知乎内容爬取
1.子话题网页爬取
第一篇爬虫博客,爬取“心理学”话题的所有层次的子话题网址、以及名称
地址:https://blog.csdn.net/qq_35159009/article/details/90516414
2.话题页面动态加载,模拟下滚
知乎界面采用动态加载技术,只有浏览器下滚,才能刷新出数据
第二篇爬虫博客,利用Selenium与PhantomJS模拟浏览器下滚
地址:https://blog.csdn.net/qq_35159009/article/details/90522384
3.进入内容页面爬虫
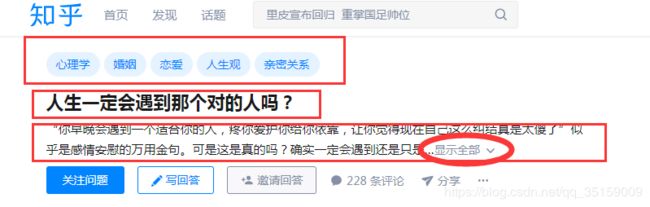
页面展示:
3.1 topic爬虫
采用chrome复制xpath路径的方式,得到topic的表达
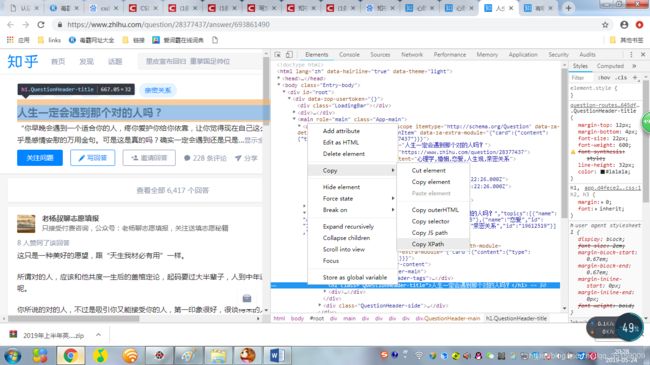
结果://*[@id=“root”]/div/main/div/div[1]/div[2]/div[1]/div[1]/h1
topic=driver.find_element_by_xpath('//*[@id="root"]/div/main/div/div[1]/div[2]/div[1]/div[1]/h1').text
3.2 内容爬虫
第一个图中可以看到,有“显示全部”按钮,同样是动态加载,只有点击了这个按钮,才能爬取全部。
- 获取按钮xpath(在按钮上右键检查,在前端元素上右键复制xpath路径)
//*[@id=“root”]/div/main/div/div[1]/div[2]/div[1]/div[1]/div[2]/div/div/div/button - 模拟click点击操作
more=driver.find_element_by_xpath('//*[@id="root"]/div/main/div/div[1]/div[2]/div[1]/div[1]/div[2]/div/div/div/button').click()
- 爬取内容
xpath://*[@id=“root”]/div/main/div/div[1]/div[2]/div[1]/div[1]/div[2]/div/div/div/span/text()
content=driver.find_element_by_xpath('//*[@id="root"]/div/main/div/div[1]/div[2]/div[1]/div[1]/div[2]/div/div/div/span').text
注意这里是末尾加.text,前面的xpath是/text(),除了这一点不同,其他没有任何区别
3.3 标签爬虫
第一个标签直接复制://[@id=“Popover5-toggle”]
这个结果不方便将所有标签爬虫
所以自己构造xpath路径

先抓大’//[@class=“Tag QuestionTopic”]’(循环)
后抓小’span/a/div/div’
labels=driver.find_elements_by_xpath('//*[@class="Tag QuestionTopic"]')
label_x=[]
for label in labels:
try:
label_x.append(label.find_element_by_xpath('span/a/div/div').text)
except IndexError:
pass
另一种方法:
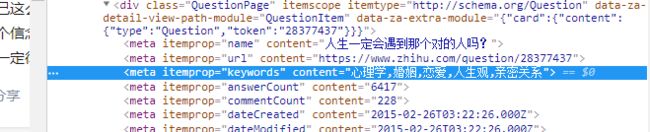
直接一起搞
复制得到的xpath是: //*[@id=“root”]/div/main/div/meta[3]
f_label=driver.find_element_by_xpath('//*[@id="root"]/div/main/div/meta[3]').get_attribute('content')
拿个属性.get_attribute(‘content’)就得到了,是不是更快
总结一下
代码为:
#获取子页面内容
def get_question_info(url):
driver = webdriver.PhantomJS()
#driver.keep_alive = False
driver.get(url)
driver.implicitly_wait(1)
try:
topic=driver.find_element_by_xpath('//*[@id="root"]/div/main/div/div[1]/div[2]/div[1]/div[1]/h1').text
#print("题目是",topic)
try:
more=driver.find_element_by_xpath('//*[@id="root"]/div/main/div/div[1]/div[2]/div[1]/div[1]/div[2]/div/div/div/button').click()
#content=driver.find_element_by_xpath('//*[@class="RichText ztext"]').text
#//*[@id="root"]/div/main/div/div[1]/div[2]/div[1]/div[1]/div[2]/div/div/div/span
content=driver.find_element_by_xpath('//*[@id="root"]/div/main/div/div[1]/div[2]/div[1]/div[1]/div[2]/div/div/div/span').text
except:
try:
content=driver.find_element_by_xpath('//*[@class="RichText ztext"]').text
except:
content='无'
#print("内容是",content)
f_label=driver.find_element_by_xpath('//*[@id="root"]/div/main/div/meta[3]').get_attribute('content')
#print(f_label)
labels=driver.find_elements_by_xpath('//*[@class="Tag QuestionTopic"]')
label_x=[]
for label in labels:
try:
label_x.append(label.find_element_by_xpath('span/a/div/div').text)
except IndexError:
pass
#print(label_x)
driver.close()
cont.insert_one({'topic':topic,'content':content,'labels':f_label}) #mongodb数据插入
except :
pass
driver.quit()
未完待续