Hadoop大数据处理技术综合实验
实验任务
这篇博客是我们一个学期作业,记录在这里,只是方便我写作和一些解决过程的记录。具体实验步骤参考:http://dblab.xmu.edu.cn/post/7499/ 任务如下:
- 本地数据集上传到数据仓库Hive;
- Hive数据分析
- Hive、MySql、HBase数据互导;
- 利用Python/R进行数据可视化分析;
- 利用Apriori基于关联规则的购物篮分析。
本地数据集上传到数据仓库Hive
实验数据的准备
本实验提供了两个数据集,其中包括一个大规模数据集raw_user.csv(包含2000万条记录),和一个小数据集small_user.csv(只包含30万条记录)。我们的思路同链接一样,先用小一点数据集实验,后用大数据集进行最后的测试。数据集点击这里下载
[root@master lailai]# cd /usr/local/
[root@master lailai]# ls
[root@master local]# su lailai
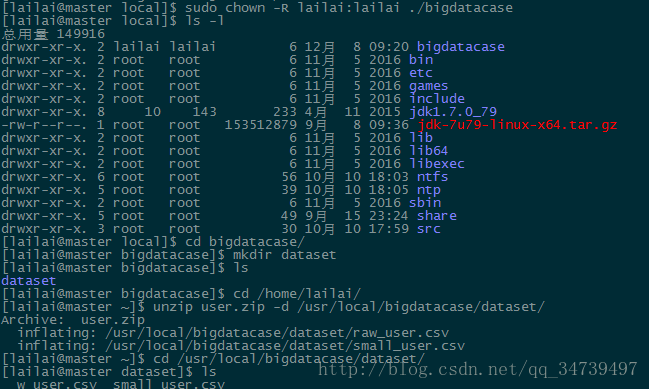
[lailai@master local]# sudo mkdir bigdatacase#这里使用sudo语法来获取其他用户权限,默认root
[lailai@master bigdatacase]$ sudo chown -R lailai:lailai ./bigdatacase #通过chown改变文件的拥有者和群组,-R 处理指定目录以及其子目录下的所有文件
[lailai@master local]$ cd bigdatacase/
[lailai@master bigdatacase]$ mkdir dataset
[lailai@master bigdatacase]$ cd /home/lailai/
[lailai@master ~]$ unzip user.zip -d /usr/local/bigdatacase/dataset/#解压文件zip,-d<目录>:指定文件解压缩后所要存储的目录运行结果如下:
[lailai@master dataset]$ head -5 raw_user.csv
数据集的预处理
- 删除文件第一行记录
[lailai@master dataset]$ sed -i '1d' small_user.csv [lailai@master dataset]$ head -5 small_user.csv结果如下:

- 对字段进行预处理
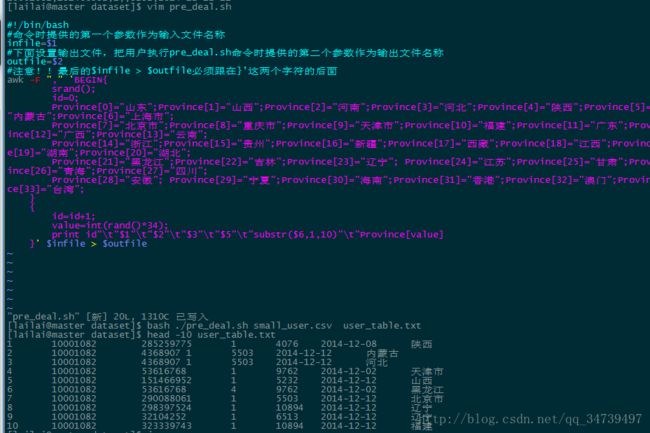
这里按照链接我们需要写一个shell脚本,其功能就是去掉每行读取的文件第四个字段,然后提取时间的前10个字符,srand()设置随机数种子,随机新增字段省份。
#!/bin/bash
#下面设置输入文件,把用户执行pre_deal.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行pre_deal.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
srand();
id=0;
Province[0]="山东";Province[1]="山西";Province[2]="河南";Province[3]="河北";Province[4]="陕西";Province[5]="内蒙古";Province[6]="上海市";
Province[7]="北京市";Province[8]="重庆市";Province[9]="天津市";Province[10]="福建";Province[11]="广东";Province[12]="广西";Province[13]="云南";
Province[14]="浙江";Province[15]="贵州";Province[16]="新疆";Province[17]="西藏";Province[18]="江西";Province[19]="湖南";Province[20]="湖北";
Province[21]="黑龙江";Province[22]="吉林";Province[23]="辽宁"; Province[24]="江苏";Province[25]="甘肃";Province[26]="青海";Province[27]="四川";
Province[28]="安徽"; Province[29]="宁夏";Province[30]="海南";Province[31]="香港";Province[32]="澳门";Province[33]="台湾";
