CUDA学习笔记(九)内存
Memory
kernel性能高低是不能单纯的从warp的执行上来解释的。比如之前博文涉及到的,将block的维度设置为warp大小的一半会导致load efficiency降低,这个问题无法用warp的调度或者并行性来解释。根本原因是获取global memory的方式很差劲。
众所周知,memory的操作在讲求效率的语言中占有极重的地位。low-latency(低延迟)和high-bandwidth(高带宽)是高性能的理想情况。但是购买拥有大容量,高性能的memory是不现实的,或者不经济的。因此,我们就要尽量依靠软件层面来获取最优latency和bandwidth。CUDA将memory model unit分为device和host两个系统,充分暴露了其内存结构以供我们操作,给予用户充足的使用灵活性。
Benefits of a Memory Hierarchy(内存层次结构的好处)
一般来说,程序获取资源是有规律的,也就是计算机体系结构经常提到的局部原则。其又分为时间局部性和空间局部性。 相信大家对计算机内存方面的知识都很熟悉了,这里就不多说了,只简单提下。

GPU和CPU的主存都是用DRAM实现,cache则是用lower-latency的SRAM来实现。GPU和CPU的存储结构基本一样。而且CUDA将memory结构更好的呈现给用户,从而能更灵活的控制程序行为。
CUDA Memory Model
对于程序员来说,memory可以分为下面两类:
- Programmable:我们可以灵活操作的部分。
- Non-programmable:不能操作,由一套自动机制来达到很好的性能。
在CPU的存储结构中,L1和L2 cache都是non-programmable的。
对于CUDA来说,programmable的类型很丰富:
- Registers
- Shared memory
- Local memory
- Constant memory
- Texture memory
- Global memory
下图展示了memory的结构,他们各自都有不用的空间、生命期和cache。
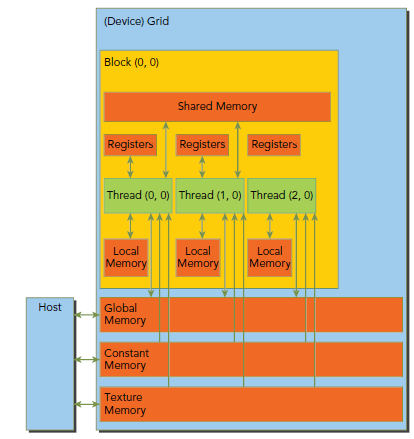
其中constant和texture是只读的。最下面这三个global、constant和texture拥有相同的生命周期。
Registers
寄存器是GPU最快的memory,kernel中没有什么特殊声明的自动变量都是放在寄存器中的。当数组的索引是constant类型且在编译期能被确定的话,就是内置类型,数组也是放在寄存器中。
寄存器变量是每个线程私有的,一旦thread执行结束,寄存器变量就会失效。寄存器是稀有资源。在Fermi上,每个thread限制最多拥有63个register,Kepler则是255个。让自己的kernel使用较少的register就能够允许更多的block驻留在SM中,也就增加了Occupancy,提升了性能。
使用nvcc的-Xptxas -v,-abi=no(这里Xptxas表示这个是要传给ptx的参数,不是nvcc的,v是verbose,abi忘了,好像是application by interface)选项可以查看每个thread使用的寄存器数量,shared memory和constant memory的大小。如果kernel使用的register超过硬件限制,这部分会使用local memory来代替register,即所谓的register spilling(寄存溢出),我们应该尽量避免这种情况。编译器有相应策略来最小化register的使用并且避免register spilling。我们也可以在代码中显式的加上额外的信息来帮助编译器做优化:
-
__global__ void -
__launch_bounds__(maxThreadsPerBlock, minBlocksPerMultiprocessor) -
kernel(...) { -
// your kernel body -
}
maxThreadsPerBlock指明每个block可以包含的最大thread数目。minBlocksPerMultiprocessor是可选的参数,指明必要的最少的block数目。
我们也可以使用-maxrregcount=32来指定kernel使用的register最大数目。如果使用了__launch_bounds__,则这里指定的32将失效。
Local Memory
有时候,如果register不够用了,那么就会使用local memory来代替这部分寄存器空间。
除此外,下面几种情况,编译器可能会把变量放置在local memory:
- 编译期无法决定确切值的本地数组。
- 较大的结构体或者数组,也就是那些可能会消耗大量register的变量。
- 任何超过寄存器限制的变量。
local memory这个名字是有歧义的:在local memory中的变量本质上跟global memory在同一块存储区。所以,local memory有很高的latency和较低的bandwidth。在CC2.0以上,GPU针对local memory会有L1(per-SM)和L2(per-device)两级cache。
Shared Memory
