基于python+selenium+Chrome自动化爬取巨潮资讯网A股财务报表
转自同学的博客
引言:
网页爬虫分为静态网页爬虫和动态网页爬虫,前者是指索要获取的网页内容不需要经过js运算或者人工交互,
后者是指获取的内容必须要经过js运算或者人工交互。这里的js运算可能是ajax,人工交互不需要解释了。
静态爬虫现在已经很成熟了,借助于python中的urllib和beautifulsoup可以很容易实现,爬到的内容通
过python的字符串处理写入数据库,甚至可以通过web形式展现。动态爬虫有两种工具,一种是selenium,现
在是selenium2(selenium+webdriver),另一种是headless的phantomjs(对caperjs的封装),前者主要是
通过控制浏览器实现,尤其是那种带video tag的场合,例如国内的一些CP站点例如youku,后者则是不需要
展现内容的场合,或者可以理解为不带video tag的场合。据说后者的速度要比前者快,因为它不需要浏览器
展现,可以闷头去做。但是我只接触了了selenium这个工具……..
动态爬虫相对于静态爬虫,速度是要慢很多的。一般来说,用静态爬虫方法爬不到的数据,我们才采用动态爬虫工具爬取。 爬取的方法简单粗暴,和平常操作浏览器很是一个道理。
工具简介:
Selenium:是ThoughtWorks开发的一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等,在python里面有第三方库,可直接安装使用。详细介绍见百度百科:https://baike.baidu.com/item/Selenium/18266?fr=aladdin
chrome:就是谷歌浏览器,一款功能强大且齐全的浏览器。
工具准备以及环境搭建:
python:首选Anaconda
selenium:pip install selenium
关键就是用selenium驱动chrome: 首先在http://www.chromeliulanqi.com/下载32位版本的谷歌浏览器(注意是32位。64位貌似驱动不了)。然后下载驱动插件 链接:https://pan.baidu.com/s/1jIIjlwq 密码:xnl1
下载解压后,将chromedriver.exe 发到Python的安装目录,例如 D:\python 。 然后再将Python的安装目录添加到系统环境变量的Path下面
用下面的python代码简单测试一下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')如果火狐浏览器自启并访问百度,则准备工作完成。
seleium的方法:
找了一篇相对详细具体的博客介绍http://blog.csdn.net/xfyangle/article/details/66478675,待会对目标网页分析的时候对具体方法说明一下。
开始爬取:
以下是巨潮资讯网的页面:
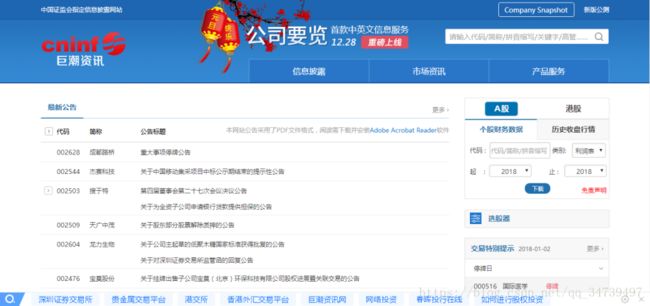
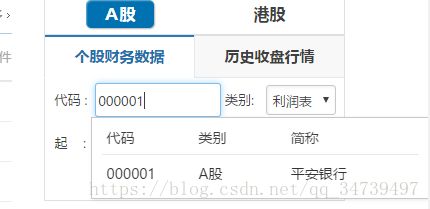
在个人财务数据那一栏,输入详细的公司代码,选择类别和年份,点击下载,浏览器就会下载并保存到本地了。我们用selenium驱动谷歌浏览器的话,其实也是一样的操作。
from selenium import webdriver #导入类库
driver = webdriver.Chrome() #实例化浏览器对象输入公司代码:
![]()
首先把鼠标点进代码文本框,右击审查元素,会看到这个文本框的网页源代码
选择用id进行定位,并向文本框中输入公司代码:
driver.find_element_by_id('index_cw_input_obj').send_keys("公司代码")在这个网站下载了一份包含所有公司代码的csv文件,将公司代码提取出来,保存在数组中,用for循环不断send就可以了:
import csv
with open("20171226091635.csv","r") as csvfile:
reader = csv.reader(csvfile)
for line in reader:
ID.append(line[0][1:])
ID=ID[2:] #ID就是包含所有公司代码的数组提交了代码之后,会出现下拉选择条
把鼠标移到下面,选择审查:

driver.find_element_by_name("公司代码").click() #通过name,也就是刚才在文本框中输入的公司代码,来定位,然后点击选择类别:
把鼠标移到类别框,审查元素

对于这种下拉菜单,有相应的方法选择其中的值,
from selenium.webdriver.support.ui import Select
select = Select(driver.find_element_by_css_selector('#index_select_type_obj'))
#通过css选择器,根据id定位到下拉菜单
select.select_by_index(j) #,选择相应的项,若j=0,则选择利润表,若j=1,则选择资产表,然后用for循环遍历3种表。选择年份(本次只需要选择左边的年份,右边的默认当前年份):