}
{
id=id+1;
value=int(rand()*34);
print id"\t"$1"\t"$2"\t"$3"\t"$5"\t"substr($6,1,10)"\t"Province[value]
}' $infile > $outfile结果如下:
导入数据库
- 启动hdfs
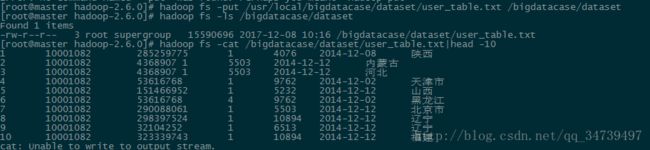
上传到hdfs目录。
[root@master hadoop-2.6.0]# ./sbin/start-all.sh #这里由于我的hdfs是用root权限安装的,所以要切换到root用户,否则会显示权限不足 [root@master hadoop-2.6.0]# hadoop fs -put /usr/local/bigdatacase/dataset/user_table.txt /bigdatacase/dataset [root@master hadoop-2.6.0]# hadoop fs -ls /bigdatacase/dataset结果如下:
在Hive上创建数据库
首先启动mysql作为Hive元数据
启动结果如下:[root@master hadoop-2.6.0]# service mysqld start [root@master apache-hive-2.3.0-bin]# ./bin/hive hive> create database dblab > ; hive> use dblab; hive> CREATE EXTERNAL TABLE dblab.bigdata_user(id INT,uid STRING,item_id STRING,behavior_type INT,item_category STRING,visit_date DATE,province STRING) COMMENT 'Welcome to xmu dblab!' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '/bigdatacase/dataset';#创建外部表,存储的数据在hdfs下'/bigdatacase/dataset’,即使把文件夹删除,此外部表数据结构还是存在的,我们只需再次创建此文件夹,就能导入数据。 hive> select * from bigdata_user limit 10;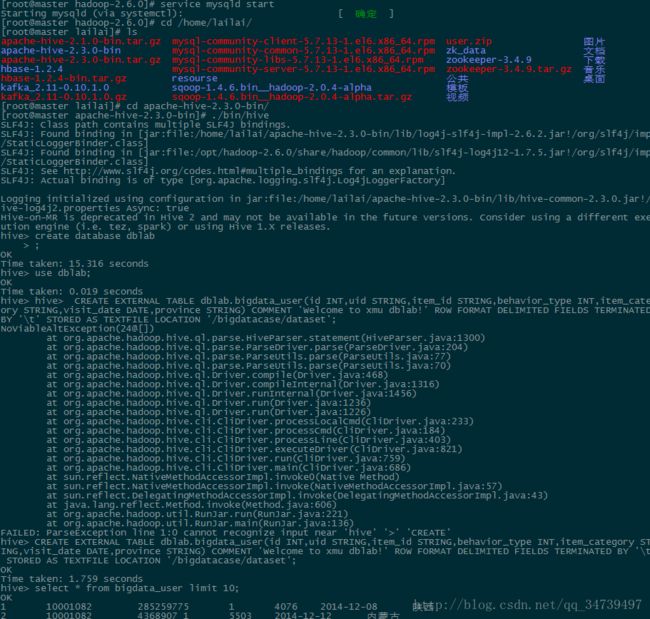
- 启动hdfs
Hive数据分析
首先我们先启动hadoop、mysql和hive。
简单查询分析
- 用聚合函数count()计算出表内有多少条行数据。当运行到这里时,我的hive出问题了,一直说内存不足,或者然后卡着不动。因为count会调用hadoop,当初我以为我的内存不够运行300000条数据,我就截取其中50条head -50 bigdata_user > test_user测试此语句,还是一样,由此可知我的hadoop集群有问题,然后我把集群格式化(此时记得删除子节点hadoop-tmp文件夹,不然没有datanode),便可导入成功。
select count(distinct uid) from bigdata_user;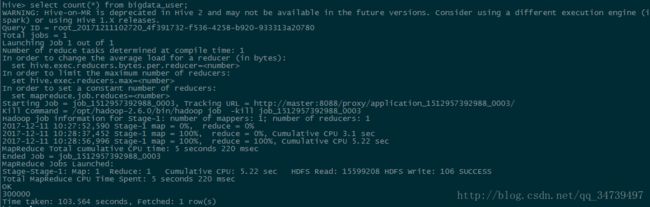
可以看到返回了300000条数据。- 我们可以加上distinct,查出某一列不重复的数据有多少条。
select count(distinct uid) from bigdata_user;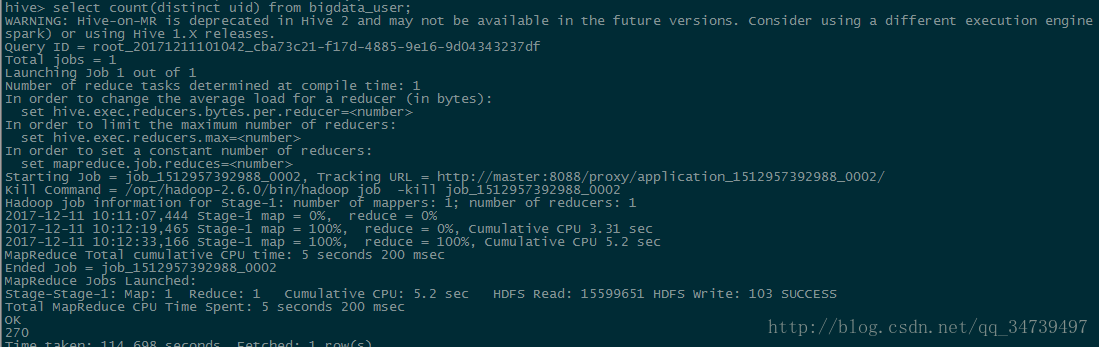
- 查询不重复的数据有多少条
select count(*) from (select uid,item_id,behavior_type,item_category,visit_date,province from bigdata_user group by uid,item_id,behavior_type,item_category,visit_date,province having count(*)=1)a;#这里用了嵌套语句,用group by 来分组,这里是聚合函数,只能用having来设置条件而不能用where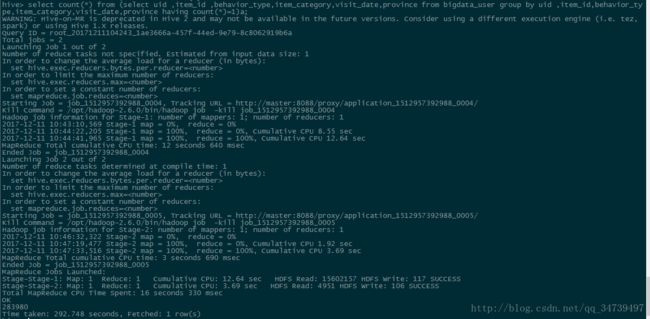
可以看到有283980条不重复的数据,这里执行过程中分配了两个任务,可能是先执行内部再到外部hql语句。注意:嵌套语句最好取别名,就是上面的a,否则很容易出现如下错误.