用__shared__修饰符修饰的变量存放在shared memory。因为shared memory是on-chip的,他相比localMemory和global memory来说,拥有高的多bandwidth和低很多的latency。他的使用和CPU的L1cache非常类似,但是他是programmable的。
按惯例,像这类性能这么好的memory都是有限制的,shared memory是以block为单位分配的。我们必须非常小心的使用shared memory,否则会无意识的限制了active warp的数目。
不同于register,shared memory尽管在kernel里声明的,但是他的生命周期是伴随整个block,而不是单个thread。当该block执行完毕,他所拥有的资源就会被释放,重新分配给别的block。
shared memory是thread交流的基本方式。同一个block中的thread通过shared memory中的数据来相互合作。获取shared memory的数据前必须先用__syncthreads()同步。
L1 cache和shared memory使用相同的64KB on-chip memory,我们也可以使用下面的API来动态配置二者:
cudaError_t cudaFuncSetCacheConfig(const void* func, enum cudaFuncCachecacheConfig);
func是分配策略,可以使用下面几种:
cudaFuncCachePreferNone: no preference (default)
cudaFuncCachePreferShared: prefer 48KB shared memory and 16KB L1 cache
cudaFuncCachePreferL1: prefer 48KB L1 cache and 16KB shared memory
cudaFuncCachePreferEqual: Prefer equal size of L1 cache and shared memory, both 32KB
Fermi仅支持前三种配置,Kepler支持全部,注意,在Maxwell之后,L1被舍弃了,所以这64KB就完全属于shared Memory了,也就没有了上面这个分配一说。
Constant Memory
Constant Memory驻留在device Memory,并且使用专用的constant cache(per-SM)。该Memory的声明应该以__connstant__修饰。constant的范围是全局的,针对所有kernel,对于所有CC其大小都是64KB。在同一个编译单元,constant对所有kernel可见。
kernel只能从constant Memory读取数据,因此其初始化必须在host端使用下面的function调用:
cudaError_t cudaMemcpyToSymbol(const void* symbol, const void* src,size_t count);
这个function拷贝src指向的count个byte到symbol的地址,symbol指向的是在device中的global或者constant Memory。
当一个warp中所有thread都从同一个Memory地址读取数据时,constant Memory表现最好。例如,计算公式中的系数。如果所有的thread从不同的地址读取数据,并且只读一次,那么constant Memory就不是很好的选择,因为一次读constant Memory操作会广播给所有thread知道。
Texture Memory
texture Memory驻留在device Memory中,并且使用一个只读cache(per-SM)。texture Memory实际上也是global Memory在一块,但是他有自己专有的只读cache。这个cache在浮点运算很有用(具体还没弄懂)。texture Memory是针对2D空间局部性的优化策略,所以thread要获取2D数据就可以使用texture Memory来达到很高的性能,D3D编程中有两种重要的基本存储空间,其中一个就是texture。
Global Memory
global Memory是空间最大,latency最高,GPU最基础的memory。“global”指明了其生命周期。任意SM都可以在整个程序的生命期中获取其状态。global中的变量既可以是静态也可以是动态声明。可以使用__device__修饰符来限定其属性。global memory的分配就是之前频繁使用的cudaMalloc,释放使用cudaFree。global memory驻留在devicememory,可以通过32-byte、64-byte或者128-byte三种格式传输。这些memory transaction必须是对齐的,也就是说首地址必须是32、64或者128的倍数。优化memory transaction对于性能提升至关重要。当warp执行memory load/store时,需要的transaction数量依赖于下面两个因素:
- Distribution of memory address across the thread of that warp 就是前文的连续
- Alignment of memory address per transaction 对齐
