tensorflow—例子
1、第一个例子:预测一个线性直线y=0.1*x+0.3
还没来得及去学习tensorflow的基础,便直接上手例子了。有点小吃力,但参照着B站莫烦的python教学视频(https://www.bilibili.com/video/av16001891/?p=10 例子5反复看了至少3回,原谅奔三的我,日益消退的理解和消化能力。。),感谢天地,看懂了并亲手实现了第一个人工神经网络训练的例子。虽然实验室的老旧电脑机器跑了大概有两三分钟,而视频中苹果的电脑是瞬间出的结果,但还是有那么一丝的小成就感和喜悦之情不由自主地溢于言表。。起码为之后的AI学习和漫长的科研道路带来了信心和希望,愿世界和平,愿疾病离你我远远的。。。
先把试验成功的代码和结果贴上来,上面简单做了注释。

二、例子2:构建简单的神经网络结构之添加隐藏层。目的:拟合一个二次函数。例子中构建了一个隐藏层含有具有十个神经元的三层神经网络。激励函数用的relu。https://en.wikipedia.org/wiki/Activation_function维基百科上有很多激励函数可供选择。
关于代码的注释在截图中会有。需要注意的是:
@1、如果定义了变量Variable 就必须进行激活。init;否则就不需要init。
@2、关于区别Variable和placeholder可以这么理解:前者是已经规划好的初始值,而后者是可以在代码运行时才传入的初始值。
@3、隐藏层的节点数(即神经元个数)可以自由定义。
@4、[None,1]可以被理解为行不确定,列为1的列向量。
三、将例子二的拟合过程进行可视化。期间主要有两个问题。
@1、在anconda下,需要在tensorflow的环境里安装上matplotlib.才可以使用spyder(tensorflow)调用matplotlib画图进行结果的可视化操作。
@2、在spyder中run,默认的是在控制台窗口显示画图结果,如果想让它在新建fig窗口独立显示图像,需要在Tools-Preference-Ipython console-Graphic-Backend选择Qt5,之后重启spyder才可有效。
现将代码段粘贴如下,并附有注释:
# -*- coding: utf-8 -*-
"""
Created on Thu Sep 13 19:36:15 2018
莫烦B站的教学视频P16的例子。拟合一个二次函数。构建了一个隐藏层含有具有十个神经元的三层神经网络。激励函数用的relu
本次主要是演示将结果可视化。
@author: Administrator
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt#首先加载可视化模块
def add_layer(inputs,in_size,out_size,activation_function=None):#None的话,默认就是线性函数
Weights=tf.Variable(tf.random_normal([in_size,out_size]))#生成In_size行和out_size列的矩阵。代表权重矩阵。
biases=tf.Variable(tf.zeros([1,out_size])+0.1)
Wx_plus_b=tf.matmul(inputs,Weights)+biases#预测出来的还没有被激活的值存储在这个变量中。
if activation_function is None:
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
return outputs#outputs是add_layer的输出值。
x_data=np.linspace(-1,1,300)[:,np.newaxis]#linspace是创建一个从-1到1的300个数的等差数列
noise=np.random.normal(0,0.05,x_data.shape)
y_data=np.square(x_data)-0.5+noise
xs=tf.placeholder(tf.float32,[None,1])#1是x_data的属性为1.None指无论给多少个例子都ok。
ys=tf.placeholder(tf.float32,[None,1])
#开始建造第一层layer。典型的三层神经网络:输入层(有多少个输入的x_data就有多少个神经元,本例中,只有一个属性,所以只有一个神经元输入),假设10个神经元的隐藏层,输出层。
#由于在使用relu,该代码就是用十条线段拟合一个抛物线。
l1=add_layer(xs,1,10,activation_function=tf.nn.relu)#L1仅是单隐藏层,全连接网络。
#再定义一个输出层,即:prediction
#add_layer的输出值是l1,把l1放在prediction的input。input的size就是隐藏层的size:10.output的size就是y_data的size就是1.