关键字条件
hive> select count(*) from bigdata_user where behavior_type='1' and visit_date<'2014-12-13'and visit_date>'2014-12-10';#这里我们可以通过where限制条件,让我惊奇的是日期这种格式可以直接比较大小,感叹数据库的强大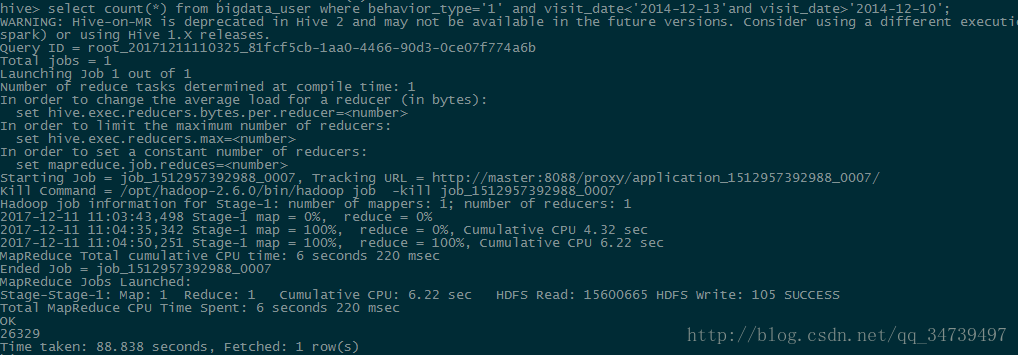
- 以月的第n天为统计单位,依次显示第n天网站卖出去的商品的个数
select count(distinct uid), day(visit_date) from bigdata_user where behavior_type='4' group by day(visit_date);#以day(d)可以从日期数据中提取具体天
可以看到真正卖出去的商品个数并不多,其中12号卖出98最多,27号最少。- 关键字赋予给定值为条件,对其他数据进行分析
取给定时间和给定地点,我们可以求当天发出到该地点的货物的数量
select count(*) from bigdata_user where province='江西' and visit_date='2014-12-12' and behavior_type='4';
可以看到2014-12-12发货到江西的数量为14。根据用户行为分析
- 查询一件商品在某天的购买比例或浏览比例
我们需要分别求得当天的购买数和浏览数。
hive> select count(*) from bigdata_user where visit_date='2014-12-11'and behavior_type='4';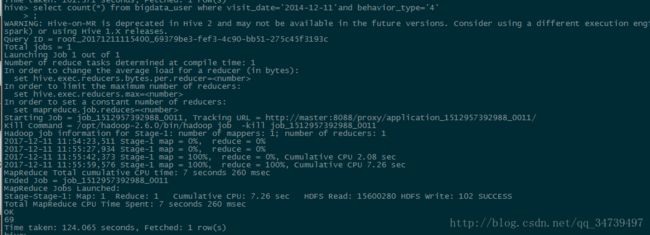
hive> select count(*) from bigdata_user where visit_date ='2014-12-11';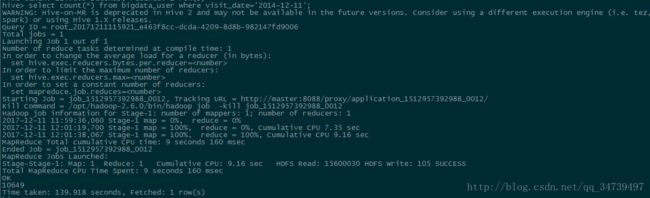
可以计算到当天的购买率为:0.64%,看起来很低,其实想想也是很正常的。- 查询某个用户在某一天点击网站占该天所有点击行为的比例(点击行为包括浏览,加入购物车,收藏,购买)
hive> select count(*) from bigdata_user where uid=10001082 and visit_date='2014-12-12';#查询用户10001082在2014-12-12(双12不知道那时候有没有)点击网页次数。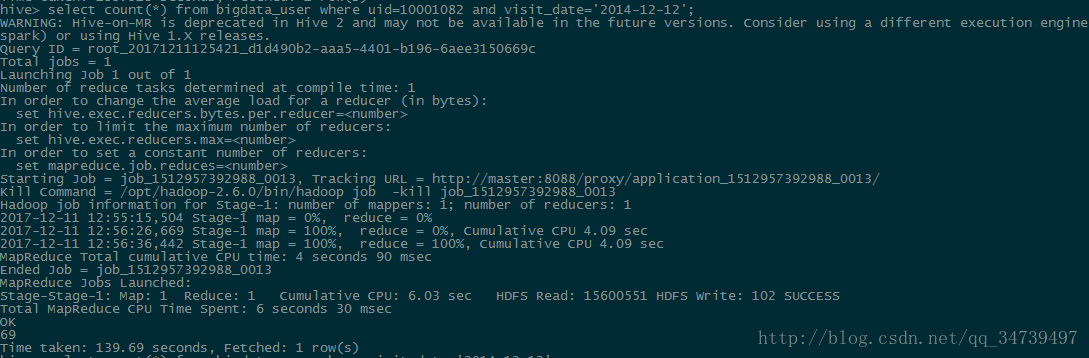
hive> select count(*) from bigdata_user where visit_date='2014-12-12';//查询所有用户在这一天点击该网站的次数
得到比例0.39%- 给定购买商品的数量范围,查询某一天在该网站的购买该数量商品的用户id
hive> select uid from bigdata_user where behavior_type='4' and visit_date='2014-12-12' group by uid having count(behavior_type='4')>5;#查询2014-12-12当天购买数超过5的id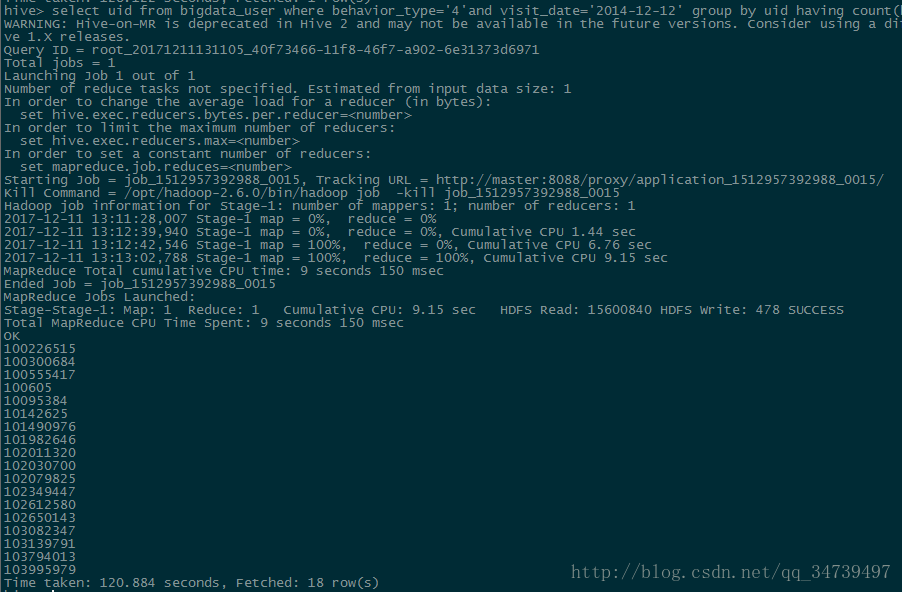
- 查询一件商品在某天的购买比例或浏览比例
用户实时查询分析
- 某个地区的用户当天浏览网站的次数