一般来说,所需求的transaction越多,潜在的不必要数据传输就越多,从而导致throughput efficiency降低。
对于一个既定的warp memory请求,transaction的数量和throughput efficiency是由CC版本决定的。对于CC1.0和1.1来说,对于global memory的获取是非常严格的。而1.1以上,由于cache的存在,获取要轻松的多。
GPU Cache
跟CPU的cache一样,GPU cache也是non-programmable的。在GPU上包含以下几种cache,在前文都已经提到:
- L1
- L2
- Read-only constant
- Read-only texture
每个SM都有一个L1 cache,所有SM共享一个L2 cache。二者都是用来缓存local和global memory的,当然也包括register spilling的那部分。在Fermi GPus 和 Kepler K40或者之后的GPU,CUDA允许我们配置读操作的数据是否使用L1和L2或者只使用L2。
在CPU方面,memory的load/store都可以被cache。但是在GPU上,只有load操作会被cache,store则不会。
每个SM都有一个只读constant cache和texture cache来提升性能。
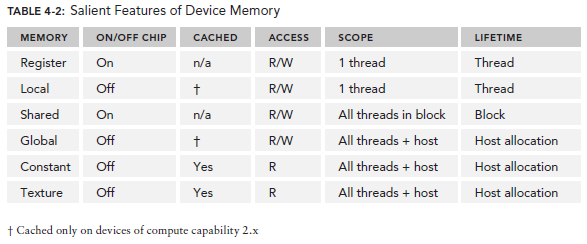
CUDA Variable Declaration Summary(CUDA变量申明摘要)
下表是之前介绍的几种memory的声明总结:


Static Global Memory
下面的代码介绍了怎样静态的声明global variable(之前的博文其实都是global variable)。大致过程就是,先声明了一个float全局变量,在checkGlobal-Variable中,该值被打印出来,随后,其值便被改变。在main中,这个值使用cudaMemcpyToSymbol来初始化。最终当全局变量被改变后,将值拷贝回host。
-
#include -
#include -
__device__ float devData; -
__global__ void checkGlobalVariable() { -
// display the original value -
printf("Device: the value of the global variable is %f\n",devData); -
// alter the value -
devData +=2.0f; -
} -
int main(void) { -
// initialize the global variable -
float value = 3.14f; -
cudaMemcpyToSymbol(devData, &value, sizeof(float)); -
printf("Host: copied %f to the global variable\n", value); -
// invoke the kernel -
checkGlobalVariable <<<1, 1>>>(); -
// copy the global variable back to the host -
cudaMemcpyFromSymbol(&value, devData, sizeof(float)); -
printf("Host: the value changed by the kernel to %f\n", value); -
cudaDeviceReset(); -
return EXIT_SUCCESS; -
}
编译运行:
-
$ nvcc -arch=sm_20 globalVariable.cu -o globalVariable -
$ ./globalVariable
输出:
-
Host: copied 3.140000 to the global variable -
Device: the value of the global variable is 3.140000 -
Host: the value changed by the kernel to 5.140000
熟悉了CUDA的基本思想后,不难明白,尽管host和device的代码是写在同一个源文件,但是他们的执行却在完全不同的两个世界,host不能直接访问device变量,反之亦然。
我们可能会反驳说,用下面的代码就能获得device的全局变量:
cudaMemcpyToSymbol(devData, &value, sizeof(float));
但是,我们应该还注意到下面的几点:
- 该函数是CUDA的runtime API,使用的GPU实现。
- devData在这儿只是个符号,不是device的变量地址。
- 在kernel中,devData被用作变量。
而且,cudaMemcpy不能用&devData这种方式来传递变量,正如上面所说,devData只是个符号,取址这种操作本身就是错误的:
cudaMemcpy(&devData, &value, sizeof(float),cudaMemcpyHostToDevice); // It’s wrong!!!
