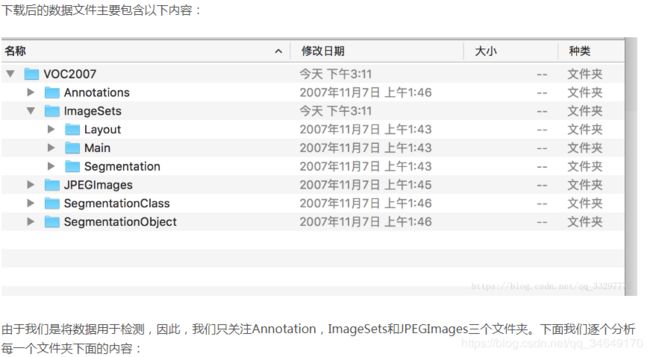
当某个数据库用户在数据库中插入、更新、删除一个表的数据,或者增加一个表的主键时或者表的索引时,常常会出现ora-00054:resource busy and acquire with nowait specified这样的错误。主要是因为有事务正在执行(或者事务已经被锁),所有导致执行不成功。
1.下面的语句
insert提示IGNORE_ROW_ON_DUPKEY_INDEX
转自:http://space.itpub.net/18922393/viewspace-752123
在 insert into tablea ...select * from tableb中,如果存在唯一约束,会导致整个insert操作失败。使用IGNORE_ROW_ON_DUPKEY_INDEX提示,会忽略唯一
1.记录慢查询配置
show variables where variable_name like 'slow%' ; --查看默认日志路径
查询结果:--不用的机器可能不同
slow_query_log_file=/var/lib/mysql/centos-slow.log
修改mysqld配置文件:/usr /my.cnf[一般在/etc/my.cnf,本机在/user/my.cn
@ControllerAdvice,是spring3.2提供的新注解,从名字上可以看出大体意思是控制器增强。让我们先看看@ControllerAdvice的实现:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Co
BW Element
OLAP Universe Element
Cube Dimension
Class
Charateristic
A class with dimension and detail objects (Detail objects for key and desription)
Hi