hive> create table scan(province STRING,scan INT) COMMENT 'This is the search of bigdataday' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;#创建一个内部表,包含省份和浏览数两项 hive> insert overwrite table scan select province,count(behavior_type) from bigdata_user where behavior_type='1' group by province;#可以直接将查询的结果导入表中,这点与sql很像。 hive> select * from scan;#查询结果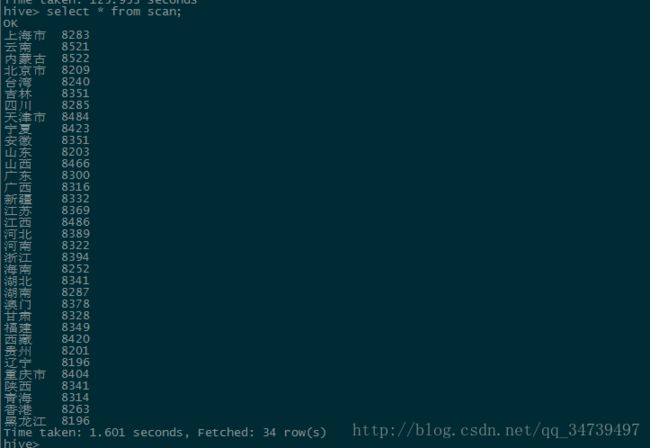
由于这里省份都是随机分配的,所以没什么参考价值。
Hive、MySql、HBase数据互导
Hive预操作
开启hadoop、mysql、hive- 创建临时表user_action
hive> create table dblab.user_action(id STRING,uid STRING, item_id STRING, behavior_type STRING, item_category STRING, visit_date DATE, province STRING) COMMENT 'Welcome to XMU dblab! ' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;#这里在hive里面创建内部表user_action这个命令会自动在HDFS文件系统中创建对应的数据文件“/user/hive/warehouse/dblab.db/user_action”。
- 将hive外部表bigdata_user表中的数据插入到user_action
hive> INSERT OVERWRITE TABLE dblab.user_action select * from dblab.bigdata_user;#上面已经说过内部表可以直接插入查询结果这个命令执行完以后,Hive会自动在HDFS文件系统中创建对应的数据文件“/user/hive/warehouse/dblab.db/user_action”这方便后面我们从本地导入hbase。

- 将bigdata_user表中的数据插入到user_action
hive>select * from user_action limit 10;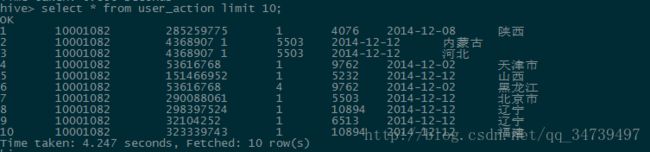
使用Sqoop将数据从Hive导入MySQL
首先我们要和前面一样开启hadoop、mysql、hive
然后在mysql创建一个待导入的表,由于表中还含有中文所以我们需要改一下编码set character_set_server=utf8;#临时修改,具体参考上面给的链接 ./bin/sqoop export --connect jdbc:mysql://localhost:3306/dblab --username root --password hadoop --table user_action --export-dir '/user/hive/warehouse/dblab.db/user_action' --fields-terminated-by '\t';#使用sqoop命令将hadoop下建的hive的表导入到mysql
但是我改了临时utf-8编码后还是识别不了中文,这个问题有待解决。
ps:后来通过改文件成功识别中文。使用Sqoop将数据从MySQL导入HBase
- 创建表user_action