不管怎样,CUDA还是为我们提供了,利用devData这种符号来获取变量地址的方式:
cudaError_t cudaGetSymbolAddress(void** devPtr, const void* symbol);
获取地址之后,就可以使用cudaMemcpy了:
-
float *dptr = NULL; -
cudaGetSymbolAddress((void**)&dptr, devData); -
cudaMemcpy(dptr, &value, sizeof(float), cudaMemcpyHostToDevice);
我们只有一种方式能够直接获取GPU memory,即使用pinned memory,下文将详细介绍。
Memory Management
CUDA非常接近C的编程风格,以便能够快速上手掌握,在内存管理这点上,CUDA区别于C最明显的操作就是在device和host之间不停的传递数据。很麻烦的一个过程,不过Unified Memory(统一内存寻址)出现后,程序编写就没那么复杂了,但是目前,Unified Memory的使用并未普及,我们还是要关注Memory的显式的操作过程:
- Allocate and deallocate device Memory(分配和释放设备内存)
- Transfer data between the host and device(在主机和设备之间传输数据)
为了达到最好的性能,CUDA提供了五花八门的接口供程序员显式的在device和host之间传递数据。
Memory Allocation and Deallocation
前面的博文已经提到一部分内存分配函数了,在分配global Memory时,最常用的就是下面这个了:
cudaError_t cudaMalloc(void **devPtr, size_t count);
如果分配出错则返回cudaErrorMemoryAllocation。分配成功后,就得对该地址初始化值,要么从host调用cudaMemcpy赋值,要么调用下面的API初始化:
cudaError_t cudaMemset(void *devPtr, int value, size_t count);
释放资源就是:
cudaError_t cudaFree(void *devPtr);
device资源分配是个非常昂贵的操作,所以,device Memory应该尽可能的重用,而不是重新分配。
Memory Transfer
一旦global Memory分配好后,如果不用cudaMemset就得用下面这个:
cudaError_t cudaMemcpy(void *dst, const void *src, size_t count,enum cudaMemcpyKind kind);
这个大家应该也很熟悉了,kind就是下面这几种:
cudaMemcpyHostToHost
cudaMemcpyHostToDevice
cudaMemcpyDeviceToHost
cudaMemcpyDeviceToDevice
下图是CPU和GPU之间传输关系图,可以看出来,CPU和GPU之间传输速度相对很差(NVLink技术能提高5~10倍),GPU和on-board Memory传输速度要快得多,所以对于编程来说,要时刻考虑减少CPU和GPU之间的数据传输。

Pinned Memory
Host Memory的分配默认情况下是pageable的,也就是说,我们要承受因pagefault导致的操作,,这个操作要将host virtual Memory的数据转移到由OS决定的不物理位置。GPU无法安全的获取host的pageable Memory,因为GPU没有办法控制host OS物理上转移数据的时机。因此,当将pageable host Memory数据送到device时,CUDA驱动会首先分配一个临时的page-locked或者pinned host Memory,并将host的数据放到这个临时空间里。然后GPU从这个所谓的pinned Memory中获取数据,如下左图所示:
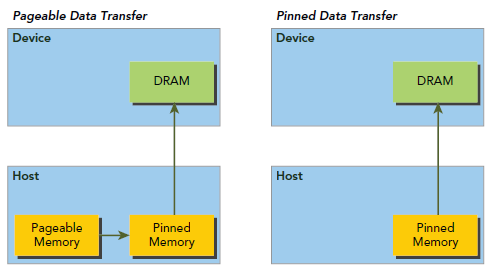
左图是默认的过程,我们也可以显式的直接使用pinned Memory,如下:
cudaError_t cudaMallocHost(void **devPtr, size_t count);
由于pinned Memory能够被device直接访问(不是指不通过PCIE了,而是相对左图我们少了pageable Memory到pinned Memory这一步),所以他比pageable Memory具有相当高的读写带宽,当然像这种东西依然不能过度使用,因为这会降低pageable Memory的数量,影响整个虚拟存储性能,我们不能因小失大。
-
cudaError_t status = cudaMallocHost((void**)&h_aPinned, bytes); -
if (status != cudaSuccess) { -
fprintf(stderr, "Error returned from pinned host memory allocation\n"); -
exit(1); -
}
Pinned Memory的释放也比较特殊:
cudaError_t cudaFreeHost(void *ptr);
Pinned Memory比pageable Memory的分配操作更加昂贵,但是他对大数据的传输有很好的表现。还有就是,pinned Memory效果的高低也是跟CC有关的。
将许多小的传输合并到一次大的数据传输,并使用pinned Memory将降低很大的传输消耗。这里提及下,数据传输的消耗有时候是可以被kernel的执行覆盖的。
Zero-Copy Memory
一般来说,host和device是不能直接访问对方的数据的,前文也有提到,但是Zero-Copy Memory是个特例。
该Memory是位于host的,但是GPU thread可以直接访问,其优点有:
- 当device Memory不够用时,能够利用host Memory。
- 避免device和host之间显式的数据传输。
- 提高PCIe传输效率。
当使用zero-copy来共享host和device数据时,我们必须同步Memory的获取,否则,device和host同时访问该Memory会导致未定义行为。
Zero-copy本身实质就是pinned memory并且被映射到了device的地址空间。下面是他的分配API:
cudaError_t cudaHostAlloc(void **pHost, size_t count, unsigned int flags);
