大数据(七):DataNode工作机制
一、DataNode工作机制
-
一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,快数据的校验和,以及时间戳
-
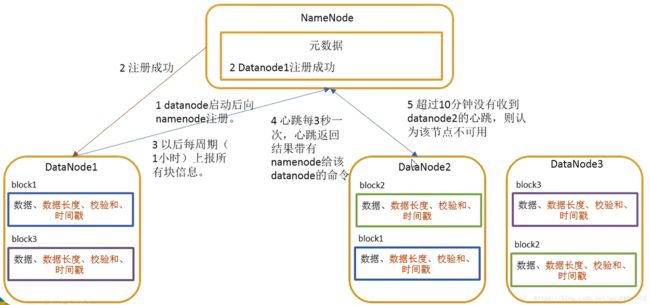
DataNode启动后向namenode注册,通过后,周期性(默认1小时)的向namenode上报所有的块信息
-
心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用了
-
集群运行中可以安全加入和退出一些机器
二、数据完整性
-
当DataNode读取block的时候,会计算checksum
- 如果计算后的checksum,与block创建时值不一样,说明block已经损坏
-
client尝试读取其他DataNode上的block
-
datanode在文件创建后周期校验checksum
三、掉线时限参数设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒,如果定义超市时长为timeout,则超时时长的公式为:
timout=2*dfs.namenode.heartbeat.recheck-interval+10*dfs.heartbeat.interval
而默认的dfs.namenode.heartbeat.recheck-interval为5分钟,dfs.heartbeat.interval为3秒
需要注意hdfs-site.xml配置文件中dfs.namenode.heartbeat.recheck-interval的单位为毫秒,dfs.heartbeat.interval的单位为秒
dfs.namenode.heartbeat.recheck-interval
300000
dfs.hearbeat.interval
3
四、DataNode目录结构
和namenode不同的是,datanode的存储目录是初始阶段自动创建的,不需要额外格式化。
-
查看版本信息文件(默认在/tmp/hadoop-用户名/dfs/data/current下的VERSION)
-
-
具体解释
-
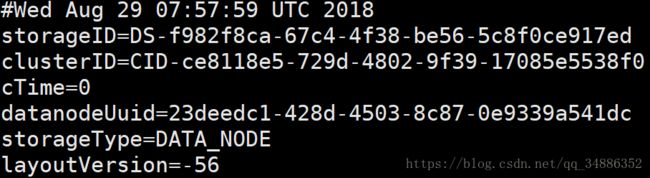
storageID:存储id号
-
clusterID:集群id,全局唯一
-
cTime:标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳
-
datanodeUuid:datanode的唯一识别码
- storageType:存储类型
- layoutVersion:是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
-
-
-
查看该数据块的版本信息(默认在/tmp/hadoop-gyx/dfs/data/current/BP-51058998-127.0.0.1-1535528973429/current下的VERSION)
-
-
具体解释
-
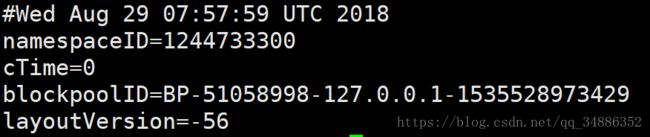
namespaceID:是datanode市场访问namenode的时候从namenode处获取的storageID对每个datanode来说是唯一的(但对于单个datanode中所有存储目录来说则是相同的),namenode可以使用这个属性来区分不同datanode
-
cTime属性标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,一个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳
-
blockpoolID:一个block pool id标识一个block pool,并且是跨集群的全局唯一,当一个新的Namespace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的BlockPoolID比认为的配置更可靠一些。NN将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。
-
layoutVersion:是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
-
-
五、Datanode多目录配置
datanode也可以配置成多个目录,每个目录存储的数据不一样。并非数据的副本。
hdfs-site.xml中配置
dfs.datanode.data.dir
file://{自己设定的文件路径}/dfs/data1,file://{自己设定的文件路径}/dfs/data2
六、服役新数据节点
1.准备一台服务器(或者虚拟机)
2.修改ip地址和主机名称
3.加主机加入ssh的管理中,并配置好hadoop服务(https://blog.csdn.net/qq_34886352/article/details/82017056)
4.在namenode节点主机上hadoop/etc/hadoop目录下创建dfs.hosts文件,将所有datanode节点ip或者主机名写入(用主机名需要配置hosts文件),每行一个ip无需分隔符
5.在namenode的hdfs-site.xml配置文件中增加dfs.hosts属性
dfs.hosts
{hadoop文件夹的位置}/etc/hadoop/dfs.hosts
6.刷新namenode,执行命令 hdfs dfsadmin -refreshNodes
7.更新resourcemanager节点,执行命令 yarn rmadmin -refreshNodes
8.修改namenode的slaves文件,将新的主机加入其中
9.启动新的主机上的数据节点和阶段管理器,hadoop-daemon.sh start datanode和yarn-daemon.sh start nodemanager
10.如果数据不均衡,可以使用命令实现集群的再平衡,start-balancer.sh
七、退役旧数据节点
1.在namenode节点主机上hadoop/etc/hadoop目录下创建dfs.hosts.exclude文件,将所有需要退役的datanode节点ip或者主机名写入(用主机名需要配置hosts文件),每行一个ip无需分隔符
2.在namenode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
dfs.hosts.exclude
{hadoop文件夹的位置}/etc/hadoop/dfs.hosts.exclude
3.属性namenode和resourcemanager,hdfs dfsadmin -refreshNodes和yarn rmadmin -refreshNodes
4.查看web端的节点状态,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点当中。

5.等待退役节点状态变成decommissioned(所有块已经复制完毕),停止该节点和节点资源管理器。注意:如果副本数位3,退役后服役的节点数小于3,是不能退役成功的需要修改副本数才能退役。
-
关闭该数据节点stopping datanode
-
关闭节点管理器stopping nodemanager
6.从include文件中删除退役节点,再次刷新节点
-
从namenode的dfs.hosts文件中删除退役节点
-
刷新namenode,刷新resourcemanager,hdfs dfsadmin -refreshNodes和yarn rmadmin -refreshNodes
-
从namenode的slave文件中删除掉退役节点
7.如果数据不均衡,可以使用命令实现集群的再平衡,start-balancer.sh