prediction=add_layer(l1,10,1,activation_function=None)
loss=tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),
reduction_indices=[1]))#reduction_indices=[1]:按行求和。reduction_indices=[0]按列求和。sum是将所有例子求和,再求平均(mean)。
#通过训练学习。提升误差。
train_step=tf.train.GradientDescentOptimizer(0.1).minimize(loss)#以0.1的学习效率来训练学习,来减小loss。
init=tf.global_variables_initializer()
sess=tf.Session()
sess.run(init)
fig=plt.figure()#申请一个图片框
ax=fig.add_subplot(1,1,1)#要实现连续性的画图,所以用ax
ax.scatter(x_data,y_data) #先把real_data以点的形式给画出来
plt.ion()
plt.ioff()
plt.show()
for i in range(1000):
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
if i%50==0:
#to seee the improvement
#print(sess.run(loss,feed_dict={xs:x_data,ys:y_data}))
#使用try是因为第一次抹除第一条线的话可能会报错,因为采用的是先擦除再plot的方法,第一条还不存在。
try:
ax.lines.remove(lines[0])#去除line的第一条线,再plot下一条。。
except Exception:
pass
prediction_value=sess.run(prediction,feed_dict={xs:x_data})#prediction与输入的xs有关,所以,要feed_dict
#然后把prediciotn的值用一条曲线的形式plot上去
lines=ax.plot(x_data,prediction_value,'r-',lw=5)#lw=5是指线的宽度为5.
#plot出一条线之后就要擦掉再plot另一条线。
plt.pause(0.1)
另外,将运行结果整理如下:

四:classification。之前的是那个例子说的是线性回归的事情,接下来看分类的问题。基于从MNIST下载数据,辨别数字。
跟学比较顺利,现记录下几个知识点点:
@1、MNIST database=modified national institute of standards and technology databases
@2、one-hot编码 独热码,不同的位置表示不同的分类。
@3、在基于分类的神经网络中,计算loss要用到cross_entropy即交叉熵,它是一个相对比较复杂的算法。后续再做研究。用softmax和cross_entropy就可以自动生成分类算法?
例子代码如下(附有注释):
# -*- coding: utf-8 -*-
"""
Created on Tue Sep 18 10:08:29 2018
分类的问题.识别数字.基于MNIST数据集。
@author: Administrator
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#number 1to 10 data
mnist=input_data.read_data_sets('MNIST_data',one_hot=True)#如果电脑中没有MNIST包就会自动下载下来,第二次运行的时候就直接用了。
def add_layer(inputs,in_size,out_size,activation_function=None):#None的话,默认就是线性函数
Weights=tf.Variable(tf.random_normal([in_size,out_size]))#生成In_size行和out_size列的矩阵。代表权重矩阵。
biases=tf.Variable(tf.zeros([1,out_size])+0.1)
Wx_plus_b=tf.matmul(inputs,Weights)+biases#预测出来的还没有被激活的值存储在这个变量中。
if activation_function is None:
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
return outputs#outputs是add_layer的输出值。
def compute_accuracy(v_xs,v_ys):
global prediction#先把prediciton定义成全局变量
y_pre=sess.run(prediction,feed_dict={xs:v_xs})#把x_data send到prediciton里生成预测值(一行10列,处于1和0之间的值,表示的是概率大小.取值最大的一个位置即是本次预测值)
correct_prediction=tf.equal(tf.argmax(y_pre,1),tf.argmax(v_ys,1))#再将此数值与真实数值对比.取预测输出的1个数里面最大的索引和真实答案的索引比较奥,一样的话就是对的.
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#计算这一组数据当中,对的个数,与错的个数
result=sess.run(accuracy,feed_dict={xs:v_xs,ys:v_ys})#run一下accuracy就可以得到结果(百分比)
return result
#define placeholder for inputs to network
xs=tf.placeholder(tf.float32,[None,784])#28*28
ys=tf.placeholder(tf.float32,[None,10])
#add output layer
prediction=add_layer(xs,784,10,activation_function=tf.nn.softmax)
#the error between prediciton and real data
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),
reduction_indices=[1])) #loss交叉熵
train_step=tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess=tf.Session()
#important step
sess.run(tf.global_variables_initializer())
for i in range(1000):
batch_xs,batch_ys=mnist.train.next_batch(100)#提取出一部分的xs和ys的sample.如果每一次都学习全套的数据,计算能力会很低,很慢.
