简单web服务器的实现(C++)
一、具体功能实现
- GET方法请求解析
- POST方法请求解析
- 返回请求资源页面
- 利用GET方法实现加减法
- 利用POST方法实现加减法
- HTTP请求行具体解析
- 400、403、404错误码返回的处理
注意:!!本人也是小白一只,这是刚刚开始学习网络编程写的东西,存在很多问题。也未用到RAII等机制,纯属是披着C++皮的C语言项目,类的封装也不是太好。也未经过压力、性能等测试。
二、什么是web服务器
- web服务器就是在物理服务器基础上的具有服务端功能的网络连接程序,简而言之就是处理客户端发来的各种请求然后根据服务器的逻辑处理返回一个结果给客户端。在web服务器和客户端之间的通信是基于HTTP协议进行的。而客户端可以是浏览器也可以是支持HTTP协议的APP。
- 那么浏览器应该怎么连接上自己的web服务器呢,最简单的web服务器就是通过TCP三次握手建立连接后,服务器直接返回一个结果给浏览器。浏览器和服务器是通过TCP三路握手建立连接的。浏览器在通过URL(统一资源定位符,就是我们俗称的网络地址)去请求服务器的连接,并且通过URL中的路径请求服务器上的资源。举个栗子就是这样的:
最简单的web服务器:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
const int port = 8888;
int main(int argc,char *argv[])
{
if(argc<0)
{
printf("need two canshu\n");
return 1;
}
int sock;
int connfd;
struct sockaddr_in sever_address;
bzero(&sever_address,sizeof(sever_address));
sever_address.sin_family = PF_INET;
sever_address.sin_addr.s_addr = htons(INADDR_ANY);
sever_address.sin_port = htons(8888);
sock = socket(AF_INET,SOCK_STREAM,0);
assert(sock>=0);
int ret = bind(sock, (struct sockaddr*)&sever_address,sizeof(sever_address));
assert(ret != -1);
ret = listen(sock,1);
assert(ret != -1);
while(1)
{
struct sockaddr_in client;
socklen_t client_addrlength = sizeof(client);
connfd = accept(sock, (struct sockaddr*)&client, &client_addrlength);
if(connfd<0)
{
printf("errno\n");
}
else{
char request[1024];
recv(connfd,request,1024,0);
request[strlen(request)+1]='\0';
printf("%s\n",request);
printf("successeful!\n");
char buf[520]="HTTP/1.1 200 ok\r\nconnection: close\r\n\r\n";//HTTP响应
int s = send(connfd,buf,strlen(buf),0);//发送响应
//printf("send=%d\n",s);
int fd = open("hello.html",O_RDONLY);//消息体
sendfile(connfd,fd,NULL,2500);//零拷贝发送消息体
close(fd);
close(connfd);
}
}
return 0;
} 最简单的html文件:
this is the html.
hello word! waste young!