同上:审查元素之后,根据id定位
select2 = Select(driver.find_element_by_id('cw_start_select_obj')) #通过id定位到年份
select2.select_by_index(j) #默认选择最老的年份,j=0下载:
把鼠标移到下载按钮,点审查元素:
![]()
对于这个元素的定位,很奇怪,用id,name,xpath都不行,只能用css selector。对于css选择器以及xpath,我们不好直接知道他们具体的值,我们采用:对当前网页源代码这一行(如上图),右击,选择copy,然后选择copy selector 或者copy xpath,然后将复制的值,填到相应的方法的括号参数里面,即可定位。
driver.find_element_by_css_selector('#con-f-2 > div > div.down_button_row > button').click() #用css selector定位,然后用.click()方法点击改按钮,即可下载在你启动的浏览器中这就是大概的一个流程,除了上述所说的过程之外。在两步操作之间,要设定一定的时间间隔,让浏览器反应一下,若浏览器没有加载出来,就会出现找不到元素的错误。以及在大量下载数据的过程中,每次下载一定数量的文件之后,网站会要求输入验证码才能下载(但是每次都输不对,过段时间又可以下载)。这就需要巧妙的用sleep函数设置休息间隔了。
代码实现:
from selenium import webdriver
from selenium.webdriver.support.ui import Select
import time
import csv
count=1 #下载计数
relax=1 #休息计数
ID=[] #公司代码
NAME=[] #公司名称
with open("20171226091635.csv","r") as csvfile:
reader = csv.reader(csvfile)
for line in reader:
ID.append(line[0][1:])
NAME.append(line[1])
ID=ID[2:]
NAME = NAME[2:]
driver = webdriver.Chrome()
driver.get("http://www.cninfo.com.cn/cninfo-new/index#") #打开页面
time.sleep(5) #等待5s
for i in ID: #遍历所有的公司代码
while (relax % 60) == 0: #下载60个公司的报表,也就是点击下载180次,休息300s
time.sleep(300)
relax = relax + 1
while(relax%40)==0: #下载40个公司的报表,也就是点击下载130次,休息120s
time.sleep(120)
relax=relax+1
while(relax%20)==0: #下载20个公司的报表,也就是点击下载60次,休息60s
time.sleep(60)
relax=relax+1
driver.find_element_by_id('index_cw_input_obj').send_keys(i) #向文本框提交公司代码
driver.find_element_by_name(i).click() #选择相应的代码,点击
print("正在下载第" + str(count) + "个: 代码: " + ID[count - 1] + "名称: " + NAME[count - 1]+".....") #可视化下载的过程
for j in range(0,3): #每个公司又3个表
select1 = Select(driver.find_element_by_css_selector('#index_select_type_obj'))
select1.select_by_index(j) #选择相应的表
select2 = Select(driver.find_element_by_id('cw_start_select_obj'))
select2.select_by_index(0) #选择最久的年份
driver.find_element_by_css_selector('#con-f-2 > div > div.down_button_row > button').click() #点击下载
time.sleep(3) #等待3s
print("下载成功")
driver.find_element_by_id('index_cw_input_obj').clear() #将代码框中的代码清除
count=count+1 #加一
relax=relax+1 #加一
time.sleep(2) #下载完一个休息2s
print("下载完成")本地处理:
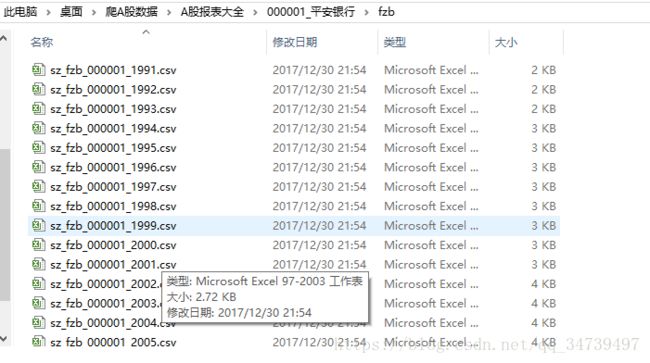
下载的zip文件是一个一个散的,很无序,而且都没有解压。如图:

首先位每个公司创建目录,名称为公司代码_公司名称。然后在每个公司目录下面创建3个目录,以此为lrb,fzb,llb。
import os #里面有创建文件夹的方法
import csv
count=0 #计数
ID=[] #公司代码
NAME=[] #公司名称
with open("20171226091635.csv","r") as csvfile:
reader = csv.reader(csvfile)
for line in reader:
ID.append(line[0][1:])
NAME.append(line[1])
ID=ID[2:]
NAME = NAME[2:]
os.mkdir("A股报表大全") #创建子目录
for x in ID:
filename=x+'_'+NAME[count] #将公司代码以及名称拼接起来
if '*' in filename:
filename=filename.replace("*","") #把公司名称里面的*去掉,不然创建文件时会提示非法字符
os.mkdir("A股报表大全/" + filename) # (‘/’代表改目录的下一个目录)在A股报表大全目录下创建以公司代码_公司名称为名字的目录
os.mkdir("A股报表大全/"+ filename + "/" + "lrb") #在公司目录下分别创建3个子目录
os.mkdir("A股报表大全/" + filename + "/" + "fzb")
os.mkdir("A股报表大全/" + filename + "/" + "llb")
count=count+1
接下来就是把zip解压,然后放到对应的文档里面
import zipfile #解压缩zip的库
import os
import csv
file_list = os.listdir(r'A股表压缩包大全.')
ID=[] #以 公司代码,公司名的形式循环存放
name="" #公司名称
table_tag="" #标记zip是什么类型的报表
file_dir=""
with open("20171226091635.csv","r") as csvfile:
reader = csv.reader(csvfile)
for line in reader:
ID.append(line[0][1:])
ID.append(line[1])
ID=ID[2:]
for file_name in file_list: #遍历压缩包目录
if os.path.splitext(file_name)[1] == '.zip':
print(file_name)
count = 0
id=file_name[7:13] #在zip压缩包的文件名中取出公司代码
table_tag=file_name[3:6] #在zip压缩包的文件名中取出公司名称
for i in ID:
if i==id:
name=ID[count+1]
break
count=count+1
file_dir=str(id)+'_'+str(name) #为zip压缩包找到他对应的目录名
if '*' in file_dir:
file_dir=file_dir.replace("*","") #去掉*
if table_tag=="lrb": #如果是lrb表
filedir="A股报表大全/"+file_dir + "/" + "lrb"
file_zip = zipfile.ZipFile("A股表压缩包大全/"+ file_name) #解压压缩包
for file in file_zip.namelist(): #遍历压缩包里的文件
file_zip.extract(file, filedir) #将file移动到filedir里面
file_zip.close() #关闭zip文件
if table_tag=="fzb":
filedir = "A股报表大全/" + file_dir + "/" + "fzb"
file_zip = zipfile.ZipFile("A股表压缩包大全/"+ file_name)
for file in file_zip.namelist():
file_zip.extract(file, filedir)
file_zip.close()
if table_tag=="llb":
filedir = "A股报表大全/" + file_dir + "/" + "llb"
file_zip = zipfile.ZipFile("A股表压缩包大全/"+ file_name)
for file in file_zip.namelist():
file_zip.extract(file, filedir)
file_zip.close()自此, 完整的A股财务报表大全就有序的整理好了,可下载看看百度云链接
总结:由于每一次爬取次数的限制,以及驱动谷歌浏览器所出现的有时响应缓慢的问题,再加上一些未知错误(莫名的程序就停下来了)。本次爬取花了大概4天的时间将3455家公司,10365个zip文件爬下来,可以说要非常的有耐心了。代码不是关键,耐心才是重点。
以上若有不详细之处,可自行百度,或者同我交流。