sess.run(train_step,feed_dict={xs:batch_xs,ys:batch_ys})
if i%50==0:#每隔50步计算准确度.
print(compute_accuracy(
mnist.test.images,mnist.test.labels))运行结果如下:
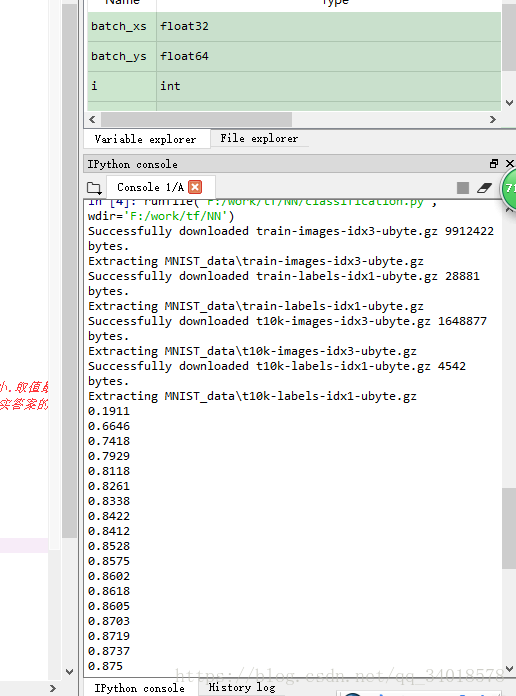
可以看到,ACC从19%一直被提高到87.5%。
五、对五类图片进行分类,使用了一个简单的神经网络模型。。
出现的主要问题就是:
@1、总是找不到图片路径。改了一通好使了。大概保证了以下几点:
a:路径格式:‘F:/pictures/train/’或者‘F:\\pictures\\train’
b:把图片存在pycharm的工作空间中。(不知道必要不必要)
c:把前一次运行产生的.idea文件删掉。
d:如果还运行不成功就重启软件。总之,别急躁,总能解决的。
@2、运行过程中,在第四步骤,对生成的patch可视化展现的时候,弹出的figure要依次关掉才可继续执行。
代码:
import os
import numpy as np
from PIL import Image
import tensorflow as tf
import matplotlib.pyplot as plt
#一、生成图片路径和标签list包括两步:
# step1:将指定路径的图片名字提取出来并且进行分类,添加标记,以便后面函数根据文件名字提取具体图片,并且知道对应分类
train_dir = 'F:/picture/train/'
def get_files(file_dir):
A5 = []
label_A5 = []
A6 = []
label_A6 = []
SEG = []
label_SEG = []
SUM = []
label_SUM = []
LTAX1 = []
label_LTAX1 = []
# os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
# 此处的文件名字提取分类是为了后面的函数根据名字提取具体图片
for file in os.listdir(file_dir):
name = file.split(sep='.')
if name[0] == 'A5':
A5.append(file_dir + file)
label_A5.append(0)
elif name[0] == 'A6':
A6.append(file_dir + file)
label_A6.append(1)
elif name[0] == 'LTAX1':
LTAX1.append(file_dir + file)
label_LTAX1.append(2)
elif name[0] == 'SEG':
SEG.append(file_dir + file)
label_SEG.append(3)
else:
SUM.append(file_dir + file)
label_SUM.append(4)
print('There are %d A5\nThere are %d A6\nThere are %d LTAX1\nThere are %d SEG\nThere are %d SUM' \
% (len(A5), len(A6), len(LTAX1), len(SEG), len(SUM)))
## step 2 对生成的图片路径和标签List做打乱处理
image_list = np.hstack((A5, A6, LTAX1, SEG, SUM))
# hstack起到了合并list的作用,合并为一行,且数字大小相同的是连续在一起的
label_list = np.hstack((label_A5, label_A6, label_LTAX1, label_SEG, label_SUM))
temp = np.array([image_list, label_list])
#利用array合并,shuffle打乱顺序
temp = temp.transpose()
np.random.shuffle(temp)
image_list = list(temp[:, 0])
label_list = list(temp[:, 1])
label_list = [int(i) for i in label_list]
return image_list, label_list
#二、生成batch包括四步:
#step1: 生成一定数量的image和lable
def get_batch(image, label, image_W, image_H, batch_size, capacity):
# (前两个参数是上面函数得到的两个list,图片宽度,图片高度,分支大小,一个队列最大多少)
image = tf.cast(image, tf.string)