其资源释放当然也是cudaFreeHost,至于flag则是下面几个选项:
- cudaHostAllocDefault
- cudaHostAllocPortable
- cudaHostAllocWriteCombined
- cudaHostAllocMapped
当使用cudaHostAllocDefault时,cudaHostAlloc和cudaMallocHost等价。cudaHostAllocPortable则说明,分配的pinned memory对所有CUDA context都有效,而不是单单执行分配此操作的那个context或者说线程。cudaHostAllocWriteCombined是在特殊系统配置情况下使用的,这块pinned memory在PCIE上的传输更快,但是对于host自己来说,却没什么效率。所以该选项一般用来让host去写,然后device读。最常用的是cudaHostAllocMapped,就是返回一个标准的zero-copy。可以用下面的API来获取device端的地址:
cudaError_t cudaHostGetDevicePointer(void **pDevice, void *pHost, unsigned int flags);
flags是保留参数,留待将来使用,目前必须设置为零。
使用zero-copy memory来作为device memory的读写很频繁的那部分的补充是很不明智的,pinned这一类适合大数据传输,不适合频繁的操作,究其根本原因还是GPU和CPU之间低的可怜的传输速度,甚至,频繁读写情况下,zero-copy表现比global memory也要差不少。
下面一段代码是比较频繁读写情况下,zero-copy的表现:
-
int main(int argc, char **argv) { -
// part 0: set up device and array -
// set up device -
int dev = 0; -
cudaSetDevice(dev); -
// get device properties -
cudaDeviceProp deviceProp; -
cudaGetDeviceProperties(&deviceProp, dev); -
// check if support mapped memory -
if (!deviceProp.canMapHostMemory) { -
printf("Device %d does not support mapping CPU host memory!\n", dev); -
cudaDeviceReset(); -
exit(EXIT_SUCCESS); -
} -
printf("Using Device %d: %s ", dev, deviceProp.name); -
// set up date size of vectors -
int ipower = 10; -
if (argc>1) ipower = atoi(argv[1]); -
int nElem = 1< -
size_t nBytes = nElem * sizeof(float); -
if (ipower < 18) { -
printf("Vector size %d power %d nbytes %3.0f KB\n", nElem,\ -
ipower,(float)nBytes/(1024.0f)); -
} else { -
printf("Vector size %d power %d nbytes %3.0f MB\n", nElem,\ -
ipower,(float)nBytes/(1024.0f*1024.0f)); -
} -
// part 1: using device memory -
// malloc host memory -
float *h_A, *h_B, *hostRef, *gpuRef; -
h_A = (float *)malloc(nBytes); -
h_B = (float *)malloc(nBytes); -
hostRef = (float *)malloc(nBytes); -
gpuRef = (float *)malloc(nBytes); -
// initialize data at host side -
initialData(h_A, nElem); -
initialData(h_B, nElem); -
memset(hostRef, 0, nBytes); -
memset(gpuRef, 0, nBytes); -
// add vector at host side for result checks -
sumArraysOnHost(h_A, h_B, hostRef, nElem); -
// malloc device global memory -
float *d_A, *d_B, *d_C; -
cudaMalloc((float**)&d_A, nBytes); -
cudaMalloc((float**)&d_B, nBytes); -
cudaMalloc((float**)&d_C, nBytes); -
// transfer data from host to device -
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice); -
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice); -
// set up execution configuration -
int iLen = 512; -
dim3 block (iLen); -
dim3 grid ((nElem+block.x-1)/block.x); -
// invoke kernel at host side -
sumArrays << -
// copy kernel result back to host side -
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost); -
// check device results -
checkResult(hostRef, gpuRef, nElem); -
// free device global memory -
cudaFree(d_A); -
cudaFree(d_B); -
free(h_A); -
free(h_B); -
// part 2: using zerocopy memory for array A and B -
// allocate zerocpy memory -
