《机器学习实战》学习大纲
学习大纲
整个机器学习内容包括:基础、分类、预测、无监督式学习、降维与分布式几大块进行。总共计划 12 周时间。
基础:第 1 章
分类: 第 1~7 章
预测:第 8~9 章
无监督式学习:第 10~12 章
降维与分布式:第 13~15 章
01 机器学习基础(第一周)
https://blog.csdn.net/qq_34243930/article/details/84948770
1.1 Python 基础知识,Numpy、pandas、Matplotlib 等库的简介
1.2 开发环境的搭建:Python3 + Anaconda + Jupyter Notebook
1.3 Jupyter Notebook 使用简介
第一节学习内容
学习时间: 12/2
任务1题目: 观看机器学习实战绪论视频+天池o2o比赛完全流程解析PPT

任务详解: 第一次视频课主要以《机器学习实战》第一章为基础,主要介绍机器学习的基本概念、算法类型、推荐学习路线和一些预备知识,包括Numpy、Pandas、Matplotlib 等Python 基本库。还有天池o2o比赛完全流程解析。
作业: 注册天池账号,报名参加比赛。提交结果,查看成绩。(结果 submit1.csv文件提供,只需按照直播视频讲述的方法提交查看成绩就好。submit1.csv 文件已放置在上)
第二节学习内容
学习时间: 12/3
**任务1题目:**配置开发环境,熟悉 Jupyter Notebook
**任务详解:**以Python3为开发语言,安装软件Anaconda。Anaconda自带Jupyter Notebook,熟悉Jupyter Notebook的基本用法。
参考资料:
[Jupyter Notebook入门教程(上)]
( https://mp.weixin.qq.com/s/O2nTGOtqGR-V33-YJgPgJQ)
[Jupyter Notebook入门教程(下)]
( https://mp.weixin.qq.com/s/AwSzkjlpwvdUzh6CmHq6AQ)
**作业:**使用Jupyter Nootbook,对Numpy、Pandas、Matplotlib各写一个小的demo程序。要求是解释性说明和代码相结合的形式。
02 k-近邻算法(第一周)
https://blog.csdn.net/qq_34243930/article/details/84948770
2.1 k-近邻算法概述
2.2 示例:使用 k-近邻算法改进网站的配对效果
2.3 示例:手写识别系统
学习内容
学习时间: 12/4—12/7
任务1题目: 书籍阅读
任务详解: 阅读《机器学习实战》书籍第二章2.1、2.2、2.3章节
参考资料: 李航《统计学习方法》第3章
作业1: 简要概括 k-近邻算法的原理,优缺点。
作业2: 将本章中“使用 k近邻算法改进网站的配对效果”完整代码键入,并添加详细注释。
作业3: 将本章中“手写识别系统”完整代码键入,并添加详细注释。
03 决策树(第二周)
https://blog.csdn.net/qq_34243930/article/details/84948790
3.1 决策树的构造
3.2 在 Python 中使用 Matplotlib 注解绘制树形图
3.3 测试和存储分类器
3.4 示例:使用决策树预测隐形眼镜类型
学习内容
学习时间: 12/09-12/10
任务1题目: 书籍阅读
任务详解: 阅读《机器学习实战》书籍第三章3.1、3.3、3.4节(3.2节选做)
参考文献: 李航《统计学习方法》第5章中的5.1-5.3节
作业1: 概括决策树分类算法的原理。
作业2: 在构建一个决策树模型时,我们对某个属性分割节点,下面四张图中,哪个属性对应的信息增益最大?
