tensorflow之overfitting(过拟合)问题
Tensorflow提供了dropout的功能来避免overfit。就参照莫烦的视频教程进行了练习。基于sklearn数据集进行了了过拟合实验。
示例代码为:
# -*- coding: utf-8 -*-
"""
Created on Tue Sep 18 14:29:11 2018
基于sklearn数据集进行了过拟合实验
@author: Administrator
"""
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
#load data
digits=load_digits()
X=digits.data #首先加载这个0-9的数字的图片data
y=digits.target#y如果代表数字2,就在第三个位置放上2。位置代表数字,从0开始排序。
y=LabelBinarizer().fit_transform(y)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=.3)#x和y都分成train sets&test sets
def add_layer(inputs,in_size,out_size,layer_name,activation_function=None):#None的话,默认就是线性函数
#aadd one more layer and return the output of this layer
Weights=tf.Variable(tf.random_normal([in_size,out_size]))#生成In_size行和out_size列的矩阵。代表权重矩阵。
biases=tf.Variable(tf.zeros([1,out_size])+0.1)
Wx_plus_b=tf.matmul(inputs,Weights)+biases#预测出来的还没有被激活的值存储在这个变量中。
if activation_function is None:
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
tf.summary.histogram(layer_name+'/outputs',outputs)#记录下ouput的值。以在tensorboard上输出。
return outputs
#define placeholder for inputs to network
xs=tf.placeholder(tf.float32,[None,64])#8*8,输入是64个单位
ys=tf.placeholder(tf.float32,[None,10])#输出是10个单位,分别是0-9.
#add output layer
l1=add_layer(xs,64,100,'l1',activation_function=tf.nn.tanh)
prediction=add_layer(l1,100,10,'l2',activation_function=tf.nn.softmax)
#the loss between prediciton and real data
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),
reduction_indices=[1])) #loss交叉熵
tf.summary.scalar('loss',cross_entropy)#在tensorboard记录它。有histogram summary和scalar summary才能在tensorboard上正常输出。
train_step=tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy)
sess=tf.Session()
merged=tf.summary.merge_all()
#summary writer goes in here
train_writer=tf.summary.FileWriter('logs/train',sess.graph)#存储在logs文件下的train文件夹中
test_writer=tf.summary.FileWriter('logs/test',sess.graph)#存在logs文件夹下的test文件夹中
sess.run(tf.global_variables_initializer())
for i in range(500):
sess.run(train_step,feed_dict={xs:X_train,ys:y_train})
if i%50==0:
#record loss
train_result=sess.run(merged,feed_dict={xs:X_train,ys:y_train})
test_result=sess.run(merged,feed_dict={xs:X_test,ys:y_test})
train_writer.add_summary(train_result,i)
test_writer.add_summary(test_result,i)
编码实现过程中出现以下问题:
@1、提示:找不到sklearn模块。Anconda内置了sklearn数据库但是并没有被加载到tensorflow的运行环境中。因此,打开anconda。在tensorflow的enviroment下进行了sklearn安装包的下载。(因为在搜索过程中,有博主说安装sklearn之前要安装scipy,不知道是不是在anconda下也这样,稳妥起见,先加载安装了scipy包,又下的scikits-learn安装包)。好像直接加载路径到tensorflow也可以,因为anconda的base环境下是默认有sklearn的数据库的。但是具体方法,我没有尝试。
在spyer上运行成功之后,利用tensorboard上展示了loss的变换曲线:(不太明白为什么有四条线,底下的不太清晰的两条是起初刚学习到的吗。。)loss当然越小越好。

如图,橘红色的为test data,蓝色的线为trainning data。可以看出,从50步开始两者有一些明显的岔开,test data的精确度会小于training data,误差大于training data。所以,这次学习存在一些的过拟合现象。现利用dropout功能将对其进行完善。期间,当add_layer输出值为100的时候,系统会报错。有人说是因为,隐藏神经元个数太多会导致输出离散值。所以要减小输出的个数,所以改成了50。
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Tue Sep 18 14:29:11 2018
基于sklearn数据集进行了过拟合实验,利用dropout功能避免过拟合现象。
@author: Administrator
"""
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
#load data
digits=load_digits()
X=digits.data #首先加载这个0-9的数字的图片data
y=digits.target#y如果代表数字2,就在第三个位置放上2。位置代表数字,从0开始排序。
y=LabelBinarizer().fit_transform(y)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=.3)#x和y都分成train sets&test sets
def add_layer(inputs,in_size,out_size,layer_name,activation_function=None):#None的话,默认就是线性函数
#aadd one more layer and return the output of this layer
Weights=tf.Variable(tf.random_normal([in_size,out_size]))#生成In_size行和out_size列的矩阵。代表权重矩阵。
biases=tf.Variable(tf.zeros([1,out_size])+0.1)
Wx_plus_b=tf.matmul(inputs,Weights)+biases#预测出来的还没有被激活的值存储在这个变量中。
Wx_plus_b=tf.nn.dropout(Wx_plus_b,keep_prob)#表示Wx_plus_b 是被drop的对象.
