RAC DRM导致Oracle RAC节点Hang住
生活就像一盒巧克力,你永远不知道下一颗是什么味道。
--《阿甘正传》
在DBA的世界里,数据库的新特性就是这样一盒巧克力,可能是惊喜也可能是坑。毋庸置疑,新特性总是伴随着新功能而来,然而在企业最核心的数据资产面前,某些新功能的出现所带来的好处,远远不及其对于性能和稳定性带来的危害。因此我们常常会选择禁用一些新特性,今天要分享的DRM就属于其中一个。
为什么DRM通常会被列入禁用的名单,今天我通过一个真实案例来认识DRM可能会导致的数据库故障。
什么是DRM
在Oracle 10g版本中,开始提出了DRM特性,默认情况下,当某个对象的被访问频率超过某阈值,并且在某一节点的访问远高出其他节点,而同时该对象的master又是其他节点时,那么Oracle则会触发DRM操作来修改master节点。
DRM的好处是通过动态修改资源的主节点,可以大幅降低某些场景下的gc grant之类的等待事件而带来性能的提升。
但Oracle DRM的Bug也非常多,常常会引发各种奇异的故障。这类故障如何分析呢,我们今天结合具体的案例来学习。
故障现象
在我们维护的一套系统上,某一时刻业务部反应业务无法正常进行,系统hang住。
当时查看alert日志,结果如下:
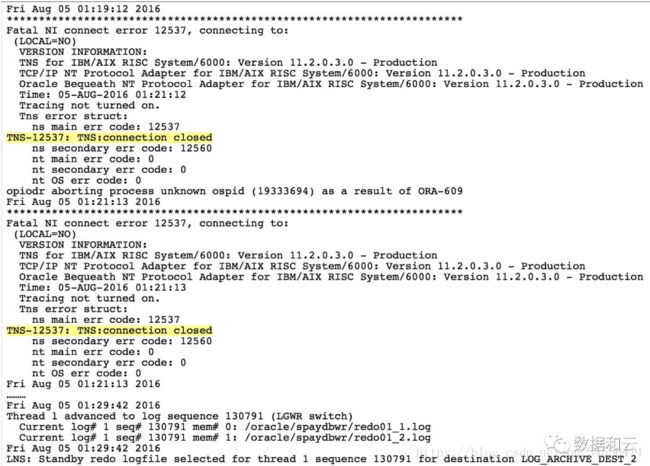
在01:19的时候实例1连接中断,01:29实例1恢复正常。实例2在这个时间段内是可以正常访问的,并且数据库alert日志正常。
错误分析:
-
从dba_hist_active_session以及后台进程trace文件中看到01:17时实例2的8248会话出现了大量gc current request等待,并且此会话也阻塞了其它很多session,引起很多control file sequential read、log file switch(checkpoint incomplete)、buffer busy waits这些等待。
-
从LMD进程的trace文件中看到的确出现了DRM事件,trace文件中看到有日志:Rcvd DRM(36333) READMOSTLYTransfer pkey 519282.0 to 1 oscan 0.1。随后就出现了”gc currentrequest”、”log file switch(checkpoint incomplete)”这样的等待事件。总结来说,看到的等待现象都是表象,问题的根源是数据库进行了DRM资源的动态调整,DRM会造成各种bug问题,这一点官方在SR中也承认了。
从收集的信息资料来看,数据库实例因为DRM而hang住的现象和BUG12998795基本匹配。但是SR中并没有明确给出确定的BUG号。
接收到个人账户数据库的严重告警后,第一时间检查了数据库后台告警日志、进程trace文件、ASH、AWR报告等相关重要信息。在排除了一些明显故障点后,立马收集告警日志、trace文件、dba_hist_active_session、oswatcher监控数据、数据库版本等信息。
分析如下:
1、数据库alert告警日志中失去连接响应前的告警日志:

数据库后台经常出现这样的告警,与ADG的传输进程有关,主库负载较高、主备库之间的网络抖动或网络丢包现象都会出现这个告警,传输进程LNS会重新尝试日志传输。
分析ORA-03113:end-of-file on communication channel相关的trace文件spaydbwr1_nsa3_58917326.trc、spaydbwr1_nsa4_20121152.trc以及NSA: Error 3113 archiving log6 to 'gzrz1'这样的错误告警,发现竟然是磁盘IO造成的?难道是存储有问题?