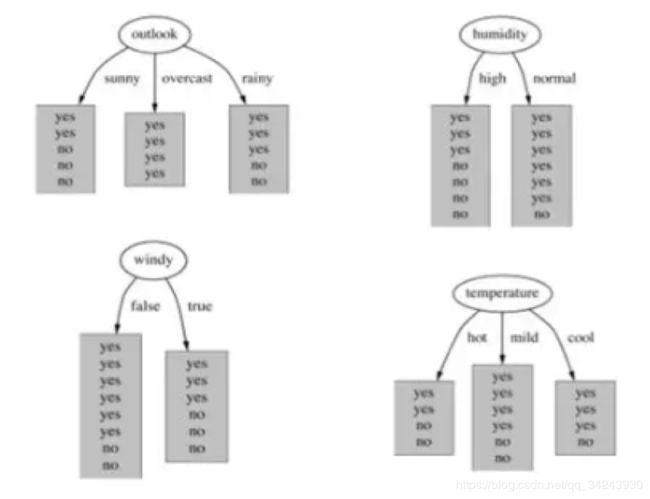
作业3: 将本章中“使用决策树预测隐形眼镜类型”完整代码键入,并添加详细注释。
04 朴素贝叶斯(第二周)
https://blog.csdn.net/qq_34243930/article/details/85016783
4.1 基于贝叶斯决策理论的分类方法
4.2 条件概率
4.3 使用条件概率来分类
4.4 使用朴素贝叶斯进行文档分类
4.5 使用 Python 进行文本分类
4.6 示例:使用朴素贝叶斯过滤垃圾邮件
4.7 示例:使用朴素贝叶斯分类器从个人广告中获取区域倾向
学习内容
学习时间: 12/11-12/14
任务1题目: 书籍阅读
任务详解: 阅读《机器学习实战》书籍第四章
参考文献: 李航《统计学习方法》第4章
参考资料: [通俗易懂!白话朴素贝叶斯]
( https://mp.weixin.qq.com/s/7xRyZJpXmeB77MZNLqVf3w)
作业1: 概括朴素贝叶斯分类算法的原理,为什么称之为“朴素”?
作业2:

试由下表的训练数据学习一个朴素贝叶斯分类器并确定x=(2,S)的类标记y。表中X1和X2为特征。
作业3: 将本章中“使用朴素贝叶斯过滤垃圾邮件”完整代码键入,并添加详细注释。
作业4: 将本章中“使用朴素贝叶斯分类器从个人广告中获取区域倾向”完整代码键入,并添加详细注释。
05 Logistic 回归(第三周)
https://blog.csdn.net/qq_34243930/article/details/86772736
5.1 基于 Logistic 回归和 Sigmoid 函数的回归
5.2 基于最优化方法的最佳回归系数确定
5.3 示例:从疝气病症预测病马的死亡率
第一节学习内容
学习时长:12/16-12/17
任务1题目:书籍阅读
任务详解:阅读《机器学习实战》书籍第5章
参考文献:李航《统计学习方法》第6章中的6.1节
作业1:写出并解释逻辑回归的损失函数,推导参数w的梯度下降公式。
提交日期:12/16
提交形式:文字或者截图打卡
作业2:将本章中“从疝气病症预测病马的死亡率”完整代码键入jupyter notebook,并添加详细注释。
提交日期:12/17
提交形式:代码截图打卡或git链接提交
作业参考答案
说明:当天作业参考答案隔天发布
1.1
https://github.com/RedstoneWill/MachineLearningInAction-Camp/blob/master/Week3/Materials/Logistic Regression/Logistic_Regression.ipynb
Jupyter Notebook 见GitHub
06 支持向量机
(第三周)
6.1 基于最大间隔分隔数据
6.2 寻找最大间隔
6.3 SMO 高效优化算法
(第四周)
6.4 利用完整 Platt SMO 算法加速优化
6.5 在复杂数据上应用核函数
6.6 手写识别问题
第一节学习内容
学习时长:12/18-12/24
任务1题目:书籍阅读
任务详解:阅读《机器学习实战》书籍第6章
参考资料:
李航《统计学习方法》第7章
[深入浅出机器学习技法(一):线性支持向量机(LSVM)]
( https://mp.weixin.qq.com/s/Ahvp0IAdgK9OVHFXigBk_Q)
[深入浅出机器学习技法(二):对偶支持向量机(DSVM)]
( https://mp.weixin.qq.com/s/Q5bFR3vDDXPhtzXlVAE3Rg)
[深入浅出机器学习技法(三):核支持向量机(KSVM)]
( https://mp.weixin.qq.com/s/cLovkwwgGJRgSSa1XWZ8eg)
作业1:推导SMO算法
提交日期:12/19
提交形式:文字或者截图打卡
作业2:理解书中程序清单6-2的简化SMO算法程序,对程序中详细注释。
提交日期:12/21
提交形式:文字或者截图打卡
作业3:为了防止SVM出现过拟合,应该对参数C进行如何设置?