label = tf.cast(label, tf.int32)
# 将两个列表加入一个队列,在后面测试的时候启动
input_queue = tf.train.slice_input_producer([image, label])
label = input_queue[1]
image_contents = tf.read_file(input_queue[0])
#step2:将图像解码,不同类型的图像不能混在一起,要么只用jpeg,要么只用png等
image = tf.image.decode_jpeg(image_contents, channels=3)
# step3: 数据预处理,对图像进行旋转、缩放、裁剪、归一化等操作,让计算出的模型更健壮。
image = tf.image.resize_image_with_crop_or_pad(image, image_W, image_H)
#该函数主要是重设原图像大小,当原图像size小于目标图像size时会使用0来填充小于的部分,反之则会直接crop掉大于的部分,这是接口自动完成的
image = tf.image.per_image_standardization(image)# #此函数的运算过程是将整幅图片标准化(不是归一化),加速神经网络的训练
image_batch, label_batch = tf.train.batch([image, label], batch_size=batch_size, num_threads=16, capacity=capacity)
# 是按顺序读取数据,队列中的数据始终是一个有序的队列,capacity是队列的长度
# tf.train.batch([example, label], batch_size=batch_size, capacity=capacity):[example, label]表示样本和样本标签,
## 这个可以是一个样本和一个样本标签,batch_size是返回的一个batch样本集的样本个数。capacity是队列中的容量。这主要是按顺序组合成一个batch
# 计算图是从一个管道中读取数据的,录入管道是用的现成的方法,读取也是。
## 为了保证多线程的时候从一个管道读取数据不会乱吧,所以这种时候 读取的时候需要线程管理的相关操作
#step4:生成batch
label_batch = tf.reshape(label_batch, [batch_size])
return image_batch, label_batch
#得到样本集
#三、准确率测试
#step1:定义所需数据
BATCH_SIZE = 5
CAPACITY = 64
IMG_W = 208
IMG_H = 208
train_dir = 'F:/picture/train/'
#step2: 利用上面的函数得到所需的image,label和batch
image_list, label_list = get_files(train_dir)
image_batch, label_batch = get_batch(image_list, label_list, IMG_W, IMG_H, BATCH_SIZE, CAPACITY)
#step3: 开始测试
#Coordinator类可以用来同时停止多个工作线程并且向那个在等待所有工作线程终止的程序报告异常。QueueRunner类用来协调多个工作线程同时将多个张量推入同一个队列中
#tf.train.start_queue_runners这个函数将会启动输入管道的线程,填充样本到队列中,以便出队操作可以从队列中拿到样本。
#首先,我们先创建数据流图,这个数据流图由一些流水线的阶段组成,阶段间用队列连接在一起:
# 第一阶段将生成文件名,我们读取这些文件名并且把他们排到文件名队列中。
# 第二阶段从文件中读取数据(使用Reader),产生样本,而且把样本放在一个样本队列中
with tf.Session() as sess:
i = 0
coord = tf.train.Coordinator()
##创建一个协调器,管理线程
#启动QueueRunner, 此时文件名队列已经进队。即启动之前创建的那个包含image和label的队列
threads = tf.train.start_queue_runners(coord=coord)
try:
while not coord.should_stop() and i < 1:
img, label = sess.run([image_batch, label_batch])
# 遍历batch中的每个元素
for j in np.arange(BATCH_SIZE):
print('label: %d' % label[j])
plt.imshow(img[j, :, :, :])
plt.show()
i += 1
except tf.errors.OutOfRangeError:
print('done!')
