CUDA学习笔记(三):第一个cuda程序
我们先从简单的做起,一般编程语言都会找个helloworld例子,而我们的显卡是不会说话的,只能做一些简单的加减乘除运算。所以,CUDA程序的helloworld,我想应该最合适不过的就是向量加了。
打开VS2013,选择File->New->Project,弹出下面对话框,设置如下:
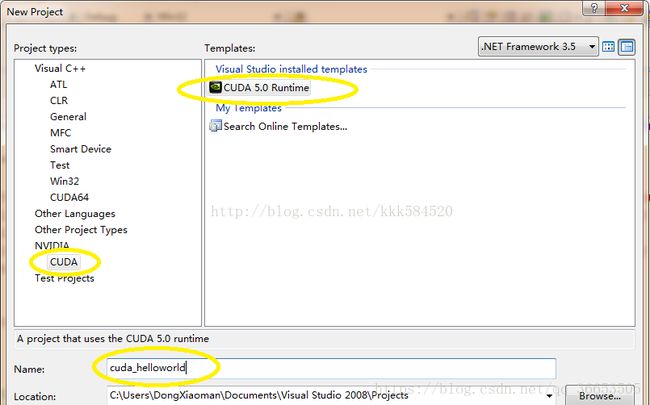
之后点OK,直接进入工程界面。
工程中,我们看到只有一个.cu文件,内容如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include 可以看出,CUDA程序和C程序并无区别,只是多了一些以”cuda”开头的一些库函数和一个特殊声明的函数:
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
这个函数就是在GPU上运行的函数,称之为核函数,英文名Kernel Function,注意要和操作系统内核函数区分开来。
我们直接按F7编译,可以得到如下输出:
1>------ Build started: Project: cuda_helloworld, Configuration: Debug Win32 ------
1>Compiling with CUDA Build Rule...
1>"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\nvcc.exe" -G -gencode=arch=compute_10,code=\"sm_10,compute_10\" -gencode=arch=compute_20,code=\"sm_20,compute_20\" --machine 32 -ccbin "C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\bin" -Xcompiler "/EHsc /W3 /nologo /O2 /Zi /MT " -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\include" -maxrregcount=0 --compile -o "Debug/kernel.cu.obj" kernel.cu
1>tmpxft_000000ec_00000000-8_kernel.compute_10.cudafe1.gpu
1>tmpxft_000000ec_00000000-14_kernel.compute_10.cudafe2.gpu
1>tmpxft_000000ec_00000000-5_kernel.compute_20.cudafe1.gpu
1>tmpxft_000000ec_00000000-17_kernel.compute_20.cudafe2.gpu
1>kernel.cu
1>kernel.cu
1>tmpxft_000000ec_00000000-8_kernel.compute_10.cudafe1.cpp
1>tmpxft_000000ec_00000000-24_kernel.compute_10.ii
1>Linking...
1>Embedding manifest...
1>Performing Post-Build Event...
1>copy "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\cudart*.dll" "C:\Users\DongXiaoman\Documents\Visual Studio 2008\Projects\cuda_helloworld\Debug"
1>C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\cudart32_50_35.dll
1>C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\cudart64_50_35.dll
1>已复制 2 个文件。
1>Build log was saved at "file://c:\Users\DongXiaoman\Documents\Visual Studio 2008\Projects\cuda_helloworld\cuda_helloworld\Debug\BuildLog.htm"
1>cuda_helloworld - 0 error(s), 105 warning(s)
========== Build: 1 succeeded, 0 failed, 0 up-to-date, 0 skipped ==========
可见,编译.cu文件需要利用nvcc工具。该工具的详细使用见后面博客。
直接运行,可以得到结果图如下:
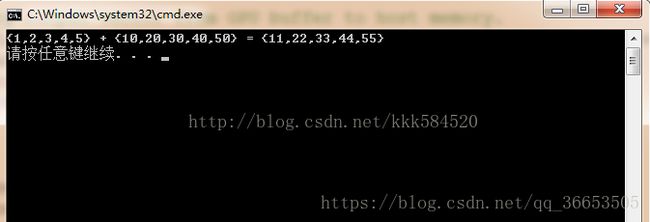
如果显示正确,那么我们的第一个程序宣告成功!