提交日期:12/23
提交形式:文字或者截图打卡
作业4:将本章中“手写识别问题”完整代码键入,并添加详细注释。
提交日期:12/24
提交形式:代码截图打卡或git链接提交
作业参考答案
2.1 李航《统计学习方法》第7章7.4.1小节
2.2 略
作业参考答案
说明:当天作业参考答案隔天发布
1.1

1.2 Jupyter Notebook 见GitHub
比赛:天池O2O数据预测大赛(初级)
第二节学习内容
学习时长:12/25-12/28
任务1题目:天池o2o预测赛(初级)
任务详解:建立一个简单的线性模型,在线提交预测结果,查看成绩
视频不清晰也可以去荔枝微课看,地址: https://m.weike.fm/lecture/10234967 ;(观看密码:011220)
源码文件:链接: https://pan.baidu.com/s/1FwCcG0Pk1V_0mK1MCbkPlg ;;提取码:y5z6
作业1:使用简单模型,在线提交预测结果,查看成绩
提交日期:12/28
提交形式:代码截图打卡或git链接提交,比赛上传结果界面排名截图打卡上传
07 利用 AdaBoost 元算法提高分类性能(第五周)
7.1 基于数据 多重抽样的分类器
7.2 训练算法:基于错误提升分类器的性能
7.3 基于单层决策树构建弱分类器
7.4 完整 AdaBoost 算法的实现
7.5 测试算法:基于 AdaBoost 的分类
7.6 示例:在一个难数据集上应用 AdaBoost
7.7 非均衡分类问题
第一节学习内容
学习时长:12/30-01/02
任务1题目:书籍阅读
任务详解:阅读《机器学习实战》书籍第7章
参考文献:
李航《统计学习方法》第8章8.1/8.2/8.3节
作业1:AdaBoost选择分类器是弱分类器还是强分类器?解释原因。
提交日期:12/30
提交形式:文字或者截图打卡
作业2:将本章中“在一个难数据集上应用AdaBoost”完整代码键入jupyter notebook,并添加详细注释。若有可能,自己可以优化该代码。
提交日期:01/02
提交形式:代码截图打卡或git链接提交
作业参考答案
说明:当天作业参考答案隔天发布
1.1 弱分类器。若是强分类器,那么该分类器占的权重alpha会很大,相当于其它分类器不起作用了。所以,多个弱分类器起到“三个臭皮匠,赛过诸葛亮”的效果。
1.2 Jupyter Notebook 见GitHub
08 预测数值型数据:回归(第五周)
8.1 用线性回归找到最佳拟合直线
8.2 局部加权线性回归
8.3 示例:预测鲍鱼的年龄
8.4 缩减系数来“理解”数据
8.5 权衡偏差和方差
8.6 示例:预测乐高玩具套装的价格
第二节学习内容
学习时长:1/03-1/04
任务1题目:书籍阅读
任务详解:阅读《机器学习实战》书籍第8章
作业1:岭回归和Lasso回归有什么区别?
提交日期:1/03
提交形式:代码截图打卡或git链接提交
作业2:将本章中“预测鲍鱼的年龄”完整代码键入jupyter notebook,并添加详细注释。若有可能,自己可以优化该代码。
提交日期:1/04
提交形式:代码截图打卡或git链接提交
作业参考答案
说明:当天作业参考答案隔天发布
2.1
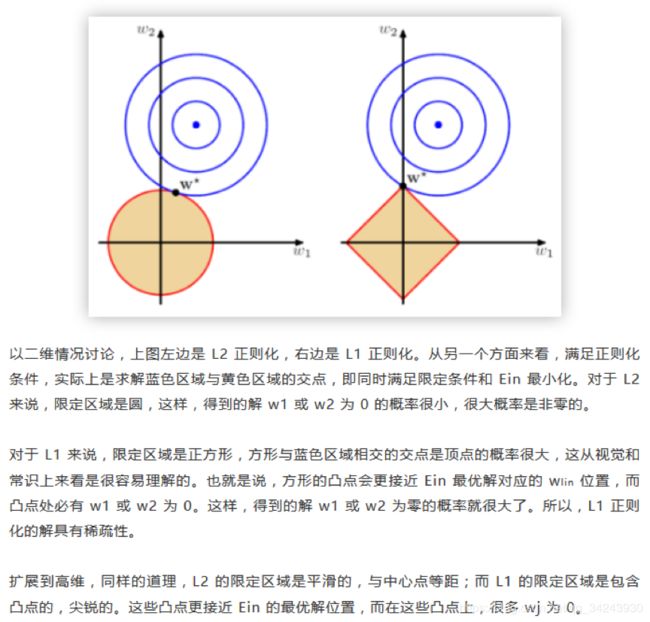
2.1 使用的正则化不同,岭回归使用L2正则化,Lasso使用L1正则化。L2正则化优点是易于求导,简化计算,更加常用一些。L1正则化优点是能得到较稀疏的解,但缺点是不易求导。
09 树回归(第六周)
9.1 复杂数据的局部性建模
9.2 连续和离散型特征的树的构建
9.3 将 CART 算法用于回归
9.4 树减枝
9.5 模型树
9.6 示例:树回归于标准回归的比较
9.7 使用 Python 的 Tkinter 库创建 GUI
第一节学习内容
学习时长:1/06-1/09
任务1题目:书籍阅读
任务详解:阅读《机器学习实战》书籍第9章
作业1:将本章中“树回归与标准回归的比较”完整代码键入jupyter notebook,并添加详细注释。若有可能,自己可以优化该代码。
提交日期:1/09
提交形式:代码截图打卡或git链接提交
作业2(选做):将本章中“使用Python的Tkinter库创建GUI”完整代码键入jupyter notebook,并添加详细注释。若有可能,自己可以优化该代码。
提交日期:1/09
提交形式:代码截图打卡或git链接提交
补充作业!!!!!!!