finally:
coord.request_stop()#线程停止
coord.join(threads)
#四、建立CNN模型
def inference(images, batch_size, n_classes):
# conv1, shape = [kernel_size, kernel_size, channels, kernel_numbers]
with tf.variable_scope("conv1") as scope:
weights = tf.get_variable("weights",
shape=[3, 3, 3, 16],
dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.1, dtype=tf.float32))
biases = tf.get_variable("biases",
shape=[16],
dtype=tf.float32,
initializer=tf.constant_initializer(0.1))
conv = tf.nn.conv2d(images, weights, strides=[1, 1, 1, 1], padding="SAME")
pre_activation = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(pre_activation, name="conv1")
# pool1 && norm1
with tf.variable_scope("pooling1_lrn") as scope:
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding="SAME", name="pooling1")
norm1 = tf.nn.lrn(pool1, depth_radius=4, bias=1.0, alpha=0.001 / 9.0,
beta=0.75, name='norm1')
# conv2
with tf.variable_scope("conv2") as scope:
weights = tf.get_variable("weights",
shape=[3, 3, 16, 16],
dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.1, dtype=tf.float32))
biases = tf.get_variable("biases",
shape=[16],
dtype=tf.float32,
initializer=tf.constant_initializer(0.1))
conv = tf.nn.conv2d(norm1, weights, strides=[1, 1, 1, 1], padding="SAME")
pre_activation = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(pre_activation, name="conv2")
# pool2 && norm2
with tf.variable_scope("pooling2_lrn") as scope:
pool2 = tf.nn.max_pool(conv2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding="SAME", name="pooling2")
norm2 = tf.nn.lrn(pool2, depth_radius=4, bias=1.0, alpha=0.001 / 9.0,
beta=0.75, name='norm2')
# full-connect1
with tf.variable_scope("fc1") as scope:
reshape = tf.reshape(norm2, shape=[batch_size, -1])
dim = reshape.get_shape()[1].value
weights = tf.get_variable("weights",
shape=[dim, 128],
dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.005, dtype=tf.float32))
biases = tf.get_variable("biases",
shape=[128],
dtype=tf.float32,
initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name="fc1")
# full_connect2
with tf.variable_scope("fc2") as scope:
weights = tf.get_variable("weights",
shape=[128, 128],
dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.005, dtype=tf.float32))
biases = tf.get_variable("biases",
shape=[128],
dtype=tf.float32,
initializer=tf.constant_initializer(0.1))
fc2 = tf.nn.relu(tf.matmul(fc1, weights) + biases, name="fc2")
# softmax
with tf.variable_scope("softmax_linear") as scope:
weights = tf.get_variable("weights",
shape=[128, n_classes],
dtype=tf.float32,
initializer=tf.truncated_normal_initializer(stddev=0.005, dtype=tf.float32))
biases = tf.get_variable("biases",
shape=[n_classes],
dtype=tf.float32,
initializer=tf.constant_initializer(0.1))
softmax_linear = tf.add(tf.matmul(fc2, weights), biases, name="softmax_linear")
return softmax_linear
#定义损失函数
def losses(logits, labels):
with tf.variable_scope("loss") as scope:
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=labels, name="xentropy_per_example")
#tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)
#除去name参数用以指定该操作的name,与方法有关的一共两个参数:
#第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes
#第二个参数labels:实际的标签,大小同上
loss = tf.reduce_mean(cross_entropy, name="loss")
tf.summary.scalar(scope.name + "loss", loss)
return loss
#优化训练模块
def trainning(loss, learning_rate):
with tf.name_scope("optimizer"):
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
global_step = tf.Variable(0, name="global_step", trainable=False)
train_op = optimizer.minimize(loss, global_step=global_step)
return train_op
#评估训练精度
def evaluation(logits, labels):
with tf.variable_scope("accuracy") as scope:
correct = tf.nn.in_top_k(logits, labels, 1)
correct = tf.cast(correct, tf.float16)
accuracy = tf.reduce_mean(correct)
tf.summary.scalar(scope.name + "accuracy", accuracy)
return accuracy
#五、给出实际参数对图片进行训练。
N_CLASSES = 5
IMG_W = 208
IMG_H = 208
BATCH_SIZE = 8
CAPACITY = 64
MAX_STEP = 1000
learning_rate = 0.0001
#调用上面定义的训练模型,输入图片batches进行图片识别训练。
def run_training():
train_dir = 'F:/picture/train/'
logs_train_dir = 'F:/picture/log/'
train, train_label = get_files(train_dir)
train_batch, train_label_batch = get_batch(train, train_label,
IMG_W,
IMG_H,
BATCH_SIZE,
CAPACITY)
train_logits = inference(train_batch, BATCH_SIZE, N_CLASSES)