hbase> create 'user_action', { NAME => 'f1', VERSIONS => 5}#创建hbase表,NAME可以随意命名。 ./bin/sqoop import --connect jdbc:mysql://localhost:3306/dblab --username root --password hadoop --table user_action --hbase-table user_action --column-family f1 --hbase-row-key id --hbase-create-table -m 1#把hadoop改成你自己mysql的密码,m表示启动map数量,我改了其他值测试好像没用在这里由于我反复创建表可能会出现错误,即使删除了还存在给上链接
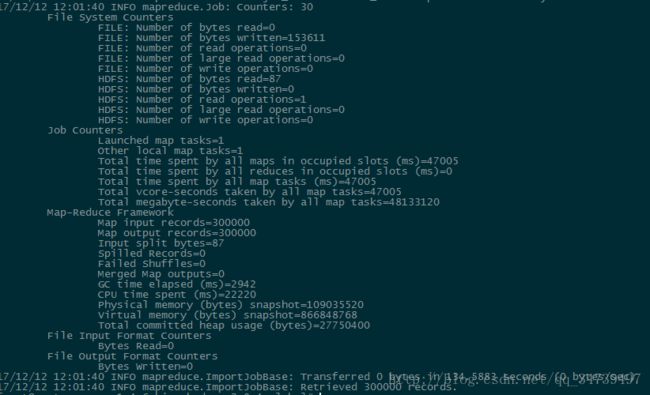
habse> scan 'user_action',{LIMIT=>10}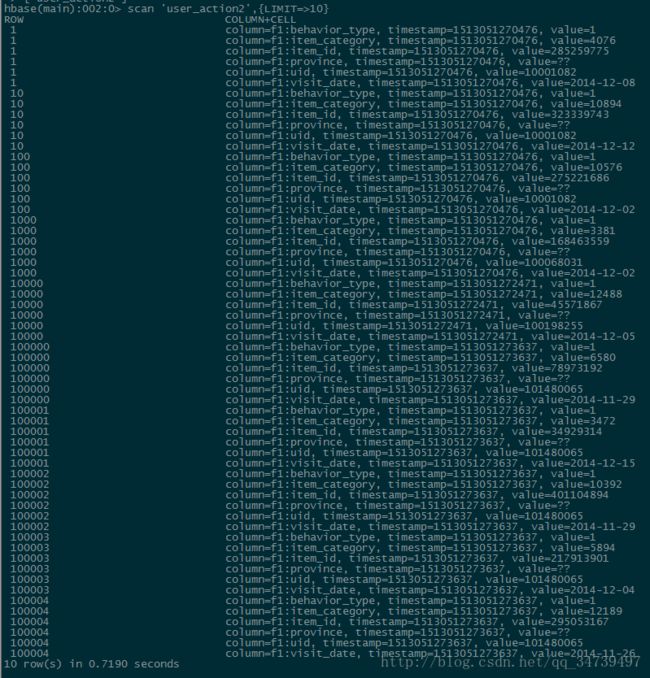
可以看到导入成功,我们用limit10是返回HBase表中的前面10行数据,但是,上面的结果,从“行数”来看,给人一种错误,似乎不是10行,要远远多于10行。这是因为,HBase在显示数据的时候,和关系型数据库MySQL是不同的,每行显示的不是一行记录,而是一个“单元格”参考链接。使用HBase Java API把数据从本地导入到HBase中
- 数据准备
我们先将hdfs中的数据复制到本地
cd /usr/local/bigdatacase/dataset /usr/local/hadoop/bin/hdfs dfs -get /user/hive/warehouse/dblab.db/user_action . #将HDFS上的user_action数据复制到本地当前目录,注意'.'表示当前目录 cat ./user_action/* | head -10 #查看前10行数据 cat ./user_action/00000* > user_action.output #将00000*文件复制一份重命名为user_action.output,*表示通配符 head user_action.output #查看user_action.output前10行- 数据导入
我们先在eclipse打包jar包,然后在linux下运行,另外我们还需要把hbase中前面建的表清除记录。
hbase> truncate 'user_action' Truncating 'user_action' table (it may take a while): - Disabling table... - Truncating table... 0 row(s) in 4.0120 seconds //删除以后再查看就没有记录了 hbase> scan 'user_action',{LIMIT=>10} ROW COLUMN+CELL 0 row(s) in 0.4010 seconds hadoop jar /usr/local/bigdatacase/hbase/ImportHBase.jar HBaseImportTest /usr/local/bigdatacase/dataset/user_action.output在执行中我又出现了错误
hadoop+hbase导致报错(NoClassDefFoundError: org/apache/hadoop/hbase/HBaseConfiguration)
我参考方法二解决
附录:ImportHBase.java代码就不贴了,上面给出链接有。大数据案例-步骤四:利用R进行数据可视化分析
- 数据准备
环境
利用windows下的R来连接linux下Mysql并进行可视化分析。由于我更习惯在windows下使用R,所以打算在windows下直接连mysql。
R语言连接mysql