运行web.c文件,生成执行文件a.out,在终端执行后,我们在浏览器的网址栏中输入:http://localhost:8888 然后确认后,就会返回hello.html的文件页面
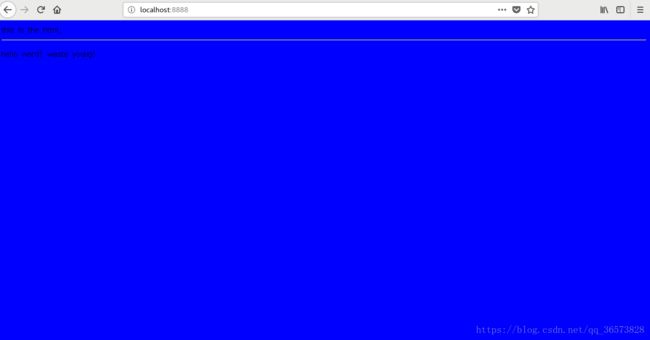
这里的URL,localhost:实际就是hostname,然后8888是端口,如果在端口后面再加上比如/hello.html这样的路径就表示请求服务器上的一个hello.html,这里请求方法是GET,所以要求服务器返回该资源的页面。
那么此时再来看下服务器接收到的东西,就是HTTP请求。

第一行就是请求行,请求行的格式是这样的:请求方法+空格+URL+空格+协议版本+\r+\n 这里的请求方法是GET ,URL是/(在这里,URL就相当于资源的路径,若在网址栏输入的是http://localhost:8888/hello.html的话,这里浏览器发送过来的URL就是/hello.html),协议版本是HTTP/1.1(现在多数协议版本都是这个)。
第二行到最后一行都是请求头部,请求头部的格式是这样的: 头部字段:+空格+数值+\r+\n 然后多个头部子段组织起来就是请求头部,在最后的头部字段的格式中需要有两个换行符号,最后一行的格式是:头部字段:+空格+数值+\r+\n+\r+\n 因为在后面还要跟着请求数据,为了区分请求数据和请求头的结束,就多了一个换行符。
三、HTTP请求和响应
(1)HTTP请求
简而言之就是客户端发送给服务端的请求。请求格式上面略提到了一点点,大概的格式就如下所示:

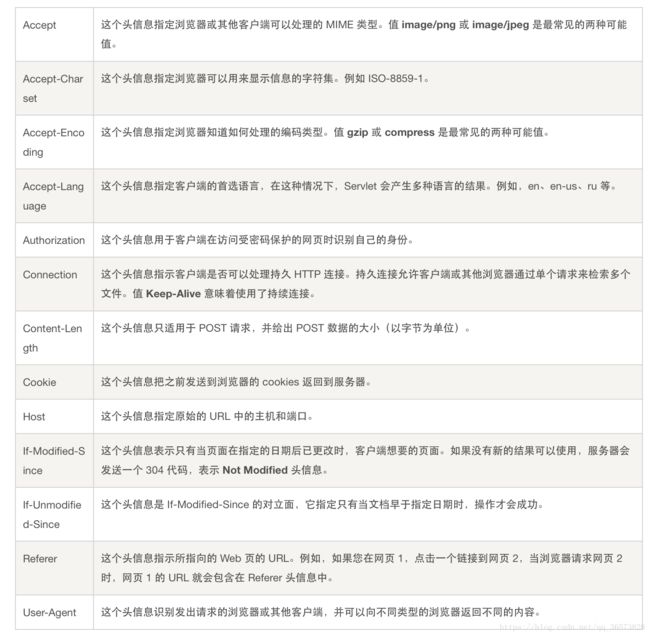
其中的细节就很多了,但是主要的是请求方法。其中头部字段有很多,大家可以上网百度。主要实现的就是GET方法和POST方法,其中GET方法是请求资源,但是不改变服务器上资源的,POST方法的话就会请求更改服务器上的资源。除了这两个方法外,还有PUT,DELETE,HEAD,TRACE等等。对应增删查改的就是PUT、DELETE、POST、GET。

然后URL就是要请求的资源路径,协议版本为HTTP/1.1,头部字段根据每个头部字段名都代表着给服务器的一个信息,具体可以根据以下网址查看:https://blog.csdn.net/sinat_22840937/article/details/64438253
(2)HTTP响应
HTTP响应就是服务端返回给客户端的响应消息。响应格式大概如下:

其中响应首行格式如:HTTP/1.1+状态响应码+\r\n 状态响应码参考如下:https://baike.baidu.com/item/HTTP状态码/5053660?fr=aladdin
这里大概用的是200,400,403,404,其中头部字段需要注意content-length,在服务器中响应码若没有消息题的长度,浏览器就只能通过关闭客户端才可以得知消息体的长度,才可以显示出消息体的具体表现。而且消息体的长度必须要和消息体吻合。如果服务端发送的消息体长度不正确的话,会导致超时或者浏览器一直显示不了要的资源文件。详细可以参考博客:https://www.cnblogs.com/lovelacelee/p/5385683.html
四、如何写出小型 web服务器
1、代码预备知识
- 了解TCP三次握手和TCP四次挥手
- 线程同步机制包装类
- 线程池创建
- epoll多路复用
(1)TCP三次握手
- 服务器需要准备好接受外来连接,通过socket bind listen三个函数完成,然后我们称为被动打开。
- 客户则通过connect发起主动连接请求,这就导致客户TCP发送一个SYN(同步)分节去告诉服务器客户将在待建立的连接中发送的数据的初始序列号,通常SYN不携带数据,其所在IP数据只有一个IP首部,一个TCP首部以及可能有的TCP选项。
- 服务器确认客户的SYN后,同时自己也要发送一个SYN分节,它含有服务器将在同一个连接中发送的数据的初始化列序号,服务器在单个分节中发送SYN和对客户SYN的确认
- 客户必须去确认服务器的SYN

(2)TCP四次挥手
- 某一个应用进程首先调用close,称为该端执行主动关闭,该端的TCP会发送一个FIN分节,表示数据已经发送完毕
- 接到FIN的对端将执行被动关闭,这个FIN由TCP确认,它的接受也作为一个文件结束符传递给接收端应用进程(放在已排队等候该应用进程接收的任何其他数据之后),因为FIN的接收意味着接收端应用进程在相应连接上已无额外数据可以接收