train_loss = losses(train_logits, train_label_batch)
train_op = trainning(train_loss, learning_rate)
train_acc = evaluation(train_logits, train_label_batch)
summary_op = tf.summary.merge_all()
sess = tf.Session()
train_writer = tf.summary.FileWriter(logs_train_dir, sess.graph)
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
for step in np.arange(MAX_STEP):
if coord.should_stop():
break
_, tra_loss, tra_acc = sess.run([train_op, train_loss, train_acc])
if step % 50 == 0:
print('Step %d,train loss = %.2f,train occuracy = %.2f%%' % (step, tra_loss, tra_acc))
summary_str = sess.run(summary_op)
train_writer.add_summary(summary_str, step)
if step % 200 == 0 or (step + 1) == MAX_STEP:
checkpoint_path = os.path.join(logs_train_dir, 'model.ckpt')
saver.save(sess, checkpoint_path, global_step=step)
except tf.errors.OutOfRangeError:
print('Done training epoch limit reached')
finally:
coord.request_stop()
coord.join(threads)
sess.close()
run_training()
def get_one_image(img_dir):
image = Image.open(img_dir)
plt.imshow(image)
image = image.resize([208, 208])
image_arr = np.array(image)
return image_arr
def test(test_file):
log_dir = 'F:/picture/log/'
image_arr = get_one_image(test_file)
with tf.Graph().as_default():
image = tf.cast(image_arr, tf.float32)
image = tf.image.per_image_standardization(image)
image = tf.reshape(image, [1, 208, 208, 3])
print(image.shape)
p = inference(image, 1, 5)
logits = tf.nn.softmax(p)
x = tf.placeholder(tf.float32, shape=[208, 208, 3])
saver = tf.train.Saver()
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(log_dir)
if ckpt and ckpt.model_checkpoint_path:
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
saver.restore(sess, ckpt.model_checkpoint_path)
print('Loading success')
else:
print('No checkpoint')
prediction = sess.run(logits, feed_dict={x: image_arr})
max_index = np.argmax(prediction)
print('预测的标签为:')
print(max_index)
print('预测的结果为:')
print(prediction)
if max_index == 0:
print('This is a LTAX with possibility %.6f' % prediction[:, 0])
elif max_index == 1:
print('This is a SUM with possibility %.6f' % prediction[:, 1])
elif max_index == 2:
print('This is a A5 with possibility %.6f' % prediction[:, 2])
elif max_index == 3:
print('This is a A6 with possibility %.6f' % prediction[:, 3])
else:
print('This is a SEG with possibility %.6f' % prediction[:, 4])
test('F:\\picture\\test\\A51.jpeg')
test('F:\\picture\\test\\A52.jpeg')
test('F:\\picture\\test\\A61.jpeg')
test('F:\\picture\\test\\A62.jpeg')
test('F:\\picture\\test\\LTAX1.jpeg')
test('F:\\picture\\test\\LTAX2.jpeg')
test('F:\\picture\\test\\SEG1.jpg')
test('F:\\picture\\test\\SEG2.jpg')
test('F:\\picture\\test\\SUM1.jpeg')
test('F:\\picture\\test\\SUM2.jpeg')
结果展示:
E:\ProgramFile\Anaconda3\python.exe F:/picture/cnnn.py
There are 5 A5
There are 6 A6
There are 3 LTAX1
There are 5 SEG
There are 9 SUM
2018-10-15 19:47:52.924105: I T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
2018-10-15 19:47:54.350041: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1405] Found device 0 with properties:
name: Quadro P400 major: 6 minor: 1 memoryClockRate(GHz): 1.2525
pciBusID: 0000:01:00.0
totalMemory: 2.00GiB freeMemory: 1.62GiB
2018-10-15 19:47:54.351986: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1484] Adding visible gpu devices: 0
2018-10-15 19:48:05.660416: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-10-15 19:48:05.661055: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0
2018-10-15 19:48:05.661467: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:984] 0: N
2018-10-15 19:48:05.735110: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1377 MB memory) -> physical GPU (device: 0, name: Quadro P400, pci bus id: 0000:01:00.0, compute capability: 6.1)
label: 4
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
label: 4
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
label: 1
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
label: 4
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
label: 4
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
There are 5 A5
There are 6 A6
There are 3 LTAX1
There are 5 SEG
There are 9 SUM
2018-10-15 19:48:32.789375: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1484] Adding visible gpu devices: 0
