【矩阵学习】Jacobian矩阵和Hessian矩阵
【矩阵学习】Jacobian矩阵和Hessian矩阵
- Jacobian 矩阵
- Jacobian 行列式
- Hessian 矩阵
- Hessian 在牛顿法中的应用
Jacobian 矩阵
在向量分析中, 雅可比矩阵是一阶(first-order)偏导数(partial derivatives)以一定方式排列成的矩阵, 其行列式称为雅可比行列式。
wikipedia 给出的定义:
假设 f : R n → R m \bm{f}:R^{n} \rightarrow R^{m} f:Rn→Rm 是一个从欧式 n n n 维空间映射到欧式 m m m 维空间的函数,输入向量为 x ∈ R n \bm{x} \in R^{n} x∈Rn,输出向量为 f ( x ) ∈ R m \bm{f(x)} \in R^{m} f(x)∈Rm。若 f f f 的偏导数存在,其组成的 m × n m \times n m×n 的矩阵就是雅可比(Jacobian)矩阵:

可以看出, J i j = ∂ f i ∂ x j \bm{J}_{ij} = \frac{\partial \bm{f}_{i}}{\partial \bm{x}_{j}} Jij=∂xj∂fi。
Jacobian 矩阵有一个很重要的知识点,就是 最佳优线性近似 。
如果 p p p 是 R n R^{n} Rn 中的一点, f \bm{f} f 在 p p p 点可微,那么这一点的导数可由 J f ( p ) \bm{J}_\bm{f}(p) Jf(p) 给出。在这种情况下, J f ( p ) \bm{J}_\bm{f}(p) Jf(p) 是 f f f 在接近点 p p p 处的最优线性近似(其中, x x x 逼近 p p p, ∣ ∣ x − p ∣ ∣ ||x-p|| ∣∣x−p∣∣ 是 x x x 和 p p p 之间的距离。):
![]()
对比标量函数的一阶泰勒展开公式,可见梯度和 Jacobian 都是一阶导数,梯度是(多变量的)标量函数的一阶导数,而 Jacobian 是(多变量的)矢量函数的一阶导数。标量函数的一阶泰勒展开式如下:
![]()
Inverse 反向
根据反函数定理,一个可逆函数的 Jacobian 矩阵的逆矩阵就是该函数的逆函数的 Jacobian 矩阵。也就是说,假设 f : R n → R m \bm{f}:R^{n} \rightarrow R^{m} f:Rn→Rm 的 Jacobian 连续并且在点 p p p 是非奇异的,那么 f f f 在 p p p 点邻域可逆,可表示为:
![]()
critical points 驻点 / 临界点
若 f : R n → R m \bm{f}:R^{n} \rightarrow R^{m} f:Rn→Rm 可微,使得 Jacobian 矩阵的秩非最大值的点称为 f f f 的驻点或临界点。也就是说,假设 k k k 是 Jacobian 矩阵秩的最大值,若某点处所有的 k k k 阶余子式都为零,则该点为驻点或临界点。
Jacobian 行列式
当 Jacobian 矩阵 m = n m=n m=n 时,那么它的行列式则称为 Jacobian 行列式。
在某个给定点 p p p 的 Jacobian 行列式提供了在 p p p 点邻域,函数 f f f 的相关重要信息。例如:
- 反函数定理。如果连续可微函数 f f f 在点 p p p 的 Jacobian 行列式非零,那么它在该点附近具有反函数。
- 如果点 p p p 的 Jacobian 行列式是正数, 则函数 f f f 在点 p p p 的取向不变;如果是负数,则的取向相反。从 Jacobian 行列式的绝对值,就可以知道函数 f f f 在点 p p p 的缩放因子。(这也是 Jacobian 行列式运用到换元积分法中的原因)
Hessian 矩阵
在数学中, 海森矩阵( Hessian matrix 或 Hessian )是一个自变量为向量的实值函数的二阶偏导数组成的方块矩阵。海森矩阵被应用于牛顿法解决的大规模优化问题。
wikipedia 给出的定义:
假设 f : R n → R f:R^{n} \rightarrow R f:Rn→R ,输入是 n n n 维向量 x ∈ R n \bm{x}\in R^{n} x∈Rn,输出是标量函数 f ( x ) f(x) f(x)。若 f f f 的二阶偏导数存在且在定义域内连续,其组成的 n × n n \times n n×n 的矩阵就是海森(Hessian)矩阵:

也就是, H i j = ∂ 2 f ∂ x i ∂ x j \bm{H}_{ij}= \frac{\partial^{2} f}{\partial \bm{x}_{i}\partial \bm{x}_{j}} Hij=∂xi∂xj∂2f,亦可表示为 H ( f ( x ) ) = J ( ∇ f ( x ) ) T \bm{H}(f(\bm{x}))=\bm{J}(\nabla f(\bm{x}))^{T} H(f(x))=J(∇f(x))T。
Hessian 矩阵的行列式( the product of the eigenvalues )也常被称为 Hessian 或 Hessian determinant。
Second derivative test 二阶导数检验
Hessian 矩阵是半正定凸函数,可以利用这一点来判断驻点(critical point)是否为局部最大值、局部最小值或鞍点。假设驻点为 x x x,判断方法如下:
- Hessian 矩阵是正定矩阵时(特征值全为正数),则 f f f 在点 x x x 处取到极小值;
- Hessian 矩阵是负定矩阵时(特征值全为负数),则 f f f 在点 x x x 处取到极大值;
- Hessian 矩阵是不定矩阵时(特征值有正有负),则 x x x 是 f f f 的鞍点;
- 否则,无法确定,需要利用其他方法判断。
Hessian 在牛顿法中的应用
一般来说,主要有两个方面:1. 求解方程的根;2. 最优化
求解方程的根
Hessian 矩阵是泰勒展开的二次项系数:

上式中,当且仅当 Δ x \Delta x Δx 无限趋近于0时, f ( x + Δ x ) = f ( x ) f(x+\Delta x) = f(x) f(x+Δx)=f(x),约去这两项,并对余项式 ∇ f ( x ) T Δ x + 1 2 Δ x T H ( x ) Δ x = 0 \nabla f(x)^{T}\Delta x +\frac{1}{2}\Delta x^{T}H(x)\Delta x = 0 ∇f(x)TΔx+21ΔxTH(x)Δx=0,对 Δ x \Delta x Δx 求导,则有:
∇ f ( x ) + H ( x ) Δ x = 0 \nabla f(x)+H(x)\Delta x = 0 ∇f(x)+H(x)Δx=0
求解:
Δ x = − [ H ( x ) ] − 1 ∇ f ( x ) \Delta x = -[H(x)]^{-1}\nabla f(x) Δx=−[H(x)]−1∇f(x)
得到迭代公式:
x n + 1 = x n − [ H ( x n ) ] − 1 ∇ f ( x n ) x_{n+1} = x_{n}-[H(x_{n})]^{-1}\nabla f(x_{n}) xn+1=xn−[H(xn)]−1∇f(xn)
以上,为高维情况下的牛顿迭代公式推导。二维的情况也可同理推导,将上述过程中 “ ∇ f \nabla f ∇f” 替换为 “ f ′ f' f′ ”,“ H H H” 替换为 “ f ′ ′ f'' f′′ ” 即可。
牛顿法可应用于未知求根公式或求根公式很复杂的方程通过迭代求解。例如,求解方程 f ( x ) = 0 f(x) = 0 f(x)=0,通过泰勒公式展开,可知方程近似于 f ( x 0 ) + ( x − x 0 ) f ′ ( x 0 ) = 0 f(x_{0})+(x-x_{0})f'(x_{0}) = 0 f(x0)+(x−x0)f′(x0)=0,进而可推出迭代公式 x n + 1 = x n − f ( x n ) f ′ ( x n ) x_{n+1} = x_{n}-\frac{f(x_{n})}{f'(x_{n})} xn+1=xn−f′(xn)f(xn),这个子式必然在 f ( x ∗ ) = 0 f(x^{*}) = 0 f(x∗)=0 处收敛。这个过程可参考下图:

最优化
线性最优化可以使用单纯形法(或称不动点算法)求解, 而对于非线性优化问题, 牛顿法提供了一种求解的办法。
在最优化问题中,牛顿法 比 梯度下降法求解需要的迭代次数更少。
如下图,红色的是牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。从几何的角度上说,牛顿法就是用一个二次曲面去拟合当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面。通常情况下,前者拟合效果更好,因此迭代次数也更少。简单来说,牛顿法在选择方向时,不仅仅考虑了下降坡度,还考虑了下一步的下降坡度;比梯度下降法,多考虑了一步。
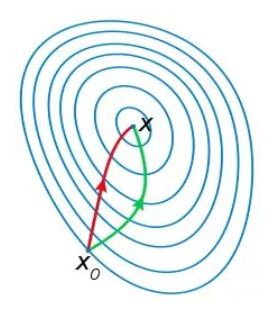
但是,牛顿法也有着它的缺点:
- 对目标函数有严格的要求,必须有连续的一阶、二阶偏导数,Hessian 矩阵必须是正定的。
- 计算量大,除计算梯度外,还需要计算二阶偏导数及其逆矩阵。
因此,衍生了许多算法,如拟牛顿法(用一个正定矩阵代替 Hessian 矩阵的逆矩阵)、DFP算法(对迭代过程中的 Hessian 矩阵作近似)和BFGS算法等,基本介绍可参考5.