JAVA爬虫多线程高速爬取高清电脑壁纸
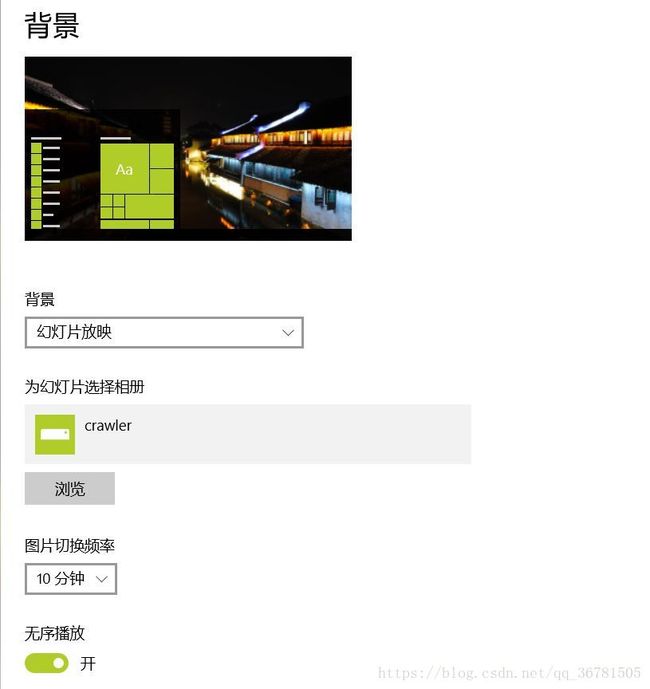
笔者特别喜欢将一大堆高清的图片作为Windows的壁纸幻灯片放映。就像下图一样。
以前各大高清壁纸网站上找自己喜欢的风景壁纸,一张一张的下载,用了好几年,终于审美疲劳了。
所以打算换一下资源。然后瞄准了这个网站(ZOL壁纸)。里面的壁纸还是不错的。
实在没精力像年少的时候一张一张的挑一张一张的下载了。就干脆写个小爬虫批量抓取吧。
额,第一步该干嘛? 先简单分析一下网页
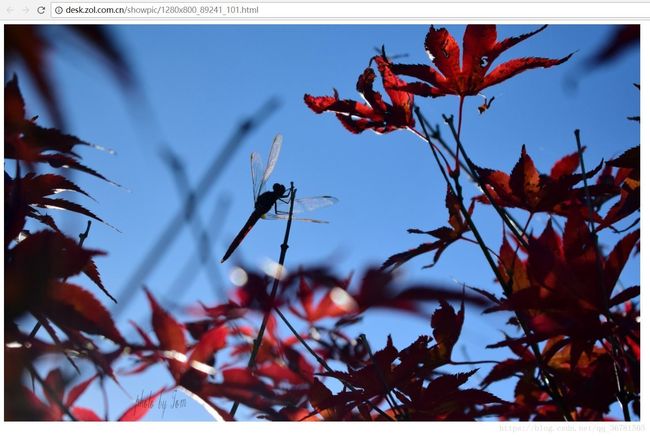
当选择我点击分辨率1280*800的后,跳转到了这张图片的网页,然后一般就可以对着图片右键选择图片另存为这样的方式下载图片了。当然,我们不这样下载。
分析一下网页的地址,细心的人一定会发现这个网页似乎有点规律呀
![]()
1280*800就是我刚刚点进去的分辨率,那后面这个89241是不是代表第89241张图片,抱着试一试的态度,里面的一个数字试一试,要不就把89241改为89242吧?
WOC,果然如此,那后面的_101有什么作用呢,我又去改了一下,发现什么都没变化。那就先不管了。反正中间那个数字对应的就是图片的编号。
对着网页右键查看源代码

图片的URL在这里,这下就可以开始干了吧。
我的思路如下
1、先抓取网页得到源码
2、通过正则表达式截取图片的URL
3、通过URL下载图片
说了这么久,终于可以上代码了~~
这是得到网页源码并通过正则表达式截取图片URL的函数
/**
* 传入网页的地址
* @param u
* @return
* @throws IOException
*/
public String getImgUrl(String u) throws IOException {
StringBuffer sb = new StringBuffer();
URL url = new URL(u);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 " +
"(KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1");
InputStream in = connection.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in, "UTF-8"));
String string = "";
while (null != (string = reader.readLine())) {
sb.append(string);
}
string = sb.toString();
//从获取的源码中截取图片的URL
Matcher matcher = Pattern.compile(imgReg).matcher(string);
if (matcher.find()) {
string = matcher.group();
string = string.substring(10, string.length() - 2);
}
in.close();
return string;
}其中imgReg为:
private static final String imgReg = ""; 然后得到图片的URL后,将图片下载,然后存入本地
public void getImg(String imgUrl) throws IOException {
URL url = new URL(imgUrl);
InputStream in = url.openStream();
FileOutputStream fo = new FileOutputStream(new File("F:/crawler/" + this.number+".jpg"));
byte[] by = new byte[1024];
int length = 0;
System.out.println("开始下载:" +this.number);
while ((length = in.read(by, 0, by.length)) != -1) {
fo.write(by, 0, length);
}
in.close();
fo.close();
}传入图片的URL就可以下载了。下载网页的源码与下载图片的函数都写好了。
首先,我们如何批量爬取呢,是不是只需要动态改变图片地址的那个关键数字就可以了

比如,写个5000 但是这样一张一张的爬取太慢了。标题说好的用多线程来爬取的呢。 先写一个类继承Thread,重写Run方法,直接上完整代码吧 这样下载一张图片的线程就写好了。接下来我们用一个线程池 第一个参数是线程池中允许的最大线程数,第二个参数是,需要扩展的时候线程池中最大的线程数(目前还不是很懂),第三个参数是,线程没有任务执行的时候多久会终止。然后第四个参数是阻塞队列,就是在后面等着去线程池中执行的队列。 然后写一个5000 下载的1920*1080的,大概花了15分钟左右吧。电脑连的手机热点,然后手机的流量少了3个Gpackage xyh.Crawler;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class MyCrawler extends Thread {
//将图片对应的网页分为三部分,前、中、后 前面后面无需改变,我们只需要动态改变中间的数字,得到的就是对应的图片
private String urlString = "http://desk.zol.com.cn/showpic/1920x1080_";
private String str = "_111.html";
//中间的数字
private int number;
//正则表达式
private static final String imgReg = " public static void main(String[] args) throws IOException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 200, 5 ,TimeUnit.SECONDS,
new ArrayBlockingQueue