- 一段时间后,接收到这个文件结束符的应用进程会调用close关闭它的套接字,这会导致它的TCP也要发送一个FIN
- 接收这个最终FIN的原发送端TCP(即执行主动关闭的那一端)确认这个FIN

参考网站:https://www.cnblogs.com/Andya/p/7272462.html
(3)线程池的创建
我用的是半同步/半反应堆线程池。该线程池通用性比较高,主线程一般往工作队列中加入任务,然后工作线程等待后并通过竞争关系从工作队列中取出任务并且执行。而且应用到服务器程序中的话要保证客户请求都是无状态的,因为同一个连接上的不同请求可能会由不同的线程处理。

ps:若工作队列为空,则线程就处于等待状态,就需要同步机制的处理。
代码:
#ifndef _THREADPOOL_H
#define _THREADPOOL_H
#include
#include
#include
#include
#include
#include
#include"myhttp_coon.h"
#include"mylock.h"
using namespace std;
template
/*线程池的封装*/
class threadpool
{
private:
int max_thread;//线程池中的最大线程总数
int max_job;//工作队列的最大总数
pthread_t *pthread_poll;//线程池数组
std::list m_myworkqueue;//请求队列
mylocker m_queuelocker;//保护请求队列的互斥锁
sem m_queuestat;//由信号量来判断是否有任务需要处理
bool m_stop;;//是否结束线程
public:
threadpool();
~threadpool();
bool addjob(T* request);
private:
static void* worker(void *arg);
void run();
};
/*线程池的创建*/
template
threadpool :: threadpool()
{
max_thread = 8;
max_job = 1000;
m_stop = false;
pthread_poll = new pthread_t[max_thread];//为线程池开辟空间
if(!pthread_poll)
{
throw std::exception();
}
for(int i=0; i
threadpool::~threadpool()
{
delete[] pthread_poll;
m_stop = true;
}
template
bool threadpool::addjob(T* request)
{
m_queuelocker.lock();
if(m_myworkqueue.size()> max_job)//如果请求队列大于了最大请求队列,则出错
{
m_queuelocker.unlock();
return false;
}
m_myworkqueue.push_back(request);//将请求加入到请求队列中
m_queuelocker.unlock();
m_queuestat.post();//将信号量增加1
return true;
}
template
void* threadpool::worker(void *arg)
{
threadpool *pool = (threadpool*)arg;
pool->run();
return pool;
}
template
void threadpool :: run()
{
while(!m_stop)
{
m_queuestat.wait();//信号量减1,直到为0的时候线程挂起等待
m_queuelocker.lock();
if(m_myworkqueue.empty())
{
m_queuelocker.unlock();
continue;
}
T* request = m_myworkqueue.front();
m_myworkqueue.pop_front();
m_queuelocker.unlock();
if(!request)
{
continue;
}
request->doit();//执行工作队列
}
}
#endif
(4)同步机制的包装类