library(RMySQL) conn <- dbConnect(MySQL(),dbname='dblab',username='root',password='SeMBYe((_4Hv',host="192.168.88.128",port=3306)其实方法与linux下r连接mysql一样,但是host我们改成linux下ip地址,然后密码是你的mysql初始密码,改后的密码没用,怎么查看如下

然后我们需要把编码格式改成能识别中文dbSendQuery(conn,'SET NAMES gbk') data <- dbGetQuery(conn,'select * from user_action')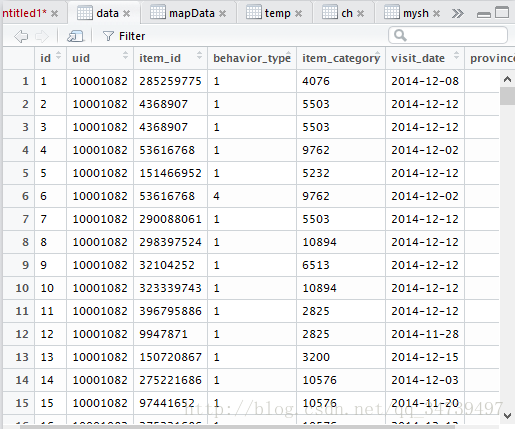
可以看到读取数据成功分析消费者对商品的行为
然后我们查看数据的五数汇总(最小值,第一四分位数,中位数,第三四分位数,最大值)summary(as.numeric(data$behavior_type))#因为是字符型数值,我们需要转化一下
用柱状图表示用户购物行为library(ggplot2) ggplot(data,aes(as.numeric(behavior_type)))+geom_histogram()#直方图
可以观察到大部分用户只是浏览,购买商品很少,也符合常理。分析哪一类商品被购买总量前十的商品和被购买总量
temp <- subset(user_action,as.numeric(behavior_type)==4) # 获取子数据集,subset函数可以从数据框中提取满足要求的项。 count <- sort(table(temp$item_category),decreasing = T) #排序,table能计算每个分类的量 print(count[1:10]) # 获取第1到10个排序结果
用散点图来可视化result <- as.data.frame(count[1:10]) #将count矩阵结果转换成数据框 ggplot(result,aes(Var1,Freq,col=factor(Var1)))+geom_point()#Var1和Freq是转化数据库系统默认生成的,我们可以通过names来修改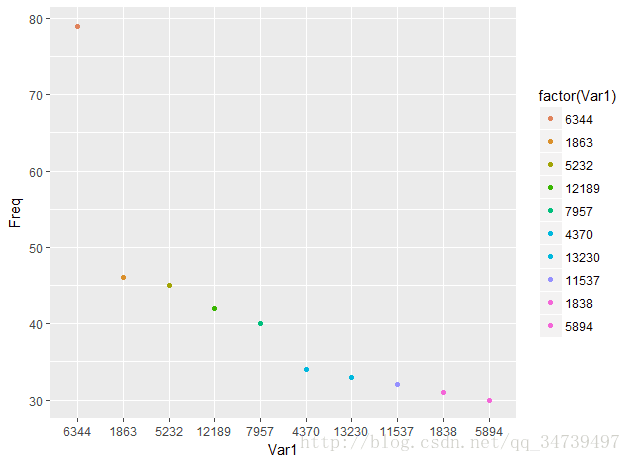
分析每年的哪个月份购买商品的量最多
因为日期是年月日数据,我们需要用substr来截取数据... month <- substr(data$visit_date,6,7)# visit_date变量中截取月份 user_action <- cbind(data,month) # user_action增加一列月份数据 ggplot(user_action ,aes(as.numeric(behavior_type),col=factor(month)))+geom_histogram()+facet_grid(.~month) #facet_grid刻面来按照每个月份,配置一个单行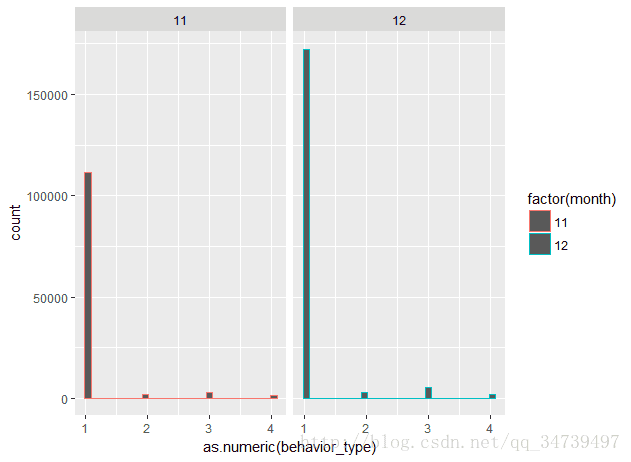
只有11和12月份所以分成两列,可以看到12月份各数略高。
分析国内哪个省份的消费者最有购买欲望
library(recharts) rel <- as.data.frame(table(temp$province))#按照省份来计数购买量 provinces <- rel$Var1#系统默认的Var1为省份值 x = c() for(n in provinces){ x[length(x)+1] = nrow(subset(temp,(province==n)))统计每个省份的量,存储到向量中 } mapData <- data.frame(province=rel$Var1, count=x, stringsAsFactors=F) # 设置地图信息 eMap(mapData, namevar=~province, datavar = ~count)#eMap必须导入数据框类型,这里我的Rstudio导入recharts库出现了问题,不知道你们电脑怎么样,有的同学直接用install.packages(“recharts”)又成功了。提供一种方法