2018-10-15 19:48:32.790183: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-10-15 19:48:32.791486: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0
2018-10-15 19:48:32.791964: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:984] 0: N
2018-10-15 19:48:32.793018: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1377 MB memory) -> physical GPU (device: 0, name: Quadro P400, pci bus id: 0000:01:00.0, compute capability: 6.1)
Step 0,train loss = 1.61,train occuracy = 0.38%
Step 50,train loss = 0.19,train occuracy = 1.00%
Step 100,train loss = 0.00,train occuracy = 1.00%
Step 150,train loss = 0.00,train occuracy = 1.00%
Step 200,train loss = 0.00,train occuracy = 1.00%
Step 250,train loss = 0.00,train occuracy = 1.00%
Step 300,train loss = 0.00,train occuracy = 1.00%
Step 350,train loss = 0.00,train occuracy = 1.00%
Step 400,train loss = 0.00,train occuracy = 1.00%
Step 450,train loss = 0.00,train occuracy = 1.00%
Step 500,train loss = 0.00,train occuracy = 1.00%
Step 550,train loss = 0.00,train occuracy = 1.00%
Step 600,train loss = 0.00,train occuracy = 1.00%
Step 650,train loss = 0.00,train occuracy = 1.00%
Step 700,train loss = 0.00,train occuracy = 1.00%
Step 750,train loss = 0.00,train occuracy = 1.00%
Step 800,train loss = 0.00,train occuracy = 1.00%
Step 850,train loss = 0.00,train occuracy = 1.00%
Step 900,train loss = 0.00,train occuracy = 1.00%
Step 950,train loss = 0.00,train occuracy = 1.00%
(1, 208, 208, 3)
2018-10-15 19:51:12.829783: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1484] Adding visible gpu devices: 0
2018-10-15 19:51:12.830717: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-10-15 19:51:12.831572: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0
2018-10-15 19:51:12.832092: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:984] 0: N
2018-10-15 19:51:12.833747: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1377 MB memory) -> physical GPU (device: 0, name: Quadro P400, pci bus id: 0000:01:00.0, compute capability: 6.1)
Loading success
预测的标签为:
1
预测的结果为:
[[0.00181954 0.6056087 0.22738117 0.00444909 0.16074155]]
This is a SUM with possibility 0.605609
(1, 208, 208, 3)
2018-10-15 19:51:14.481932: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1484] Adding visible gpu devices: 0
2018-10-15 19:51:14.482632: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-10-15 19:51:14.483316: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0
2018-10-15 19:51:14.483794: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:984] 0: N
2018-10-15 19:51:14.485124: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1377 MB memory) -> physical GPU (device: 0, name: Quadro P400, pci bus id: 0000:01:00.0, compute capability: 6.1)
Loading success
预测的标签为:
4
预测的结果为:
[[2.0864157e-03 1.1025291e-01 6.3456863e-02 8.0309832e-04 8.2340074e-01]]
This is a SEG with possibility 0.823401
(1, 208, 208, 3)
2018-10-15 19:51:15.420752: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1484] Adding visible gpu devices: 0
2018-10-15 19:51:15.421446: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-10-15 19:51:15.422226: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0
2018-10-15 19:51:15.422744: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:984] 0: N
2018-10-15 19:51:15.424367: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1377 MB memory) -> physical GPU (device: 0, name: Quadro P400, pci bus id: 0000:01:00.0, compute capability: 6.1)
Loading success
预测的标签为:
3
预测的结果为:
[[0.00115634 0.0297138 0.1901305 0.65874475 0.1202546 ]]
This is a A6 with possibility 0.658745
(1, 208, 208, 3)
2018-10-15 19:51:16.361773: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1484] Adding visible gpu devices: 0
2018-10-15 19:51:16.362771: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-10-15 19:51:16.364159: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0
2018-10-15 19:51:16.364642: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:984] 0: N
2018-10-15 19:51:16.365863: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1377 MB memory) -> physical GPU (device: 0, name: Quadro P400, pci bus id: 0000:01:00.0, compute capability: 6.1)
Loading success
预测的标签为:
3
预测的结果为:
[[0.00150369 0.11753147 0.2714638 0.4502552 0.15924588]]
This is a A6 with possibility 0.450255
(1, 208, 208, 3)