因为采用了线程池,就相当于用了多线程编程,此时就需要考虑各个线程对公共资源的访问的限制,因为方便之后的代码采用了三种包装机制,分别是信号量的类,互斥锁的类和条件变量的类。在服务器中我使用的是信号量的类。其中信号量的原理和System V IPC信号量一样(不抄书了,直接拍照了。。。)


代码实现:
#ifndef _MYLOCK_H
#define _MYLOCK_H
#include
#include
#include
#include
#include
#include
#include"myhttp_coon.h"
using namespace std;
/*封装信号量*/
class sem{
private:
sem_t m_sem;
public:
sem();
~sem();
bool wait();//等待信号量
bool post();//增加信号量
};
//创建信号量
sem :: sem()
{
if(sem_init(&m_sem,0,0) != 0)
{
throw std ::exception();
}
}
//销毁信号量
sem :: ~sem()
{
sem_destroy(&m_sem);
}
//等待信号量
bool sem::wait()
{
return sem_wait(&m_sem) == 0;
}
//增加信号量
bool sem::post()
{
return sem_post(&m_sem) == 0;
}
/*封装互斥锁*/
class mylocker{
private:
pthread_mutex_t m_mutex;
public:
mylocker();
~mylocker();
bool lock();
bool unlock();
};
mylocker::mylocker()
{
if(pthread_mutex_init(&m_mutex, NULL) != 0)
{
throw std::exception();
}
}
mylocker::~mylocker()
{
pthread_mutex_destroy(&m_mutex);
}
/*上锁*/
bool mylocker::lock()
{
return pthread_mutex_lock(&m_mutex)==0;
}
/*解除锁*/
bool mylocker::unlock()
{
return pthread_mutex_unlock(&m_mutex) == 0;
}
/*封装条件变量*/
class mycond{
private:
pthread_mutex_t m_mutex;
pthread_cond_t m_cond;
public:
mycond();
~mycond();
bool wait();
bool signal();
};
mycond::mycond()
{
if(pthread_mutex_init(&m_mutex,NULL)!=0)
{
throw std::exception();
}
if(pthread_cond_init(&m_cond, NULL)!=0)
{
throw std::exception();
}
}
mycond::~mycond()
{
pthread_mutex_destroy(&m_mutex);
pthread_cond_destroy(&m_cond);
}
/*等待条件变量*/
bool mycond::wait()
{
int ret;
pthread_mutex_lock(&m_mutex);
ret = pthread_cond_wait(&m_cond,&m_mutex);
pthread_mutex_unlock(&m_mutex);
return ret == 0;
}
/*唤醒等待条件变量的线程*/
bool mycond::signal()
{
return pthread_cond_signal(&m_cond) == 0;
}
#endif
(5)epoll多路复用
epoll系列系统调用函数(#include
int epoll_create(int size);创建内核事件表
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);操作epoll的内核事件表
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);一段时间内等待一组文件描述符上的就绪事件
除此这些函数外,还需要了解epoll的LT模式和ET模式还有EPOLLONESHOT事件.
