Spark实现Hadoop简单实例
众所周知,在hadoop中的主要操作是map和reduce,只有单纯的两种操作造成使用hadoop去编写去重、排序等简单实例需要很多的代码,至少需要一个map过程、一个reduce过程以及一个Job的配置。而在Spark中具有更加丰富的操作,增加了reduceBykey、union、distinct等近十种操作,同时匿名函数以及流式处理的方式使得很多实例的实现仅仅需要一行代码,对于代码的编写者来说更加地简单易用。笔者初探Spark,对Scala语言进行了简单学习后对下述六个hadoop简单实例,使用spark进行了实现。相信大家也可以在代码中感受到scala语言的简洁,但其可读性对于初学者而言不高,其中的匿名函数以及占位符等都与主流语言Java有些不同。事实上仍然有很多的语句是笔者处于初学状态下所进入的误区,造成代码仍然有些冗长。对一个RDD的操作可以在其后继续使用transformation而不需要另起一行重新定义一个新的RDD,在实践过以下几个实例后,相信读者能够读懂一般的spark程序。
1. 数据去重
“数据去重”主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重。
1.1 实例描述
对数据文件中的数据进行去重。数据文件中的每行都是一个数据。样例输入如下:
rdd1:
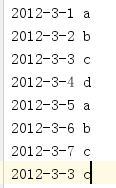
rdd2:
1.2 设计思路
首先,Spark有两种创建RDD的方式,第一种是从内部创建,使用parallelize方法,第二种是从外部创建,使用textfile方法。以下实例都是使用第二种方式创建,即从外部文本文件创建RDD。Spark中自带了union方法,可以对两个rdd取并集,并且有distinct方法,对rdd进行去重处理。
1.3 代码实现
object Dedupli {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Sort").setMaster("local")
val sc = new SparkContext(conf)
//创建两个rdd
val rdd1 = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/Dedupli/rdd1.txt")
val rdd2 = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/Dedupli/rdd2.txt")
//取并集
val union_RDD = rdd1.union(rdd2)
//对集合去重
var dedup_RDD = union_RDD.distinct()
//打印结果
dedup_RDD.foreach(println)
}
}2. 数据排序
“数据排序”是许多实际任务执行时要完成的第一项工作,比如学生成绩评比、数据建立索引等。这个实例和数据去重类似,都是先对原始数据进行初步处理,为进一步的数据操作打好基础。
2.1 实例描述
对输入文件中数据进行排序。输入文件中的每行内容均为一个数字,即一个数据。要求在输出中每行有两个间隔的数字,其中,第一个代表原始数据在原始数据集中的位次,第二个代表原始数据。样例输入如下:
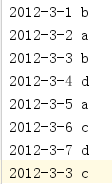
rdd1:

rdd2:
rdd3:

2.2 设计思路
先将三个rdd进行union操作后,使用Spark自带的sortBy方法进行排序,排序前需将rdd中的数据强制转换为Int型。
2.3 代码实现
object Sort {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Sort").setMaster("local")
val sc = new SparkContext(conf)
//创建三个rdd
val rdd1 = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/Sort/rdd1.txt")
val rdd2 = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/Sort/rdd2.txt")
val rdd3 = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/Sort/rdd3.txt")
//取并集
val rdd = rdd1.union(rdd2).union(rdd3)
//对rdd进行排序
val result_Rdd = rdd.sortBy(f=>(f.toInt))
//打印排序结果
result_Rdd.foreach(println)
}
}3. 平均成绩
“平均成绩”主要目的还是在重温经典”WordCount”例子,可以说是在基础上的微变化版,该实例主要就是实现一个计算学生平均成绩的例子。
3.1 实例描述
对输入文件中数据进行就算学生平均成绩。输入文件中的每行内容均为一个学生的姓名和他相应的成绩,如果有多门学科,则每门学科为一个文件。要求在输出中每行有两个间隔的数据,其中,第一个代表学生的姓名,第二个代表其平均成绩。样例输入如下:
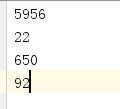
china:

english:
math:
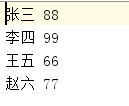
3.2 设计思路
将三个rdd进行union操作,需要对名字相同的分数进行累加再求平均分,所以需要存储为K-V对,value为分数值需要强制转换为Int类型。然后对K-V使用reduceByKey方法,将rdd中key相同的value值相加,再使用mapValues方法只对value值进行除以3操作。
3.3 代码实现
object Score {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Score").setMaster("local")
val sc = new SparkContext(conf)
//创建三个rdd
val math = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/Score/math.txt")
val china = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/Score/china.txt")
val english = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/Score/english.txt")
//合并数据集
val rdd1 = math.union(china).union(english)
//将数据集存储为K-V对
val rdd = rdd1.map(f => {
val part = f.split(" ")
(part(0), part(1).toInt)
} )
//累加V值求平均分
val rddtemp = rdd.reduceByKey(_+_).mapValues(_/3)
//输出结果
rddtemp.foreach(println)
}
}4. 单表关联
前面的实例都是在数据上进行一些简单的处理,为进一步的操作打基础。”单表关联”这个实例要求从给出的数据中寻找所关心的数据,它是对原始数据所包含信息的挖掘。
4.1 实例描述
实例中给出child-parent(孩子——父母)表,要求输出grandchild-grandparent(孙子——爷奶)表。样例输入如下:
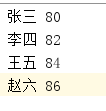
family:

4.2 设计思路
分别以parent-child的键值对作为左表,以child-parent的键值对作为右表进行自连接形成(key,values[])的数据结构,此时values[]中存储的是grandchild和grandparent,提取出其中的数据后按格式输出即可。
4.3 代码实现
object STjoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("STjoin").setMaster("local")
val sc = new SparkContext(conf)
//创建rdd
val rdd = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/STjoin/family.txt")
//将数据集存储为K-V对形成左表
val left_RDD = rdd.map(f => {
val part = f.split(" ")
(part(1), part(0))
} )
//将数据集存储为K-V对形成右表
val right_RDD = rdd.map(f => {
val part = f.split(" ")
(part(0), part(1))
} )
//左右表连接
val linked_RDD = left_RDD.join(right_RDD)
//取数据有效列并去重
val distinct_RDD = linked_RDD.map(f => {
(f._2._1, f._2._2)
}).distinct().sortByKey()
//打印结果
println("grandchild grandparent")
distinct_RDD.foreach(println)
}
}5. 多表关联
多表关联和单表关联类似,它也是通过对原始数据进行一定的处理,从其中挖掘出关心的信息。
5.1 实例描述
输入是两个文件,一个代表工厂表,包含工厂名列和地址编号列;另一个代表地址表,包含地址名列和地址编号列。要求从输入数据中找出工厂名和地址名的对应关系,输出”工厂名——地址名”表。样例输入如下:
address:

factory:

5.2 设计思路
与上面一个实例相类似,只是取有效列的时候所取的部分不同。
5.3 代码实现
object MTjoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("MTjoin").setMaster("local")
val sc = new SparkContext(conf)
//创建rdd
val rdd1 = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/MTjoin/factory.txt")
val rdd2 = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/MTjoin/address.txt")
//将factory存储为K-V对
val first_RDD = rdd1.map(f => {
val part = f.split(",")
(part(1), part(0))
} )
first_RDD.foreach(println)
//将address存储为K-V对
val second_RDD = rdd2.map(f => {
val part = f.split(" ")
(part(0), part(1))
} )
second_RDD.foreach(println)
//两表连接
val union_RDD = first_RDD.join(second_RDD)
//取有效列
val distinct_RDD = union_RDD.map(f => {
(f._2._1,f._2._2)
} ).sortByKey()
//打印结果
println("factoryname addressname")
distinct_RDD.foreach(println)
}
}6. 倒排索引
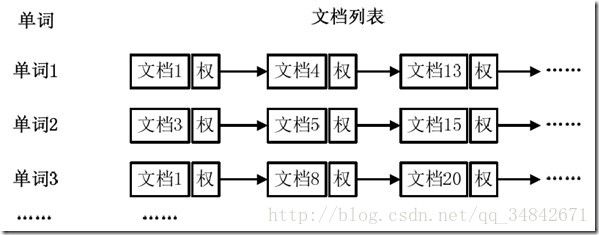
“倒排索引”是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(Inverted Index)。
6.1 实例描述
使用词频作为权重,即记录单词在文档中出现的次数,如图。
样例输入如下:
file1: MapReduce is simple
file2: MapReduce is powerful is simple
file3: Hello MapReduce bye MapReduce
样例输出如下:
| Key | Values |
|---|---|
| MapReduce | file1.txt:1;file2.txt:1;file3.txt:2; |
| simple | file1.txt:1;file2.txt:1; |
| powerful | file2.txt:1; |
| Hello | file3.txt:1; |
| bye | file3.txt:1; |
6.2 设计思路
先对三行数据进行union操作,再通过flatMap方法对每一行数据通过空格进行分隔,之后形成键值对的结构(Key值为单词,Value值为该单词所在文件),对rdd再进行一次map,此时key值为单词+单词所在文件,value值为1,通过reduceByKey进行词频计数,之后再对输出格式进行整理。
6.3 代码实现
object InvertedIndex {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("InvertedIndex").setMaster("local")
val sc = new SparkContext(conf)
//创建rdd
val rdd1 = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/InvertedIndex/file1.txt")
val rdd2 = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/InvertedIndex/file2.txt")
val rdd3 = sc.textFile("E:/IdeaProjects/SparkExamples/src/main/DataSet/InvertedIndex/file3.txt")
//将三个file中的单词存储为K-V对并合并
val kv1_RDD = rdd1.flatMap(_.split(" ")).map((_, "file1.txt"))
val kv2_RDD = rdd2.flatMap(_.split(" ")).map((_, "file2.txt"))
val kv3_RDD = rdd3.flatMap(_.split(" ")).map((_, "file3.txt"))
val union_RDD = kv1_RDD.union(kv2_RDD).union(kv3_RDD).sortByKey()
//统计词频
val rdd = union_RDD.map(f => {
(f._1+":"+f._2, 1)
} ).reduceByKey(_+_)
//调整输出格式
val result_RDD = rdd.map(f => {
(f._1.split(":")(0), f._1.split(":")(1)+":"+f._2)
}).reduceByKey((x, y)=> x + ";" + y)
//打印结果
result_RDD.foreach(println)
}
}