天池O2O优惠券使用预测分析比赛开始啦!
学习时长:1/6-1/11
任务1题目:阿里云天池o2o优惠券使用预测分析比赛(初级)
任务详解:建立一个简单的线性模型,在线提交预测结果,查看成绩
视频地址: https://m.weike.fm/lecture/10888815(观看密码:031220)
源码文件: https://pan.baidu.com/s/1MQIutT1ALrPETGE1SXy_pQ(提取码:rql8)
作业名称:使用简单模型,在线提交预测结果,查看成绩
作业提交日期:1/11
任务提交形式:代码截图打卡或git链接提交,比赛上传结果界面排名截图打卡上传
10 利用 K-均值聚类算法对未标注数据分组(第六周)
10.1 K-均值聚类算法
10.2 使用后处理来提高聚类性能
10.3 二分 K-均值算法
10.4 示例:对地图上的点进行聚类
第二节学习内容
学习时长:1/10-1/12
任务1题目:书籍阅读
任务详解:阅读《机器学习实战》书籍第10章
作业1:将本章10.4.2中“对地理坐标进行聚类”完整代码键入jupyter notebook,并添加详细注释。若有可能,自己可以优化该代码。
提交日期:1/11
提交形式:代码截图打卡或git链接提交
11 使用 Apriori 算法进行关联分析(第七周)
11.1 关联分析
11.2 Apriori 原理
11.3 使用Apriori 算法来发现频繁集
11.4 从频繁项集中挖掘关联规则
11.5 示例:发现国会投票中的模式
11.6 示例:发现毒蘑菇的相似特征
第一节学习内容
学习时长:1/13-1/14
任务1题目:书籍阅读
任务详解:阅读《机器学习实战》书籍第11章11.1/11.2/11.3节
作业1:使用Apriori算法进行关联分析的目标主要包含哪两个方面?Apriori的原理是什么?
提交日期:1/14
提交形式:文字或者截图打卡
作业参考答案
说明:当天作业参考答案隔天发布
1.1 Apriori算法关联分析的目标主要包括两项:发现频繁项集和发现关联规则。Apriori原理是说如果某个项集是频繁的,那么它的所有子集也是频繁的。反过来说,如果一个项集是非频繁集,那么它的所有超集也是非频繁的。
第二节学习内容
学习时长:1/15-1/18
任务1题目:书籍阅读
任务详解:阅读《机器学习实战》书籍第11章11.4/11.6节
作业1:将本章11.6中“发现毒蘑菇的相似特征”完整代码键入jupyter notebook,并添加详细注释。若有可能,自己可以优化该代码。
提交日期:1/18
提交形式:代码截图打卡或git链接提交
12 使用 FP-growth 算法高效发现频繁项集(第八周)
12.1 FP 树:用于编码数据集的有效方式
12.2 构建 FP 树
12.3 从一颗 FP 树中挖掘频繁项集
12.4 示例:在 Twitter 源中发现一些共现词
12.5 示例:从新闻网站点击流中挖掘
第一节学习内容
学习时长:1/20-1/21
任务1题目:书籍阅读
任务详解:阅读《机器学习实战》书籍第12章12.1/12.2节
作业1:FP-growth算法的基本工作流程是什么?其相比Apriori算法优点是什么?