下面三篇博客了解下:
https://blog.csdn.net/davidsguo008/article/details/73556811
https://blog.csdn.net/men_wen/article/details/53456491
https://blog.csdn.net/yusiguyuan/article/details/15027821
代码:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include"threadpool.h"
//#include"myhttp_coon.h"
using namespace std;
const int port = 8888;
int setnonblocking(int fd)
{
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
void addfd(int epfd, int fd, bool flag)
{
epoll_event ev;
ev.data.fd = fd;
ev.events = EPOLLIN | EPOLLET | EPOLLRDHUP;
if(flag)
{
ev.events = ev.events | EPOLLONESHOT;
}
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &ev);
setnonblocking(fd);
}
int main(int argc, char *argv[])
{
threadpool* pool = NULL;
pool = new threadpool;
http_coon* users = new http_coon[100];
assert(users);
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
address.sin_port = htons(port);
address.sin_addr.s_addr = htons(INADDR_ANY);
int listenfd = socket(AF_INET,SOCK_STREAM,0);
assert(listenfd >= 0);
int ret;
ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
assert(ret != -1);
ret = listen(listenfd,5);
assert(ret >= 0);
int epfd;
epoll_event events[1000];
epfd = epoll_create(5);
assert(epfd != -1);
addfd(epfd, listenfd, false);//listen不能注册EPOLLONESHOT事件,否则只能处理一个客户连接
while(true)
{
int number = epoll_wait(epfd, events, 1000, -1);
if( (number < 0) && (errno != EINTR) )
{
printf("my epoll is failure!\n");
break;
}
for(int i=0; i MAX_FD)
{
show_error(client_fd, "Internal sever busy");
continue;
}*/
//初始化客户连接
cout << epfd << " " << client_fd << endl;
addfd(epfd, client_fd, true);
cout << "client_fd:" << client_fd << "****\n";
users[client_fd].init(epfd,client_fd);
}
else if(events[i].events & (EPOLLRDHUP | EPOLLHUP | EPOLLERR))
{
/*出现异常则关闭客户端连接*/
users[sockfd].close_coon();
}
else if(events[i].events & EPOLLIN)//可以读取
{
if(users[sockfd].myread())
{
/*读取成功则添加任务队列*/
pool->addjob(users+sockfd);
}
else{
users[sockfd].close_coon();
}
}
else if(events[i].events & EPOLLOUT)//可写入
{
if(!users[sockfd].mywrite())
{
users[sockfd].close_coon();
}
}
}
}
close(epfd);
close(listenfd);
delete[] users;
delete pool;
return 0;
}
2、主要逻辑思路
- 首先创建和客户端的连接
- 服务器通过客户端的HTTP请求解析来判断返回何种结果.HTTP解析是以行为单位的,前提条件是根据\r\n来判断是否完整度入一行,若完整读入一行了那么就可以进行解析了。
- 通过HTTP请求的解析后,在写缓冲区写如HTTP响应,发送给客户端(HTTP应答包括一个状态行,多个头部字段,一个空行和资源内容,其中前三个部分的内容一般会被web服务器放置在一块内存中,而文档的内容通常会被放到另一个单独的内存中)
- 发送响应首行后,就可以发送主要的消息体了
主要就是封装在myhttp_coon.h中:
#ifndef _MYHTTP_COON_H
#define _MYHTTP_COON_H
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
#define READ_BUF 2000
class http_coon{
public:
/*NO_REQUESTION是代表请求不完整,需要客户继续输入;BAD_REQUESTION是HTTP请求语法不正确;GET_REQUESTION代表获得并且解析了一个正确的HTTP请求;FORBIDDEN_REQUESTION是代表访问资源的权限有问题;FILE_REQUESTION代表GET方法资源请求;INTERNAL_ERROR代表服务器自身问题;NOT_FOUND代表请求的资源文件不存在;DYNAMIC_FILE表示是一个动态请求;POST_FILE表示获得一个以POST方式请求的HTTP请求*/