install.packages( 'recharts', repos = c('http://yihui.name/xran', 'http://cran.rstudio.com') )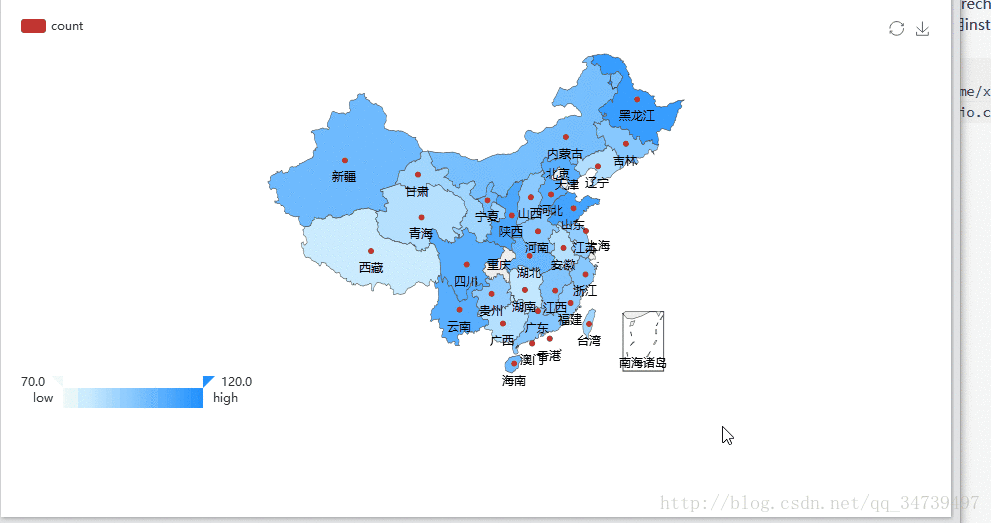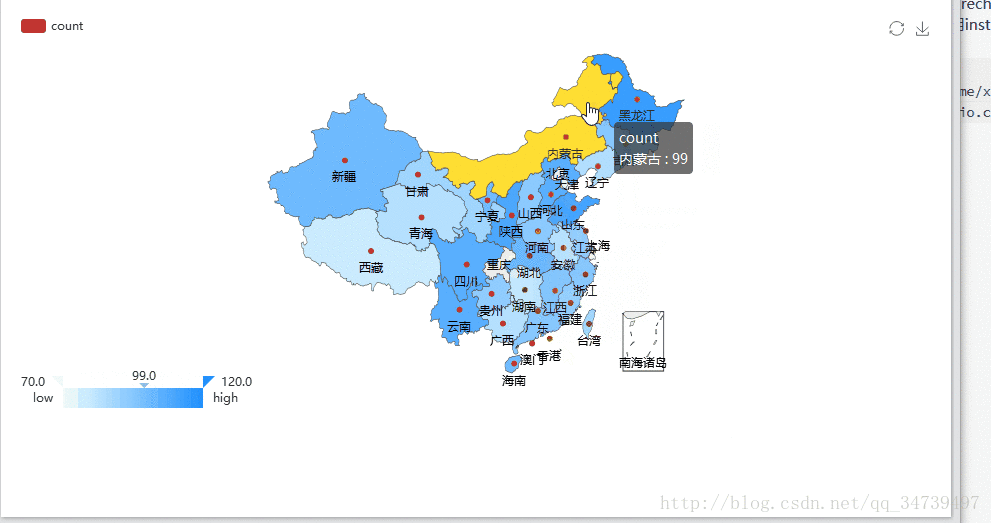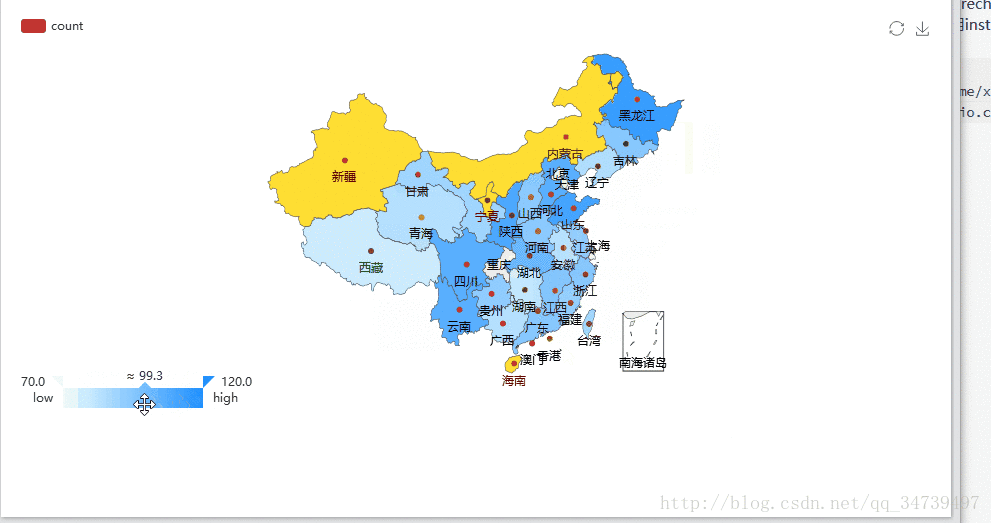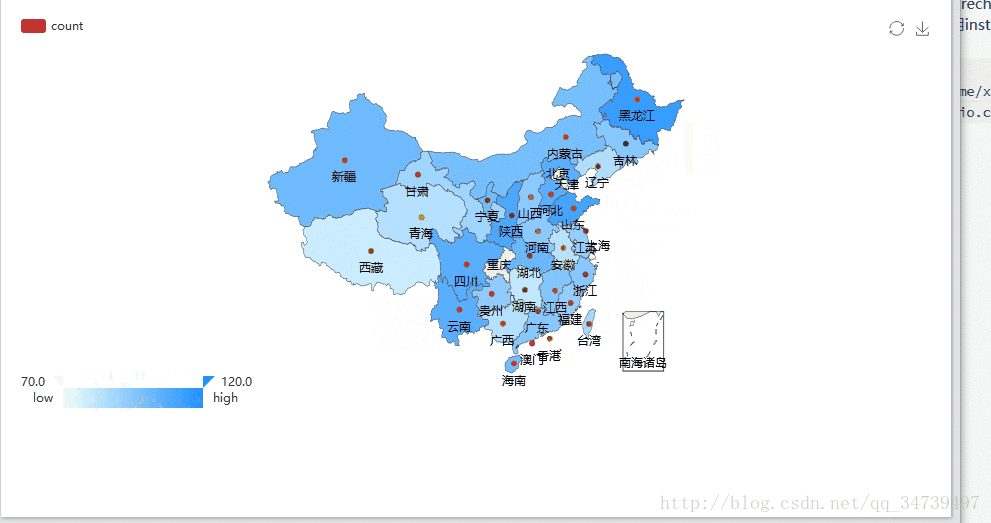
recharts包还是非常强大的,基于百度Echarts2开发,具体细节参考https://madlogos.github.io/recharts/index_cn.html#-enmaptools,ggplot2绘制中国地图
还有另外一种比较古老的方法绘制,基于地图的GIS数据来绘制,此方法比较复杂,而且数据较老,我尝试了一下,虽然做出来了但是效果一般,贴上运行结果
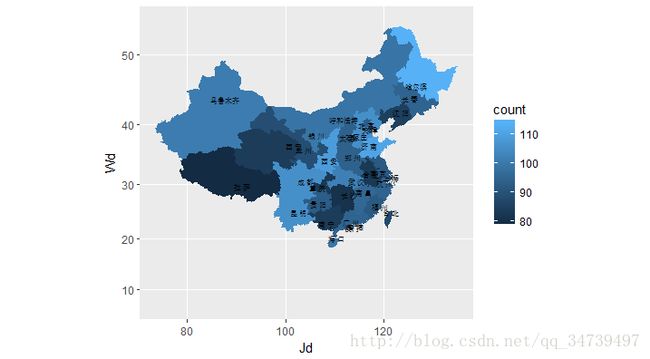
详情参考R 绘制中国地图,并展示流行病学数据
其中的一个错误我也卡了好久,贴上原因

利用Apriori基于关联规则的购物篮分析
这是我学习机器学习算法后,觉得可以运用到此数据集,虽然此数据集并没有给出商品的名称,但是我们可以以此作为练习,以后碰见相同的数据集时,可以以此作为参考。详情参考《机器学习与R语言》这本书。
数据预处理
前面我们曾经把每个购买记录为4(也就是购买了商品的记录)筛选出来了,如下:
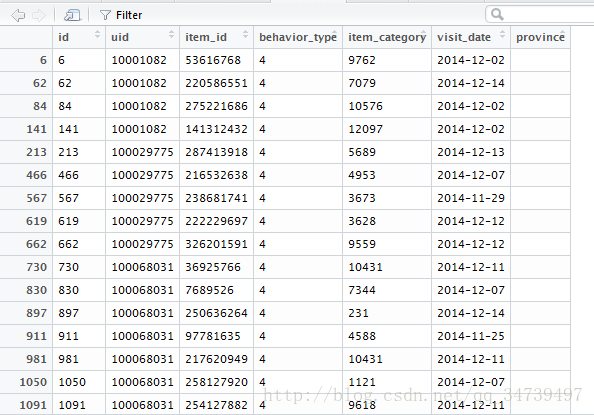
但是我们对于Apriori算法我们需要将此关系型数据转化为事务型数据,以用户id(uid)和时间(visit_date)作为商品分组。将文件转化为事务性数据 transform <- function(x){ a <- split(x,x$visit_date) for (i in 1:length(unique(x$visit_date))){ b <- split(as.data.frame(a[i]),as.data.frame(a[i])[,2]) for (j in 1:length(unique(as.data.frame(a[i])[,2]))){ write.table(t(as.numeric(as.data.frame(b[j])[,5])),file = "C:\\Users\\user\\Desktop\\1.txt",append = T,col.names = F,row.names = F) } } } >transform(temp)我们定义了一个r函数来转化文件,结果如下:
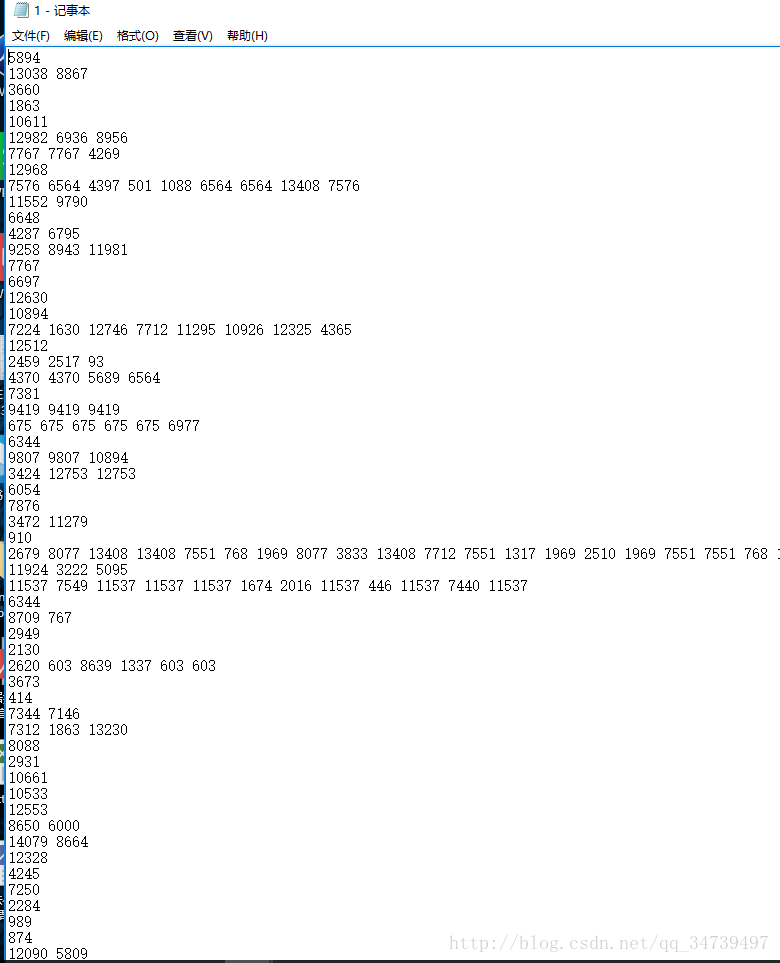
每一条记录对应了该天该用户购买的物品种类。接下来我们需要引入两个概念来评估我们的规则好坏
支持度
数据中出现的频率
support(X)=count(X)N置信度
该规则的预测能力或者准确率的度量
confindence(X→Y)=support(X,Y)support(N)
对于具有高频率和高置信度的规则称为强规则,以此我们可以推测用户购物的兴趣水平,以此作为推荐商品。数据准备—为交易数据创建一个稀疏矩阵