unsigned int flags = cudaHostAllocMapped; -
cudaHostAlloc((void **)&h_A, nBytes, flags); -
cudaHostAlloc((void **)&h_B, nBytes, flags); -
// initialize data at host side -
initialData(h_A, nElem); -
initialData(h_B, nElem); -
memset(hostRef, 0, nBytes); -
memset(gpuRef, 0, nBytes); -
// pass the pointer to device -
cudaHostGetDevicePointer((void **)&d_A, (void *)h_A, 0); -
cudaHostGetDevicePointer((void **)&d_B, (void *)h_B, 0); -
// add at host side for result checks -
sumArraysOnHost(h_A, h_B, hostRef, nElem); -
// execute kernel with zero copy memory -
sumArraysZeroCopy << -
// copy kernel result back to host side -
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost); -
// check device results -
checkResult(hostRef, gpuRef, nElem); -
// free memory -
cudaFree(d_C); -
cudaFreeHost(h_A); -
cudaFreeHost(h_B); -
free(hostRef); -
free(gpuRef); -
// reset device -
cudaDeviceReset(); -
return EXIT_SUCCESS; -
}
编译运行:
-
$ nvcc -O3 -arch=sm_20 sumArrayZerocpy.cu -o sumZerocpy -
$ nvprof ./sumZerocpy -
Using Device 0: Tesla M2090 Vector size 1024 power 10 nbytes 4 KB -
Time(%) Time Calls Avg Min Max Name -
27.18% 3.7760us 1 3.7760us 3.7760us 3.7760us sumArraysZeroCopy -
11.80% 1.6390us 1 1.6390us 1.6390us 1.6390us sumArrays -
25.56% 3.5520us 3 1.1840us 1.0240us 1.5040us [CUDA memcpy HtoD] -
35.47% 4.9280us 2 2.4640us 2.4640us 2.4640us [CUDA memcpy DtoH]
下表是尝试不同数组长度后的结果:
./sumZerocopy

因此,对于共享host和device之间的一小块内存空间,zero-copy是很好的选择,因为他简化的编程而且提供了合理的性能。
Unified Virtual Addressing
在CC2.0以上的设备支持一种新特性:Unified Virtual Addressing(UVA)。这个特性在CUDA4.0中首次介绍,并被64位Linux系统支持。如下图所示,在使用UVA的情况下,CPU和GPU使用同一块连续的地址空间:

在UVA之前,我们需要分别管理指向host memory和device memory的指针。使用UVA之后,实际指向内存空间的指针对我们来说是透明的,我们看到的是同一块连续地址空间。
这样,使用cudaHostAlloc分配的pinned memory获得的地址对于device和host来说是通用的。我们可以直接在kernel里使用这个地址。回看前文,我们对于zero-copy的处理过程是:
- 分配已经映射到device的pinned memory。
- 根据获得的host地址,获取device的映射地址。
- 在kernel中使用该映射地址。
使用UVA之后,就没必要来获取device的映射地址了,直接使用一个地址就可以,如下代码所示:
-
// allocate zero-copy memory at the host side -
cudaHostAlloc((void **)&h_A, nBytes, cudaHostAllocMapped); -
cudaHostAlloc((void **)&h_B, nBytes, cudaHostAllocMapped); -
// initialize data at the host side -
initialData(h_A, nElem); -
initialData(h_B, nElem); -
// invoke the kernel with zero-copy memory -
sumArraysZeroCopy<<
可以看到,cudaHostAlloc返回的指针直接就使用在了kernel里面,编译指令;
$ nvcc -O3 -arch=sm_20 sumArrayZerocpyUVA.cu -o sumArrayZerocpyUVA
修改后的代码执行效率和之前的效率是相差无几的,大家可以自己动手试试。
Unified Memory
nvidia从cuda 6开始支持unified memory(统一内存寻址),目前更新至cuda 8,进一步加强了该特性。
CUDA 6 introduced Unified Memory, which creates a pool of managed memory that is shared between the CPU and GPU, bridging the CPU-GPU divide. Managed memory is accessible to both the CPU and GPU using a single pointer. The CUDA system software automatically migrates data allocated in Unified Memory between GPU and CPU, so that it looks like CPU memory to code running on the CPU, and like GPU memory to code running on the GPU.