if activation_function is None:
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
tf.summary.histogram(layer_name+'/outputs',outputs)#记录下ouput的值。以在tensorboard上输出。
return outputs
#define placeholder for inputs to network、
keep_prob=tf.placeholder(tf.float32)#在定义一个dropout之前先定义个keep_probability,即要保持一个多少的结果不被drop掉。
xs=tf.placeholder(tf.float32,[None,64])#8*8,输入是64个单位
ys=tf.placeholder(tf.float32,[None,10])#输出是10个单位,分别是0-9.
#add output layer
l1=add_layer(xs,64,50,'l1',activation_function=tf.nn.tanh)
prediction=add_layer(l1,50,10,'l2',activation_function=tf.nn.softmax)
#the loss between prediciton and real data
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),
reduction_indices=[1])) #loss交叉熵
tf.summary.scalar('loss',cross_entropy)#在tensorboard记录它。有histogram summary和scalar summary才能在tensorboard上正常输出。
train_step=tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy)
sess=tf.Session()
merged=tf.summary.merge_all()
#summary writer goes in here
train_writer=tf.summary.FileWriter('logs/train',sess.graph)#存储在logs文件下的train文件夹中
test_writer=tf.summary.FileWriter('logs/test',sess.graph)#存在logs文件夹下的test文件夹中
sess.run(tf.global_variables_initializer())
for i in range(500):
sess.run(train_step,feed_dict={xs:X_train,ys:y_train,keep_prob:0.5})#keep_prob多少即保持多少不被drop掉。
if i%50==0:
#record loss
train_result=sess.run(merged,feed_dict={xs:X_train,ys:y_train,keep_prob:1})
test_result=sess.run(merged,feed_dict={xs:X_test,ys:y_test,keep_prob:1})#保证result不被drop掉。
train_writer.add_summary(train_result,i)
test_writer.add_summary(test_result,i)
结果如下图所示:keep_prob为1的时候(即drop掉0)为:

当keep_prob为0.5的时候结果为:
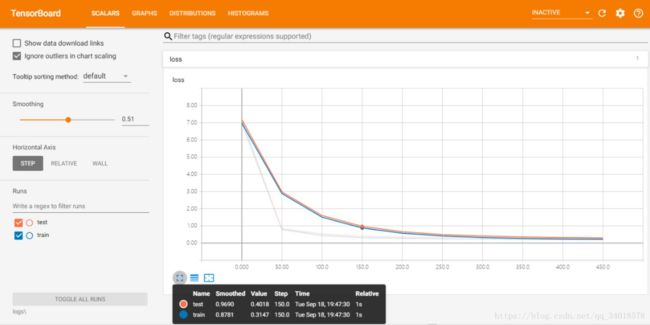
对比前面分别drop掉0和0.5的两种情况,可以看到,使用drop功能之后,过拟合现象有所改善。