enum HTTP_CODE{NO_REQUESTION, GET_REQUESTION, BAD_REQUESTION, FORBIDDEN_REQUESTION,FILE_REQUESTION,INTERNAL_ERROR,NOT_FOUND,DYNAMIC_FILE,POST_FILE};
/*HTTP请求解析的状态转移。HEAD表示解析头部信息,REQUESTION表示解析请求行*/
enum CHECK_STATUS{HEAD,REQUESTION};
private:
char requst_head_buf[1000];//响应头的填充
char post_buf[1000];//Post请求的读缓冲区
char read_buf[READ_BUF];//客户端的http请求读取
char filename[250];//文件总目录
int file_size;//文件大小
int check_index;//目前检测到的位置
int read_buf_len;//读取缓冲区的大小
char *method;//请求方法
char *url;//文件名称
char *version;//协议版本
char *argv;//动态请求参数
bool m_linger;//是否保持连接
int m_http_count;//http长度
char *m_host;//主机名记录
char path_400[17];//出错码400打开的文件名缓冲区
char path_403[23];//出错码403打开返回的文件名缓冲区
char path_404[40];//出错码404对应文件名缓冲区
char message[1000];//响应消息体缓冲区
char body[2000];//post响应消息体缓冲区
CHECK_STATUS status;//状态转移
bool m_flag;//true表示是动态请求,反之是静态请求
public:
int epfd;
int client_fd;
int read_count;
http_coon();
~http_coon();
void init(int e_fd, int c_fd);//初始化
int myread();//读取请求
bool mywrite();//响应发送
void doit();//线程接口函数
void close_coon();//关闭客户端链接
private:
HTTP_CODE analyse();//解析Http请求头的函数
int jude_line(int &check_index, int &read_buf_len);//该请求是否是完整的以行\r\n
HTTP_CODE head_analyse(char *temp);//http请求头解析
HTTP_CODE requestion_analyse(char *temp);//http请求行解析
HTTP_CODE do_post();//对post请求中的参数进行解析
HTTP_CODE do_file();//对GET请求方法中的url 协议版本的分离
void modfd(int epfd, int sock, int ev);//改变socket为状态
void dynamic(char *filename, char *argv);//通过get方法进入的动态请求处理
void post_respond();//POST请求响应填充
bool bad_respond();//语法错误请求响应填充
bool forbiden_respond();//资源权限限制请求响应的填充
bool succeessful_respond();//解析成功请求响应填充
bool not_found_request();//资源不存在请求响应填充
};
void http_coon::init(int e_fd, int c_fd)
{
epfd = e_fd;
client_fd = c_fd;
read_count = 0;
m_flag = false;
}
http_coon::http_coon()
{
}
http_coon::~http_coon()
{
}
/*关闭客户端链接*/
void http_coon::close_coon()
{
epoll_ctl(epfd, EPOLL_CTL_DEL, client_fd, 0);
close(client_fd);
client_fd = -1;
}
/*改变事件表中的事件属性*/
void http_coon::modfd(int epfd, int client_fd, int ev)
{
epoll_event event;
event.data.fd = client_fd;
event.events = ev | EPOLLET | EPOLLONESHOT | EPOLLRDHUP;
epoll_ctl(epfd, EPOLL_CTL_MOD, client_fd, &event);
}
/*read函数的封装*/
int http_coon::myread()
{
bzero(&read_buf,sizeof(read_buf));
while(true)
{
int ret = recv(client_fd, read_buf+read_count, READ_BUF-read_count, 0 );
if(ret == -1)
{
if(errno == EAGAIN || errno == EWOULDBLOCK)//读取结束
{
break;
}
return 0;
}
else if(ret == 0)
{
return 0;
}
read_count = read_count + ret;
}
strcpy(post_buf,read_buf);
return 1;
}
/*响应状态的填充,这里返回可以不为bool类型*/
bool http_coon::succeessful_respond()//200
{
m_flag = false;
bzero(requst_head_buf,sizeof(requst_head_buf));