提交日期:1/21
提交形式:文字或者截图打卡
作业2:理解带头指针表的FP树(图12.2),理解FP树生成代码。
提交日期:1/21
提交形式:文字或者截图打卡
作业参考答案
说明:当天作业参考答案隔天发布
1.1 FP-growth算法的基本工作流程分为两步。一、首先构建FP树。需要对原始数据集扫描两遍,第一遍对所有元素项的出现次数进行计数,第二遍只考虑那些频繁元素。二、挖掘频繁项集。
FP-growth算法只需要对数据库进行两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此FP-growth算法的速度要比Apriori算法更快。
1.2 略
第二节学习内容
学习时长:1/22-1/25
任务1题目:书籍阅读
任务详解:阅读《机器学习实战》书籍第12章12.3/12.5/12.6节
作业1:将本章12.5中“从新闻网站点击流中挖掘”完整代码键入jupyter notebook,并添加详细注释。若有可能,自己可以优化该代码。
提交日期:1/25
提交形式:代码截图打卡或git链接提交
13 利用 PCA 来简化数据(第九周)
13.1 降纬技术
13.2 PCA
13.3 示例:利用 PCA 对半导体制造数据降维
第一节学习内容
学习时长:1/27-1/28
任务1题目:书籍阅读
任务详解:阅读《机器学习实战》书籍第13章13.1/13.2/13.3节
作业1:将本章13.3中“利用PCA对半导体制造数据降维”完整代码键入jupyter notebook,并添加详细注释。若有可能,自己可以优化该代码。
提交日期:1/28
提交形式:代码截图打卡或git链接提交
14 利用 SVD 简化数据(第九周)
14.1 SVD 的应用
14.2 矩阵分解
14.3 利用 Python 实现 SVD
14.4 基于协调过滤的推荐引擎
14.5 示例:餐馆菜肴推荐引擎
14.6 示例:基于 SVD 的图像压缩
第二节学习内容
学习时长:1/29-2/1
任务1题目:书籍阅读
任务详解:阅读《机器学习实战》书籍第14章14.1-14.6节
作业1:将本章14.5中“餐馆菜肴推荐引擎”完整代码键入jupyter notebook,并添加详细注释。若有可能,自己可以优化该代码。
提交日期:1/30
提交形式:代码截图打卡或git链接提交
作业2:将本章14.6中“基于SVD的图像压缩”完整代码键入jupyter notebook,并添加详细注释。若有可能,自己可以优化该代码。
提交日期:2/1
提交形式:代码截图打卡或git链接提交
15 大数据与 MapReduce(第十周)
15.1 MapReduce:分布式计算的框架
15.2 Hadoop 流
15.3 在 Amazon 网络服务上运行 Hadoop 程序
15.4 MapReduce 上的机器学习
15.5 在 Python 中使用 mrjob 来自动化 MapReduce
15.6 示例:分布式 SVM 的 Pegasos 算法
15.7 你真的需要 MapReduce 吗?
比赛:天池O2O数据预测大赛(高级)(第十周)
第 1~7 章总结(第十一周)
第 8~9 章总结(第十一周)
第 10~12 章总结(第十二周)
第 13~15 章总结(第十二周)
其它机器学习算法(拓展,待定)(第十二周)
讲在前面
1、资料纷杂,资料不在多,而在精。
不要沉入搜集资料中,要学会舍弃不需要的资料。
保证高效学习。
2、动手很重要。
3、推荐的机器学习路线/教程
吴恩达,Coursera,machine learning课程(不是CS229,入门非常好)
台湾大学 林轩田的《机器学习基石》(讲解透彻,由浅入深)
台湾大学 林轩田的《机器学习技法》(干货,有概括,知识体系完善)
周志华《机器学习》
李航《统计学方法》
吴恩达,deep learning.ai
4、选择 《机器学习实战》的原因


手把手从0实现机器学习主流算法,实战和理论的交叉,这里我们用Python3实现
我们实现机器学习算法,加深对理论知识的理解。
提高实战能力,比赛经验。
作业代码等会发在老师GitHub上
5、具备先修知识:线性代数、概率论、python、机器学习基本知识
推荐廖雪峰Python3
6、需要开发环境anaconda+notebook(建议,不强制)