这里我们采用前几篇博文中朴素贝叶斯处理垃圾短信的方法,为每一个商品特征创建一个稀疏矩阵,在R中我们需要引入一个库arules,将数据读取到R中。groceries <- read.transactions("C:\\Users\\user\\Desktop\\1.txt",sep = " ") summary(groceries)
可以看到有1262行、983列的稀疏矩阵,这其中大部分的是0,稀疏矩阵实际上没有存储完整矩阵,所以效率高一些。density值得是非0元素所占总矩阵的比例,下面就是1863类的商品出现的次数为42,是最高的,后面以此类推。788次交易中只包含单一的商品,229次包含2件,以此类推。我们再来看看前五项交易数据
inspect(groceries[1:5])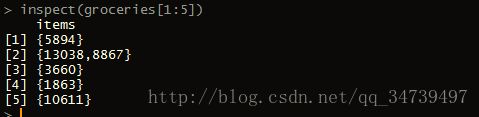
符合我们导入的原始文件前五项如果还想看看商品类出现的比例
itemFrequency(groceries[,1:3])
可以看到前三类商品的频率,也就是前面的支持度。可视化商品的支持度
> itemFrequencyPlot(groceries,support=0.015)
至少支持度有1.5%的11类商品。我们再来看看前20支持度的商品
> itemFrequencyPlot(groceries,topN=20)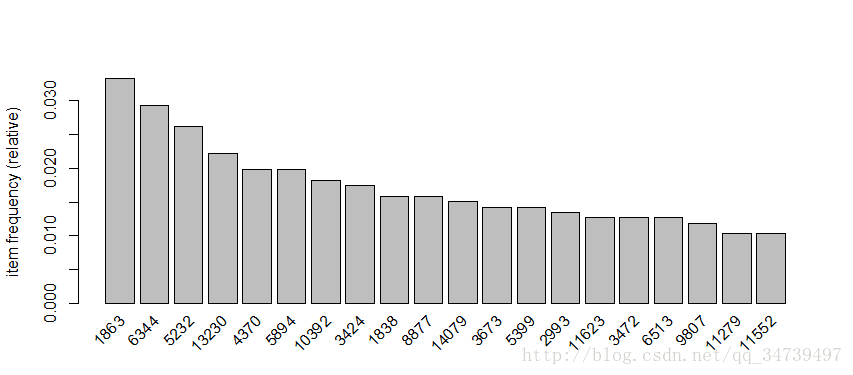
可视化交易数据
由于交易量比较大,图像很难展示出来,所以我们随机抽取200次交易,并用散点图表示> image(sample(groceries,200))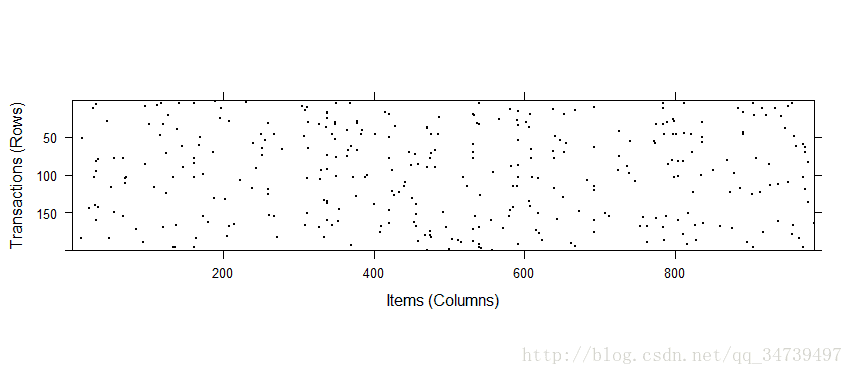
交易还是比较随机分布的,大致有些商品黑点还是比较集中,说明比较受欢迎。基于数据训练模型
这里我们还是依旧用arules包中的apriori函数来训练数据模型,这里唯一的难点就是支持度和置信度阈值的设定> groceryrules <- apriori(groceries,parameter = list(support=0.002,confidence=0.5,minlen=2))#列表传递参数,minlen设定的是规则的最小为两类商品
可以看到我们建立了77条规则,这其中有很多规则是没有用的,所以还要进一步分析。评估模型的性能
> summary(groceryrules)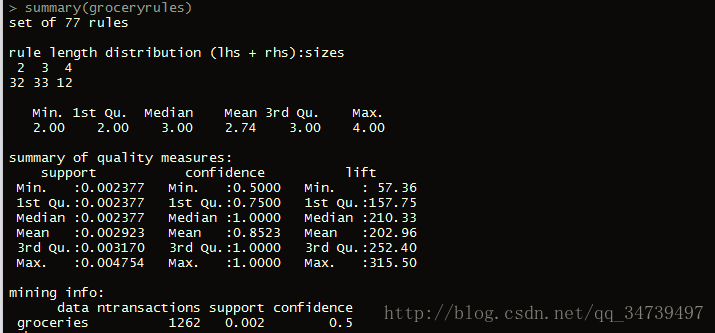
首先我们看规则中有两类商品的有32个({a}→{b}为两类,其他以此类推),三类有33个,可以看到结果还是比较正常的。
第三项summary of quality measures中,支持度和置信度我们没什么问题,lift(提升度)是用来度量一类或商品集相对于一般的购买率,计算公式如下:
lift(X→Y)=confidence(X→Y)support(Y)
也就是规则的置信度除以支持度。下面我们就以提升度为指标来从高到低排序
> inspect(sort(groceryrules,by="lift")[1:20])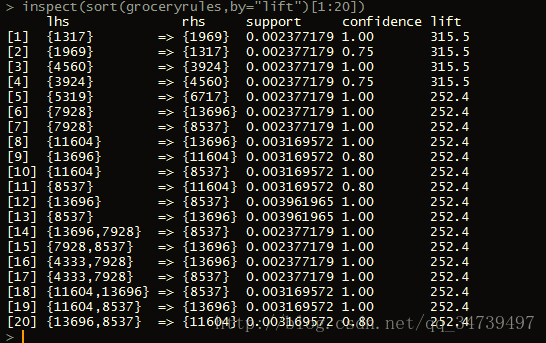
可以看到我们的规则的lift都很高,最小都有57.36,主要是因为置信度高,而支持度相对较低,不过我们还是可以从中筛选出比较好的规则,比如购买了1317类的顾客,购买1969类的可能比一般顾客的300多倍的可能性,如果我们还想得到特定分类的关联规则我们可以运用强大的subset函数来进行条件限制,比如我们对11604类感兴趣> a <- subset(groceryrules,items %in% "11604") > inspect(a)
可以看到4333、13696、8537这几类与它关系“密切”,这样就可以方便商家推荐商品分类了。
好了,分析到这里就结束了,学习之路还很长,希望大家砥砺前行!