sprintf(requst_head_buf,"HTTP/1.1 200 ok\r\nConnection: close\r\ncontent-length:%d\r\n\r\n",file_size);
}
bool http_coon::bad_respond()//400
{
bzero(url, strlen(url));
strcpy(path_400,"bad_respond.html");
url = path_400;
bzero(filename,sizeof(filename));
sprintf(filename,"/home/jialuhu/linux_net/web_sever/%s",url);
struct stat my_file;
if(stat(filename,&my_file)<0)
{
cout << "文件不存在\n";
}
file_size = my_file.st_size;
bzero(requst_head_buf,sizeof(requst_head_buf));
sprintf(requst_head_buf,"HTTP/1.1 400 BAD_REQUESTION\r\nConnection: close\r\ncontent-length:%d\r\n\r\n",file_size);
}
bool http_coon::forbiden_respond()//403
{
bzero(url, strlen(url));
strcpy(path_403,"forbidden_request.html");
url = path_403;
bzero(filename,sizeof(filename));
sprintf(filename,"/home/jialuhu/linux_net/web_sever/%s",url);
struct stat my_file;
if(stat(filename,&my_file)<0)
{
cout << "失败\n";
}
file_size = my_file.st_size;
bzero(requst_head_buf,sizeof(requst_head_buf));
sprintf(requst_head_buf,"HTTP/1.1 403 FORBIDDEN\r\nConnection: close\r\ncontent-length:%d\r\n\r\n",file_size);
}
bool http_coon::not_found_request()//404
{
bzero(url, strlen(url));
strcpy(path_404,"not_found_request.html");
url = path_404;
bzero(filename,sizeof(filename));
sprintf(filename,"/home/jialuhu/linux_net/web_sever/%s",url);
struct stat my_file;
if(stat(filename,&my_file)<0)
{
cout << "草拟\n";
}
file_size = my_file.st_size;
bzero(requst_head_buf,sizeof(requst_head_buf));
sprintf(requst_head_buf,"HTTP/1.1 404 NOT_FOUND\r\nConnection: close\r\ncontent-length:%d\r\n\r\n",file_size);
}
/*动态请求处理*/
void http_coon::dynamic(char *filename, char *argv)
{
int len = strlen(argv);
int k = 0;
int number[2];
int sum=0;
m_flag = true;
bzero(requst_head_buf,sizeof(requst_head_buf));
sscanf(argv,"a=%d&b=%d",&number[0],&number[1]);
if(strcmp(filename,"/add")==0)
{
sum = number[0] + number[1];
sprintf(body,"\r\n%d + %d = %d
\r\n\r\n",number[0],number[1],sum);
sprintf(requst_head_buf,"HTTP/1.1 200 ok\r\nConnection: close\r\ncontent-length: %d\r\n\r\n",strlen(body));
}
else if(strcmp(filename,"/multiplication")==0)
{
cout << "\t\t\t\tmultiplication\n\n";
sum = number[0]*number[1];
sprintf(body,"\r\n%d * %d = %d
\r\n\r\n",number[0],number[1],sum);
sprintf(requst_head_buf,"HTTP/1.1 200 ok\r\nConnection: close\r\ncontent-length: %d\r\n\r\n",strlen(body));
}
}
/*POST请求处理*/
void http_coon::post_respond()
{
if(fork()==0)
{
dup2(client_fd,STDOUT_FILENO);
execl(filename,argv,NULL);
}
wait(NULL);
}
/*判断一行是否读取完整*/
int http_coon::jude_line(int &check_index, int &read_buf_len)
{
cout << read_buf << endl;
char ch;
for( ; check_index1 && read_buf[check_index-1]=='\r')
{
read_buf[check_index-1] = '\0';
read_buf[check_index++] = '\0';
return 1;
}
else{
return 0;
}
}
}
return 0;
}
/*解析请求行*/
