 提交到数据库执行
self.db.commit()
except:
# 如果发生错误则回滚
self.db.rollback()
class LagouPipeline(object):
def process_item(self, item, spider):
sql = sqlHelper("localhost", "root", "admin", "lagou")
sql.insert(item['name'], item['salary'], item['require'], item['tag'], item['companyName'], item['companyType'],
item['location'], item['keyWord'], item['day'])
return item这里是对爬取并解析后的item进行处理,我们的处理方法是保存进数据库等待wordCloud来生成词云。
setting.py:
# -*- coding: utf-8 -*-
# Scrapy settings for lagou project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'lagou'
SPIDER_MODULES = ['lagou.spiders']
NEWSPIDER_MODULE = 'lagou.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'lagou (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 10
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'lagou.middlewares.LagouSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'lagou.middlewares.LagouDownloaderMiddleware': 30,
}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'lagou.pipelines.LagouPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
这里需要编写的有
第22行ROBOTSTXT_OBEY = False,即不遵守目标网址的rebots.txt文本
第30行DOWNLOAD_DELAY = 10,即每次请求间隔10秒再发起下一次请求。
第55-70行,将刚刚编写的中间件middleware和解析后续处理pipe添加到setting中。
运行
在该项目的文件目录下打开命令行,输入:scrapy crawl lagouSpider,等待5分钟左右即可获得数据。
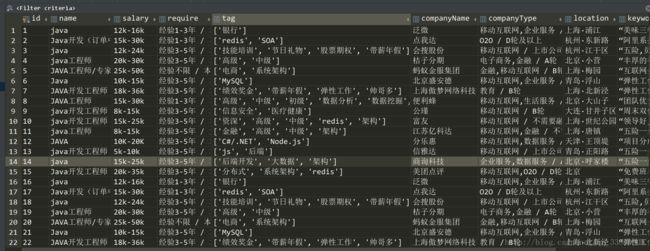
生成词云
demo.py:
#!/usr/bin/env python
from os import path
import matplotlib.pyplot as plt
import pymysql
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import numpy as np
from PIL import Image
import jieba
class sqlHelper(object):
def __init__(self, host, user, password, database):
# 打开数据库连接
self.db = pymysql.connect(host, user, password, database, use_unicode=True, charset="utf8")
# 使用 cursor() 方法创建一个游标对象 cursor
self.cursor = self.db.cursor()
# 析构函数关闭连接
def __del__(self):
self.cursor.close()
# 关闭数据库连接
self.db.close()
# 插入数据库
def insert(self, name, salary, require, tag, companyName, companyType, location, keyWord, day):
sql = "insert into lagou values(null,\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\")" % (
name, salary, require, tag, companyName, companyType, location, keyWord, day)
print(sql)
try:
# 执行sql语句
self.cursor.execute(sql)
# 提交到数据库执行
self.db.commit()
except:
# 如果发生错误则回滚
self.db.rollback()
# 随机获取一条
def getAll(self):
sql = "SELECT * FROM lagou"
try:
# 执行SQL语句
self.cursor.execute(sql)
# 获取所有记录列表
results = self.cursor.fetchall()
return results
except:
print("Error: unable to fetch data")
if __name__ == '__main__':
sql = sqlHelper("localhost", "root", "admin", "lagou")
datas = sql.getAll()
print('开始加载文本')
text = ''
for data in datas:
# 2对应拉钩网每个职位的工资范围 (可以通过修改代码计算出平均范围)
# 3对应拉钩网每个职位的最低要求
# 4对应拉钩网每个职位的关键要求tag
# 6对应拉钩网每个招聘公司类型
# 8对应拉钩网招聘公司的关键词
text += data[4]
text = text.replace("'", "")
text = " ".join(jieba.cut(text))
d = path.dirname(__file__)
font = path.join(path.dirname(__file__), "xingshu.ttf")
background = np.array(Image.open(path.join(d, "demo.webp")))
print('加载图片成功!')
wordcloud = WordCloud(background_color="white", max_words=200, font_path=font, width=300, height=150,
mask=background, max_font_size=500,
margin=2).generate(text)
image_colors = ImageColorGenerator(background)
plt.imshow(wordcloud.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
plt.figure()
plt.imshow(background, cmap=plt.cm.gray, interpolation="bilinear")
plt.axis("off")
plt.show()
print('生成词云成功!')
解析:我们先是编写sqlHelper类对数据库里的内容进行获取,然后再将需要生成词云的内容拼接成文本,运用wordCloud库来进行生成。其中WordCloud的具体内容参考百度。
得到结果:
- 招聘关键字词云
- 公司关键字词云
通过词云发现目前java招聘关键要求有:中高级、金融、银行、linux、mysql、redis、soa…
通过词云发现目前公司关键有:弹性、全球、双休、五险…