spark点点滴滴 —— spark streaming+kafka流式计算实战
概述
本篇不会讲spark streaming原理,会直接进入实战,因此建立在你对spark有了基本的了解基础之上。
不同于storm等流式计算框架的设计,spark streaming的流式计算框架本质上还是spark的批处理框架,只是将流式数据按时间维度切分为细粒度的批处理框架,因此了解spark的话spark streaming应该也不难理解。
我们以一张图来直观的看看spark streaming的基本原理:
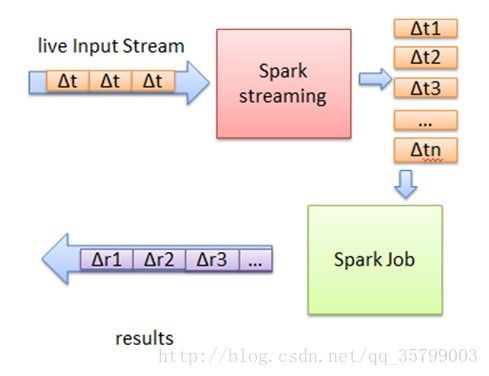
下面我们直接进入spark streaming+kafka实战。
实战
环境
| 环境 | 说明 |
|---|---|
| hadoop | 版本2.6 |
| spark | 版本2.0.2 |
| spark模式 | spark on yarn |
| kafka | 版本0.8.2 |
场景描述
在实际生产环境中,我们采用spark streaming进行流式计算,数据源一般接kafka,输出方式有很多,有直接存储数据的,有发送给kafka消息队列供下游继续处理的,简单的视图如下:

当然也可以继续发送给kafka到下游,本篇我们讲的是直接发送到kafka消息队列的情况。
本篇我们要采用的场景是:
假如我们kafka发送过来的是web请求日志,其中包含了请求的url,假如我们用流式计算来解析日志,提取出其中的url并发送出去。
包含url的日志格式形如:
[29/Mar/2017:11:00:14 +0800] "POST xxxxx?aaa=111&bbb=222&ccc=333 HTTP/1.1" nYyU1pZQVFBQUFBJCQAAAAAAAAAAAEAAAANZUtcsrvKx8K~tv我们要做的是从杂乱的日志文本中提取出“GET/POST xxxx HTTP/1.1”这段数据,并发送给下游处理。
好,下面直接开始我们的实战。
java版
先直接上代码:
maven依赖
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.10artifactId>
<version>2.0.2version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.10artifactId>
<version>2.0.2version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka_2.10artifactId>
<version>1.5.1version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka_2.10artifactId>
<version>0.8.2.1version>
dependency>
dependencies>kafkaProducer的封装
public class KafkaProducerWrapper {
private static KafkaProducerWrapper kafkaProducerWrapper = null;
private static boolean inited = false;
private KafkaProducerWrapper() { }
public static KafkaProducerWrapper getInstance() {
if (kafkaProducerWrapper == null) {
synchronized (KafkaProducerWrapper.class) {
if (kafkaProducerWrapper == null) {
kafkaProducerWrapper = new KafkaProducerWrapper();
}
}
}
return kafkaProducerWrapper;
}
public boolean isInited() { return inited; }
public static void init(String kafkaPros) {
// todo
inited = true;
}
public static void send(String message) {
// todo
}
}
以上,是对kafka producer的封装,不详细写,参考kafka进击之路(五) ——producer API开发。
spark的运行代码
下面是要提交的spark的运行代码:
import kafka.serializer.StringDecoder;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
import scala.Tuple2;
import template.KafkaProducerWrapper;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class SparkMain {
/**
* 匹配日志中的url
*/
private static final String filterReg = "(.*)([GET|POST].*\\?)(.*)(HTTP/1\\.1)(.*)";
private static final String LOG_IGNORE = "IGNORE";
public static String parseLog(String log) {
if (log == null) {
return null;
}
Pattern pattern = Pattern.compile(filterReg);
Matcher matcher = pattern.matcher(log);
if (matcher.find()) {
return matcher.group(3);
} else {
return null;
}
}
public static void main(String[] args) {
/**
* spark提交的appName
*/
String appName = "JavaSparkStreamingTest";
/**
* spark streaming处理的时间片,即1s为一个时间单元
*/
int sparkStreamingInterval = 1000;
/**
* 读取的kafka topic集合,支持多个
*/
Set topicsSet = new HashSet();
topicsSet.add("testTopic");
/**
* kafka的broker配置
*/
String brokers = "x.x.x.1:9092,x.x.x.2:9092";
Map kafkaParams = new HashMap();
kafkaParams.put("metadata.broker.list", brokers);