***2016-08-05 01:19:30.185
***2016-08-05 01:19:30.185 3327 krsb.c
krsb_iorb_reap:Error 3135 reaping buffers
krsb_bcb_get:Error 3135 performing stall for 1 BCB I/O completion check
***2016-08-05 01:19:30.186 4320 krsh.c
NSA: Error 3135 archiving log 6 to 'spaydbb'
Error1041 detaching RFS from standby instance at host 'spaydbb'
***2016-08-05 01:19:30.186 2961 krsi.c
krsi_dst_fail:dest:3 err:3135 force:0 blast:1
ORA-03135:connection lost contact
Closing Redo Read Context
经过排查并咨询了存储工程师,存储系统并无异常。但是这个错误和AWR报告中的top wait event中log file switch(checkpoint incomplete)等待现象比较符合。
为什么checkpoint没有完成从而造成了数据库hang住?
抓取了1点到2点的AWR报告,发现两个节点的topevents都是“enq: SQ - contention”如下图所示:
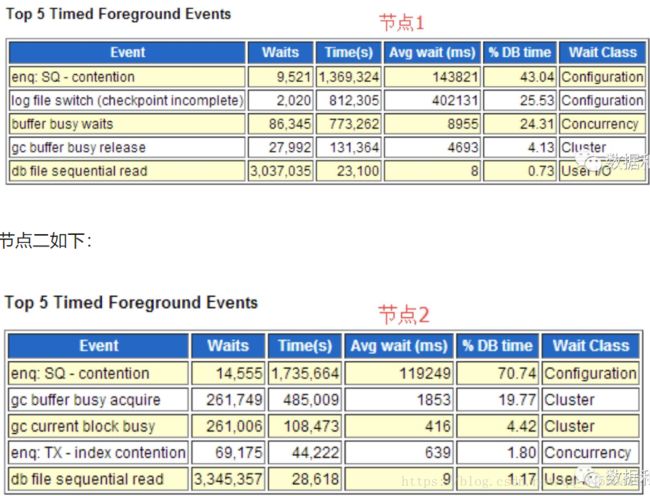
通过分析ash信息得知:基本都是sequence相关查询在等待。
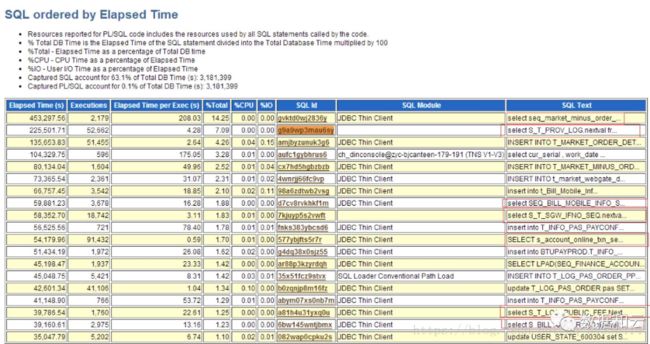
按时间排序的top SQL如下:
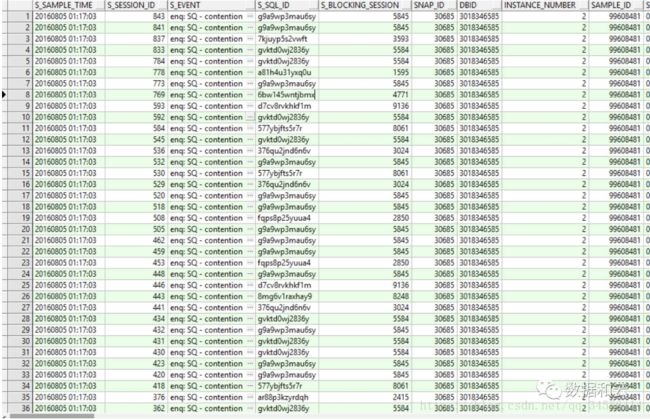
进一步分析dba_hist_active_session中session之间的阻塞关系时发现,sid为8248的这个session阻塞了其它大部分会话,这个会话是final blocker,问题的根源。
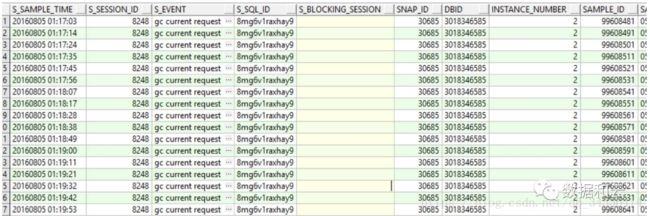
数据库hang的时候session 8248 正在执行SQL 8mg6v1raxhay9 SQL文本如下:
SELECTLPAD(SEQ_FINANCING_TCK_ORDER.NEXTVAL, 8, '0') FROM DUAL