实质上,就是将用户从CPU-GPU间的内存拷贝操作中解放出来,交给CUDA实现。
用法:cudaMalloc用cudaMallocManaged替换
CUDA 6 Unified Memory was limited by the features of the Kepler and Maxwell GPU architectures: all managed memory touched by the CPU had to be synchronized with the GPU before any kernel launch; the CPU and GPU could not simultaneously access a managed memory allocation; and the Unified Memory address space was limited to the size of the GPU physical memory.
PASCAL GP100 UNIFIED MEMORY:Two main hardware features enable these improvements: support for large address spaces and page faulting capability.
在CPU访问Unified Memory之前需要加上
cudaDeviceSynchronize();- 1
进行同步,防止CPU和GPU同时对Unified Memory进行访问
对于compute capabiliy 6.x 以上的设备,可以通过stream支持CPU/GPU对Unified Memory的异步访问,即CPU不需要等待GPU kernel处理完成后才能访问Unified Memory
而对于compute capabiliy 5.x 及以下的设备,则不支持CPU/GPU对Unified Memory的异步访问,当kernel运行过程中,CPU是无法访问Unified Memory的
Unified memory really shines with C++ data structures. C++ simplifies the deep copy problem by using classes with copy constructors. A copy constructor is a function that knows how to create an object of a class, allocate space for its members, and copy their values from another object. C++ also allows the new and delete memory management operators to be overloaded.
Thanks to Unified Memory, the deep copies, pass by value and pass by reference all just work. This provides tremendous value in running C++ code on the GPU.
通过在拷贝构造函数使用cudaMallocManaged,即可以实现GPU kernel中对象的值传递和引用传递。
总结unified memory的好处:
Simpler programming and memory model
Unified Memory lowers the bar of entry to parallel programming on GPUs, by making explicit device memory management an optimization, rather than a requirement. Unified Memory lets programmers focus on developing parallel code without getting bogged down in the details of allocating and copying device memory. This makes it easier to learn to program GPUs and simpler to port existing code to the GPU. But it’s not just for beginners; Unified Memory also makes complex data structures and C++ classes much easier to use on the GPU. With GP100, applications can operate out-of-core on data sets that are larger than the total memory size of the system. On systems that support Unified Memory with the default system allocator, any hierarchical or nested data structure can automatically be accessed from any processor in the system.
减轻GPU内存管理的繁杂性,方便代码移植GPU。
Performance through data locality
By migrating data on demand between the CPU and GPU, Unified Memory can offer the performance of local data on the GPU, while providing the ease of use of globally shared data. The complexity of this functionality is kept under the covers of the CUDA driver and runtime, ensuring that application code is simpler to write. The point of migration is to achieve full bandwidth from each processor; the 750 GB/s of HBM2 memory bandwidth is vital to feeding the compute throughput of a GP100 GPU. With page faulting on GP100, locality can be ensured even for programs with sparse data access, where the pages accessed by the CPU or GPU cannot be known ahead of time, and where the CPU and GPU access parts of the same array allocations simultaneously.
An important point is that CUDA programmers still have the tools they need to explicitly optimize data management and CPU-GPU concurrency where necessary: CUDA 8 introduces useful APIs for providing the runtime with memory usage hints (cudaMemAdvise()) and for explicit prefetching (cudaMemPrefetchAsync()). These tools allow the same capabilities as explicit memory copy and pinning APIs without reverting to the limitations of explicit GPU memory allocation.
提高性能,通过CUDA的驱动和运行时对全局共享数据进行优化,简化应用程序的编码工作。
In simple terms, Unified Memory eliminates the need for explicit data movement via the cudaMemcpy*() routines without the performance penalty incurred by placing all data into zero-copy memory. Data movement, of course, still takes place, so a program’s run time typically does not decrease; Unified Memory instead enables the writing of simpler and more maintainable code.
注意:数据迁移是不可避免的,unified memory不会降低代码的运行时间
Unified Memory has three basic requirements:
‣ a GPU with SM architecture 3.0 or higher (Kepler class or newer)
‣ a 64-bit host application and operating system, except Android
‣ Linux or Windows
Unified Memory的运行环境要求:Kepler以上的核心、64位Linux或者Windows