SparkConf sparkConf = new SparkConf().setAppName(appName);
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, Durations.milliseconds(sparkStreamingInterval));
/**
* 构造从kafka读取的数据源
*/
JavaPairInputDStream logMessages = KafkaUtils.createDirectStream(
jssc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
kafkaParams,
topicsSet
);
/**
* 执行map操作,解析日志
*/
final JavaDStream parsedurls = logMessages.map(new Function, String>() {
public String call(Tuple2 stringStringTuple2) throws Exception {
String log = stringStringTuple2._2();
String url = parseLog(log);
if (url == null) {
return LOG_IGNORE;
} else {
return url;
}
}
});
/**
* 过滤操作,过滤非URL
*/
final JavaDStream urls = parsedurls.filter(new Function() {
public Boolean call(String s) throws Exception {
return s == null || s.equals(LOG_IGNORE);
}
});
/**
* 遍历每个url,并发送到kafka
*/
urls.foreachRDD(new VoidFunction>() {
public void call(JavaRDD stringJavaRDD) throws Exception {
// 这个判断非常重要
if (!KafkaProducerWrapper.getInstance().isInited()) {
// 从resource文件初始化
KafkaProducerWrapper.getInstance().init("/producer.properties");
}
for (String url : stringJavaRDD.collect()) {
KafkaProducerWrapper.getInstance().send(url);
}
}
});
/**
* 启动spark streaming
*/
jssc.start();
try {
jssc.awaitTermination();
} catch (Exception e) {
e.printStackTrace();
}
}
} 代码关键节点说明
由于spark提交后是在分布式环境中运行,main函数中代码在driver中执行,转换和action的代码分发到各个节点执行,因此我们要考虑到同一份代码在不同节点中运行注意事项:
1. 初始化
不能只在main函数里初始化,每个转换和action里用到需要初始化的对象,都要初始化,当然可以用单例模式;
2. 配置文件
要读取配置文件,如果配置的是本地路径,则每个spark节点都需要在相同路径中有同一份配置文件;当然这是很不靠谱的事情,因此,我们可以采用HDFS上的文件或者工程中的资源文件(java中的resources目录),我们在上述示例中初始化kafka的producer使用的就是资源文件路径。
spark作业提交命令
spark-submit --class SparkMain --master yarn-cluster --jars lib/spark-streaming-kafka_2.10-1.3.0.jar,lib/kafka-clients-0.8.2.1.jar,lib/scala-library-2.10.4.jar,lib/kafka_2.10-0.8.2.1.jar,lib/spark-streaming_2.10-2.0.2.jar ./spark-test.jar
配置调优
如果按照上面的spark提交命令提交任务后,我们会发现,这些spark streaming任务跑不了多久就有可能会挂掉了,会出现各种 java.lang.OutOfMemoryError等堆错误或者GC问题,这在实际生产环境中没法保证spark streaming任务的7 * 24小时运行的。
实际工程中,要保证稳定性,我们还需要对很多参数进行调优处理,下面介绍下我在实际工程中处理这些配置中一些关键的配置。
关于spark提交任务有哪些配置,可以看这里。下面介绍对spark streaming任务有很大影响的配置的一些优化建议:
| spark任务参数 | 说明 | 默认值 | 优化建议 |
|---|---|---|---|
| spark.executor.memory | executor内存大小 | 1G | 看实际情况尽可能大,比如8G |
| spark.driver.memory | driver内存大小 | 1G | 尽可能大,比如4G |
| spark.executor.extraJavaOptions | java参数 | 无 | 合适的GC算法,也可以打印gc日志来辅助定位问题 |
| spark.storage.memoryFraction | spark任务缓存所占内存比例 | 0.6 | 如果实际任务不太需要使用缓存,尽可能小,比如0.1 |
| spark.cleaner.ttl | spark缓存数据的周期 | 默认infinite | 尽可能小,比如600秒 |
特别最后两个参数,非常影响spark streaming任务的内存占用,要保证任务的稳定性,我们需要针对参数进行详细的优化配置。
调优后我们的提交命令如下:
spark-submit --class SparkMain --master yarn-cluster --executor-memory 8G --driver-cores 2 --driver-memory 4G --conf spark.storage.memoryFraction=0.1 --conf spark.cleaner.ttl=3600 --jars lib/spark-streaming-kafka_2.10-1.3.0.jar,lib/kafka-clients-0.8.2.1.jar,lib/scala-library-2.10.4.jar,lib/kafka_2.10-0.8.2.1.jar,lib/spark-streaming_2.10-2.0.2.jar ./spark-test.jar
结语
以上,就是一个典型的spark streaming+kafka的流式计算实战,从代码的编写到任务调优,就可以开始我们的spark流式计算之路了。