一条sequence相关的在节点2的查询语句,但是它在等待gc current request。这就是问题的根源,为什么会有gc currentrequest这个等待?还是在实例2上发生的,很有可能是与DRM相关。
2、如果是DRM造成的gc current request等待,那么前面出现的等待log file switch(checkpoint incomplete)就容易解释了。因为drm造成的问题会导致整个数据库freeze。
继续分析trace文件:在01:07:30的时候发现有DRM相关操作

随后出现了bufer busy waits等待

还有gc current request等待:

还有后来出现的log file switch (checkpoint incomplete)等待
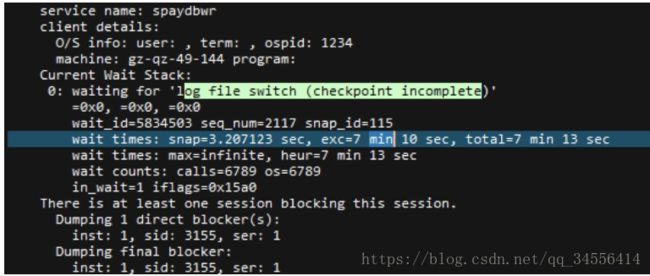
总结的来说,DRM的问题是先出现的,随后数据库就报出了一大堆问题。
分析和建议
根据提供的诊断材料分析来看,数据库中出现了严重的gc current request等待,很有可能触发了DRM方便的BUG。与以下BUG比较匹配:
Bug12998795 - RAC hang with signature 'gc current request'<='gc buffer busyacquire' (Doc ID 12998795.8)
SR中最终迟迟没有定论,需要等到下次数据库hang的时候,做hang anlyze然后分析dmp文件才能下结论。但是从沟通讨论的过程可以看到官方也承认是DRM方面引起的问题。提供的soloution中让我们尝试设置不受支持的隐含参数:"_gc_read_mostly_locking"=FALSE
"_gc_bypass_readers"=false。
解决方案
关闭数据库DRM功能。
A、方案1:彻底关闭需要修改_gc_policy_time=0参数,但是需要重启数据库。
B、方案2:在线调整参数_gc_policy_minimum=1000000
_gc_affinity_ratio=1000000
使其达不到设置的值,做到在线关闭DRM。
验证DRM是否关闭:
select* from v$policy_history wherepolicy_event = 'initiate_affinity';
案例总结
1、应用连接到数据库的方式改为负载均衡:案例为11g RAC系统,当应用发现连接到节点1失败后,自动切换到节点2的健康实例。
2、建议数据库升级到11.2.0.4的稳定版本,官方已经承认11.2.0.3有比较多的bug。