2018-10-15 19:51:17.984710: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1484] Adding visible gpu devices: 0
2018-10-15 19:51:17.985422: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-10-15 19:51:17.986114: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0
2018-10-15 19:51:17.986600: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:984] 0: N
2018-10-15 19:51:17.987746: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1377 MB memory) -> physical GPU (device: 0, name: Quadro P400, pci bus id: 0000:01:00.0, compute capability: 6.1)
Loading success
预测的标签为:
1
预测的结果为:
[[1.3509640e-04 5.9970856e-01 1.3556199e-01 2.2494867e-02 2.4209945e-01]]
This is a SUM with possibility 0.599709
(1, 208, 208, 3)
2018-10-15 19:51:19.601834: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1484] Adding visible gpu devices: 0
2018-10-15 19:51:19.602602: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-10-15 19:51:19.603436: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0
2018-10-15 19:51:19.603894: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:984] 0: N
2018-10-15 19:51:19.604563: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1377 MB memory) -> physical GPU (device: 0, name: Quadro P400, pci bus id: 0000:01:00.0, compute capability: 6.1)
Loading success
预测的标签为:
4
预测的结果为:
[[1.9814190e-04 4.2093730e-01 5.2375749e-02 2.0062068e-02 5.0642669e-01]]
This is a SEG with possibility 0.506427
(1, 208, 208, 3)
2018-10-15 19:51:20.789713: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1484] Adding visible gpu devices: 0
2018-10-15 19:51:20.790427: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-10-15 19:51:20.791592: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0
2018-10-15 19:51:20.792309: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:984] 0: N
2018-10-15 19:51:20.793097: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1377 MB memory) -> physical GPU (device: 0, name: Quadro P400, pci bus id: 0000:01:00.0, compute capability: 6.1)
Loading success
预测的标签为:
4
预测的结果为:
[[3.3060056e-05 2.5724115e-02 2.3482880e-01 3.1745610e-01 4.2195794e-01]]
This is a SEG with possibility 0.421958
(1, 208, 208, 3)
2018-10-15 19:51:21.886535: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1484] Adding visible gpu devices: 0
2018-10-15 19:51:21.887229: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-10-15 19:51:21.887909: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0
2018-10-15 19:51:21.888394: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:984] 0: N
2018-10-15 19:51:21.889051: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1377 MB memory) -> physical GPU (device: 0, name: Quadro P400, pci bus id: 0000:01:00.0, compute capability: 6.1)
Loading success
预测的标签为:
4
预测的结果为:
[[4.1343395e-05 2.8887866e-02 3.3908620e-01 2.1828508e-01 4.1369945e-01]]
This is a SEG with possibility 0.413699
(1, 208, 208, 3)
2018-10-15 19:51:23.039367: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1484] Adding visible gpu devices: 0
2018-10-15 19:51:23.040136: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-10-15 19:51:23.041250: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0
2018-10-15 19:51:23.041875: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:984] 0: N
2018-10-15 19:51:23.042648: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1377 MB memory) -> physical GPU (device: 0, name: Quadro P400, pci bus id: 0000:01:00.0, compute capability: 6.1)
Loading success
预测的标签为:
4
预测的结果为:
[[0.00238566 0.09336179 0.05032029 0.01495224 0.83898 ]]
This is a SEG with possibility 0.838980
(1, 208, 208, 3)
2018-10-15 19:51:24.216819: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1484] Adding visible gpu devices: 0
2018-10-15 19:51:24.217522: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-10-15 19:51:24.218243: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0
2018-10-15 19:51:24.219407: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:984] 0: N
2018-10-15 19:51:24.220441: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1377 MB memory) -> physical GPU (device: 0, name: Quadro P400, pci bus id: 0000:01:00.0, compute capability: 6.1)
Loading success
预测的标签为:
4
预测的结果为:
[[0.00170975 0.03447482 0.07225168 0.02174537 0.86981845]]
This is a SEG with possibility 0.869818
Process finished with exit code 0