http_coon::HTTP_CODE http_coon::requestion_analyse(char *temp)
{
char *p = temp;
cout << "p=" << p << endl;
for(int i=0; i<2; i++)
{
if(i==0)
{
method = p;//请求方法保存
int j = 0;
while((*p != ' ') && (*p != '\r'))
{
p++;
}
p[0] = '\0';
p++;
cout << "method:" <0 && r>0)
{
return true;
}
}
else{
int fd = open(filename,O_RDONLY);
assert(fd != -1);
int ret;
ret = write(client_fd,requst_head_buf,strlen(requst_head_buf));
if(ret < 0)
{
close(fd);
return false;
}
ret = sendfile(client_fd, fd, NULL, file_size);
if(ret < 0)
{
close(fd);
return false;
}
close(fd);
return true;
}
return false;
}
#endif 其中两个附加功能加法和减法的实现(通过GET方法请求),以及POST方法请求的加法和减法的实现
- 动态请求是什么样子(GET)
sum.html文件:
sum
点击"提交"按钮,表单数据将被发送到服务器上的“add”程序上。
服务器收到的请求是这样的,首先是打开sum.html文件

然后在表单上提交要相加的两个数字
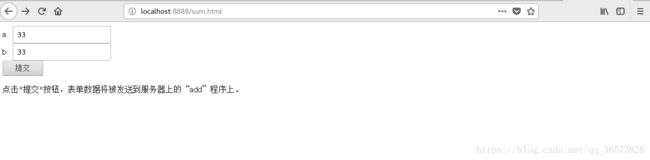
点击提交后,此时服务器收到的请求是这样的:

看到了/add?a=33&b=33 这就是通过方法GET提交上来的参数a和b ,此时我们在解析请求行的时候就可以通过问好来判断是否是GET的动态请求,若是那么根据sscanf()函数,分离出参数a和b,进行相加后就可以填充HTTP响应发送给浏览器了。此处我根据提交的程序名称来选择函数,在函数中相加填充返回给浏览器。当然我觉得正确的做法是重新写一个add.c然后执行生产add文件,再在fork()一个子线程通过execl( )函数去执行。
- 那么POST请求又是什么样子呢,其实POST请求将参数放在了请求
修改后的sum.html文件
sum
点击"提交"按钮,表单数据将被发送到服务器上的“add”程序上。
加入了属性method="post",此时打开sum.html文件依然是GET方法,只是点击提交表单后用的是POST方法。

和GET不同的是,参数被在请求的数据部分,也就是空行之后,此时若方法是POST的话,根据read_buf_len和Content_Length就可以求出参数在read_buf中的起始位置。然后又可以通过sscanf( )分离参数了,然后fork()一个进程,利用dup2函数,将标准输出重定向到浏览器的sockfd上,再执行execl( )函数。此时我们的add执行文件的.c文件如下:
#include
#include
int main(int argc, char *argv[])
{
char re_head[1000];
char message[1000];
int ret;
int a,b,result;
ret = sscanf(argv[0],"a=%d&b=%d", &a, &b);
//printf("a=%d\t b=%d\n",a,b);
if(ret < 0 || ret != 2)
{
sprintf(message,"\r\n");
sprintf(message,"%sfailure
\r\n",message);
sprintf(message,"%s");
sprintf(re_head,"HTTP/1.1 GET\r\n");
sprintf(re_head,"%scontent-length: %d\r\n",re_head,strlen(message));
sprintf(re_head,"%scontent-type: text/html\r\n",re_head);
sprintf(re_head,"%sconection: close\r\n\r\n");
/*错误提示消息*/
}
else{
result = a+b;
/*返回正确信息*/
sprintf(message,"\r\n");
sprintf(message,"%s%d + %d = %d
\r\n",message,a,b,result);
sprintf(message,"%swelcome to the word of jialuhu
\r\n",message);
sprintf(message,"%s\r\n",message);
sprintf(re_head,"HTTP/1.1 200 ok\r\n");
sprintf(re_head,"%sContent-length: %d\r\n",re_head,(int)strlen(message));
sprintf(re_head,"%scontent-type: text/html\r\n\r\n",re_head);
// sprintf(re_head,"%sconection: close\r\n\r\n");
}
printf("%s",re_head);
printf("%s",message);
fflush(stdout);
return 0;
} 当然除了加减法,还有很多功能可以去实现。此处就简单实现了这些功能。还有一些HTML文件,因为懒癌原因,所以随便写了几个。
五、总结
纵观博客其实感觉涉及的知识有点杂乱,但是很综合吧。首先满足代码上高性能的需求,利用了线城池和epoll多路复用,其中也包括同步机制的封装。其次就是HTTP这块的知识了,包括请求格式响应格式和请求方法和响应状态码,很多很多都是零零碎碎平凑一起的。而且感觉这个服务器的实现,也终于明白了浏览器和后台是怎么沟通交流的,有时候看不如动手实现下,很多东西就会突然明白了。大体模块就是epoll、线城池、同步机制、逻辑处理。代码里肯定也有很多没有测试出来的bug,但是实现大概三分之二后还是有丢丢开心的吧。